Google Cloud における医療テキストの処理
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
FDA には、医薬品承認プロセスの不可欠な要素としてリアルワールド エビデンス(RWE)を使用してきた歴史があります。さらに、一部の臨床試験では、RWE によりプラセボの必要性を軽減できます。しかし、RWE を有用なものにする臨床記録は、医師のメモなどの非構造化形式で存在することが多く、それらの臨床データを構造化形式に「抽象化」する必要があります。クラウド テクノロジーと AI を利用すると、このプロセスを加速させることができるため、その期間が大幅に短縮化し、拡張性も高まります。
第一線の医薬品研究者は、FDA への試験申請に向けて、リアルワールド データで臨床試験を補強することを始めています。時間の節約になり、費用対効果も向上するためです。ですが、患者の治療が終了すると、患者がこれまでに受けた医療データが、膨大な量で構造化されていない形で残ることになり、ストレージ ニーズの増加につながります。非構造化データは、臨床意思決定支援システムにとって重要であり不可欠です。元の非構造化形式から分析情報を得ようとすれば、人がその非構造化データをレビューしなければなりません。分析情報を迅速に引き出せる個別のデータポイントがないため、構造化されていない医療データは、治療のギャップや差異の増幅につながる可能性があります。単純に考えても、この患者データすべてを抽象化するのに、人の手だけに頼った作業では速さも正確性も不十分であることはわかります。