Google の Cloud TPU v4 が業界をリードする効率性でエクサフロップス規模の ML を提供

Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 本日は、2 人の伝説的な Google エンジニアが、TPU v4 が ML モデルを大規模にトレーニングするためのプラットフォームとして世界をリードする AI の研究者や開発者に選ばれるに至った「独自のノウハウ」について説明します。Norm Jouppi は、TPU v1 から TPU v4 まで、すべての Google の TPU のチーフ アーキテクトを務めています。Google Fellow であり、全米技術アカデミー(NAE)の会員でもあります。Google 上級エンジニアの David Patterson は、ACM A.M. チューリング賞および NAE チャールズ スターク ドレイパー賞を共同受賞しました。David は RISC と RAID の生みの親であり、近年はML による CO2e 排出量について研究しています。
コンピューティング パフォーマンスのスケーリングは、機械学習(ML)の最先端技術開発の基本です。相互接続技術とドメイン固有アクセラレータ(DSA)の重要なイノベーションのおかげで、Google Cloud TPU v4 が実現しました。
TPU v3 と比べ、ML システムのパフォーマンスのスケーリングが 10 倍近く向上
従来の ML の DSA と比較して、エネルギー効率が最大 2~3 倍向上
一般的なオンプレミス データセンターの DSA と比較して、CO2e を最大 20 倍削減1
その結果、TPU v4 は、大規模言語モデルにとって理想的なパフォーマンス、スケーラビリティ、効率性、可用性を備えるプロダクトとなりました。
