클라우드 위 구름(cloud): Google Cloud에서 기상 예측
Joe Schoonover
Founder & Director of Operations, Fluid Numerics
Wyatt Gorman
Solutions Manager, HPC & AI Infrastructure, Google Cloud
* 본 아티클의 원문은 2022년 3월 29일 Google Cloud 블로그(영문)에 게재되었습니다.
기상 예측과 기후 모델링은 세상에서 가장 복잡한 컴퓨팅이 요구되는 까다로운 작업에 해당합니다. 특히 시간에 매우 민감하고 수요가 높습니다. 주말 나들이객부터 대규모 산업형 농장 운영자에 이르기까지 모두가 최신의 기상 예측 정보를 원합니다. 기상 예보관은 의미 있는 예측을 적시에 제공하기 위해 일반적으로 온프레미스 데이터 센터에 호스팅된 고성능 컴퓨팅(HPC) 클러스터를 이용합니다. 이 온프렘 HPC 시스템은 막대한 자본을 투자해야 하고 장기간 많은 운영비가 발생합니다. 전력 소모가 심하고 구성의 대부분이 고정적이며 기본 컴퓨터 하드웨어의 교체 주기 역시 경직되어 있습니다.
클라우드를 이용할 경우 유연성 향상, 지속적인 하드웨어 업그레이드, 높은 안정성, 지리적으로 분산된 컴퓨팅과 네트워킹, '사용한 만큼 비용을 지불하는' 가격 모델 등 다양한 이점을 누릴 수 있습니다. 그 결과 클라우드 컴퓨팅을 이용하는 기상 예보관과 기후 모델러는 최신 하드웨어 및 소프트웨어 시스템을 사용하는 유연한 플랫폼에서 비용 효율적인 방식으로 정확한 결과를 시의적절하게 제공할 수 있게 됩니다. 이러한 접근은 기존의 기상 예측 방식과 크게 다르기 때문에 어려워 보일 수 있습니다. 이제 기상 예보관은 Google Cloud에서 Fluid Numerics의 새로운 WRF VM 이미지를 사용하여 손쉽게 WRF(Weather Research and Forecasting)를 실행하고 저렴한 비용으로 온프레미스 슈퍼 컴퓨터의 성능을 구현하는 데 도움을 얻을 수 있습니다. 이 솔루션을 사용하면 기상 예보관이 Google Cloud에서 WRF 시뮬레이션을 준비하고 실행하는 데 1시간이 채 걸리지 않습니다.
WRF 자세히 살펴보기
WRF(Weather Research and Forecasting)는 연구원과 운영 조직 모두 활발히 사용하는 오픈소스 기반의 수치형 기상 예측 모델링 시스템입니다. WRF가 주로 기상 및 기후 시뮬레이션에 사용되지만 화학적 상호작용, 산불 모델링 등 다양한 사용 사례를 지원하도록 WRF의 기능을 확장했습니다. WRF 개발은 1990년대 후반 미국 국립 대기 연구 센터(NCAR), 미국 해양대기청(NOAA), 미국 공군 및 해군 연구소(U.S. Air Force, Naval Research Laboratory), 오클라호마 대학교, 연방항공국의 협업을 통해 시작되었습니다. WRF 커뮤니티는 대기 연구와 운영 예측을 지원한다는 공동의 목표 아래 160여 개국의 48,000명이 넘는 사용자로 구성되어 있습니다.
Google Cloud WRF 이미지는 Google의 HPC 관련 MPI 권장사항을 토대로 빌드되지만 예외적으로 하이퍼스레딩이 기본적으로 사용 중지되고, Google Cloud에서 SchedMD의 Slurm-GCP 등의 다른 HPC 솔루션과 손쉽게 통합됩니다. 일반적으로 WRF 및 관련 종속 항목을 설치하는 데는 많은 시간이 소요됩니다. 새로운 WRF VM 이미지를 이용하면 WRF v4.2가 사전 설치된 확장 가능한 HPC 클러스터를 Codelab을 통해 빠르고 쉽게 배포할 수 있습니다. 이전에는 이 작업 전반에서 OpenMPI 4.0.2를 사용했습니다. Google은 Intel MPI로 성공적인 결과를 얻었으며 이 사례에서 추가적인 성능 개선의 여지가 있는지 조사하고자 합니다.
WRF 최적화
WRF 이미지 개발 과정에서 핵심은 성능과 비용을 고려하여 최적의 아키텍처와 빌드 설정을 결정하는 것이었습니다. Google이 이상적인 컴파일러와 적절한 CPU 플랫폼, 파일 IO 처리에 가장 적합한 파일 시스템을 선택하는 방법을 평가했으므로 이제 고객은 그럴 필요가 없습니다. 성능 평가의 테스트 사례로는 CONUS 2.5km 벤치마크를 사용했습니다.
아래의 CONUS 2.5km 런타임 및 비용 그림은 Google Cloud에서 사용 가능한 다양한 머신 유형을 대상으로 (수치화 프로세스를 통해) 480개 MPI 랭크를 사용한 2시간 예측에서 WRF를 시뮬레이션하는 데 필요한 런타임을 보여줍니다. 머신 유형별로 컴파일러, 컴파일러 최적화, 작업 어피니티를 달리 하여 여러 테스트를 진행하고 여기서 측정된 최저 런타임을 보여줍니다.
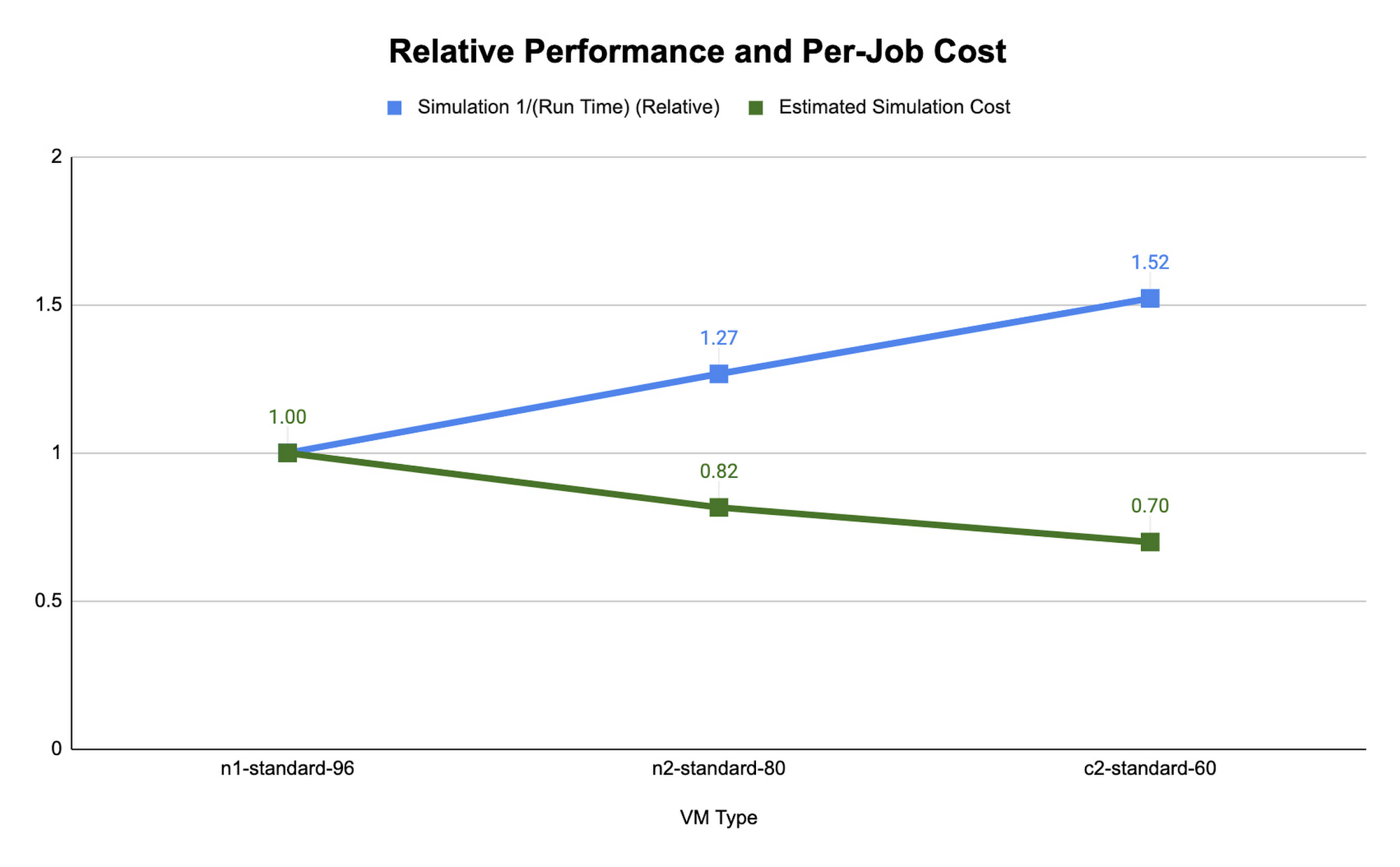
컴퓨팅 최적화된 c2 인스턴스의 런타임이 가장 짧은 것으로 확인되었습니다. Slurm 작업 스케줄러를 사용하면 작업 어피니티 플래그를 사용하여 컴퓨팅 하드웨어에 MPI 작업을 매핑할 수 있습니다. 각 머신 유형의 런타임과 비용을 최적화할 때는 WRF 실행을 위해 각 MPI 프로세스를 실제 코어(MPI 랭크당 vCPU 2개)에 매핑하는 srun –map-by core –bind-to core와 각 MPI 프로세스를 vCPU 1개에 매핑하는 srun –map-by thread –bind-to thread를 사용하는 사례를 비교했습니다. 코어별로 매핑하고 MPI 랭크를 코어에 바인딩하는 것은 하이퍼스레딩을 사용 중지하는 것과 유사합니다.
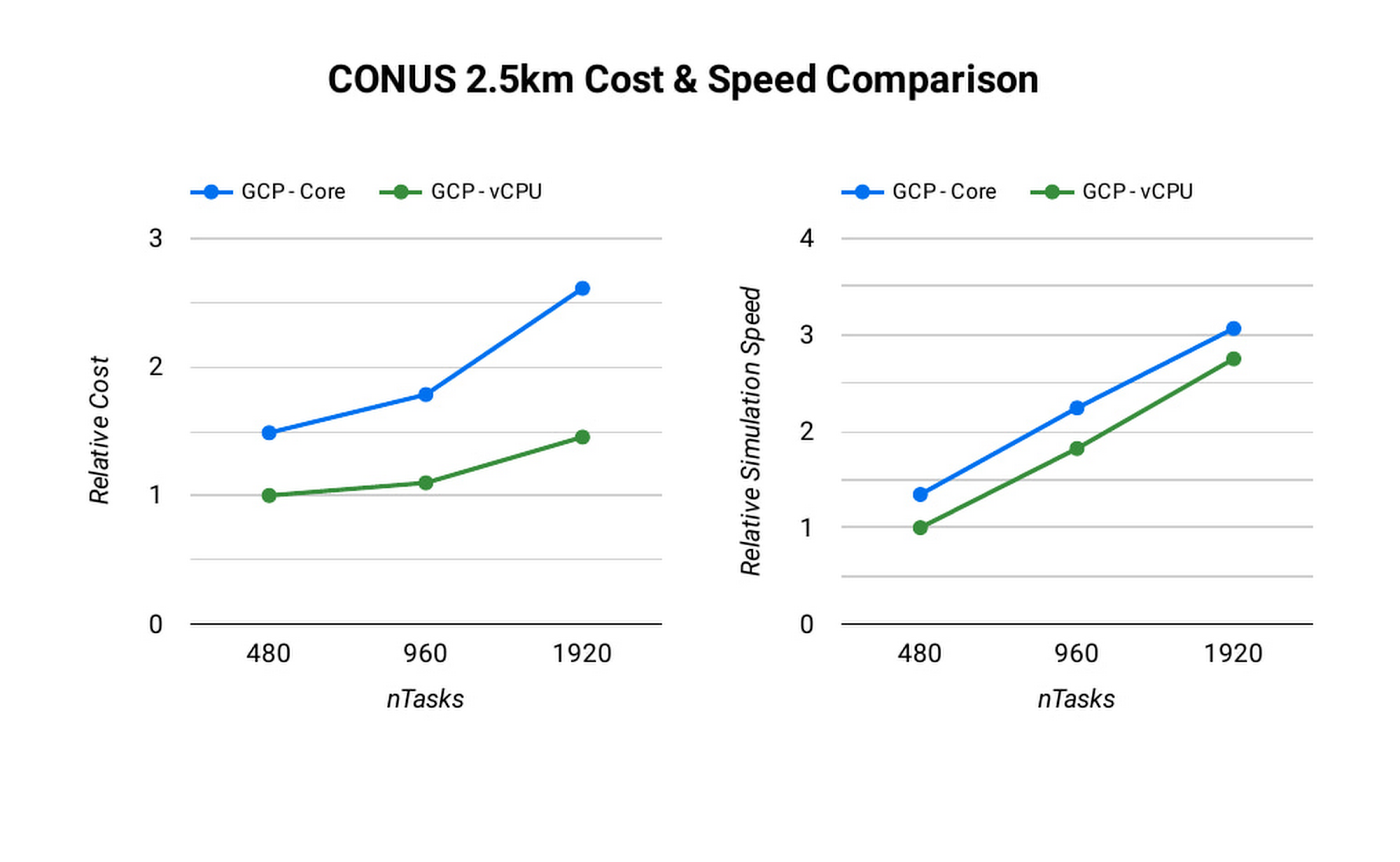
각 플랫폼에서 CONUS 2.5km의 시뮬레이션 비용과 런타임이 가장 이상적인 경우는 각 MPI 랭크가 각 vCPU에 구독될 때입니다. vCPU에 바인딩하는 경우 필요한 컴퓨팅 리소스가 실제 코어에 바인딩할 때의 절반에 불과하므로 시뮬레이션의 초당 비용이 줄어듭니다. CONUS 2.5km의 경우, MPI 랭크를 코어에 매핑하면 동일한 수의 MPI 랭크에 대해 런타임이 감소하는 결과가 나타났지만 성능상의 이점이 비용 절감 효과를 능가할 만큼 크지는 않습니다. 이런 이유로 WRF-GCP 솔루션은 기본적으로 하이퍼스레딩을 사용 중지하지 않습니다.
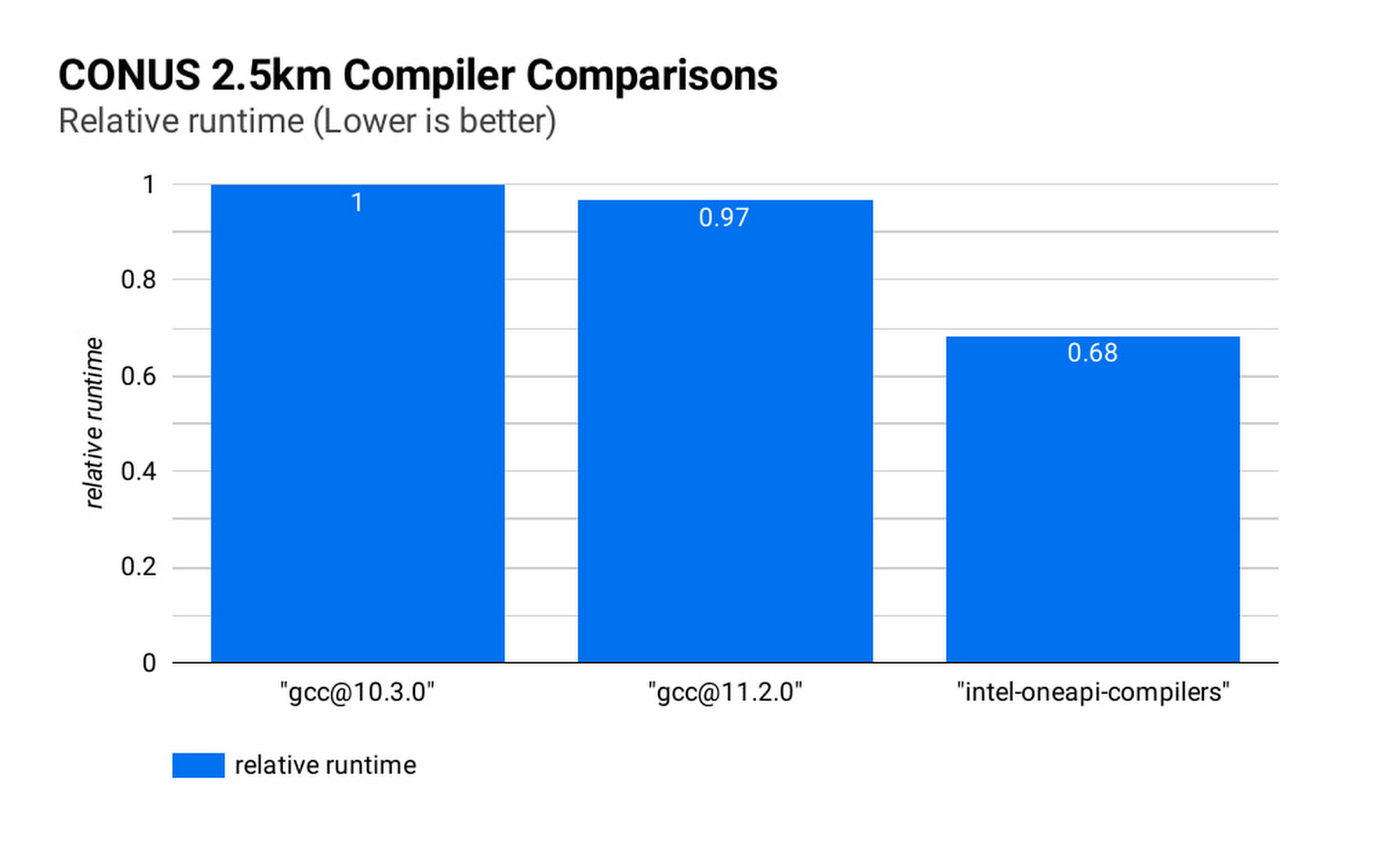
이상적인 컴파일러를 선택하면 런타임과 시뮬레이션 비용을 더욱 절감할 수 있습니다. 아래 그림(CONUS 2.5km 컴파일러 비교)은 GCC 10.30, GCC 11.2.0, Intel® OneAPI® 컴파일러(v2021.2.0)를 사용하여 8개 c2-standard-60 인스턴스에 대해 실행한 WRF CONUS 2.5km 벤치마크에 대한 시뮬레이션 런타임을 보여줍니다. 어떤 방식을 사용하든 WRF는 수준 3 컴파일러 최적화와 Cascade Lake 대상 아키텍처 플래그를 사용하여 빌드됩니다. WRF를 Intel® OneAPI® 컴파일러로 컴파일하면 WRF 시뮬레이션 속도가 GCC 빌드보다 47% 더 빨라지므로 동일한 하드웨어에서 약 68%의 비용으로 실행할 수 있습니다. 이 작업에는 MPI 구현으로 각 컴파일러와 함께 OpenMPI 4.0.2가 사용되었습니다. 다른 애플리케이션의 경우 Intel MPI 2018에서 양호한 성능이 확인되었으므로 이 구현과 다른 MPI 구현에서 성능을 비교하는 조사를 실시하려고 합니다.