Google Cloud 上のサーバーレス ソフトウェア コンポーネントを使用した応用自然言語処理(NLP)は、優先すべき患者医療文書を特定してリスト化し、臨床データの抽象化担当者をこのリストへと効率よく誘導します。
Google Cloud における医療テキスト処理の実行方法
Google Cloud の Vertex Workbench Jupyter ノートブックを使用すると、未加工の臨床テキスト ドキュメントを取得して、Google Cloud の Healthcare Natural Language API を通じて処理し、構造化された JSON 出力を BigQuery に取り込むデータ パイプラインを作成できます。そこから、ラベルの数や関係など、臨床テキストの特性を表示できるダッシュボードを構築できます。ここから、テキストを抽出でき、また人がラベル付けすることで時間とともにさらに改良できる、トレーニング可能な言語モデルを構築できるようになります。
このソリューションがこれらの課題にどのように対処するかについて理解を深めるために、医療テキスト エンティティの抽出ワークフローを確認してみましょう。
- データ取り込みのための Document AI: このシステムは、医師の手書きのメモやその他の非構造化テキストなど、匿名化された医療テキストを含む PDF ファイルから始まります。この非構造化データは、まず光学式文字認識(OCR)技術を使用して Document AI によって処理され、テキストと画像がデジタル化されます。
- 自然言語処理: Cloud Natural Language API には、医療テキストの抽出と分類のためのモデルなど、事前トレーニングされたモデルのセットが含まれています。このサービスの出力の一部として生成されるラベルは、Vertex AI AutoML サービスの「正解」ラベルとして機能し、Vertex AI AutoML サービスにドメイン固有のカスタム ラベルが追加されます。
- Vertex AI AutoML: Vertex AI AutoML は、Google モデルを使用して、人間参加型のデータセットのラベル付けと自動ラベル分類のための機械学習ツールセットを提供します。Google モデルは、チームメンバーがコーディングやデータ サイエンスの専門知識をほとんど持っていない場合でも、データを使用してトレーニングできます。
- BigQuery テーブル: NLP 処理されたレコードは、さらなる処理と可視化のために BigQuery に保存されます。
- Looker ダッシュボード: Looker ダッシュボードは、臨床テキストの抽象化プロセスの中心的な「頭脳」として機能します。ここでの可視化により、チームはタグやコンセプトの「密度」などの指標を使用して最も優先度の高い臨床文書を特定できるようになります。
- Python Jupyter ノートブック: Colab(無料)ノートブックまたは Vertex AI(エンタープライズ)ノートブックを使用して、テキストデータを探索し、取り込みと NLP 用のさまざまな API を呼び出します。
