How to build and execute AI use cases at the edge
Abdul Haseen Kinadiyil
Staff Technical Solutions Consultant
Yanni Peng
Customer Engineer
Running and processing vision ML models at the edge can support a wide variety of use cases. For example, ensuring that staff are wearing personal protective equipment (PPE), managing storefront and warehouse inventory, and predictive maintenance on assembly lines can improve the customer experience. Yet modernizing and leveraging AI, maintaining control over mission critical data, and complexity in managing multiple edge deployments can be difficult barriers to break through.
Artificial intelligence (AI) and machine learning (ML) technologies are popular for industrial use cases such as predictive maintenance, factory safety, voice recognition, and many more. These use cases require AI models deployed on edge locations such as manufacturing facilities, healthcare centers, retail stores, vehicles, etc. Deploying and managing AI workloads at scale across public cloud and edge locations can be challenging for many customers. Google Cloud provides a set of technologies and platforms to run and manage AI applications at scale on public cloud, edge locations, and devices.
Optimizing data and AI at the edge with Google Cloud.
Google Cloud has made it easy to develop, deploy and operationalize industrial AI applications with the Vertex AI platform. The Vertex AI platform provides high-quality pre-trained models such as product recognizer, tag recognizer, and other Vision and Video AI models. Developers can train the models using the Vertex AI platform and invoke image inference services for various use cases. The Edge AI applications may require developing custom models like object recognition. The custom models can be created and trained on the Vertex AI platform and deployed on Edge locations.
Google Distributed Cloud (GDC) allows developers to leverage Google’s best in class AI, security, and open-source with the independence and control over mission critical data, everywhere their customers are, including Google Distributed Cloud Edge (GDC Edge), fully managed software and hardware products for enterprise workloads such as such as retail, manufacturing, and transportation, and Google Distributed Cloud Hosted (GDC Hosted), an air-gapped private cloud solution to enable governments and regulated enterprises address strict data residency and security requirements
Edge TPU is Google Cloud’s purpose-built ASIC designed to run AI at the edge. It delivers high performance in a small physical and power footprint, enabling the deployment of high-accuracy AI at the edge. It complements Cloud TPU and Google Cloud services to provide an end-to-end, cloud-to-edge, hardware + software infrastructure for facilitating the deployment of customers' AI-based solutions. It isn't just a hardware solution, it combines custom hardware, open software, and state-of-the-art AI algorithms to provide high-quality, easy to deploy AI solutions for the edge. Edge TPU allows you to deploy high-quality ML inferencing at the edge, using various prototyping and production products from Coral. Edge TPU complements CPUs, GPUs, FPGAs, and other ASIC solutions for running AI at the edge.
In this post, you will learn how to build, train, and deploy a vision based machine learning model at the edge using Google Vertex AI, Google Distributed Cloud, and Edge TPUs to support industry cases such as inventory detection, PPE detection, and predictive maintenance.
Learning on the edge
When deploying AI workload on Edge locations, every single use case should have the trained models deployed on the right topology extending the public cloud. One end of the spectrum is large server farms using hypervisors and the other end is sensors and devices such as cameras. The developers should have consistent experience in developing and running the applications across these locations. The platform operators should be able to manage and monitor applications with ease no matter where they are running.
Customers can deploy machine learning models on Google Cloud Edge TPUs or GPUs using the GDC platforms. GPU and TPU not only enable AI workloads, they also provide several benefits including accelerated computation, enhanced performance for graphical applications, deep learning, energy efficiency, and scalability. The machine learning models can be trained using Cloud TPUs or Cloud GPUs and deployed on GDC. In this blog, we’ll cover how to configure both GPUs and Edge TPUs for edge workloads.
GPUs can be used to run AI/ML workload on edge networks using Google Distributed Cloud (GDC) deployments, supporting NVIDIA T4 and A100 GPUs to run AI workloads on edge locations and data centers. Customers can deploy NVIDIA’s GPU Device Plugin directly on their hardware, and run high performance ML workloads.