TPU v4 は、4,096 個のチップを Google 内で開発された業界最先端の光回路スイッチ(OCS)で相互接続し、エクサスケールの ML パフォーマンスを提供します。以下で、TPU v4 Pod の 8 分の 1 をご覧いただけます。Google の Cloud TPU v4 は、TPU v3 をチップあたりで平均 2.1 倍上回り、1 ワットあたりのパフォーマンスが 2.7 倍向上しています。通常、TPU v4 チップの平均消費電力はたったの 200W です。

である TPU v4 Pod の 8 分の 1 はオクラホマ州にあり、最大 90% がカーボンフリー エネルギーで稼働しています。
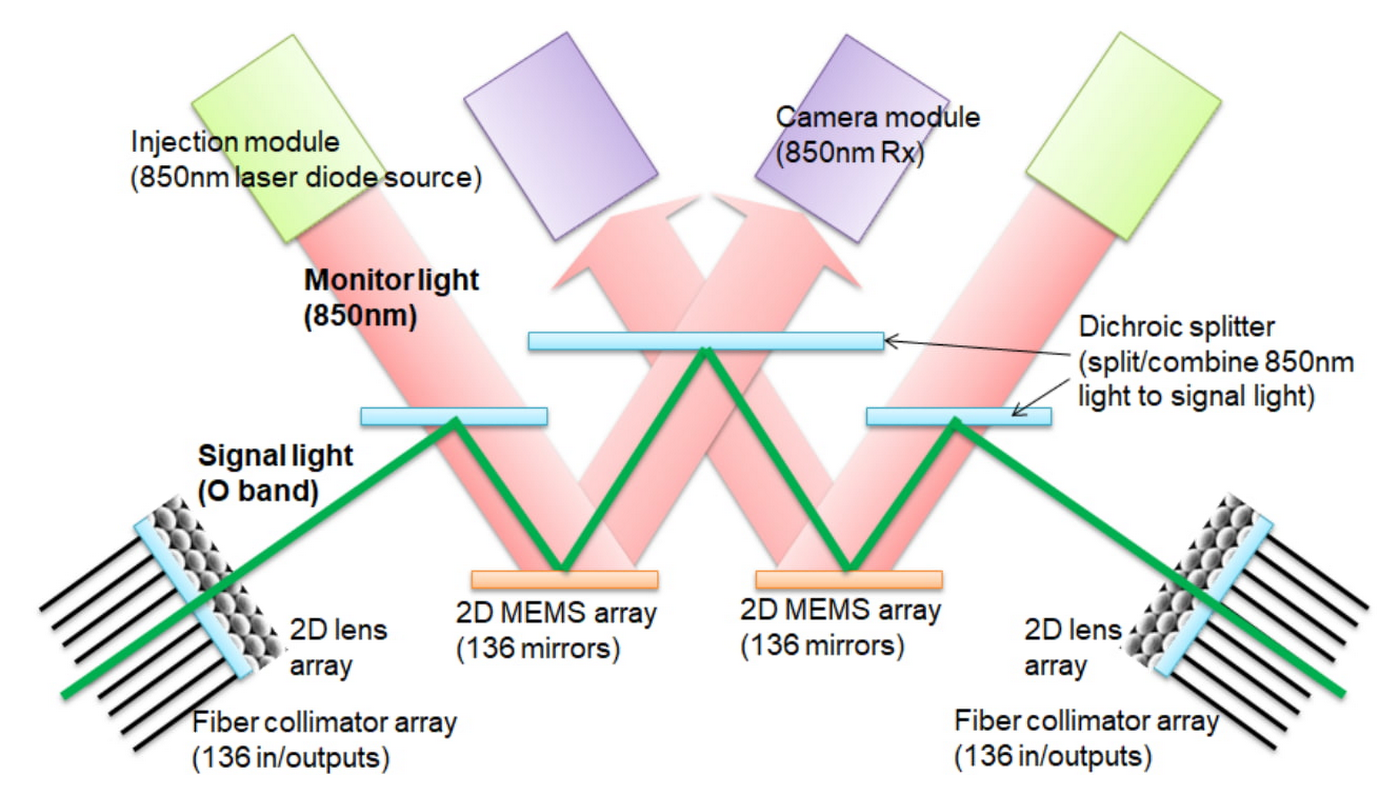
TPU v4 は、再構成可能な OCS をデプロイした最初のスーパーコンピュータです。OCS は、相互接続トポロジを動的に再構成し、スケール、可用性、利用率、モジュール性、デプロイ、セキュリティ、電力、パフォーマンスを向上させます。Infiniband よりもはるかに安価で消費電力量が低く、高速な OCS と基盤となる光コンポーネントは、TPU v4 のシステムにかかる費用の 5% 未満、システム消費電力の 5% 未満です。2 つの MEM 配列を使用した OCS の仕組みを以下の図に示します。光から電気、電気から光への変換や、電力を大量に消費するネットワークのパケット スイッチは必要なく、電力を節約できます。
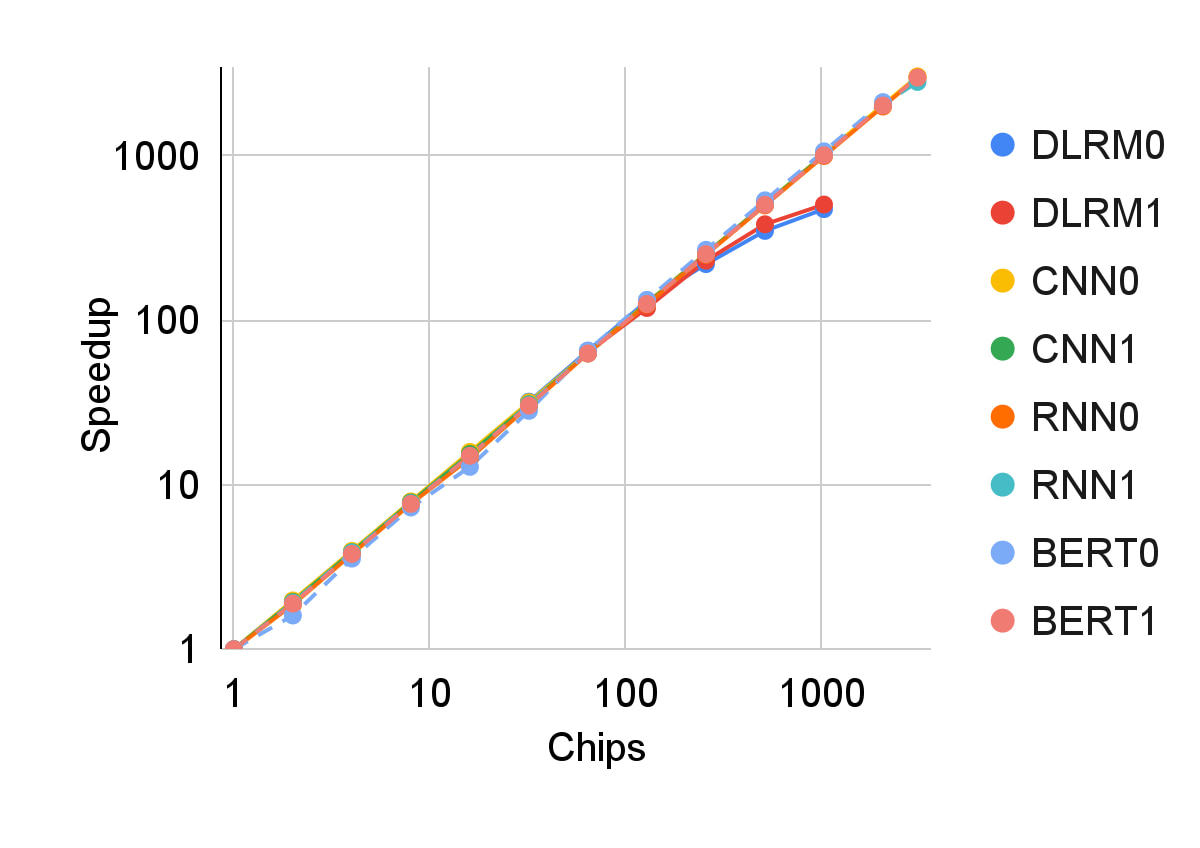
高機能かつ効率的なプロセッサと分散共有メモリシステムの組み合わせは、ディープ ニューラル ネットワーク モデルに優れたスケーラビリティを実現します。さまざまなモデルタイプにおける TPU v4 の本番環境ワークロードのスケーラビリティを、以下に量対数スケールで示します。
動的 OCS の再構築機能も可用性に貢献します。回路の切り替えにより、障害コンポーネントを簡単に迂回できるため、ML トレーニングのような長期的なタスクでは、一度に数千個のプロセッサを数週間にわたって使用できます。この柔軟性により、スーパーコンピュータ相互接続のトポロジを変更して、ML モデルのパフォーマンスを加速させることも可能です。
