Speed up model inference with Vertex AI Predictions’ optimized TensorFlow runtime
Mark Iverson
Technical Writer
Aleksey Vlasenko
Software Engineer
Speed up model inference with Vertex AI Predictions’ optimized TensorFlow runtime
From product recommendations, to fraud detection, to route optimization, low latency predictions are vital for numerous machine learning tasks. That’s why we’re excited to announce a public preview for a new runtime that optimizes serving TensorFlow models on the Vertex AI Prediction service. This optimized TensorFlow runtime leverages technologies and model optimization techniques that are used internally at Google, and can be incorporated into your serving workflows without any changes to your training or model saving code. The result is faster predictions at a lower cost compared to the open source based pre-built TensorFlow serving containers.
This post is a high-level overview of the optimized TensorFlow runtime that reviews some of its features, how to use it, and then provides benchmark data that demonstrates how it performs. For detailed information about how to use the runtime, see Optimized TensorFlow runtime in the Vertex AI User Guide.
Optimized TensorFlow runtime overview
The optimized TensorFlow runtime uses model optimizations and proprietary Google technologies to serve trained models faster and at a lower cost than open source TensorFlow. This runtime leverages both the TensorFlow runtime (TFRT) and Google’s internal stack.
To make use of this runtime, all you need to do is select a specific container when deploying the model and optionally set a few flags. After doing this, you get the following benefits:
Improved tabular model performance on GPUs: This runtime can serve tabular models faster and at a lower cost by running computationally expensive parts of the model on GPUs. The rest of the model is run on CPUs by minimizing communication between the host and the accelerator. The runtime automatically determines which operations are best run on GPUs, and which ones are best run on CPUs. This optimization is available by default and does not require any changes to your model code or setting any flags to use it.
Model precompilation: To eliminate the overhead caused by running all operations individually, this runtime can precompile some, or all, of the TensorFlow graph. Precompilation is optional and can be enabled during model deployment.
Optimizations that may affect precision: This flag provides optional optimizations that can deliver significant improvements in latency and throughput, but may incur a small (usually a fraction of a percentage) drop in model precision or accuracy. Because of this, it’s recommended that you test the precision or accuracy of the optimized model on a hold out validation set before you deploy a model with these optimizations.
These are the optimizations available at the time of public preview. Additional optimizations and improvements will be added in upcoming releases.
To further lower your latency, you can use a private endpoint with the optimized TensorFlow runtime. For more information, see Use private endpoints for online prediction in the Vertex AI Predictions User Guide.
Note that the impact of the above optimizations depends on the operators used in the model and the model architecture. The latency and throughput (i.e. cost) improvements observed vary for different models. The benchmarks in the later section provide a rough estimate of what you can expect.
How to use the optimized TensorFlow runtime
You can use the optimized TensorFlow runtime almost exactly how you use the open source based pre-built TensorFlow Serving containers. Instead of using a pre-built container that’s based on open source TensorFlow build, all you need to do is choose an optimized TensorFlow runtime container.
There are two types of containers available: nightly and stable. Nightly containers have the most current updates and optimizations and are best suited for experimentation. Stable containers are based on stable TensorFlow releases and are best suited for production deployments. To see a list of containers with the optimized TensorFlow runtime, see Available container images.
When you configure your deployment, you can enable the two optional optimizations mentioned earlier in this article, model precompilation and optimizations that affect precision. For details about how to enable these optimizations, see Model optimization flags in the Vertex AI Prediction User Guide.
The following code sample demonstrates how you can create a model with a pre-built optimized TensorFlow runtime container. The key difference is the use of the us-docker.pkg.dev/vertex-ai-restricted/prediction/tf_opt-cpu.nightly:latest container in the “container_spec”. For more details, see Deploy a model using the optimized TensorFlow runtime in the Vertex AI Predictions User Guide.
Comparing performance
To showcase the benefits of using Vertex AI Prediction’s optimized TensorFlow runtime, we conducted a side-by-side comparison of performance for the tabular Criteo and BERT base classification models deployed on Vertex AI Prediction. For the comparison, we used the stock TensorFlow 2.7 and the optimized TensorFlow runtime containers.
To assess the performance, we used MLPerf loadgen for Vertex AI in the “Server” scenario. MLPerf loadgen sends requests to Vertex Prediction endpoints using the same distribution as the official MLPerf Inference benchmark. We ran it at increasing queries per second (QPS) until the models were saturated, then the observed latency was recorded for each request.
Models and benchmark code are fully reproducible and available in the vertex-ai-samples GitHub repository. You can walk through and run our benchmark tests yourself using the following notebooks.
Training a tabular Criteo model and deploying it to Vertex AI Predictions
Fine-tuning a BERT base classification model and deploying it to Vertex AI Predictions
Criteo model performance testing
The tabular Criteo model was deployed on Vertex AI Prediction using n1-standard-16 with NVIDIA T4 GPU instances and the optimized TensorFlow runtime, TF2.7 CPU, and TF2.7 GPU containers. While using the optimized TensorFlow runtime with the gRPC protocol isn’t officially supported, they work together. To compare the performance of different Criteo model deployments, we run MLPerf loadgen benchmarks over Vertex AI Prediction private endpoints using the gRPC protocol with requests of batch size 512.
The following graph shows the performance results. The “TF Opt GPU” bar shows the performance of the optimized TensorFlow runtime with precompilation enabled, and the “TF Opt GPU lossy” bar shows performance with both precompilation and precision affecting optimizations enabled.
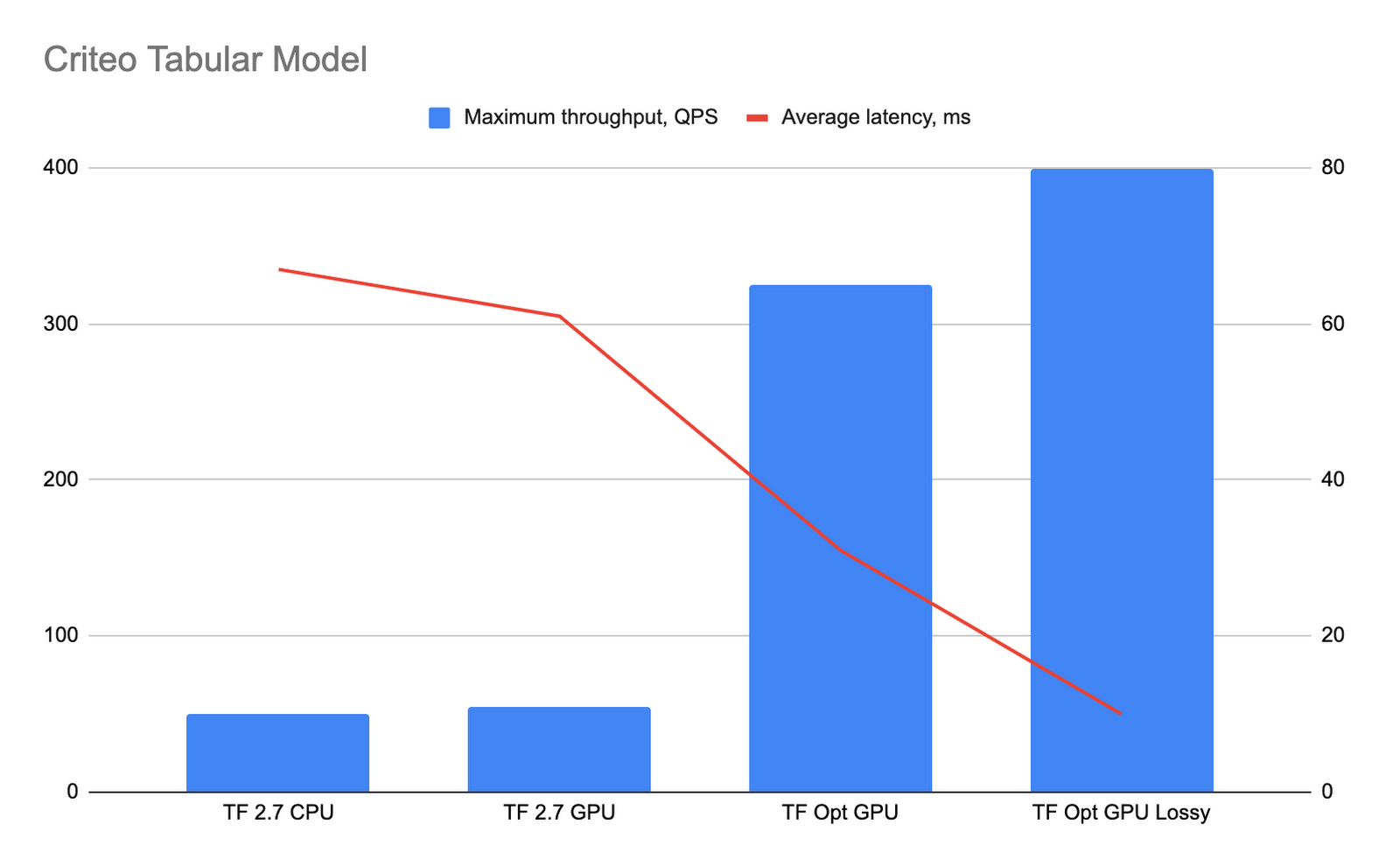
The optimized TensorFlow runtime resulted in significantly lower latency and higher throughput. Because the optimized TensorFlow runtime moves the majority of the computations to the GPU, machines with less CPU power can be used. These benchmark tests demonstrate that enabling the optional precision affecting optimizations (the “TF Opt GPU” lossy bar) significantly helps improve the model’s performance. We compared the results of predictions for 51,200 requests for a model running on the optimized TensorFlow runtime with lossy optimizations and a model running on TF2.7 containers. The average difference in precision in our results is less than 0.0016%, and in the worst case the precision difference is less than 0.05%.
Based on these results, for the tabular Criteo model the optimized TensorFlow runtime offers approximately 6.5 times better throughput and 2.1 times better latency compared to TensorFlow 2.7 CPU, and 8 times better throughput and 6.7 times better latency when precision affecting optimizations are enabled.
BERT base model performance testing
For benchmarking the BERT base model, we fine tuned the bert_en_uncased_L-12_H-768_A-12 classification model from TensorFlow Hub for sentiment analysis using the IMDB dataset. The benchmark was run using MLPerf loadgen on the public endpoint with requests of batch size 32.
The following graph shows the performance results. The “TF Opt GPU” bar shows the performance of the optimized TensorFlow runtime with precompilation enabled, and the “TF Opt GPU lossy” bar shows performance with both precompilation and precision affecting optimizations enabled.
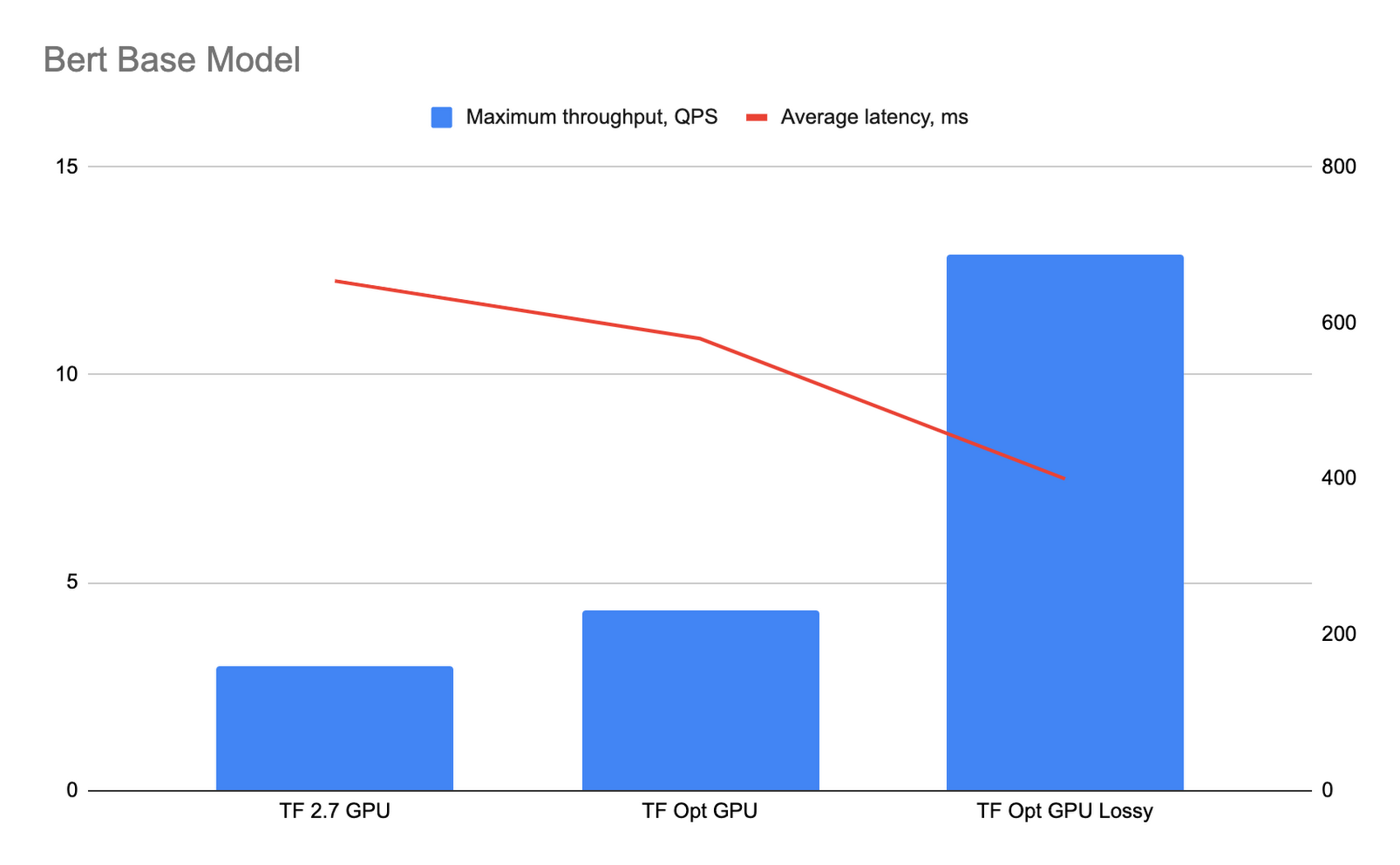
To determine the impact of precision affecting optimizations on the model precision, we compared the results of predictions for 32,000 requests for a model running on the optimized TensorFlow runtime with lossy optimizations with a model running on TF2.7 containers. The average difference in precision in our results is less than 0.01%, and in the worst case the precision difference is less than 1%.
For the BERT base model the optimized TensorFlow runtime offers approximately 1.45 times better throughput and 1.13 times better latency compared to TensorFlow 2.7, and 4.3 times better throughput and 1.64 times better latency when precision affecting optimizations are enabled.
What’s next
In this article you learned about the new optimized TensorFlow runtime and how to use it. If you’d like to reproduce the benchmark results, be sure to try out the Criteo and Bert samples, or check out the list of available images to start running some low latency experiments of your own!
Acknowledgements
A huge thank you to Cezary Myczka who made significant contributions in getting the benchmarking results, and Nikita Namjoshi for her work on this project.



