Improving speech recognition for contact centers
Dan Aharon
Product Manager, Speech
Shantanu Misra
Senior Product Manager, Google Cloud
Contact centers are critical to many businesses, and the right technologies play an important role in helping them provide outstanding customer care. Last July, we announced Contact Center AI to help businesses apply artificial intelligence to greatly improve the contact center experience. Today, we’re announcing a number of updates to the technologies that underpin the Contact Center AI solution—specifically Dialogflow and Cloud Speech-to-Text—that improve speech recognition accuracy by over 40% in some cases to better support customers and the agents that help them.
These updates include:
- Auto Speech Adaptation in Dialogflow (beta)
- Speech recognition baseline model improvements for IVRs and phone-based virtual agents in Cloud Speech-to-Text
- Richer manual Speech Adaptation in Dialogflow and Cloud Speech-to-Text (beta)
- Endless streaming in Cloud Speech-to-Text (beta)
- MP3 file format support in Cloud Speech-to-Text
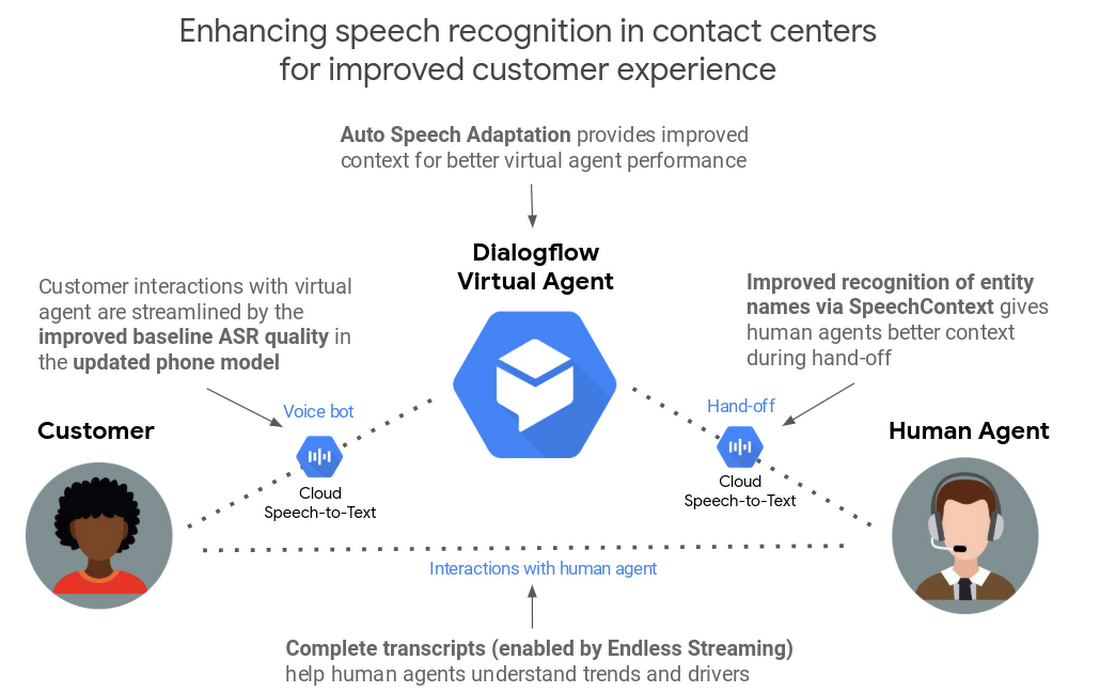
Improving speech recognition in virtual agents
Virtual agents are a powerful tool for contact centers, providing a better user experience around the clock while reducing wait times. However, the automated speech recognition (ASR) that virtual agents require is much harder to do on noisy phone lines than in the lab. And even at high recognition-accuracy rates (~90%), ASR can sometimes still result in a frustrating customer experience, as you can see below.

To help virtual agents quickly understand what customers need, and respond accurately, we’re introducing an exciting new feature in Dialogflow.
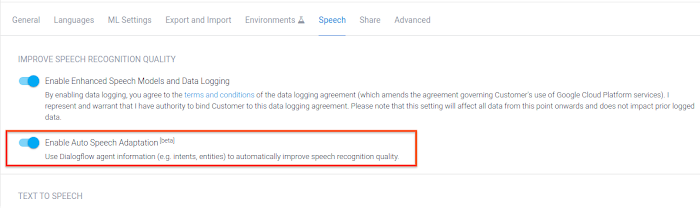
Auto Speech Adaptation in Dialogflow Beta
Just like knowing the context in a conversation makes it easier for people to understand one another, ASR improves when the underlying AI understands the context behind what a speaker is saying. We use the term speech adaptation to describe this learning process.
In Dialogflow—our development suite for creating automated conversational experiences—knowing context can help virtual agents respond more accurately. Using the example in the animation above, if the Dialogflow agent knew the context was “ordering a burger” and that “cheese” is a common burger ingredient, it would probably understand that the user meant “cheese” and not “these”. Similarly, if the virtual agent knew that the term “mail” is a common term in the context of a product return, it wouldn’t confuse it with the words “male” or “nail”.
To meet that goal, the new Auto Speech Adaptation feature in Dialogflow helps the virtual agent automatically understand context by taking all training phrases, entities, and other agent-specific information into account. In some cases, this feature can result in a 40% or more increase in accuracy on a relative basis.
It’s easy to activate Auto Speech Adaptation: just click the “on” switch in the Dialogflow console (off by default), and you’re all set!
Cloud Speech-to-Text baseline model improvements for IVRs and phone-based virtual agents
In April 2018, we introduced pre-built models for improved transcription accuracy from phone calls and video. We followed that up last February by announcing the availability of those models to all customers, not just those who had opted in to our data logging program. Today, we’ve further optimized our phone model for the short utterances that are typical of interactions with phone-based virtual agents. The new model is now 15% more accurate for U.S. English on a relative basis beyond the improvements we previously announced. Applying speech adaptation can also provide additional improvements on top of that gain. We’re constantly adding more quality improvements to the roadmap—an automatic benefit to any IVR or phone-based virtual agent, without any code changes needed--and will share more about these updates in future blog posts.
Improving transcription to better support human agents
Accurate transcriptions of customer conversations can help human agents better respond to customer requests, resulting in better customer care. These updates improve the quality of transcription accuracy to support human agents.
Richer manual speech adaptation tuning in Cloud Speech-to-Text
When using Cloud Speech-to-Text, developers use what are called SpeechContext parameters to provide additional contextual information that can make transcription more accurate. This tuning process can help improve recognition of phrases that are common in the specific use case involved. For example, a company’s customer service support line might want to better recognize the company’s product names.
Today, we are announcing three updates, all currently in beta, that make SpeechContext even more helpful for manually tuning ASR to improve transcription accuracy. These new updates are available in both the Cloud Speech-to-Text and Dialogflow APIs.
SpeechContext classes Beta
Classes are pre-built entities reflecting popular/common concepts, which give Cloud Speech-to-Text the context it needs to more accurately recognize and transcribe speech input. Using classes lets developers tune ASR for a whole list of words at once, instead of adding them one by one.
For example, let’s say there is an utterance that would normally result in the transcription, “It’s twelve fifty one”. Based on your use case, you could use a SpeechContext class to refine the transcription in a few different ways:
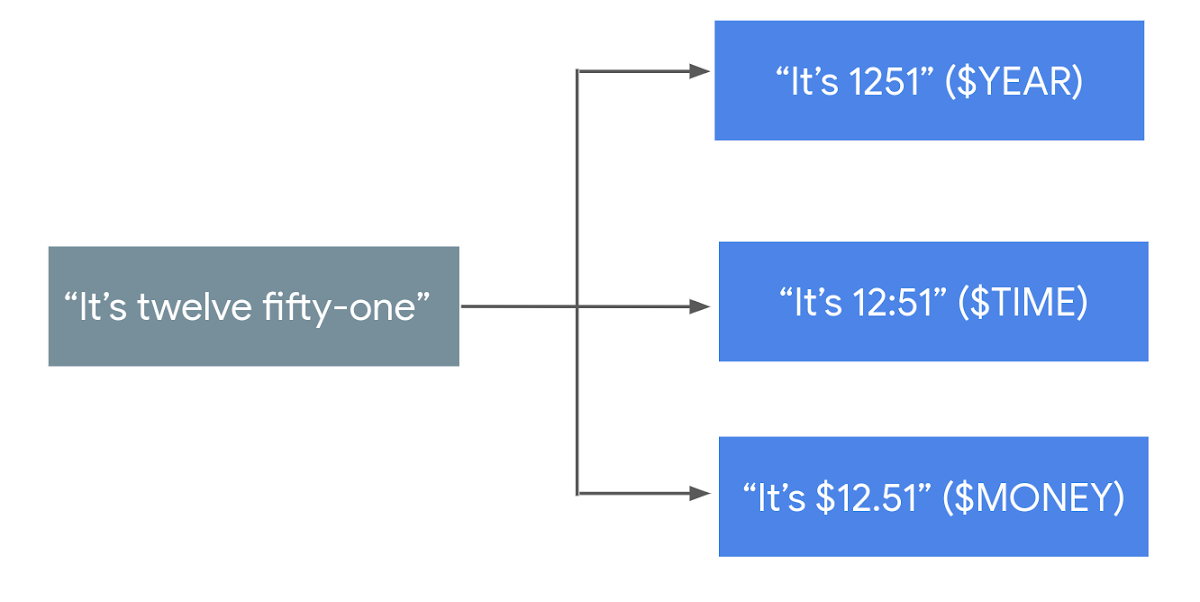
A number of other classes are available to similarly provide context around digit sequences, addresses, numbers, and money denominations—you can see the full list here.
