Google Cloud 6세대 TPU, Trillium 정식 버전 출시 발표

Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
* 본 아티클의 원문은 2024년 12월 12일 Google Cloud 블로그(영문)에 게재되었습니다.
텍스트, 이미지와 같은 다양한 형식을 처리할 수 있는 대규모 AI 모델이 등장하면서 인프라 측면에서 고유한 과제도 생겨났습니다. 이러한 모델은 학습, 파인 튜닝, 추론을 효율적으로 처리하기 위해 막대한 컴퓨팅 성능과 특수한 하드웨어가 필요합니다. Google은 10여 년 전에 증가하는 AI 워크로드 수요에 대응하기 위해 커스텀 AI 가속기인 Tensor Processing Unit(TPU)을 개발하기 시작하면서 멀티모달 AI를 위한 기반을 마련했습니다.
Google Cloud는 올해 6세대이자 현존하는 가장 강력한 TPU인 Trillium을 발표했습니다. 이제 Trillium이 Google Cloud 고객에게 정식 버전으로 출시됩니다.
Google Cloud는 Trillium TPU를 사용하여 역대 가장 강력한 Google AI 모델인 새로운 Gemini 2.0을 학습시켰습니다. 이제 기업과 스타트업 모두 이와 동일한 인프라의 강력한 성능, 효율성, 지속 가능성을 활용할 수 있습니다.
Trillium TPU는 성능에 최적화된 하드웨어, 개방형 소프트웨어, 선도적인 ML 프레임워크, 유연한 소비 모델로 구성된 통합 시스템을 활용하는 획기적인 슈퍼컴퓨터 아키텍처인 Google Cloud AI Hypercomputer의 핵심 구성요소입니다. Google은 Trillium TPU의 정식 버전 출시에 따라 AI Hypercomputer의 개방형 소프트웨어 레이어에도 중요한 개선 사항을 적용하고 있습니다. 이러한 개선 사항에는 AI 학습, 튜닝, 서빙 전반에서 대규모로 최고의 가성비를 달성하기 위한 JAX, PyTorch, TensorFlow 등 인기 있는 프레임워크와 XLA 컴파일러의 최적화 등이 포함됩니다. 또한 대용량 호스트 DRAM을 사용하는 호스트 오프로딩과 같은 기능(고대역폭 메모리, 즉 HBM 보완)은 효율성의 수준을 한 차원 높입니다. AI Hypercomputer를 사용하면 초당 13페타비트의 바이섹션 대역폭을 갖추고 Jupiter 네트워크 패브릭당 100,000여 개의 전례 없는 Trillium 칩 배포로 최대한의 가치를 끌어낼 수 있으며, 이를 통해 단일 분산 학습 작업을 수십만 개의 가속기로 확장할 수 있습니다.
이미 AI21 Labs와 같은 고객사는 Trillium을 사용하여 고객에게 효과적인 AI 솔루션을 더 빠르게 제공하고 있습니다.
“AI21은 Mamba 및 Jamba 언어 모델의 성능과 효율성을 개선하기 위해 지속적으로 노력하고 있습니다. v4부터 오랜 기간 TPU를 사용해 온 입장에서 볼 때 Google Cloud Trillium의 기능은 매우 놀라운 수준입니다. 규모, 속도, 비용 효율성에서 큰 발전을 이루었습니다. 앞으로 Trillium은 정교한 차세대 언어 모델 개발을 앞당기는 데 핵심이 되어 AI21이 더욱 강력하고 접근성 높은 AI 솔루션을 고객에게 제공하도록 지원할 것입니다." - Barak Lenz, AI21 Labs CTO
이전 세대 대비 Trillium의 주요 개선 사항은 다음과 같습니다.
-
학습 성능 4배 이상 개선
-
추론 처리량 최대 3배 증가
-
에너지 효율성 67% 향상
-
칩당 최대 컴퓨팅 성능의 유의미한 4.7배 증대
-
고대역폭 메모리(HBM) 용량 두 배 증가
-
칩 간 상호 연결(ICI) 대역폭 두 배 증가
-
단일 Jupiter 네트워크 패브릭에 10만 개의 Trillium 칩
-
달러당 학습 성능 최대 2.5배 개선, 달러당 추론 성능 최대 1.4배 개선
이러한 개선을 통해 Trillium은 다음을 포함한 광범위한 AI 워크로드에서 뛰어난 성능을 발휘합니다.
-
AI 학습 워크로드 확장
-
밀집형 및 전문가 망(MoE) 모델을 포함한 LLM 학습
-
추론 성능 및 컬렉션 예약
-
임베딩을 많이 사용하는 모델
-
우수한 학습 및 추론 가성비 제공
이러한 각 워크로드에서 Trillium의 성능을 살펴보겠습니다.
AI 학습 워크로드 확장
Gemini 2.0과 같은 대용량 모델을 학습시키기 위해서는 방대한 데이터와 계산이 필요합니다. Trillium의 선형에 가까운 확장 기능을 통해 이러한 모델을 훨씬 더 빠르게 학습시킬 수 있습니다. 256칩 포드 내 고속 칩 간 상호 연결과 Google Cloud의 첨단 Jupiter 데이터 센터 네트워킹을 통해 연결된 다수의 Trillium 호스트 전반에 워크로드가 효과적이고 효율적으로 분산됩니다. 이를 위해 TPU 멀티슬라이스 및 대규모 학습을 위한 풀 스택 기술이 사용되며, Trillium의 확장 기능은 호스트 어댑터에서 네트워크 패브릭에 이르는 동적 데이터 센터 전체 오프로드 시스템인 Titanium을 통해 더욱 최적화됩니다.
Trillium은 3,072개의 칩이 있는 12개의 포드 배포로 확장 효율성 99%를 달성하며, 데이터 센터 네트워크 전반에서 작동하면서 gpt3-175b를 선행 학습시키는 경우에도 6,144개의 칩이 있는 24개의 포드에서 94%의 확장 효율성을 보여줍니다.
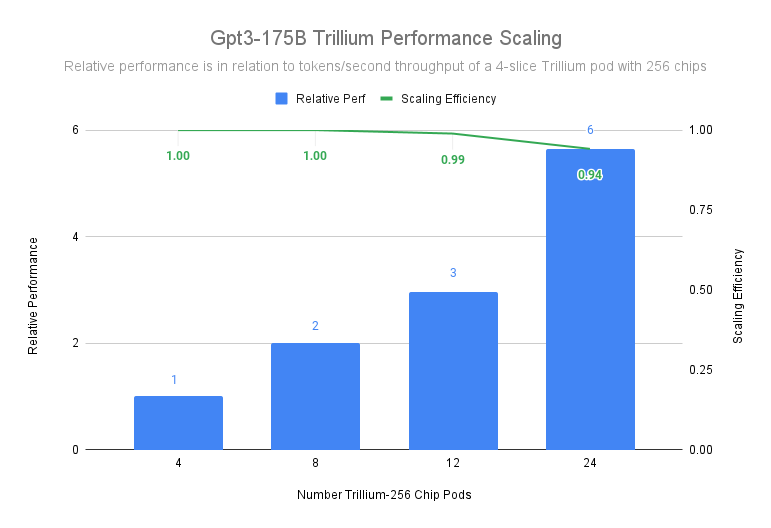
그림 1. 소스 데이터: Google 벤치마크 및 MLPerf™ 4.1. n x Trillium-256은 단일 ICI 도메인에서 256개의 칩이 있는 n개의 Trillium 포드에 해당합니다.
위 그래프에서는 4슬라이스 Trillium-256 칩 포드를 기준으로 사용하지만 1슬라이스 Trillium-256 칩 포드를 기준으로 사용하더라도 24개의 포드로 확장 시 90%가 넘는 확장 효율성을 얻을 수 있습니다.
Google Cloud의 테스트 결과, Llama-2-70B 모델 학습에서 Trillium은 99%의 확장 효율성을 보이며 4슬라이스 Trillium-256 칩 포드에서 36슬라이스 Trillium-256 칩 포드로 선형에 가깝게 확장한다는 점이 입증되었습니다.
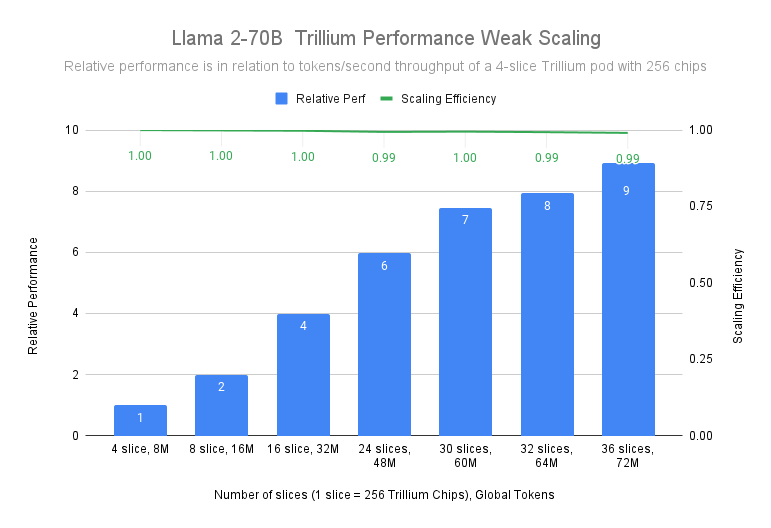
그림 2. 소스 데이터: 4k 시퀀스 길이에서 MaxText 참조 구현을 사용한 Google 벤치마크. n x Trillium-256은 단일 ICI 도메인에서 256개의 칩이 있는 n개의 Trillium 포드에 해당합니다.
Trillium TPU는 이전 세대에 비해 훨씬 더 높은 확장 효율성을 보입니다. 아래 그래프는 Google Cloud의 테스트 결과, 동일한 규모(총 피크 FLOPS)의 Cloud TPU v5p 클러스터와 비교 시 12포드 규모에서 Trillium의 확장 효율성이 99%임을 보여줍니다.
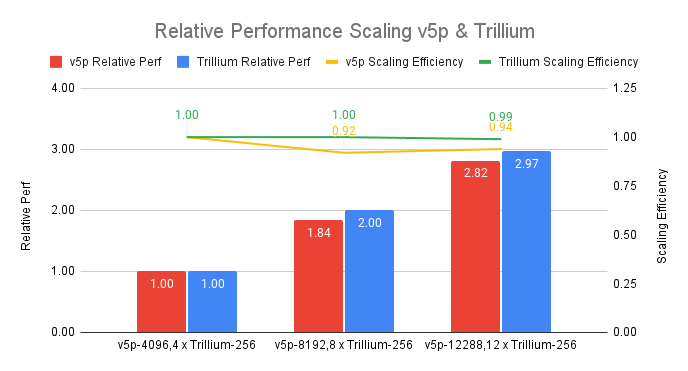
그림 3. 소스 데이터: Trillium(프리뷰)과 v5p에서 gpt3-175b 학습 작업을 진행한 MLPerf™ 4.1의 학습 종료 결과. 2024년 11월 기준: Trillium과 Cloud TPU v5p의 약한 확장 비교. v5p-4096 및 4xTrillium-256은 배율 측정의 기준으로 간주됩니다. n x Trillium-256은 단일 ICI 도메인에서 256개의 칩이 있는 n개의 Trillium 포드에 해당합니다. v5p-n은 단일 ICI 도메인에서 n/2개의 v5p 칩에 해당합니다.
밀집형 및 전문가 망(MoE) 모델을 포함한 LLM 학습
Gemini와 같은 LLM은 본질적으로 강력하고 복잡하며 수십억 개의 파라미터가 있습니다. 이러한 밀집형 LLM을 학습시키려면 막대한 컴퓨팅 성능과 공동 설계된 소프트웨어 최적화가 필요합니다. Trillium은 이전 세대 Cloud TPU v5e와 비교해 Llama-2-70b 및 gpt3-175b와 같은 밀집형 LLM의 학습 속도를 최대 4배 앞당깁니다.
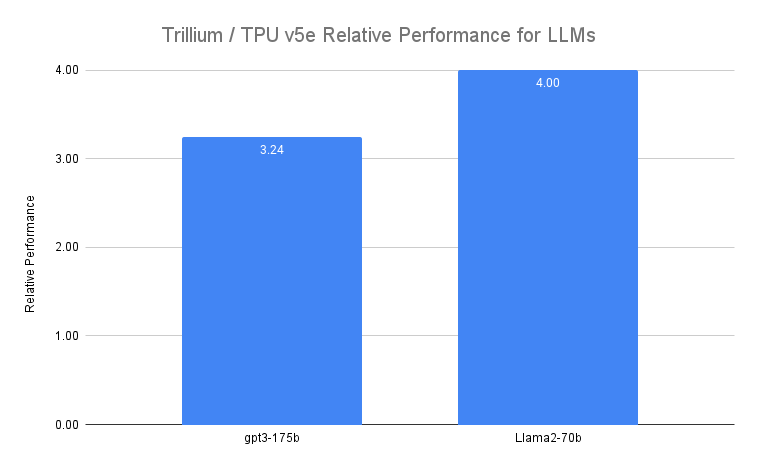
그림 4. 소스 데이터: v5e 및 Trillium에서 단계 시간 실행에 대한 Google 벤치마크
밀집형 LLM 외에, 전문가 망(MoE) 아키텍처를 사용하는 LLM 학습이 갈수록 인기를 끌고 있습니다. 이 방식에서는 각각 다른 AI 작업 측면에 특화된 여러 '전문가' 신경망이 사용됩니다. 학습 중 이러한 전문가를 관리하고 조율하는 작업은 단일 모놀리식 모델 학습보다 더 복잡합니다. Trillium은 이전 세대 Cloud TPU v5e와 비교해 MoE 모델의 학습 속도를 최대 3.8배 앞당깁니다.
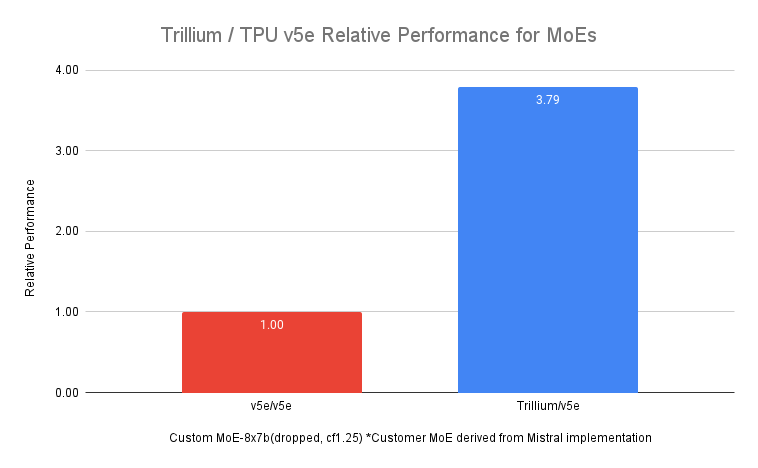
그림 5. 소스 데이터: v5e 및 Trillium에서 단계 시간 실행에 대한 Google 벤치마크
또한 Trillium TPU는 Cloud TPU v5e에 비해 호스트 동적 랜덤 액세스 메모리(DRAM)가 3배 더 많습니다. 이를 통해 일부 계산을 호스트로 오프로드하여 성능 및 굿풋을 대규모로 극대화할 수 있습니다. Trillium의 호스트 오프로딩 기능은 모델 FLOPS 사용률(MFU)로 측정 시 Llama-3.1-405B 모델 학습에서 50% 넘게 성능을 개선합니다.
추론 성능 및 컬렉션 예약
추론 시점에서 다단계 추론의 중요성이 커지면서 늘어난 컴퓨팅 수요를 효율적으로 처리할 수 있는 가속기가 필요해졌습니다. Trillium은 추론 워크로드를 크게 개선하여 더 빠르고 효율적인 AI 모델 배포를 지원합니다. 실제로 Trillium은 이미지 확산 및 밀집형 LLM을 위한 Google Cloud 최고의 TPU 추론 성능을 자랑합니다. Google Cloud의 테스트 결과, Cloud TPU v5e와 비교할 때 Stable Diffusion XL의 상대 추론 처리량(초당 이미지 수)은 3배 넘게, Llama2-70B의 상대 추론 처리량(초당 토큰 수)은 2배 가까이 높은 것으로 나타났습니다.
Trillium은 오프라인과 서버 추론, 두 가지 사용 사례 모두에서 가장 성능이 우수한 TPU입니다. 아래 그래프는 Cloud TPU v5e에 비해 오프라인 추론에서 상대 처리량(초당 이미지 수)은 3.1배, Stable Diffusion XL 서버 추론에서 상대 처리량은 2.9배 더 높은 것을 보여줍니다.
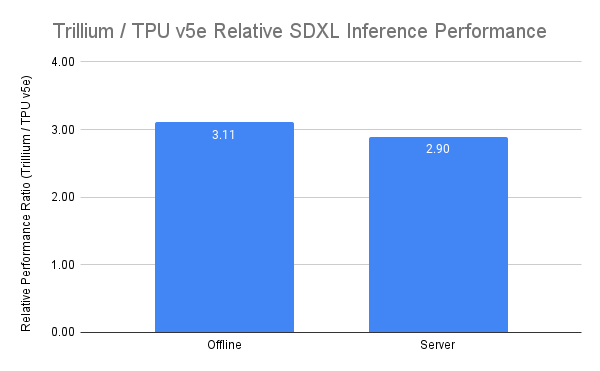
그림 6. 소스 데이터: MaxDiffusion 참조 구현을 사용한 오프라인 및 온라인 SDXL 사용 사례의 초당 이미지 수에 대한 Google 벤치마크
더 나은 성능 외에 Trillium은 새로운 컬렉션 예약 기능도 제공합니다. 이 기능은 컬렉션에 여러 개의 복제본이 있는 경우 Google의 예약 시스템에서 지능적으로 작업 예약에 관한 의사 결정을 내려 추론 워크로드의 전체적인 가용성과 효율성을 높입니다. 이는 Google Kubernetes Engine(GKE)을 통한 방법을 포함하여 단일 호스트 또는 다중 호스트 추론 워크로드를 실행하는 여러 TPU 슬라이스를 관리하기 위한 방법을 제공합니다. 이러한 슬라이스를 하나의 컬렉션으로 그룹화하면 수요에 맞추어 복제본의 수를 간단히 조정할 수 있습니다.
임베딩을 많이 사용하는 모델
3세대 SparseCore가 추가된 Trillium은 임베딩을 많이 사용하는 모델의 성능을 2배, DLRM DCNv2의 성능을 5배 높여줍니다.
SparseCore는 임베딩 사용량이 많은 워크로드를 위해 적응력이 더 높은 아키텍처 기반을 제공하는 Dataflow 프로세서입니다. Trillium의 3세대 SparseCore는 분산 수집, 희소 구간 합, 파티셔닝과 같은 동적이고 데이터 종속적인 작업의 속도를 높이는 데 효과적입니다.
우수한 학습 및 추론 가성비 제공
Trillium은 세계 최대의 AI 워크로드를 학습시키는 데 필요한 절대적인 성능과 규모 외에, 달러당 성능도 최적화하도록 설계되었습니다. 현재 Trillium은 Llama2-70b, Llama3.1-405b와 같은 밀집형 LLM 학습에서 Cloud TPU v5e에 비해 달러당 최대 2.1배, Cloud TPU v5p에 비해 달러당 최대 2.5배 더 높은 성능을 보입니다.
Trillium은 비용 효율적인 방식으로 대규모 모델의 병렬 처리를 지원하는 데 효과적입니다. 연구원과 개발자가 전보다 훨씬 더 낮은 비용으로 견고하고 효율적인 이미지 모델을 제공할 수 있도록 설계되었습니다. Trillium에서 이미지 1,000개를 생성하는 데 드는 비용은 오프라인 추론에서 Cloud TPU v5e에 비해 27% 낮고, SDXL의 서버 추론에서 Cloud TPU v5e보다 22% 낮습니다.
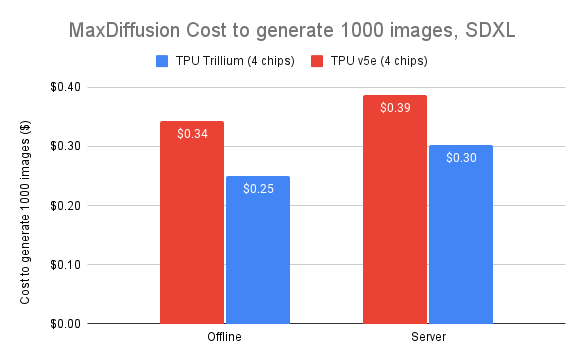
그림 7. 소스 데이터: MaxDiffusion 참조 구현을 사용한 오프라인 및 온라인 SDXL 사용 사례의 초당 이미지 수에 대한 Google 벤치마크
한 차원 더 높은 AI 혁신
Trillium은 Google Cloud의 AI 인프라에서 있어 큰 도약이며, 다양한 AI 워크로드에서 놀라운 성능과 확장성, 효율성을 제공합니다. 세계 최고 수준의 공동 설계 소프트웨어를 기반으로 수십만 개의 칩으로 확장 가능한 Trillium을 사용하면 더 빠르게 혁신을 달성하고 더 우수한 AI 솔루션을 제공할 수 있습니다. 또한 Trillium은 탁월한 가성비를 통해 AI 투자에서 얻는 가치를 극대화하고자 하는 조직에 비용 효율적인 선택지입니다. AI 환경이 계속 발전함에 따라, Trillium은 기업에서 AI의 잠재력을 최대한 끌어내는 데 기반이 되는 첨단 인프라를 제공하기 위한 Google Cloud의 노력을 방증합니다.
앞으로 AI 혁신의 경계를 넓혀 나가는 데 Trillium과 AI Hypercomputer가 어떻게 활용될지 기대됩니다. 다음 발표 동영상에서 Trillium 시스템이 가장 까다로운 AI 워크로드의 속도를 어떻게 높이는지 확인해 보세요.