Healthcare Natural Language API
Healthcare Natural Language API を使用すると、次の最適化に重点を置くことで、医療テキスト エンティティの処理を大規模かつ効率的に実行できます。
- スケーラブルな Cloud Functions を使用してドキュメント処理を並列実行することにより、ドキュメント OCR とデータ抽出を最適化します。
- 完全にサーバーレスなマネージド サービスを使用して、コストと製品化までの時間を最適化します。
- ML による人間参加型の抽象化を組み込んだ、柔軟で包括的なワークフローを促進します。
次の図は、ソリューションのアーキテクチャを示したものです。
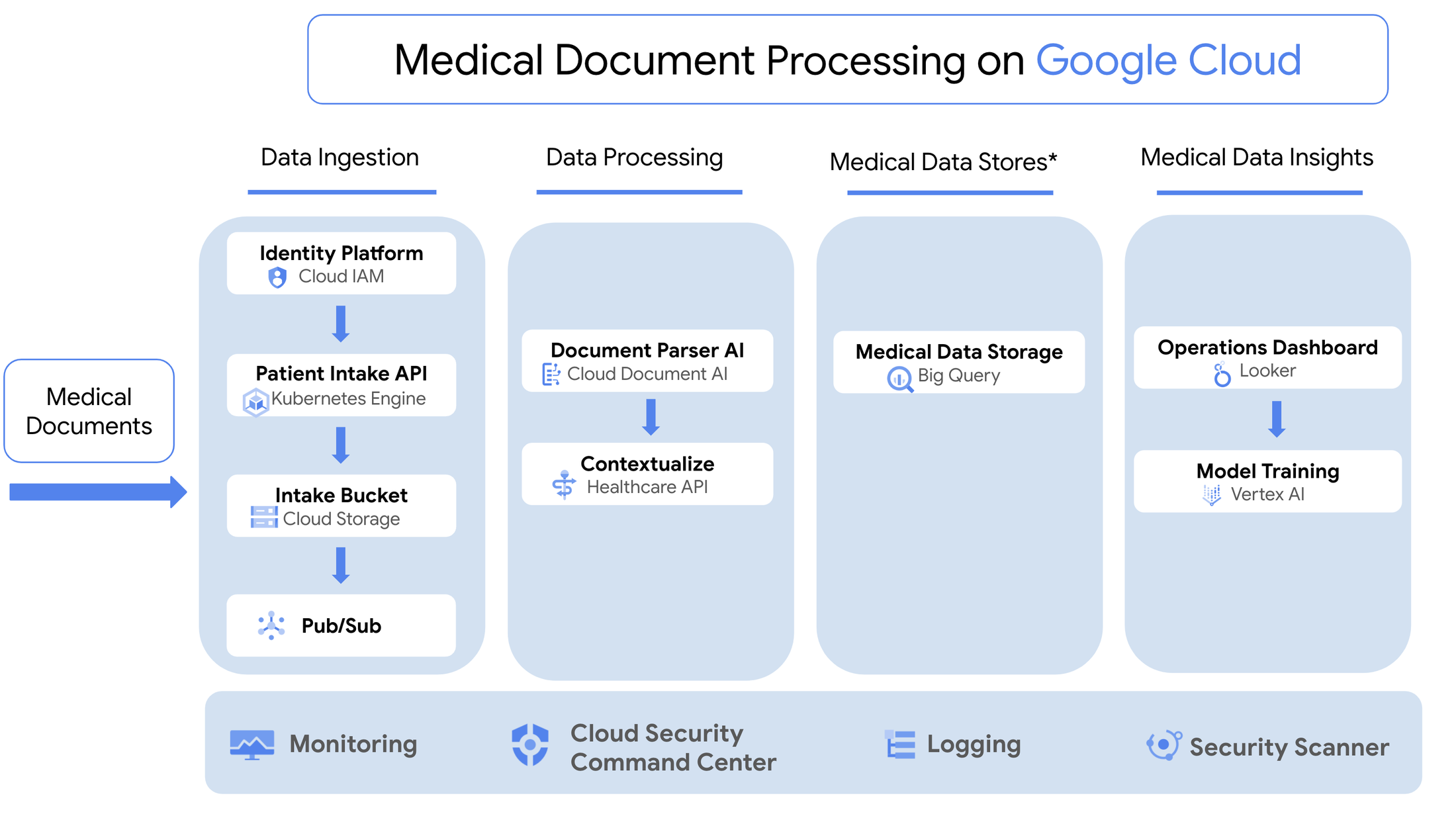
- Jupyter ノートブックまたは Google Cloud Functions から実行でき、NLP 処理パイプラインのさまざまな段階を動作させる再利用可能な Python スクリプトのセット。医療テキストを構造化患者データに変換して、Looker ダッシュボードに表示し、これが臨床データの抽象化担当者チームの意思決定支援インターフェースとして機能します。
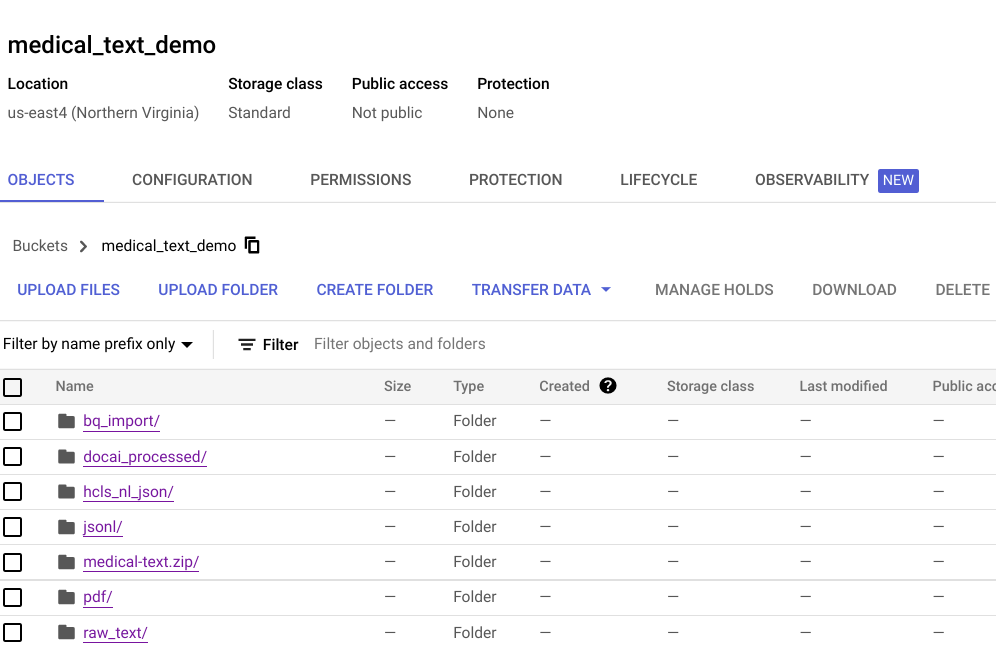
- データ処理のさまざまな段階をサポートする一連の Google Cloud Storage バケット(下図参照)。
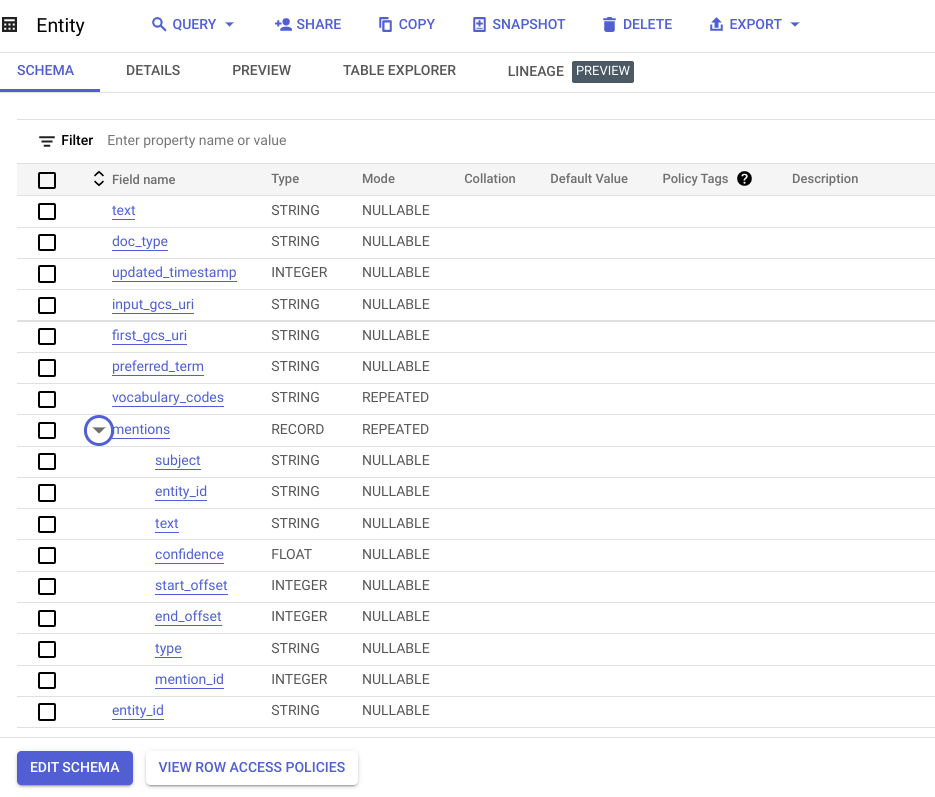
