Filtering inappropriate content with the Cloud Vision API
Sara Robinson
Developer Advocate, Google Cloud Platform
You may know the Cloud Vision API for its face, object, and landmark detection, but you might not know that the Vision API can also detect inappropriate content in images using the same machine learning models that power Google SafeSearch. Since we announced the Google Cloud Vision API GA in April, we’ve seen over 100 million requests for SafeSearch detection.
Any application with user uploaded images can make use of inappropriate content detection. To get started with this feature, just add SAFE_SEARCH_DETECTION to your API request:
Instead of reviewing all user uploaded images manually, the Vision API’s SafeSearch detection feature flags inappropriate images automatically and returns very few “false positives” (images flagged as inappropriate with no explicit content).
Let’s see how this API method looks for and categorizes inappropriate content (using appropriate images, of course). For example, let’s run SafeSearch detection on this picture of avocado toast:

I get the following response:
For each of the four inappropriate content types (spoof, medical, adult, and violence) the API returns one of five possible likelihood values: “VERY_UNLIKELY”, “UNLIKELY”, “POSSIBLE”, “LIKELY”, or “VERY_LIKELY”. Using these likelihood values, you can decide which subset of images require manual review for your app. For example, you might want to manually review only images that the API identifies as “POSSIBLE” and above.
Unsurprisingly, the API response does not give my avocado toast high chances of containing spoof, medical, adult, or violent content. Among the four labels, medical has the highest score due to the close-up nature of the image. If any of these four categories indicated a higher likelihood, it would be easy to flag the image.
The Vision API SafeSearch detection feature uses a deep neural network model specifically trained to classify inappropriate content in images. It computes a score on a 0 to 1 scale for each vertical, and based on that score applies the corresponding likelihood as a string.
What exactly is the API looking for in each SafeSearch category? I chatted with Nikola Todorovic, an engineer on the SafeSearch models, to find out the details. Let’s take a closer look at each part of the API response:
Adult
The adult content classifier is trained to separate pornographic and non-pornographic images. For example, photos of people in swimsuits without nudity are labeled by the API as UNLIKELY or VERY_UNLIKELY. On the other hand, sexual intercourse, nudity and adult content in cartoon images, like hentai, typically gets LIKELY or VERY_LIKELY labels. This classification can be useful in the following scenarios:- When you want to be absolutely certain you’ve removed all inappropriate content (high recall)
- When you want to be sure to only remove offensive images (high precision)
The classifier is trained not to flag pictures that contain nudity in a medical, scientific, educational, or artistic context. In addition, the classifier is quite effective in correctly classifying swimsuit and lingerie photos as non-pornographic; despite the skin showing, Cloud Vision is able to detect that the “strategic” parts are covered.
The SafeSearch engineering team has built a debug tool to analyze image classifications and better understand the deep neural networks powering the detection model. Using the internal neural network activations and backpropagation gradients, this tool imposes a heatmap on the image, indicating the parts that the classifier identified as possibly explicit. In the following heatmap, the final classification (VERY_UNLIKELY) is mostly influenced by the highlighted swimsuit area:

Violence
Images flagged as violent include pictures depicting killing, shooting, or blood and gore. Let’s take a look at a few examples.Simple images of knives or guns won’t be labeled as violent. For the following image, the API returns UNLIKELY:

This image on the other hand, is flagged as POSSIBLE:

Running the image above through the heatmap debugging tool, the following heatmap shows us which parts of the image cause the API to return POSSIBLE for violence:

This indicates that the model has detected soldiers in the photo. In addition, the pointed rifle will also impact the classification.
Medical
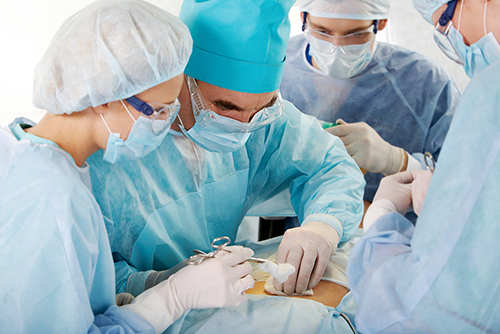
Images flagged as medical content contain explicit images of surgery, diseases, or body parts. A before-and-after picture of hand or face surgery, or a picture depicting an operating room with no close-ups of the patient would not be flagged by the API. The medical classifier looks primarily for graphic photographs of open wounds, genital close-ups, and egregious disease symptoms.Although the following image clearly depicts a medical procedure, it is labeled as UNLIKELY by the Vision API since there’s nothing inappropriate or shocking about it:
Spoof
The spoof detection classifier primarily looks for memes, which are indicated by the presence of text, typical meme faces, and backgrounds.The following meme returns a spoof likelihood of VERY_LIKELY:

Looking at the heatmap, we can see that the spoof classifier clearly identified the combination of the face and text as the spoofed part of this image:





{kind=link}