The ML workflow of deploying and managing a production-ready model on the edge network progress through these stages:
Preparing data
developing models
training models
deploying models
monitor the predictions
manage versions
Vertex AI and GDC streamline this process and enable you to run the AI workloads at scale on the edge network. Google Kubernetes Engine (GKE) enables you to run containerized AI workloads that require TPU or GPU for ML inference, training, and processing of data in the Google Cloud. You can run these AI workloads on GKE on the Edge network using GDC. Learn more about Google Distributed Cloud Edge supports retail vision AI use cases with the “magic mirror,” an interactive display leveraging cloud-based processing and image rendering at the edge to make retail products “magically” come to life in partnership with T-Mobile and Google Cloud. Let's look at the end to end architecture of deploying and managing AI models below.
Machine learning end-to-end
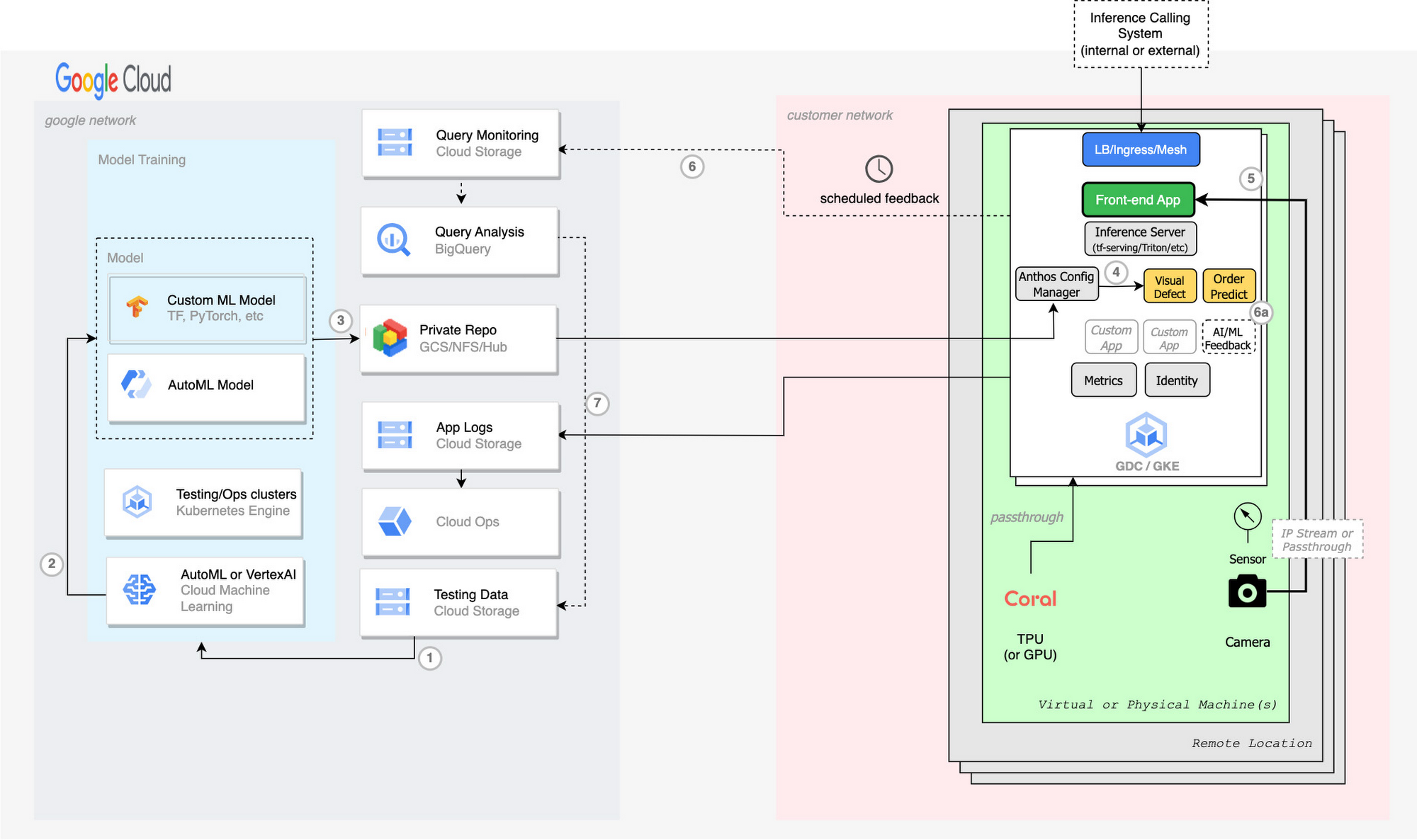
Train model using labeled or annotated data on Vertex AI
Export model from Vertex AI
Push exported model into GCS bucket or private AI Hub repo
Each cluster pulls down new model using KRM (YAML K8s configuration) on a TF Serving or Inference Server deployment through Anthos Config Manager (ACM)
Optionally export feedback via percentage results (6) or custom human verification application (6a). Export to GCS buckets
Use BigQuery to analyze ML model efficiency, identify changes to labels, attribution, classifiers, quality, etc and push to testing data (7)
Find the steps to configure Edge TPUs and GPUs on GDC below.
