How do I speed up my Tensorflow Transformer models?
Erwin Huizenga
AI engineering and evangelism manager
Aleksey Vlasenko
Software Engineer
Transformer models have gained much attention in recent years and have been responsible for many of the advances in Natural Language Processing (NLP). Transformer models have often replaced Recurrent Neural Networks for many use cases like machine translation, text summarization, and document classification. For organizations, it can be challenging to deploy transformer models in production and perform inference because inference can be expensive, and the implementation can be complex. Recently we announced the public preview for a new runtime that optimizes serving TensorFlow (TF) models on the Vertex AI Prediction service. We are happy to announce that the optimized Tensorflow runtime is now GA. The optimized Tensorflow runtime generally results in faster predictions and better throughput than most open source based pre-built TensorFlow serving containers.
In this post, you learn how to deploy a fine-tuned T5x base model to the Vertex AI Prediction service using the optimized TensorFlow runtime and then evaluate the model performance. See the optimized TF runtime in the Vertex AI user guide for more details on how to use the runtime.
T5x
In this example, you will use the T5x base model. T5x is a new and improved implementation of the T5 codebase (based on Mesh TensorFlow) in JAX and Flax. T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. The model can be fine-tuned for specific tasks that it was not trained for. In this example, you use the model that’s fine-tuned for English to German translations that is JAX based.
The T5x pre-trained model can be exported as a TensorFlow Saved Model, and deployed to Vertex AI Prediction service using the optimized Tensorflow runtime. To do this, you can use the export script.
Deploying T5x on Vertex AI Predictions using the optimized TensorFlow runtime
To help you understand the notebook, you can follow these steps in a Vertex AI Workbench notebook or Colab. In this example, there are two types of exported models: one exported using float32 and one with bfloat16. The latter is a native format used for Google Cloud TPUs that you can also use with the NVIDIA A100, which the Optimized TF Runtime supports. You must use float32 with NVIDIA T4 or V100. If you use float32, you can leverage --allow_compression to run models on lower precision. The NVIDIA T4 doesn’t support bfloat16.
In this example you use the Vertex AI SDK for Python to deploy the model to a Vertex AI Endpoint. You use one of the optimized Tensorflow runtime containers to deploy the model on NVIDIA T4 GPUs. For more information, see Use the Vertex AI SDK for Python.
Next, upload and deploy the T5x base model with float32 weights and no optimizations on Vertex AI.
You can deploy the T5x model with different weight settings or model optimization flags. You can enable the following features to further optimize serving TensorFlow models:
In the Notebook example, you can find different configurations. For the best performance when you deploy the T5x model with bfloat16 weights on NVIDIA A100, use the –allow_precompilation argument to effectively utilize the bfloat16 logic.
After the models are deployed, you’re ready to send requests to the endpoints.
Benchmarking the T5x base model deployed using the optimized TF runtime on Vertex AI
To evaluate the benefits of using the optimized Tensorflow runtime with Vertex AI, we benchmarked the T5x model deployed on Vertex AI using MLPerf inference loadgen for Vertex Prediction. MLPerf Inference is a benchmark suite for measuring how fast systems can run models in various deployment scenarios. The main goal of benchmarking is to measure model latency on different loads and to identify the maximum throughput the model can handle. The benchmark code is included in the notebook and is reproducible.
Below you can see two charts that visualize the benchmark results for throughput and latency. The T5x model is deployed on Vertex AI Prediction using n1-standard-16 compute, NVIDIA T4 and A100 GPU instances, the optimized TensorFlow runtime, and TF nightly GPU containers.
Chart one shows the performance results for T5x deployed on Vertex AI using the NVIDIA T4 GPU. For this deployment we used the T5x model with float32 weights, because T4 doesn’t support bfloat16. The first bar shows the performance without any optimizations, the second bar shows the performance with precompilation enabled, and the third bar shows the results with precompilation and compression enabled.
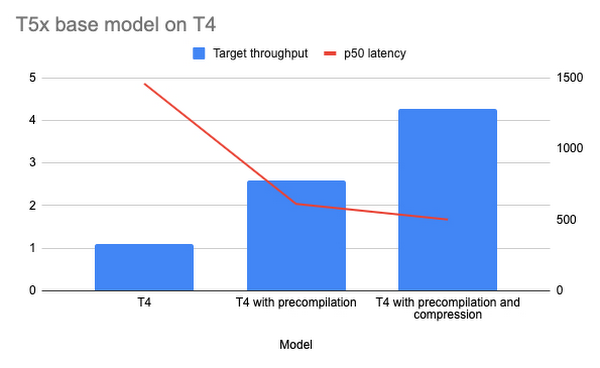
Chart one shows the performance results for T5x deployed on Vertex AI using the NVIDIA A100 GPU. The first bar shows T5x performance results without optimizations. The second bar shows the performance results with pre-compilations enabled using the bfloat16 format.
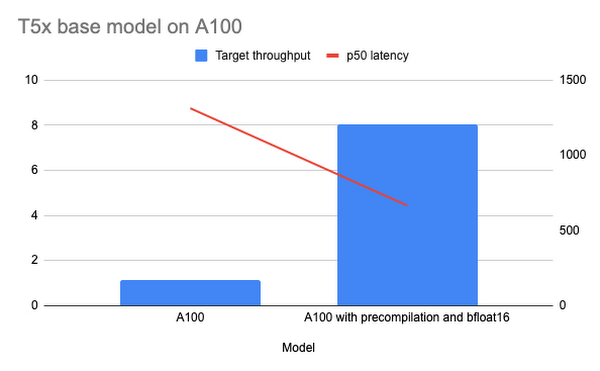
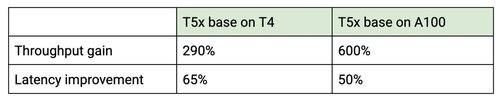
Use of the optimized TensorFlow runtime resulted in significantly lower latency and higher throughput for the T5x base model. Because the optimized TensorFlow runtime moves most of the computations to the GPU, you can use machines with less CPU power. In the table below you can see the overall improvements for throughput and latency.
What’s next?
To learn more about the optimized Tensorflow runtime and Vertex AI, take a look at the additional examples on BERT and Criteo or check out the optimized Tensorflow runtime documentation. You’ll see how easy it is to deploy your optimized model on Vertex AI.