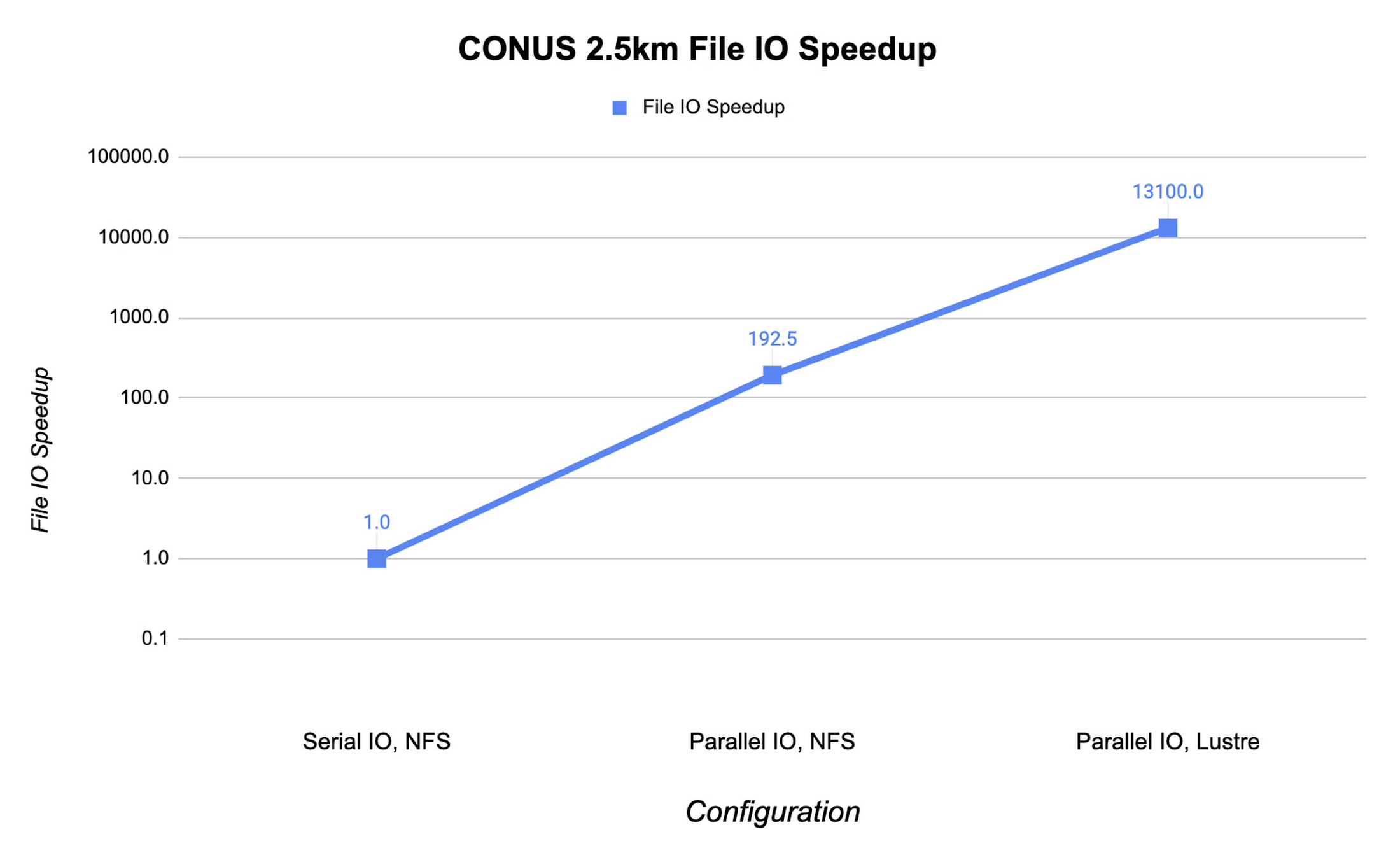
MPI 랭크 수가 증가하면 WRF의 파일 IO가 심각한 병목 현상을 유발할 수 있습니다. 최적의 파일 IO 성능을 얻으려면 WRF에서 병렬 파일 IO를 사용하고 Lustre와 같은 병렬 파일 시스템을 이용해야 합니다.
아래에서는 파일 IO 활동의 속도 향상을 NFS 파일 시스템의 직렬 IO와 비교하여 보여줍니다. 이 예에서는 MPI 랭크 수가 960개인 조건에서 c2-standard-60 인스턴스에 대해 CONUS 2.5km 벤치마크를 실행합니다. WRF의 파일 IO 전략을 병렬 IO로 변경할 경우 파일 IO 시간이 60배 빨라집니다.
또한 Fluid Numerics의 오픈소스 Lustre Terraform 코드형 인프라에서 배포된 Lustre 병렬 파일 시스템을 사용하여 IO 속도를 높이고 시뮬레이션 비용을 절감합니다. Lustre는 Google Cloud Marketplace의 DDN EXAScaler 솔루션 지원을 통해서도 이용할 수 있습니다. 이 경우 Lustre OSS(Object Storage Service) 인스턴스에 4개의 n2-standard-16 인스턴스를 사용하고 각 로컬 SSD는 3TB입니다. Lustre MDS(Metadata Server)는 n2-standard-16 인스턴스이고 1TB의 PD-SSD 디스크를 사용합니다. Lustre 파일 시스템을 클러스터에 마운트한 후 파일 IO가 4개 OSS 인스턴스에 분산될 수 있도록 Lustre 스트라이프 수를 4로 설정합니다. IO에 대해 Lustre 파일 시스템을 사용하도록 전환하여 파일 IO를 193배 가속화합니다. 이는 직렬 IO를 지원하는 1개 NFS 서버보다 몇 배 더 빠른 수치입니다.
컴퓨팅 리소스를 추가하고 MPI 랭크 수를 늘리면 시뮬레이션 실행 시간이 줄어듭니다. 이상적으로는 완벽한 선형 확장으로 MPI 랭크 수를 두 배로 늘리면 시뮬레이션 시간이 절반으로 단축되게 됩니다. 하지만 MPI 랭크를 추가하면 통신 오버헤드가 늘어나므로 시뮬레이션당 비용이 증가할 수 있습니다. 통신 오버헤드는 문제를 더 많은 머신에 골고루 분산하기 위해 필요한 통신의 양이 늘어나기 때문에 발생합니다.
MPI 랭크 수를 순차적으로 두 배씩 늘려 일련의 모델 예측을 실행하는 방법으로 CONUS 2.5km 벤치마크에 대해 WRF의 확장성을 평가할 수 있습니다. 아래에는 MPI 랭크 수를 480개에서 1,920개로 변경하면서 Lustre 파일 시스템을 사용하여 c2-standard-60 인스턴스에 대해 실행한 2시간 예측이 나와 있습니다. 이 모든 실행에서는 MPI 랭크 수가 증가함에 따라 각 시뮬레이션의 전용 vCPU 수도 증가하도록 MPI 랭크가 vCPU에 결속되어 있습니다. 많은 HPC 워크로드는 동시 멀티스레딩(SMT)이 사용 중지된 상태에서 실행하는 것이 가장 좋지만 CONUS 2.5km의 경우에는 SMT를 사용 설정한 상태에서 성능이 가장 우수한 것으로 확인됩니다. 따라서 본 실행에서는 MPI 랭크 수가 vCPU의 총 수와 동일합니다.
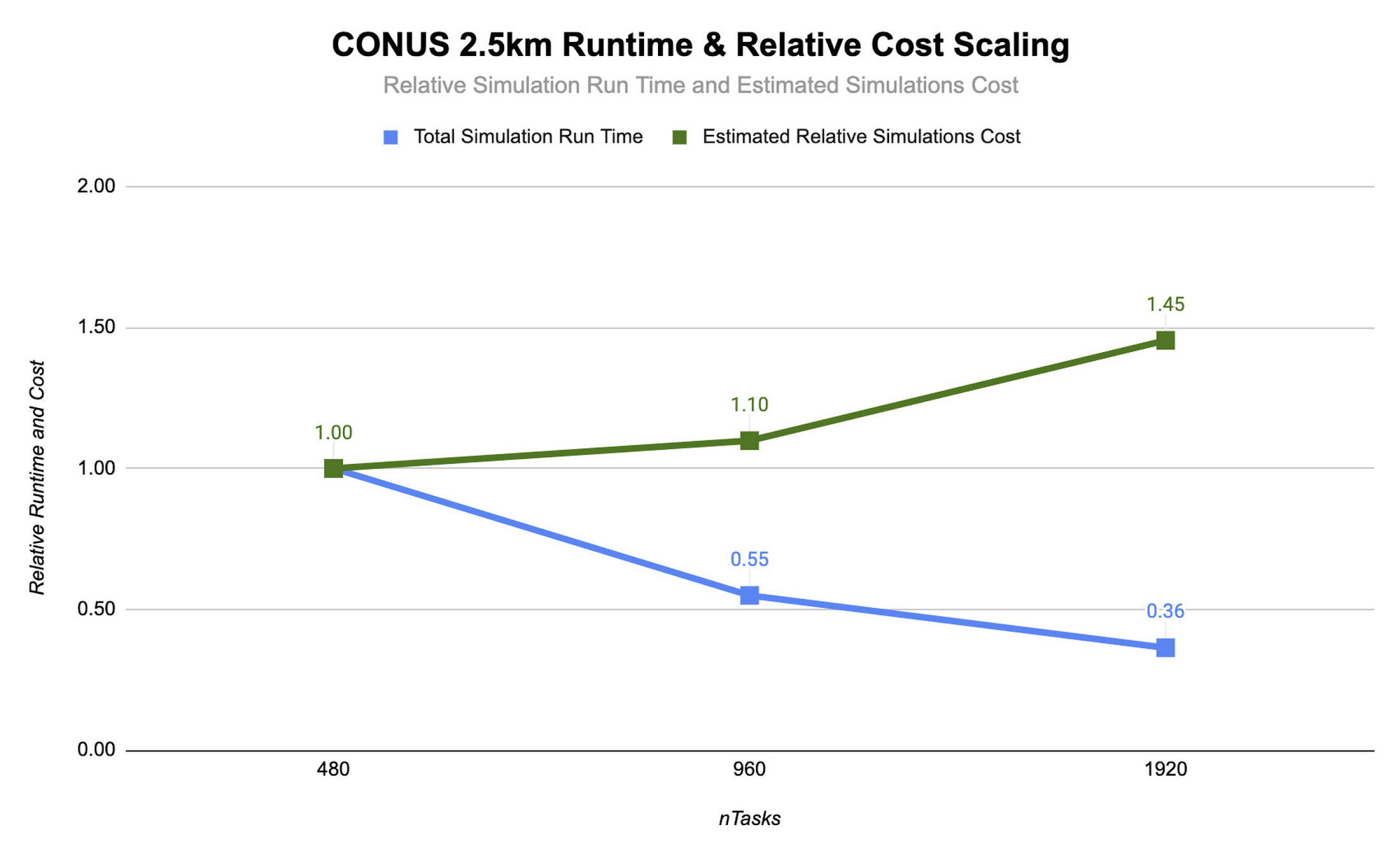
여기에 나와 있는 CONUS 2.5km 런타임 및 비용 확장 그림에서는 MPI 랭크 수와 컴퓨팅 리소스 양이 최소한 1,920개 랭크까지 증가하는 과정에서는 런타임(파란색 막대)이 감소한다는 것을 알 수 있습니다. MPI 랭크를 480개에서 960개로 전환하면 런타임이 줄고 속도가 약 1.8배 빨라집니다. 1,920개 MPI 랭크로 다시 두 배로 늘린 경우에는 속도가 추가적으로 1.5배 증가하는 데 그쳤습니다. 이렇게 MPI 랭크 증가 대비 속도 증가분이 줄어드는 추세를 통해 MPI 랭크가 증가할수록 MPI 오버헤드가 커지는 것을 알 수 있습니다.
최적의 사례 결정
WRF와 같이 긴밀하게 결합되는 대부분의 MPI 애플리케이션에서 이러한 확장 동작이 나타나며 MPI 랭크가 증가할수록 확장 효율성은 감소합니다. 따라서 총 소유 비용(TCO)을 고려할 때는 성능 대비 확장과 더불어 비용 대비 확장을 평가해야 합니다. 다행히 Google Cloud에서는 초 단위로 요금이 청구되므로 이러한 분석을 더 쉽게 수행할 수 있습니다. 위 그림과 같이 두 번째로 코어 수를 두 배를 늘린 경우인 960개에서 1,920개로 늘린 경우에는 속도가 1.5배 더 빨라지지만 비용도 32% 증가합니다. 상황에 따라 추가 비용을 감수할 만큼 이러한 빠른 처리가 필요한 경우가 있을 수 있습니다.
WRF를 빠르게 시작하고 CONUS 2.5km 벤치마크를 실험하고 싶은 고객을 위해 Google은 이 배포를 Terraform 스크립트로 캡슐화하고 관련 Codelab도 마련했습니다.
Google Cloud의 고성능 컴퓨팅 서비스에 대한 자세한 내용은 https://cloud.google.com/hpc에서 확인할 수 있으며 Google 파트너 Fluid Numerics에 대한 자세한 내용은 https://www.fluidnumerics.com을 참조하세요.