パフォーマンス、スケーラビリティ、可用性により、TPU は、LaMDA、MUM、PaLM などの主力大規模言語モデルのスーパーコンピュータとして機能します。540B パラメータの PaLM モデルは、なんと 50 日間にわたりピーク時のハードウェア浮動小数点演算性能の 57.8% を維持しながら、TPU v4 スーパーコンピュータをトレーニングします。TPU v4 のスケーラブルな相互接続性は、多次元のモデル パーティショニング技術を生み出し、これらの LM の低レイテンシ、高スループットの推論を実現します。
また、TPU スーパーコンピュータは、広告、検索結果での掲載順位、YouTube、Google Play で使用されているディープ ラーニングのレコメンデーション モデル(DLRM)の主要コンポーネントであるエンベディングのハードウェア サポートを最初に提供しました。各 TPU v4 には、第 3 世代の SparseCores が搭載されています。SparseCores は、エンベディングに依存するモデルを 5~7 倍高速化しながらも、ダイ面積と消費電力をたったの 5% に抑えたデータフロー プロセッサです。
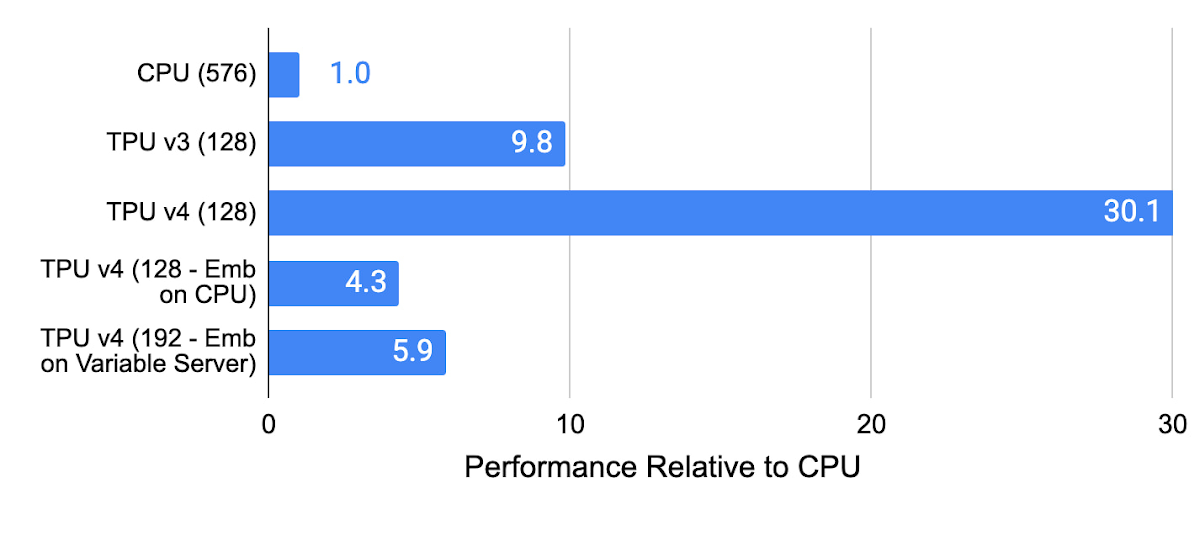
CPU メモリにエンベディングが使用された CPU、TPU v3、TPU v4、TPU v4 の内部レコメンデーション モデルのパフォーマンス(SparseCore 未使用)は以下のとおりです。TPU v4 SparseCore は、レコメンデーション モデルで TPU v3 の 3 倍、CPU を使用したシステムで 5~30 倍の高速化を実現しています。
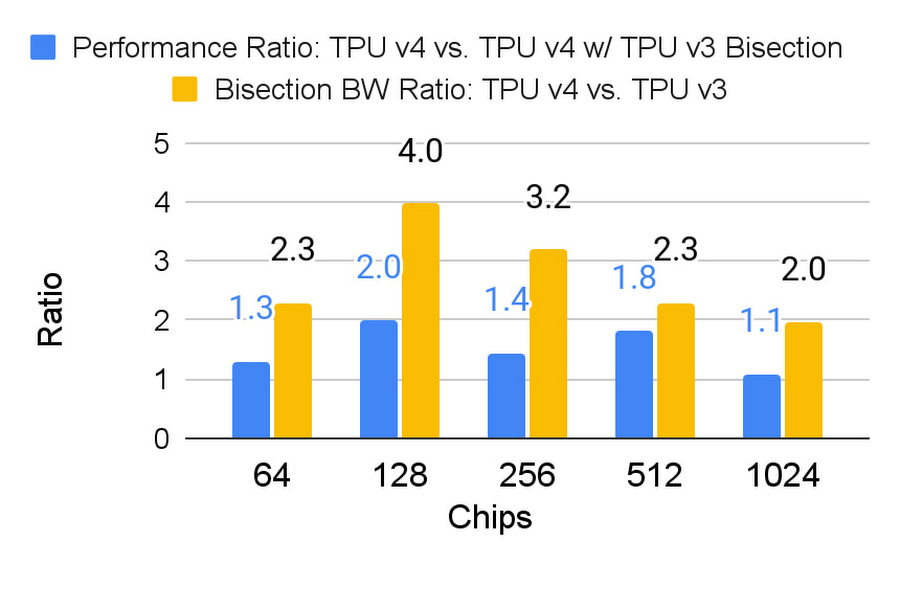
エンベディングの処理は、1 つのモデルで連携される TPU チップに分散しているため、大量の全対全通信が必要です。このパターンは、共有メモリ相互通信の帯域幅にストレスを与えます。そのため、TPU v4 は、(2 次元トーラスで使用される TPU v2 や v3 ではなく)3 次元トーラス相互接続を使用します。TPU v4 の 3 次元トーラスは、より高い二分割帯域幅(相互接続の中央を挟んでチップの半分からもう半分までの帯域幅)を提供し、より多くのチップ数と SparseCore v3 のより高いパフォーマンスに対応しています。下の図は、3 次元トーラスによる帯域幅とパフォーマンスの大幅な向上を示しています。
TPU v4 は 2020 年から Google で運用されており、Google Cloud のお客様には昨年から提供されるようになりました。リリース以来、TPU v4 スーパーコンピュータは、言語モデル、レコメンダー システム、ジェネレーティブ AI など、最先端の ML 研究および本番環境ワークロードのために、世界中のトップクラスの AI チームが積極的に使用しています。たとえば、公共の利益となるような影響力の高い AI 研究を行うことを目的として Paul Allen が設立した非営利研究機関である Allen Institute for AI は、TPU v4 のアーキテクチャから多大な恩恵を受け、多くの大規模で影響力の高い研究イニシアチブを生み出すことができました。
「最近では、多くの研究者が、大量の処理ユニットに簡単に分散できる Cloud TPU に着目しています。GPU の場合、1 台のマシンを超えてスケーリングすると配布用のコードを調整する必要があり、サーバー間の接続速度に失望するかもしれません」と、Allen Institute for AI のエンジニアリング担当シニア ディレクター Michael Schmitz 氏は言います。「しかし、Cloud TPU を使えば、個別のワークロードを数千のチップにシームレスにスケーリングでき、すべてのチップが高速メッシュ ネットワークで互いに直接接続されます。」
Midjourney は、業界をリードする text-to-image AI のスタートアップの一つです。同社は、Cloud TPU v4 を使用して偶然にも「バージョン 4」と呼ばれる最先端モデルをトレーニングしてきました。
「Google Cloud と連携し、Google のグローバルにスケーラブルなインフラストラクチャを活用して、創造性豊かなコミュニティにシームレスな体験を提供できることを誇りに思います」と Midjourney の創業者兼 CEO の David Holz 氏は言います。「最新の v4 TPU で JAX を使ってアルゴリズムのバージョン 4 をトレーニングすることから、GPU で推論を実行することまで、TPU v4 によってユーザーが素晴らしいアイデアを実現するスピードに感動しています。」
TPU v4 研究のその他の詳細を論文で共有できることを誇りに思います。この論文は、コンピュータ アーキテクチャ国際シンポジウムで発表される予定です。そして、この研究結果についてコミュニティと議論できることを楽しみにしています。
著者一同は、TPU v4 を成功に導いた Google の多くのエンジニアリング チームとプロダクト チームに感謝します。また、このブログ投稿の執筆にご協力いただいた Amin Vahdat、Mark Lohmeyer、Maud Texier、James Bradbury、Max Sapozhnikov に感謝いたします。
1. この最大で 20 倍の改善は、エネルギー効率が最大で 2~3 倍高い TPU、オンプレミス データセンターに比べて PUE が最大で 1.4 倍低い Google データセンター、一般的なオンプレミス データセンターの平均のエネルギー クリーン度と比べてすべての Cloud TPU v4 スーパーコンピュータを収容するオクラホマ州のエネルギーが最大で 6 倍クリーンであることの組み合わせによるものです。
- Google、Google Fellow Norm Jouppi
- Google Brain、Google 上級エンジニア David Patterson