SpeechContext boost Beta
Tuning speech recognition with tools like SpeechContext increases the likelihood of certain phrases getting captured—which will both reduce the number of false negatives (when a phrase was mentioned, but does not appear in the transcript), but can also potentially increase the number of false positives (when a phrase wasn’t mentioned, but appears in transcript). The new “boost” feature lets developers use the best speech adaptation strength for their use case.
Example:
SpeechContext expanded phrase limit Beta
As part of the tuning process, developers use “phrase hints" to increase the probability that commonly used words or phrases related to their business or vertical will be captured by ASR. The maximum number of phrase hints per API request has now been raised by 10x, from 500 to 5,000, which means that a company can now optimize transcription for thousands of jargon words (such as product names) that are uncommon in everyday language.
In addition to these new adaptation-related features, we’re announcing a couple of other highly requested enhancements that improve the product experience for everyone.
Endless streaming Beta in Cloud Speech-to-Text
Since we introduced Cloud Speech-to-Text nearly three years ago, long-running streaming has been one of our top user requests. Until now, Cloud Speech-to-Text only supported streaming audio in one-minute increments, which was problematic for long-running transcription use cases like meetings, live video, and phone calls. Today, the session time limit has been raised to 5 minutes. Additionally, the API now allows developers to start a new streaming session from where the previous one left off—effectively making live automatic transcription infinite in length, and unlocking a number of new use cases involving long-running audio.
MP3 file format support Beta in Cloud Speech-to-Text
Cloud Speech-to-Text has supported seven file formats up until now (list here). Up until now, processing MP3 files required first expanding them into the LINEAR16 format, which requires maintaining additional infrastructure. Cloud Speech-to-Text now natively supports MP3 so there are no additional conversions needed.
Woolworths’ use of conversational AI to improve the contact center experience
Woolworths is the largest retailer in Australia with over 100,000 employees, and has been serving customers since 1924.
“In partnership with Google, we’ve been building a new virtual agent solution—called Olive—based on Dialogflow and Google AI. We’ve seen market-leading performance right from the start," says Nick Eshkenazi, Chief Digital Technology Officer, Woolworths.
“We were especially impressed with accuracy of long sentences, recognition of brand names, and even understanding of the format of complex entities, such as '150g' for 150 grams."
“Auto Speech Adaptation provided a significant improvement on top of that and allowed us to properly answer even more customer queries. In the past, it used to take us months to create a high quality IVR experience. Now we can build very powerful experiences in weeks and make adjustments within minutes."
"For example, we recently wanted to inform customers about a network outage impacting our customer hub and were able to add messaging to our virtual agent quickly. The new solution provides our customers with instant responses to questions with zero wait time and helps them connect instantly with the right people when speaking to a live agent is needed.”
Looking forward
We’re excited to see how these improvements to speech recognition improve the customer experience for contact centers of all shapes and sizes—whether you’re working with one of our partners to deploy the Contact Center AI solution, or taking a DIY approach using our conversational AI suite. Learn more about both approaches via these links:




