NVIDIA Tesla T4 GPUs now available in beta
Chris Kleban
Group Product Manager, Google Cloud
In November, we announced that Google Cloud Platform (GCP) was the first and only major cloud vendor to offer NVIDIA’s newest data center GPU, the Tesla T4, via a private alpha. Today, these T4 GPU instances are now available publicly in beta in Brazil, India, Netherlands, Singapore, Tokyo, and the United States. For Brazil, India, Japan, and Singapore, these are the first GPUs we have offered in those GCP regions.
The T4 GPU is well suited for many machine learning, visualization and other GPU accelerated workloads. Each T4 comes with 16GB of GPU memory, offers the widest precision support (FP32, FP16, INT8 and INT4), includes NVIDIA Tensor Core and RTX real-time visualization technology and performs up to 260 TOPS1 of compute performance. Customers can create custom VM shapes that best meet their needs with up to four T4 GPUs, 96 vCPUs, 624GB of host memory and optionally up to 3TB of in-server local SSD. Our T4 GPU prices are as low as $0.29 per hour per GPU on Preemptible VM instances. On-demand instances start at $0.95 per hour per GPU, with up to a 30% discount with sustained use discounts. Committed use discounts are also available as well for the greatest savings for on-demand T4 GPU usage—talk with sales to learn more.
Broadest GPU availability
We’ve distributed our T4 GPUs across the globe in eight regions, allowing you to provide low latency solutions to your customers no matter where they are. The T4 joins our NVIDIA K80, P4, P100 and V100 GPU offerings, providing customers with a wide selection of hardware-accelerated compute options. T4 GPUs are now available in the following regions: us-central1, us-west1, us-east1, asia-northeast1, asia-south1, asia-southeast1, europe-west4, and southamerica-east1.

Machine learning inference
The T4 is the best GPU in our product portfolio for running inference workloads. Its high performance characteristics for FP16, INT8 and INT4 allow you to run high scale inference with flexible accuracy/performance tradeoffs that are not available on any other GPU. The T4’s 16GB of memory supports large ML models or running inference on multiple smaller models simultaneously. ML inference performance on Google Compute Engine’s T4s has been measured at up to 4267 images/sec2 with latency as low as 1.1ms3. Running production workloads on T4 GPUs on Compute Engine is a great solution thanks to the T4’s price, performance, global availability across eight regions and high-speed Google network. To help you get started with ML inference on the T4 GPU, we also have a technical tutorial demonstrating how to deploy a multi-zone, auto-scaling ML inference service on top of Compute Engine VMs and T4 GPUs.
Machine learning training
The V100 GPU has become the primary GPU for ML training workloads in the cloud thanks to its high performance, Tensor Core technology and 16GB of GPU memory to support larger ML models. The T4 supports all of this at a lower price point, making it a great choice for scale-out distributed training or when a V100 GPU’s power is overkill. Our customers tell us they like the near-linear scaling of many training workloads on our T4 GPUs as they speed up their training results with large numbers of T4 GPUs.
ML cost savings options only on Compute Engine
Our T4 GPUs complement our V100 GPU offering nicely. You can scale up with large VMs up to eight V100 GPUs, scale down with lower cost T4 GPUs or scale out with either T4 or V100 GPUs based on your workload characteristics. With Google Cloud as the only major cloud provider to offer T4 GPUs, our broad product portfolio lets you save money or do more with the same resources.
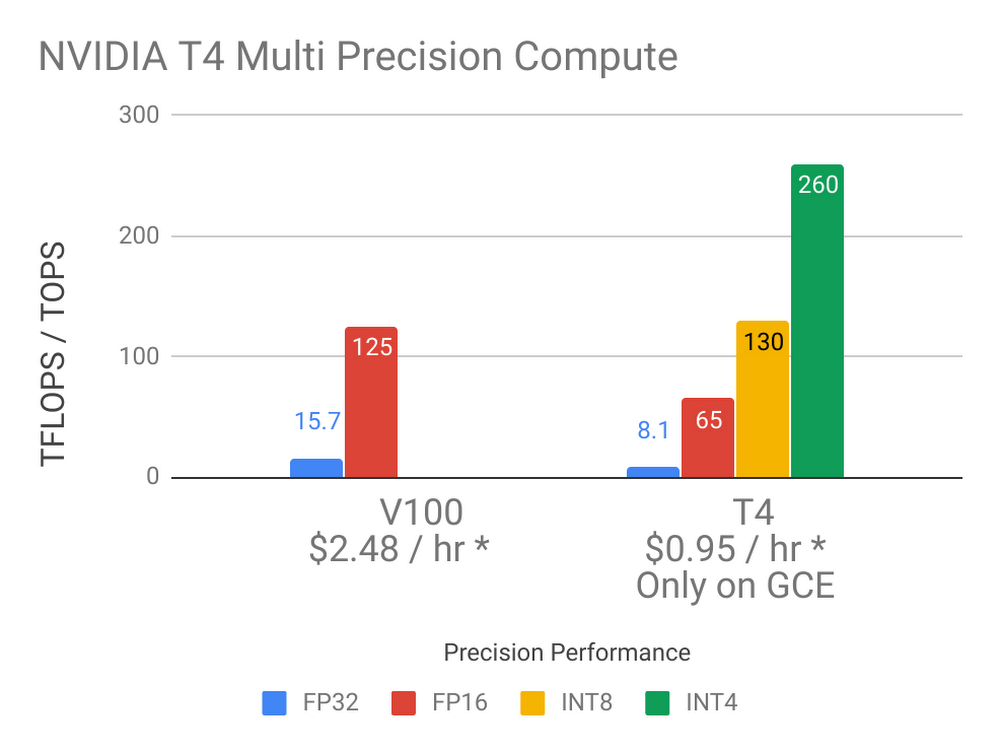
* Prices listed are current Compute Engine on-demand pricing for certain regions.
Prices may vary by region and lower prices are available through SUDs and Preemptible GPUs
Strong visualization with RTX
The NVIDIA T4 with its Turing architecture is the first data center GPU to include dedicated ray-tracing processors. Called RT Cores, they accelerate the computation of how light travels in 3D environments. Turing accelerates real-time ray tracing over the previous-generation NVIDIA Pascal architecture and can render final frames for film effects faster than CPUs, providing hardware-accelerated ray tracing capabilities via NVIDIA’s OptiX ray-tracing API. In addition, we are glad to also offer virtual workstations running on T4 GPUs that give creative and technical professionals the power of the next generation of computer graphics with the flexibility to work from anywhere and on any device.
Getting started
We make it easy to get started with T4 GPUs for ML, compute and visualization. Check out our GPU product page to learn more about the T4 and our other GPU offerings. For those looking to get up and running quickly with GPUs and Compute Engine, our Deep Learning VM image comes with NVIDIA drivers and various ML libraries pre-installed. Not a Google Cloud customer? Sign up today and take advantage of our $300 free tier.
Want a demo? Watch our on-demand webinar to discover the eight reasons why to run your ML training and inference with NVIDIA T4 GPUs on GCP.
1. 260 TOPs INT4 performance, 130 TOPs INT8, 65 TFLOPS FP16, 8.1 TFLOPS FP32
2. INT8 precision, resnet50, batch size 128
3. INT8 precision, resnet50, batch size 1