Configuration of Edge TPUs
When you're developing for a platform that's running Linux, Windows, or macOS, you can choose to use TensorFlow Lite with either Python or C/C++.
Regardless of the language you choose, you need to install the Edge TPU runtime (libedgetpu.so), as documented in the setup for each Coral device. Then you just need the appropriate TensorFlow Lite library and optional Coral library.
The containerization of the models requires custom development.
Configuration of GPUs
Here's how you configure NVIDIA T4 GPUs for K8s worker(s) in the GDC or Edge Anthos GKE platform.
Prerequisites:
1. Roles and permissions configuration.
- 1. Disable selinux
- 2. Disable apparmor
- 3. If selinux is enabled, run plugin daemonset with security context privileged
2. Dependencies:
- 1. Cuda dependencies installed on os
- 2. Install NVIDIA-Linux driver using script or manually
- 3 . Install Nvidia docker runtime
- 4. Configure kubernetes container runtime to point to nvidia (*most cases this is containerd)
- 5. Nvidia daemonset on each node.
- 6. Supported operating systems
3. Testing
- 1. Use nvidia-smi cli tool
- 2. Run a gpu workload test in cluster
- 3. Run cmd check gpu: kubectl describe nodes
Install:
1. Configure security (selinux, apparmor)
To disable SELinux open up the /etc/selinux/config configuration file and change the property to: SELINUX=disabled
2. Set-up Anthos Bare Metal by running bmctl commands on the VM (you need to be an owner/editor of the project being used).
3. Docker
Add your user to the docker group
Reboot the VM for the docker user group changes to take effect.
4. Install Nvidia drivers & cuda
ssh into the VM and run following commands:
Refer to this page in case of any errors or want to learn more.
5. Install Nvidia Docker & point kubernetes default container runtime to nvidia:
6. Install daemonset (may need to run as privileged):
7. Verify using nvidia-smi cli and check kubectl describe node. It should list “nvidia/gpu” with a value 1 or more under the allocatable resources.
What’s next?
Edge computing is accelerating the digital transformation for enterprises in an unprecedented way. With a comprehensive portfolio of fully managed hardware and software solutions, Google Distributed Cloud brings Google Cloud’s AI and analytics solutions closer to where your data is being generated and consumed, so you can harness real-time insights across deployments. GKE provides a consistent management experience across the cloud and the edge network for AI workloads.
Learn more about leveraging your data at the edge with the latest in AI from Google with Google Distributed Cloud Edge here.
Learn more about the Google Distributed Cloud, a product family that allows you to unleash your data with the latest in AI from edge, private data center, air-gapped, and hybrid cloud deployments. Available for enterprise and public sector, you can now leverage Google’s best-in-class AI, security, and open-source with the independence and control that you need, everywhere your customers are.
Dive deep into leveraging your data with Google Distributed Cloud at Google Cloud Next at the Moscone Center in San Francisco Aug. 29-31, 2023
Running AI at the edge to deliver modern customer experiences Session ARC 101
Mind the air gap: How cloud is addressing today’s sovereignty needs Session ARC100
What’s next for architects and IT professionals Spotlight SPTL202
Unleash the power of AI on Google Cloud hardware at the Hardware-verse:
Hardware-verse: Experience real-time visual inspection at the edge Interactive Demo HWV-101
Hardware-verse: Address sovereignty needs with air-gapped private cloud—Interactive Demo HWV-102
Hardware-verse: Supercharge your generative AI model development with Cloud TPUs Interactive Demo HWV-103
Learn more about the above for configuring GPU References with these step by step guides: