멀티슬라이스를 사용하여 AI 학습을 최대 수만 개의 Cloud TPU 칩으로 확장하는 방법
Nisha Mariam Johnson
Product Manager
Andi Gavrilescu
Software Engineering Manager
가장 큰 규모의 생성형 AI 모델은 수천억 개 이상의 파라미터와 수조 개의 토큰을 사용하여 학습합니다. 이러한 모델의 경우 학습 을 몇 주 이내로 완료하기 위해서는 수십 EFLOPS(10^18FLOPS)의 AI 슈퍼컴퓨팅이 필요합니다. 이 성능을 달성하기 위해서는 수만 개의 가속기가 병렬적으로 작동해야 합니다. 그러나 대부분의 대규모 분산학습 솔루션에는 정교한 코딩과 튜닝 등의 수작업이 요구되어, 범용적이지 못하며 학습 성능을 선형적으로 향상시키기 어렵게 만듭니다.
Google Cloud는 이 문제를 해결하기 위해 이번 주 Google Cloud Next에서 멀티슬라이스 기술을 발표했습니다. 멀티슬라이스는 최대 수만 개의 Cloud 텐서 처리 장치(TPU) 칩에 걸쳐 모델 학습을 쉽고 비용 효율적으로 확장할 수 있게 해주는 풀 스택 대규모 학습 기술입니다. 지금까지는 모델 학습시 칩 간 상호 연결(ICI)을 통해 연결되는 TPU 칩들의 묶음인 슬라이스를 최대 하나만 사용할 수 있었습니다. 이는 한 개의 슬라이스 내에 연결가능한 최대 TPU v4 칩은 3,072개 이므로 Cloud TPU를 이용한 분산 학습시 한번에 활용가능한 최대 칩 수는 3,072개 였음을 의미합니다. 그러나멀티슬라이스를 활용하면 Cloud TPU를 이용한 분산 학습 시 한 번에 두 개 이상의 슬라이스를 병렬적으로 연결할 수 있습니다. 이 때 서로 다른 포드에 위치하는 슬라이스 간에는 데이터 센터 네크워킹(DCN)을 통해 통신합니다.
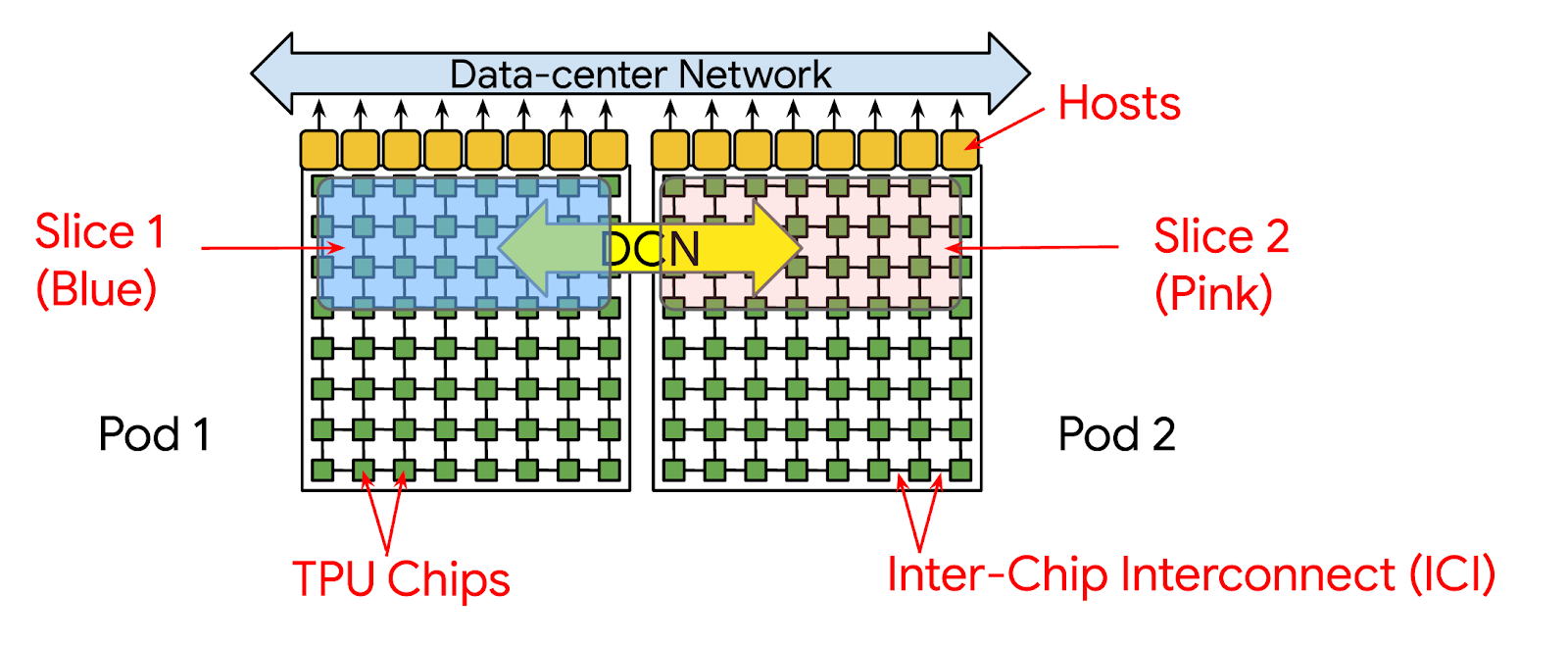
한 포드의 슬라이스가 멀티슬라이스 구성을 통해 다른 포드의 슬라이스와 통신합니다.
요약하면, 멀티슬라이스는 다음과 같은 이점을 제공할 수 있습니다.
- 단일 슬라이스에서 최대 수만 개의 칩이 포함된 다중 슬라이스까지 선형에 가까운 성능 확장 으로 대규모 모델 학습 용이
- 코드를 거의 수정하지 않고 간단한 설정으로 개발자 생산성 향상
- 자동 컴파일러 최적화를 활용하여 시간 절약
- TPU v4에 비해 LLM 학습에 최대 2배 더 높은 가격 대비 성능을 제공하는 TPU v5e를 통해 비용 효율성 극대화
- TPU v5e 및 TPU v4를 각각 사용하는 8칩 ICI 도메인 시스템에 비해 최대 2~24배 더 높은 피크 FLOPS 예산에 액세스
“멀티슬라이스 Cloud TPU v5e를 포함한 Google Cloud의 차세대 AI 인프라는 가격 대비 성능 측면에서 자사 워크로드에 놀라운 이점을 제공할 것입니다. 향후 Google Cloud에서 차세대 AI를 구축하게 되기를 기대합니다.”—Tom Brown, Co-Founder, Anthropic
멀티슬라이스의 작동 방식
멀티슬라이스 구성으로 배포되는 경우 각 슬라이스 내의 TPU 칩은 고속 ICI를 통해 통신합니다. 또한 서로 다른 슬라이스 내의 TPU 칩들은 Google Cloud의 Jupiter 데이터 센터 네트워크를 통해 통신합니다. 예를 들어 Data Parallelism 학습 시 Activation 값들은 단일 슬라이스 내에서의 통신인 ICI를 통해 계속 전달되지만 경사하강은 DCN을 통해 일어납니다.
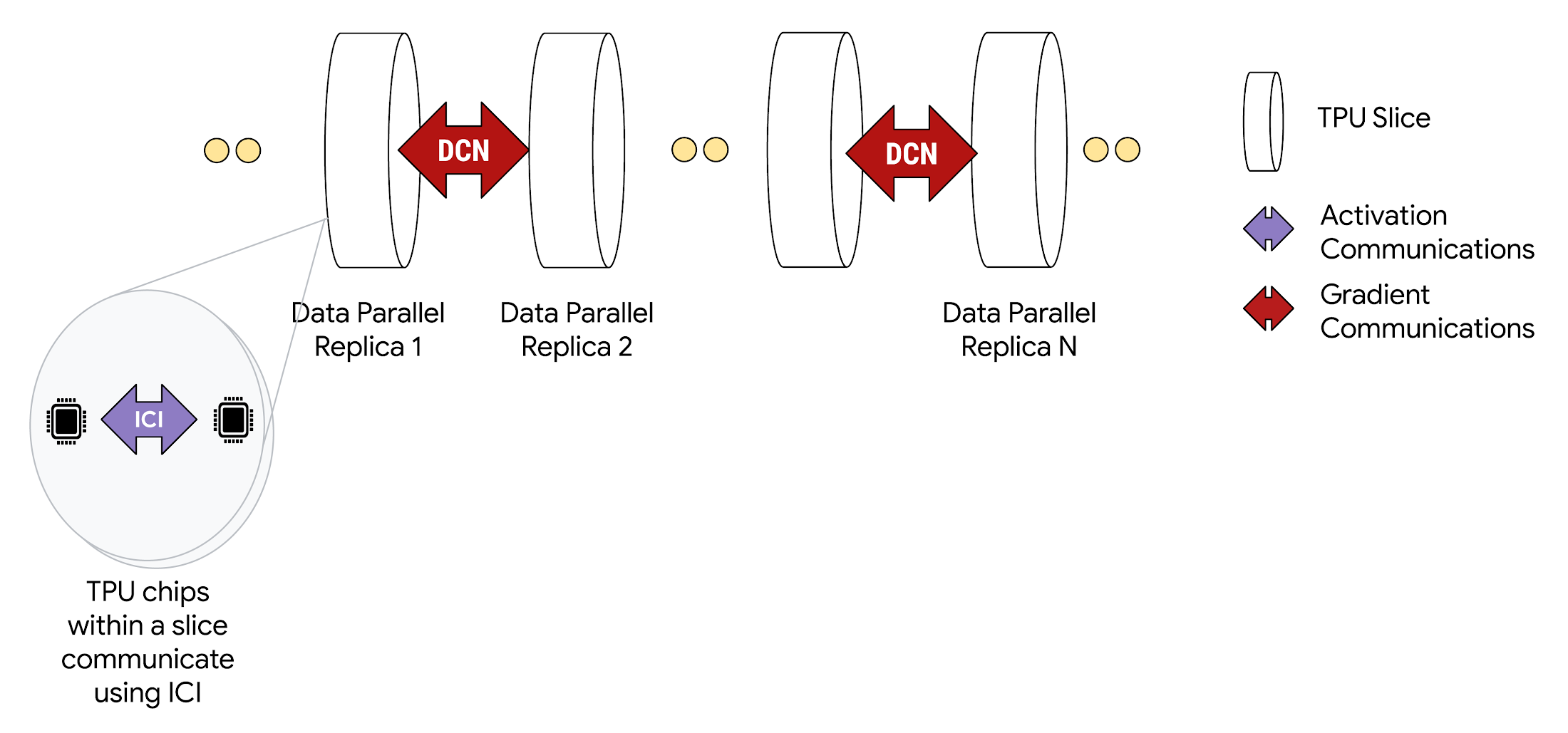
멀티슬라이스를 사용한 Data Parallelism
멀티슬라이스 기술은 단일 포드 내 슬라이스간 연결과 서로 다른 포드 내 슬라이스간의 연결을 모두 지원하여 다양한 병렬화 기법에 적용할 수 있습니다. Dense Decoder와 Diffusion Model을 포함한 대부분의 모델 학습에는 Data Parallelism(DP)만으로 충분하지만, 그 이상의 거대 모델이나 대규모 데이터를 위해 멀티슬라이스에서는 Fully Sharded Data Parallelism(FSDP), Model Parallelism(MP), Pipeline Parallelism(PP)까지 모두 도 지원합니다. 고급 최적화 및 샤딩 전략에 대한 더 자세한 내용은 멀티슬라이스 사용자 가이드를 참조하세요.
개발자는 슬라이스 간 DCN 통신을 위해 추가적인 코드를 작성할 필요가 없습니다. XLA 컴파일러가 최대 성능을 위한 코드 변환 및 최적화를 자동으로 수행해줍니다.
2배 이상 더 높은 시스템 규모 달성
소프트웨어의 확장은 하드웨어에 의해 제한됩니다. 가속기에서 구동되는 소프트웨어 시스템은 FLOPS 예산까지만 확장이 가능합니다. 그 이상의 확장은 통신 병목 현상으로 인해 성능이 제한됩니다. 즉, 효과적인 확장을 위해서는 하드웨어 시스템 자체가 확장을 지원해야 합니다. Cloud TPU 시스템의 대규모 ICI 도메인은 통신 병목 현상 없이 8칩 ICI 도메인을 사용하는 기존 시스템보다 최대 24배 더 높은 최대 FLOPS를 달성하는 데 도움이 됩니다.
이것을 더 잘 이해하려면 ICI 도메인의 개념을 이해해야합니다. 하드웨어 가속기에서 고속 ICI로 연결할 수 있는 최대 칩 수를ICI 도메인이라고 합니다. TPU v4 포드의 ICI 도메인은 3,072칩이고, TPU v5e 포드의 경우에는 256칩 입니다.
P를 확장할 수 있는 최대 FLOPS로 정의해 보겠습니다. DP 및 FSDP를 사용하는 Dense LLM의 ICI 도메인 당 최소 배치 크기는 DCN의 Arithmetic Intensity와 같습니다. 이러한 모델의 경우 DCN의 Arithmetic Intensity는 칩당 DCN 대역폭에 대한 칩당 FLOPS의 비율로 근사할 수 있습니다. 그러면 P는 다음과 같습니다.
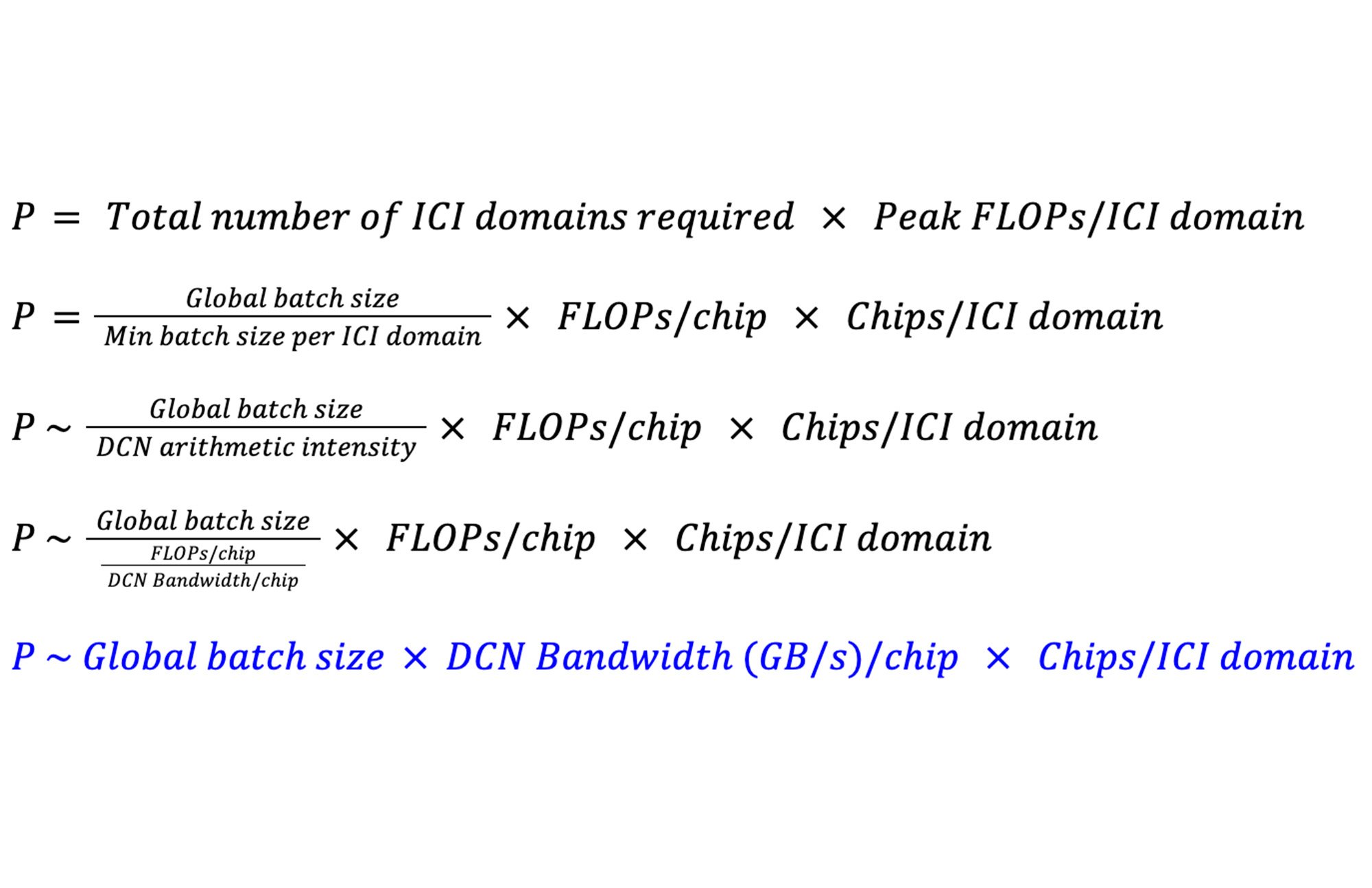
이는 총 피크 FLOPS 관점에서 시스템의 최대 규모는 칩당 사용 가능한 DCN 대역폭, ICI 도메인의 크기 및 글로벌 배치 크기에 의해 결정된다는 것을 보여줍니다.
통신 병목 현상이 없는 상황에서 ICI 도메인 크기가 시스템의 최대 규모에 미치는 영향을 알아보기 위해 모델을 32M 크기의 전역배치로 학습하는 시스템들의 예시를 살펴보겠습니다.
기본적으로 8칩 ICI 도메인이 있는 시스템이 기존의 고속 DCN 기술을 사용하여 400Gbps/칩의 속도로 DCN을 통해 통신한다고 가정해 보겠습니다.

여기서 이 시스템이 성능 저하 없이 실현할 수 있는 가장 높은 총 피크 FLOPS는 P8 = 12.8 EFLOPS 입니다.
TPU 포드는 더 높은 ICI 도메인 값을 가지므로 DCN을 통해 전송되는 바이트당 Arithmetic Intensity를 증가시킬 수 있습니다. ICI 도메인당 256칩과 칩당 25Gbps의 DCN 대역폭을 갖춘 TPU v5e 포드의 경우 P256 = 25.6 EFLOPS 입니다.

ICI 도메인당 3,027칩과 칩당 25Gbps의 DCN 대역폭을 갖춘 TPU v4 포드의 경우 P3072 = 307.2 EFLOPS 입니다.
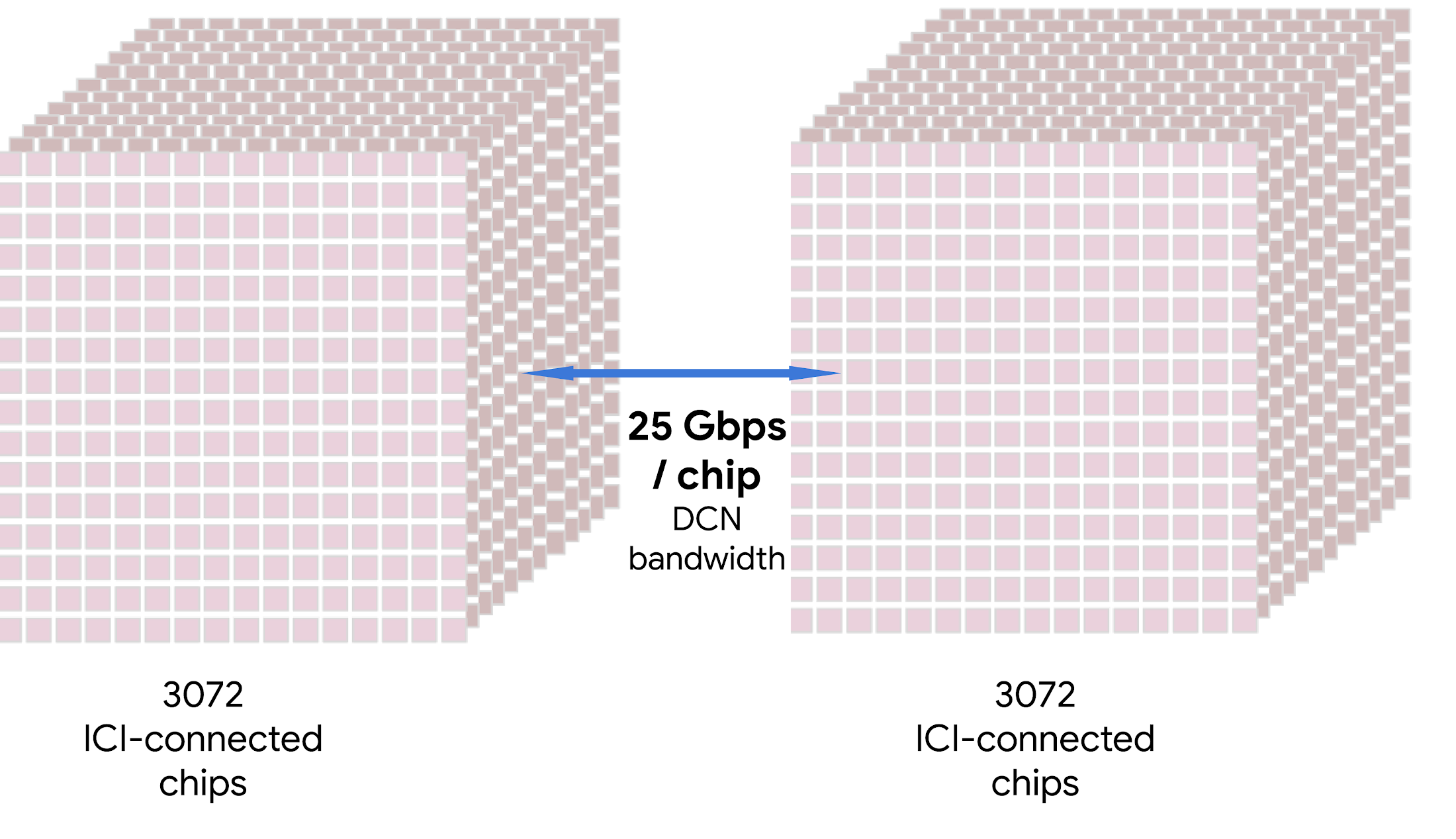
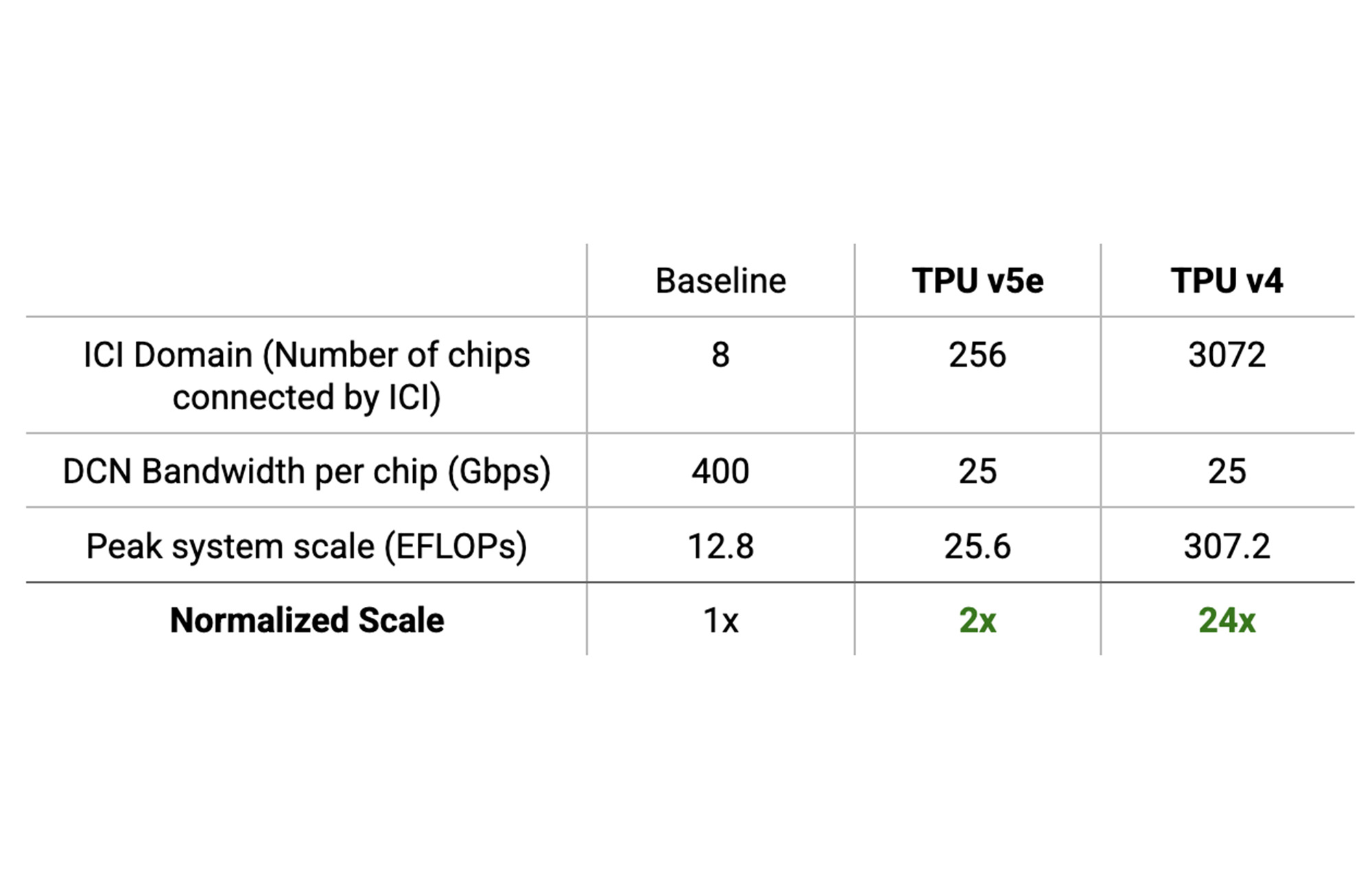
따라서, TPU v5e 시스템과 TPU v4 시스템은 8칩 ICI 도메인 및 칩당 400Gbps의 DCN 대역폭을 갖춘 시스템에 비해 각각 최대 2배, 24배 더 큰 규모를 달성할 수 있게 해줍니다.
“Google DeepMind 및 Research는 멀티슬라이스 구성을 활용하여—TPU v4와 비슷한 탁월한 확장 효율성으로—수천 개의 TPU v5e 칩 위에서 LLM 사용 사례를 위한 모델을 포함한 여러번의 모델 학습을 성공적으로 수행했습니다. ”—Jeff Dean, Chief Scientist, Google
TPU v5e의 경우 최대 수만 개의 칩까지 선형에 가깝게 확장
멀티슬라이스 성능을 단일 슬라이스 성능과 비교하기 위해, 피크 FLOPS에서 작동하는 시스템의 이론상 최대 처리량 대비 관측된 처리량(초당 토큰 수)의 비율로 정의되는 지표인 Model FLOPS Utilization (MFU)을 사용할 수 있습니다.
멀티슬라이스 구성으로 다중 슬라이스를 사용하는 TPU 학습 시에도 컴파일러 최적화를 통해 단일 슬라이스를 사용하는 학습 시와 동일한 MFU Rate을 달성할 수 있습니다. 다음은 몇 가지 예입니다.
- 역전파와 중첩되는 FSDP의 경사 감소
- 통신 토폴로지를 기반으로 기존 집합체를 해체하는 특수 계층 구조 집합체
또한 다른 가속기와 달리 TPU 칩은 스로틀링 없이 피크 FLOPS를 유지할 수 있으므로 더 높은 FLOPS와 MFU Rate을 달성할 수 있습니다.
멀티슬라이스 구성을 통해 수천억 개의 파라미터로 구성된 생성형 AI 모델을 학습시킬 수 있으며, TPU v4에서 수십억 개의 파라미터를 갖는 모델 학습 시 최대 58.9% MFU를 보여줍니다.
사용되는 포드 수가 증가함에 따라 배치 크기가 증가하는 현상을 의미하는 약한 확장(Weak Scaling) 으로 TPU v5e1에서 GPT-3 175B의 학습 성능을 측정한 결과, 선형에 가까운 성능 확장 추세를 보입니다.
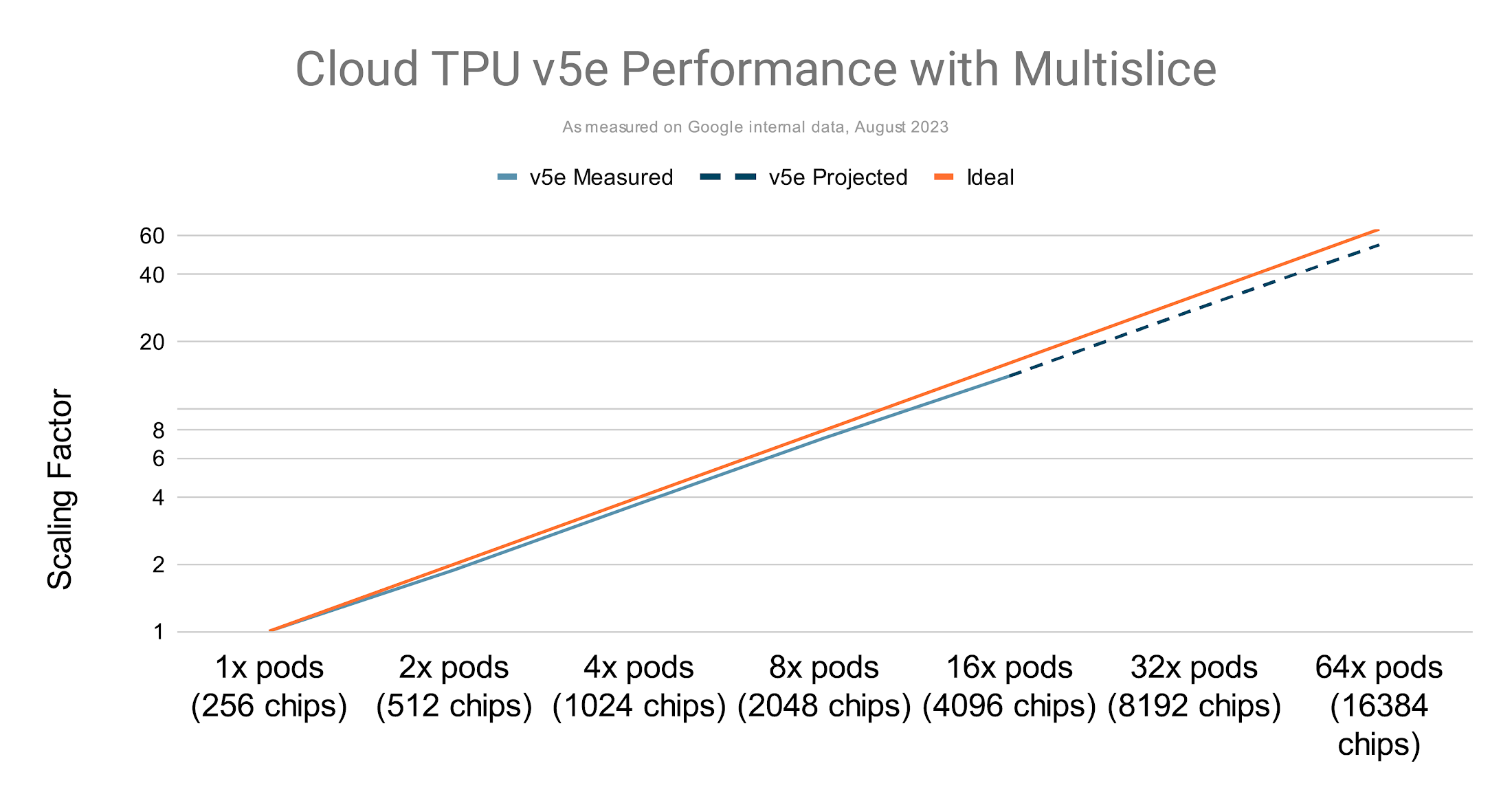
멀티슬라이스 구성을 통한 v5e의 선형에 가까운 확장
사용하기 쉬운 Cloud TPU의 멀티슬라이스
분산학습을 위한 통신 레이어를 직접 관리하는 일은 복잡하므로 개발자 생산성을 저하시킬 수 있습니다. 멀티슬라이스는 최적화된 소프트웨어 스택을 이용해 분산학습을 위한 확장 과정을 단순화합니다. 따라서 사용자는 복잡한 인프라 관리보다 AI 모델 학습 자체에 집중할 수 있으며, 이로 인해 대규모 학습 시에도 우수한 개발자 경험을 제공합니다. 멀티슬라이스 구성시에도 단일 슬라이스를 활용한 학습시와 동일한 프로파일링 및 오케스트레이션 도구를 사용하여 설정에 걸리는 시간을 단축할 수 있습니다.
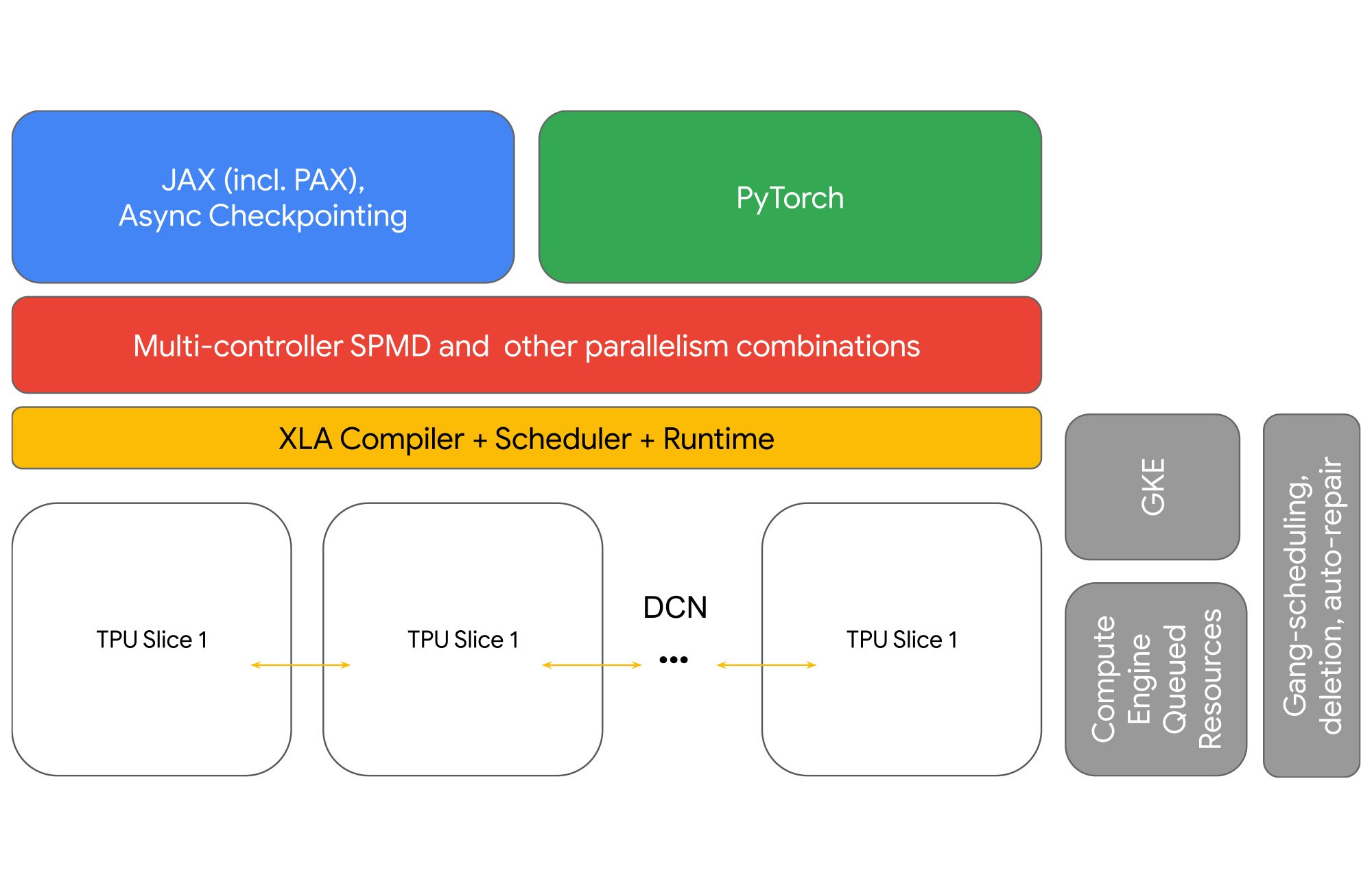
Cloud TPU 멀티슬라이스는 네트워크, 런타임, 스케줄러, 프레임워크 및 오케스트레이션 기능을 풀스택으로 제공합니다
GSPMD를 사용하면 샤딩 축을 조작하여 Tensor Parallelism, Data Parallelism, FSDP Parallelism 간의 전환을 통해 2개의 슬라이스에서 2,000개의 슬라이스까지 확장할 수 있습니다. 멀티슬라이스 워크로드를 위해 개량된 런타임과 인프라를 통해 JAX 및 PyTorch 모델의 DCN을 통한 모델 샤딩을 가능케 했습니다.
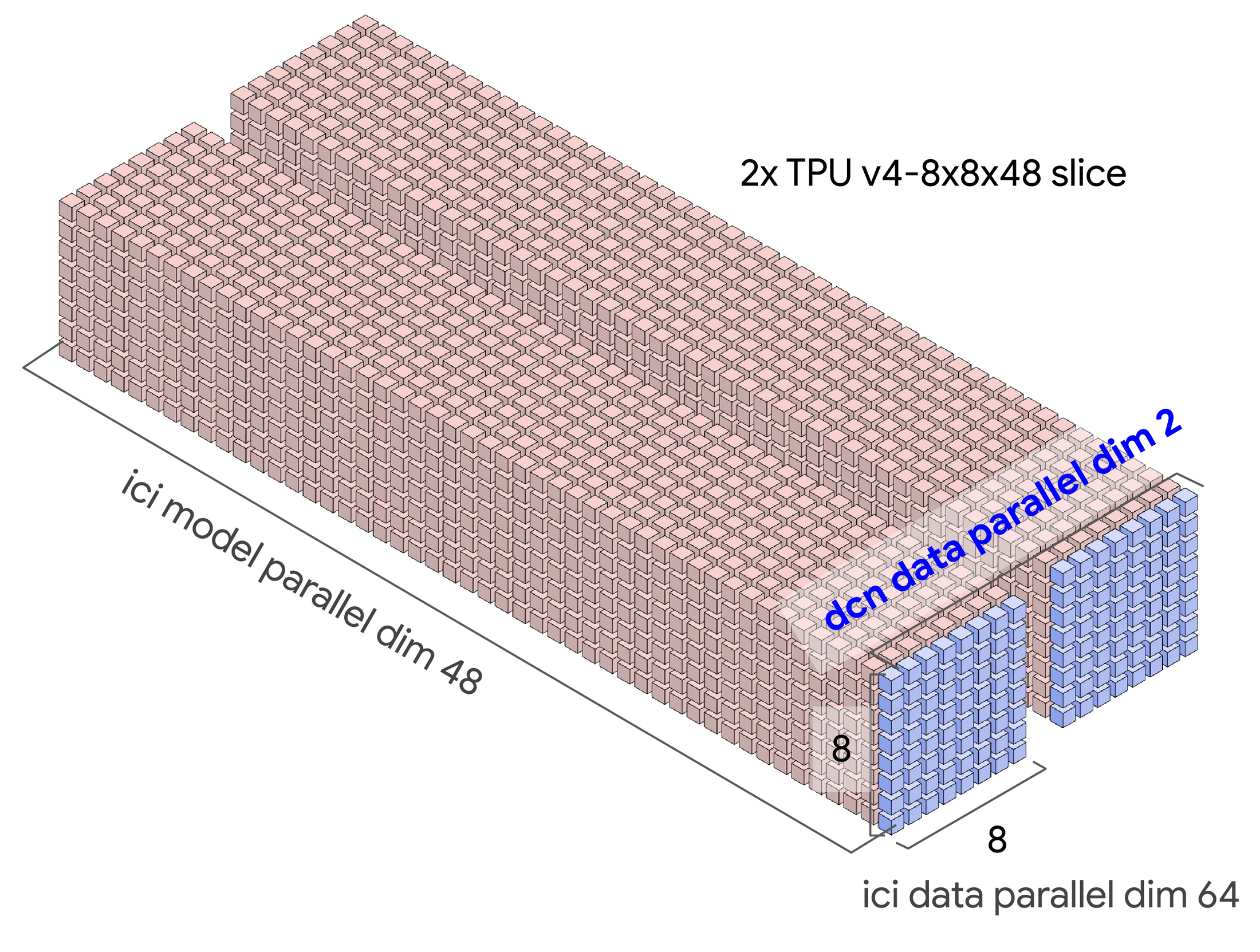
멀티슬라이스로 DCN에 대한 새로운 샤딩 차원 도입
GSPMD 용어인 mesh는 모델의 행렬 연산을 분산처리할 수 있는 디바이스들의 논리적인 묶음을 의미합니다:
아래의 테이블은 DCN을 분산의 축으로 두개의 슬라이스에서 Data Parallelism을 설정하는 예시입니다.
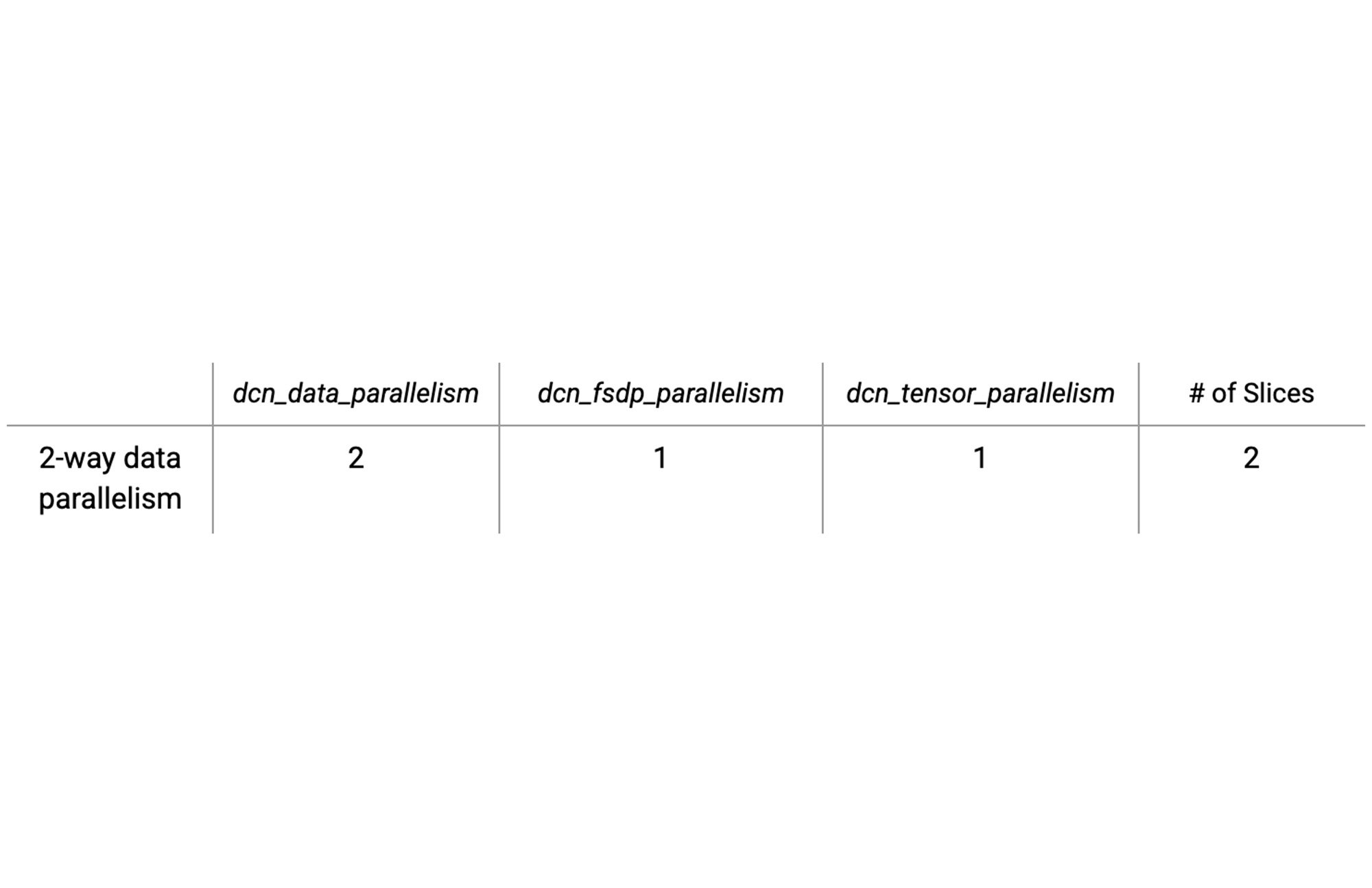
이러한 유형의 분산학습을 위한 설정시 필요한 값을 찾는 과정은 매우 간단합니다. dcn_parallelism 변수와 icn_parallelism 변수의 곱이 전체 칩 수와 동일하게 설정해주면 됩니다.
또한 XLA 컴파일러는 기반이 되는 하이브리드 DCN/ICI 네트워크 토폴로지를 이해하여 자동으로 적절한 계층 구조 집합체를 삽입하고, 나아가 단일 슬라이스 작업을 멀티슬라이스 계층 구조 집합체로 변환하여 컴퓨팅 통신 중첩을 개선할 수도 있습니다.
AllReduce 작업을 예를 들어 보겠습니다. XLA 컴파일러는 자동으로 이를 3단계 계층 구조 집합체로 분해합니다.
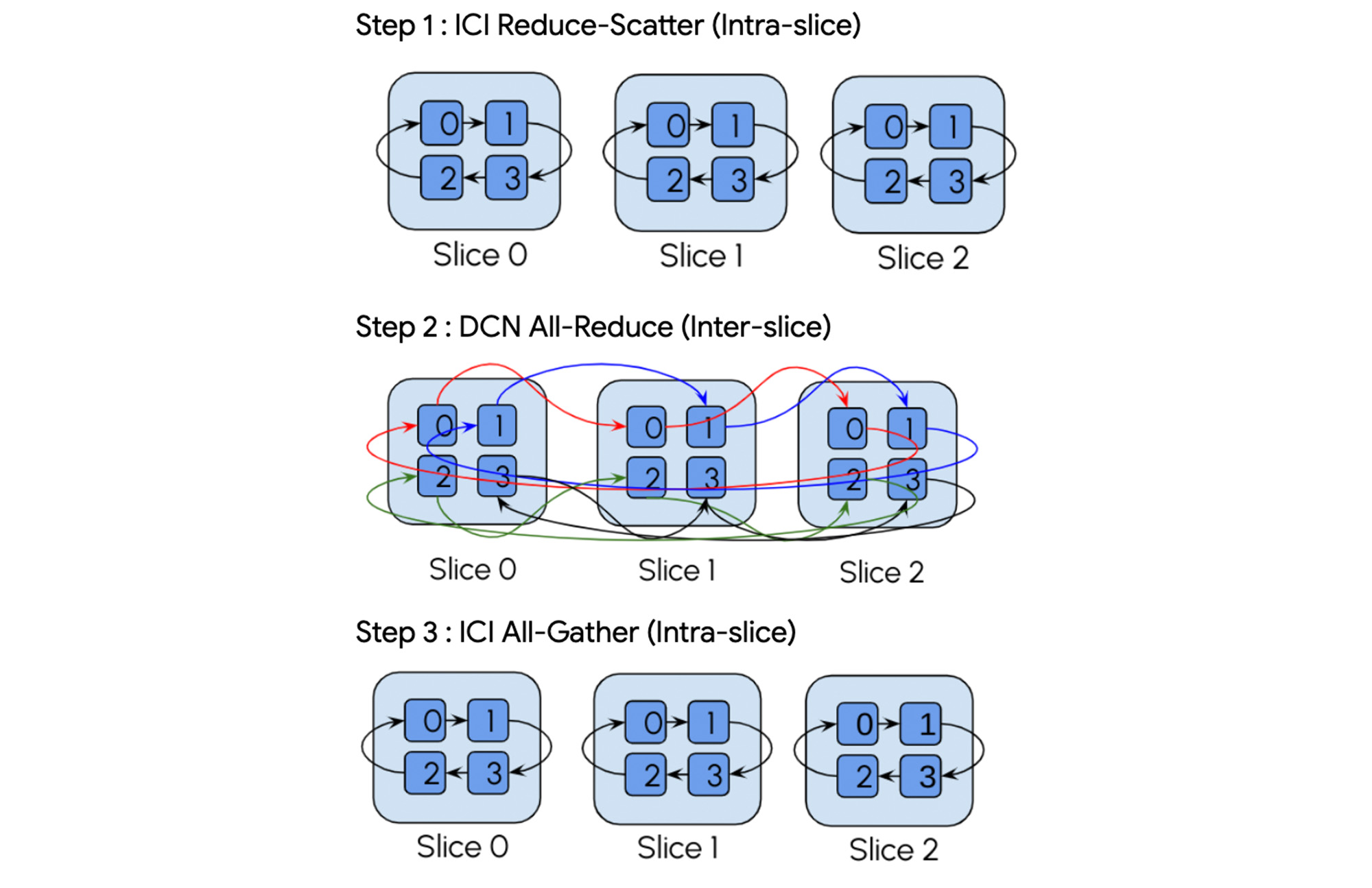
XLA 컴파일러는 AllReduce를 계층 구조 집합체로 자동으로 분해합니다.
“멀티슬라이스 학습은 획기적입니다. 멀티슬라이스 덕분에 데이터 센터 네트워킹(DCN)을 통해ML 워크로드를 여러 슬라이스에 걸쳐 손쉽게 확장할 수 있었습니다. JAX XLA는 이를 쉽게 설정할 수 있게 해주었으며 높은 성능을 제공했습니다.”—Myle Ott, Co-founder, Character AI
멀티슬라이스는 JAX 및 PyTorch 프레임워크를 지원합니다. JAX 및 PyTorch 모델을 위한 컴파일러 외에도 멀티슬라이스를 위한 높은 성능의 LLM인 MaxText와 프레임워크인 PAX가 같이 제공됩니다. 이를 통해 Python 및 JAX로 작성된 다수의 검증된 예제 코드로부터 시작할 수 있습니다. PAX는 거대 모델의 학습을 위한 프레임워크로, 완전히 커스터마이즈 된 학습 및 실험이 가능하며, 업계 최고의 입증된 MFU Rate을 제공합니다. MaxText는 fork 및 적은 수준의 커스터마이즈를 위한 미니멀한 프레임워크입니다. 멀티슬라이스 구동을 위해서는 단일 슬라이스에서 구동되는 코드에 DCN을 통한 샤딩만 추가로 설정해주면 됩니다.
고성능 네트워킹
멀티슬라이스는 Google의 Jupiter 데이터 센터 네트워크를 통해 AllReduce, Broadcast, Reduce, AllGather 및 ReduceScatter 집단 통신 작업을 지원합니다. 2022년 8월에 보고된 바와 같이 Jupiter는 이전 세대의 Google 데이터 센터 네트워크에 비해 흐름 완료를 10% 줄이고, 처리량을 30% 개선하고, 전력 사용량을 40% 줄이고, capex를 30% 절감하며, 다운타임은 50배나 줄였습니다.3
손쉬운 관리
멀티슬라이스 작업을 관리하기 위한 옵션은 두 가지입니다. Compute Engine Queued Resource CLI 및 API를 사용하는 옵션, 그리고 Google Kubernetes Engine(GKE)을 통한 옵션입니다.
슬라이스 컬렉션을 한번에삭제하거나 생성할 수 있게 해주는 특수 옵션도 있습니다. 또한 빠른 복구를 통해 개별 슬라이스가 중단되더라도 작업을 신속하게 다시 시작할 수 있습니다.
안정성과 내결함성
개발 슬라이스에 장애가 발생한다 해도 모델 학습 작업은 이전 체크포인트에서 자동으로 다시 시작됩니다. 멀티슬라이스를 GKE와 함께 사용하면 장애 복구 환경이 더욱 개선됩니다. yaml 파일의 필드 하나만 변경하면 오류 발생 시 자동 재시도가 구현되도록 할 수 있습니다.
“Google Cloud의 TPU 멀티슬라이스를 통해 곧바로 상당한 생산성 및 효율성 개선 효과를 볼 수 있었고, 덕분에 언어 모델 학습을 안정적으로 확장할 수 있었습니다. 대규모 생성형 언어 AI 모델을 구축한다면 멀티슬라이스를 권장합니다."—Emad Mostaque, CEO, Stability AI
시작하기
멀티슬라이스는 효율적인 대규모 AI 모델 학습을 지원하도록 만들어졌습니다. AI 워크로드를 확장하려면 하드웨어와 소프트웨어가 상호 조화롭게 작동해야 합니다. Google Cloud는 평소 AI 개발 생산성을 가장 중시해 왔습니다. 이번에 Cloud TPU v4와 새로 발표된 Cloud TPU v5e에서 미리보기로 멀티슬라이스를 사용할 수 있다는 소식을 전하게 되어 기쁩니다.
더 자세히 알아보고 Cloud TPU를 멀티슬라이스와 함께 사용해 보려면 Google Cloud 계정 담당자에게 문의하세요(PAX 및 MaxText 사용).
1. Google internal data as of August, 2023
2. Google internal data as of August, 2023
3. Google internal data as of August, 2023


