MLPerf에서 세계 최고 속도의 학습 슈퍼컴퓨터로 AI 성능 기록을 경신한 Google

Naveen Kumar
Principal Engineer
* 본 아티클의 원문은 2020년 7월 30일 Google Cloud 블로그(영문)에 게재되었습니다.
머신러닝(ML) 모델의 빠른 학습 속도는 이전에는 불가능했던 신규 제품, 서비스, 연구 혁신을 제공하는 연구개발팀에게 매우 중요한 역할을 합니다. 최근 Google이 이룬 ML 기반의 기술적인 진보에는 더욱 유용한 검색결과, 100개의 다른 언어를 번역할 수 있는 단일 ML 모델 등이 있습니다.
업계 표준 MLPerf 벤치마크 콘테스트의 최근 결과에서 Google이 세계에서 가장 빠른 ML 학습 슈퍼컴퓨터를 구축했다는 사실이 입증되었습니다. Google은 학습 슈퍼컴퓨터와 더불어 Google의 최신 Tensor Processing Unit(TPU) 칩을 활용하여 MLPerf 벤치마크 8개 부문 중 6개 부문에서 신기록을 달성했습니다.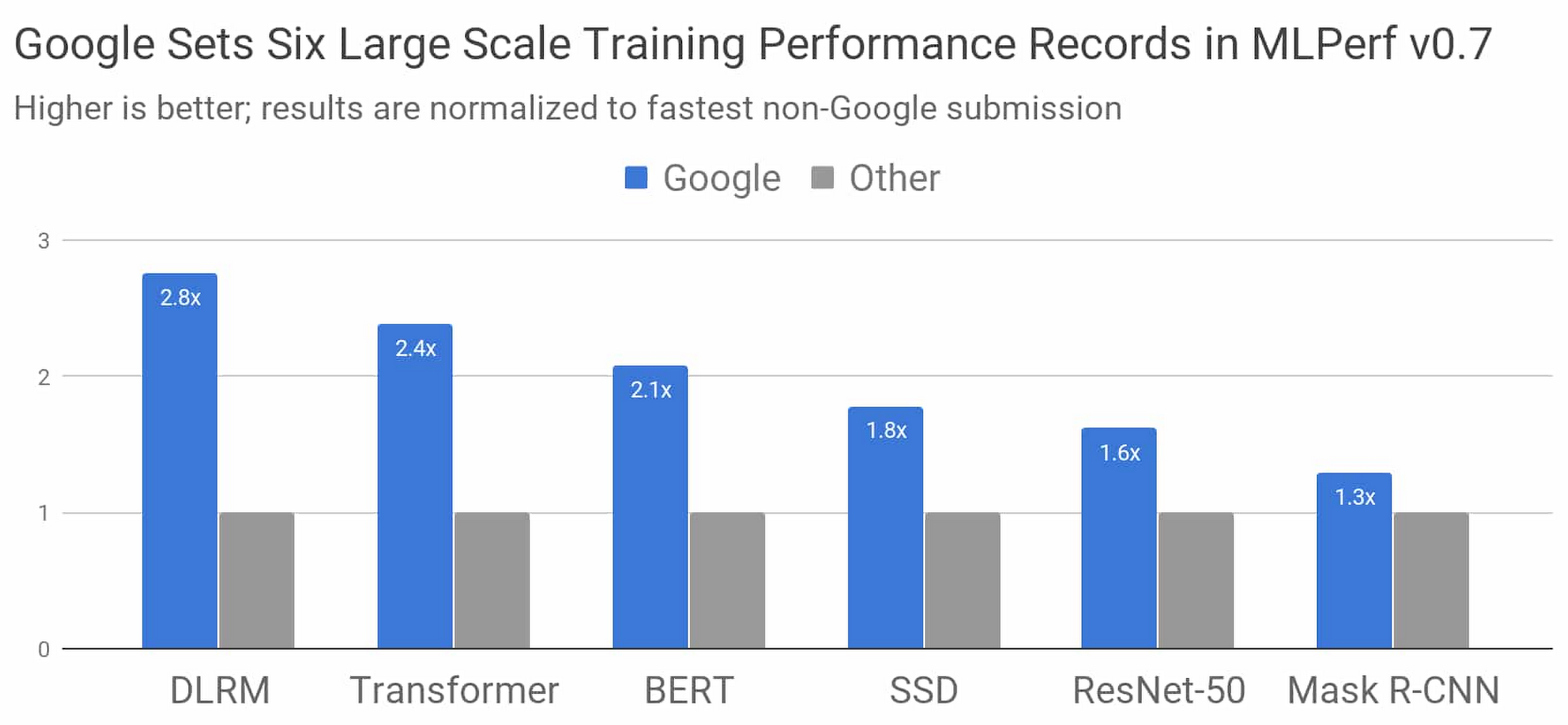
그림 1: 모든 가용성 카테고리에서 Google 최고의 MLPerf Training v0.7 Research는 Google을 제외하고 가장 빨리 결과를 제출한 업체보다도 제출 속도가 빠릅니다. 8개 칩에서 4,096개 칩에 이르는 시스템 크기에 상관없이 전체 학습 시간을 정규화하여 비교합니다. 막대가 길수록 성과가 더 우수함을 의미합니다.1
Google에서는 TensorFlow, JAX, Lingvo에서 ML 모델을 구현하여 이와 같은 결과를 얻었습니다. 모델 8개 중 4개는 30초도 안 되는 시간에 처음부터 학습을 완료했습니다. 이해를 돕자면, 2015년에는 사용 가능한 최첨단 하드웨어 가속기에서 이러한 모델 중 하나를 학습하는 데 3주가 넘게 걸렸습니다. 불과 5년이 흐른 지금 Google의 최신 TPU 슈퍼컴퓨터는 동일한 모델을 거의 100,000배 빠르게 학습시킬 수 있습니다.
이 블로그 게시물에서는 콘테스트에 대한 몇 가지 세부정보, Google이 뛰어난 성능을 구현할 수 있었던 비결, 이 모든 성과가 모델 학습 속도에 시사하는 바에 대해 살펴봅니다.
MLPerf 모델 요약
MLPerf 모델은 업계 및 학계를 아울러 공통적으로 첨단 머신러닝 워크로드를 대표하는 모델로 손꼽힙니다. 위 그림에 표기된 각 MLPerf 모델에 대한 보다 구체적인 정보는 다음과 같습니다.
DLRM은 미디어에서 여행, 전자상거래에 이르는 온라인 비즈니스에서 핵심 요소인 순위 및 추천 모델을 나타냅니다.
Transformer는 BERT를 비롯한 자연어 처리 분야에서 이어지는 최신 개발의 토대입니다.
BERT를 통해 Google 검색은 '지난 5년 동안 비약적으로 발전했습니다.'
ResNet-50은 이미지 분류에서 널리 사용되는 모델입니다.
SSD는 휴대기기에서 실행 가능할 정도로 가벼운 객체 인식 모델입니다.
Mask R-CNN은 널리 사용되는 이미지 세분화 모델로 자동 항법, 의료 영상, 기타 영역에서 활용 가능합니다(Colab에서 실험 가능).
위와 같이 Google은 최대 규모로 업계를 선도하는 결과를 낸 것 외에도 현재 기업에서도 사용할 수 있는 Google Cloud Platform의 TensorFlow를 사용하여 MLPerf에 결과물을 제출했습니다. 이 제출 결과에 관한 자세한 내용은 함께 제공되는 블로그 게시물을 참조하세요.
세계 최고 속도의 ML 학습 슈퍼컴퓨터

Google이 이 MLPerf Training 라운드에 사용한 슈퍼컴퓨터는 이전 콘테스트에서 3개의 신기록을 달성한 Cloud TPU v3 Pod보다 4배 더 큽니다. 이 시스템에는 4,096개의 TPU v3 칩과 수백 개의 CPU 호스트 머신이 포함되며 모두 속도가 매우 빠른 초대형 커스텀 상호 연결을 통해 연결됩니다. 전체적으로 이 시스템은 430플롭스가 넘는 최고 성능을 제공합니다.
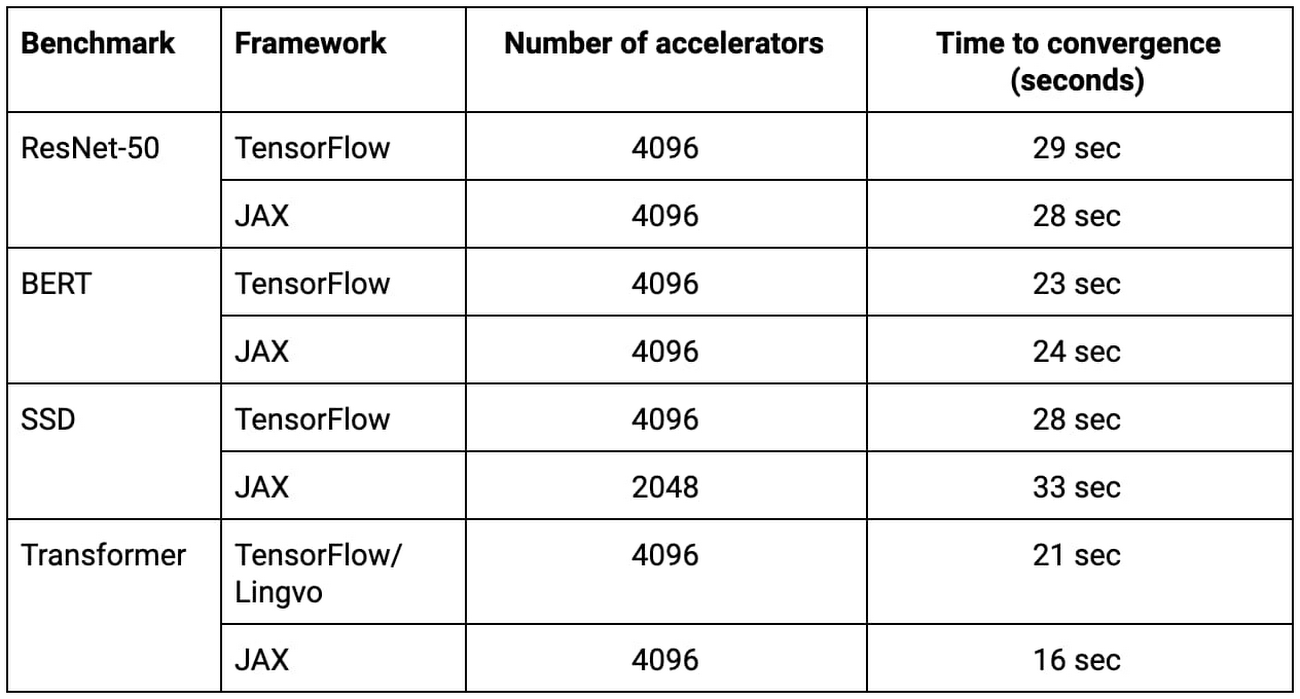
표 1: 제시된 모든 MLPerf 제출물은 Google의 새로운 ML 슈퍼컴퓨터에서 처음부터 학습하는 데 33초 이하가 소요되었습니다.2
TensorFlow, JAX, Lingvo, XLA로 규모에 맞춘 학습
수천 개의 TPU 칩을 사용하여 복잡한 ML 모델을 학습하려면 TensorFlow, JAX, Lingvo, XLA의 알고리즘 기술과 최적화를 조합해야 했습니다. 배경을 설명하자면 XLA는 Google의 모든 MLPerf 제출을 지원하는 기본 컴파일러 기술이고, TensorFlow는 Google의 엔드 투 엔드 오픈소스 머신러닝 프레임워크이며, Lingvo는 TensorFlow를 사용하여 빌드된 시퀀스 모델을 위한 고수준 프레임워크이고, JAX는 구성 가능한 함수 변환을 기반으로 하는 새로운 연구 중심 프레임워크입니다. 위에 언급된 대규모 신기록 달성은 모델 동시 로드, 조정 배치 정규화, 효율적인 컴퓨팅 그래프 시작, 트리 기반 가중치 초기화를 통해 이루어졌습니다.
ResNet-50, BERT, SSD, Transformer 구현을 나타내는 위 표의 모든 TensorFlow, JAX, Lingvo 제출물은 TPU 칩 2,048개 또는 4,096개 환경에서 각각 33초 미만의 시간에 학습되었습니다.
TPU v4: Google의 4세대 Tensor Processing Unit 칩
Google의 4세대 TPU ASIC는 TPU v3의 행렬 곱셈에 비해 2배가 넘는 TFLOPS의 성능을 제공합니다. 이는 메모리 대역폭의 엄청난 증가이자 상호연결 기술의 놀라운 발전을 뜻합니다. Google의 TPU v4 MLPerf 제출물은 이처럼 새로운 하드웨어 기능과 더불어 이를 보완하는 컴파일러 및 모델링의 발전을 활용합니다. 제출 결과는 지난 MLPerf Training 콘테스트에서 비슷한 규모의 TPU v3이 거둔 성능보다 평균 2.7배 향상된 성능을 나타냅니다. TPU v4에 대한 자세한 정보가 곧 공개되니 계속 관심을 가져주시길 바랍니다.
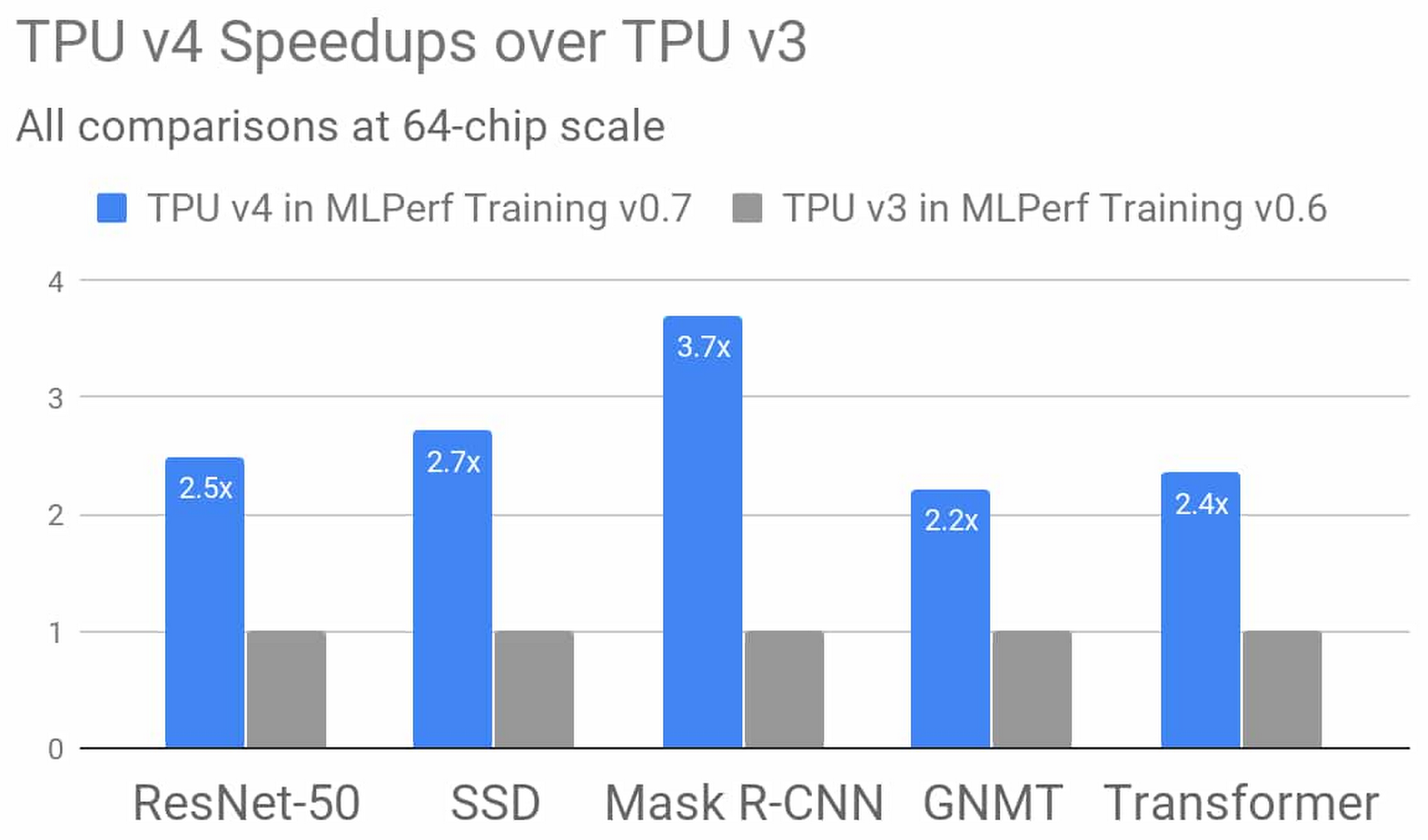
그림 2: Google의 MLPerf Training v0.7 Research 제출물에서 TPU v4의 결과는 64개 칩을 사용하는 동일 규모에서 Google의 MLPerf Training v0.6 Available 제출물의 비교 가능한 TPU v3 결과에 비해 2.7배 개선된 것을 보여줍니다. 이러한 개선은 TPU v4의 하드웨어뿐 아니라 소프트웨어도 혁신적으로 향상되었기에 가능한 일입니다.3
빠르고 지속적인 발전
Google의 MLPerf Training v0.7 제출 결과는 머신러닝 연구개발을 대규모로 발전시키고 향상된 결과를 오픈소스 소프트웨어, Google 제품, Google Cloud를 통해 사용자에게 제공하려는 Google의 노력을 보여줍니다.
지금 Google Cloud에서 Google의 2세대 및 3세대 TPU 슈퍼컴퓨터를 사용할 수 있습니다. 자세히 알아보려면 Cloud TPU 홈페이지를 방문하거나 문서를 참조하세요. Cloud TPU는 TensorFlow와 PyTorch를 지원하며 JAX Cloud TPU 미리보기도 제공합니다.
1. 모든 결과는 2020년 7월 29일에 www.mlperf.org에서 검색한 것입니다. MLPerf의 이름과 로고는 상표입니다. 자세한 내용은 www.mlperf.org를 참조하세요. 차트는 0.7~70과 0.7~17, 0.7~66과 0.7~31, 0.7~68과 0.7~39, 0.7~68과 0.7~34, 0.7~66과 0.7~38, 0.7~67과 0.7~29 결과에 대한 비교를 나타냅니다.
2. 모든 결과는 2020년 7월 29일에 www.mlperf.org에서 검색한 것입니다. MLPerf의 이름과 로고는 상표입니다. 자세한 내용은 www.mlperf.org를 참조하세요. 표는 0.7~68, 0.7~66, 0.7~68, 0.7~66, 0.7~68, 0.7~65, 0.7~68, 0.7~66 결과를 나타냅니다.
3. 모든 결과는 2020년 7월 29일에 www.mlperf.org에서 검색한 것입니다. MLPerf의 이름과 로고는 상표입니다. 자세한 내용은 www.mlperf.org를 참조하세요. 그림은 0.7~70과 0.6~2의 결과에 대한 비교를 나타냅니다.