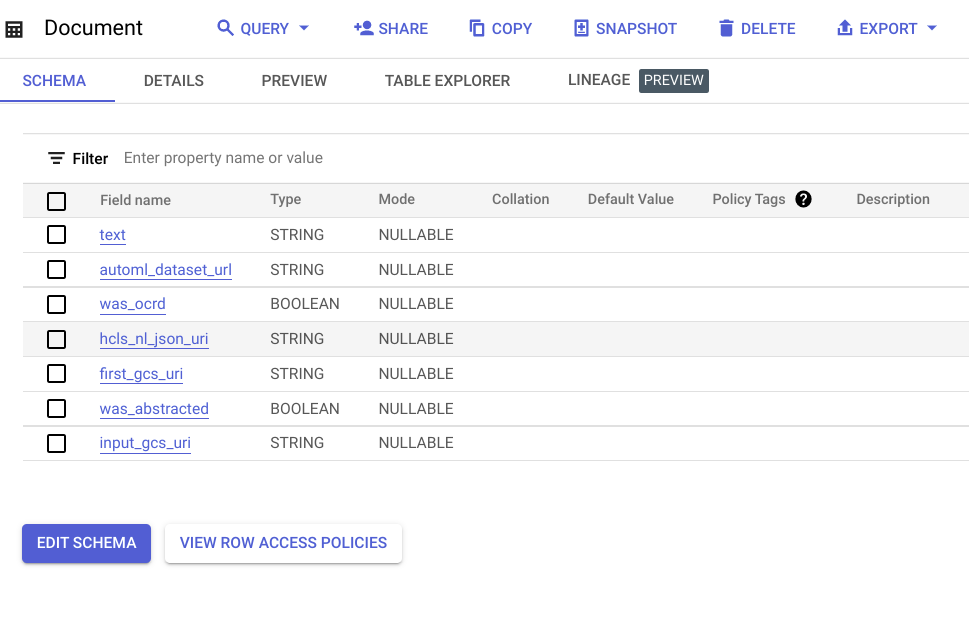
- 「エンティティ」というデータセット内に「Entity」と「Document」という 2 つの BigQuery テーブルが、Looker ダッシュボードのデータモデルとして作成されます。
- 臨床データの抽象化担当者が人間参加型のラベル付けに使用する Vertex AI データセット。これを使用して Google Vertex AI Labeling チームにラベル付けのリクエストを送信することで、柔軟性と拡張性が高まります。
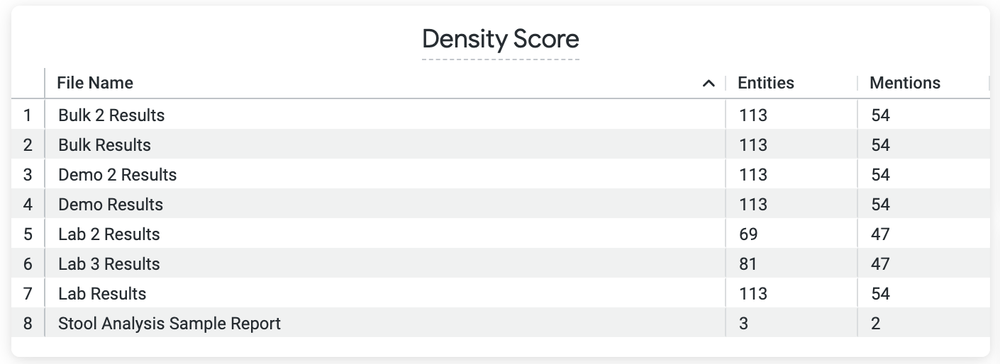
- カスタムの「密度」指標(ドキュメント内で見つかったデータ要素(ラベル)の数)に基づいて抽象化担当者が処理すべきドキュメントの順番をスタックランキングで表示する Looker ダッシュボード。このダッシュボードでは、抽象化担当者はまずスパース(低密度)にラベル付けされたドキュメントに注目でき、Google の NLP に面倒な作業を任せることができます。
密度スコア別のドキュメントのリストを見ることで、抽象化担当者は、多くの作業が必要なドキュメントと、軽いレビューのみで済むドキュメントを判別できます。
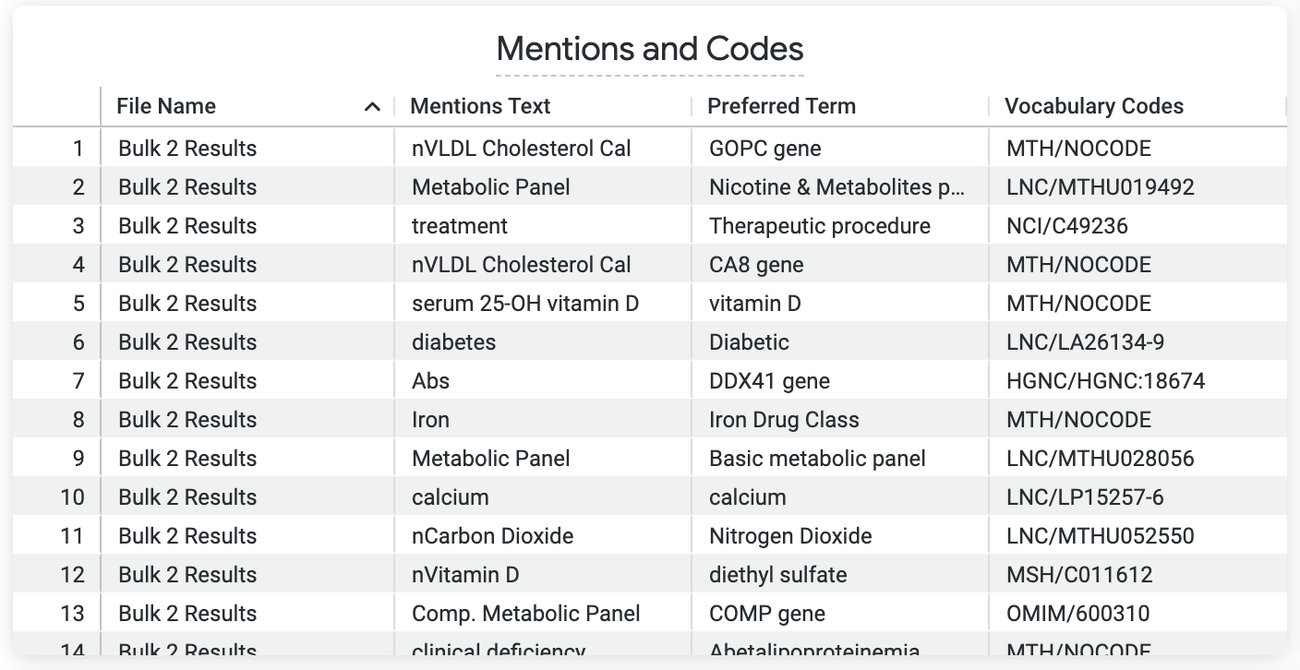
この Look(ビュー)は、Google Healthcare Natural Language API によって UMLS 臨床オントロジーにマッピングされた、コード化された医療テキストを示しています。
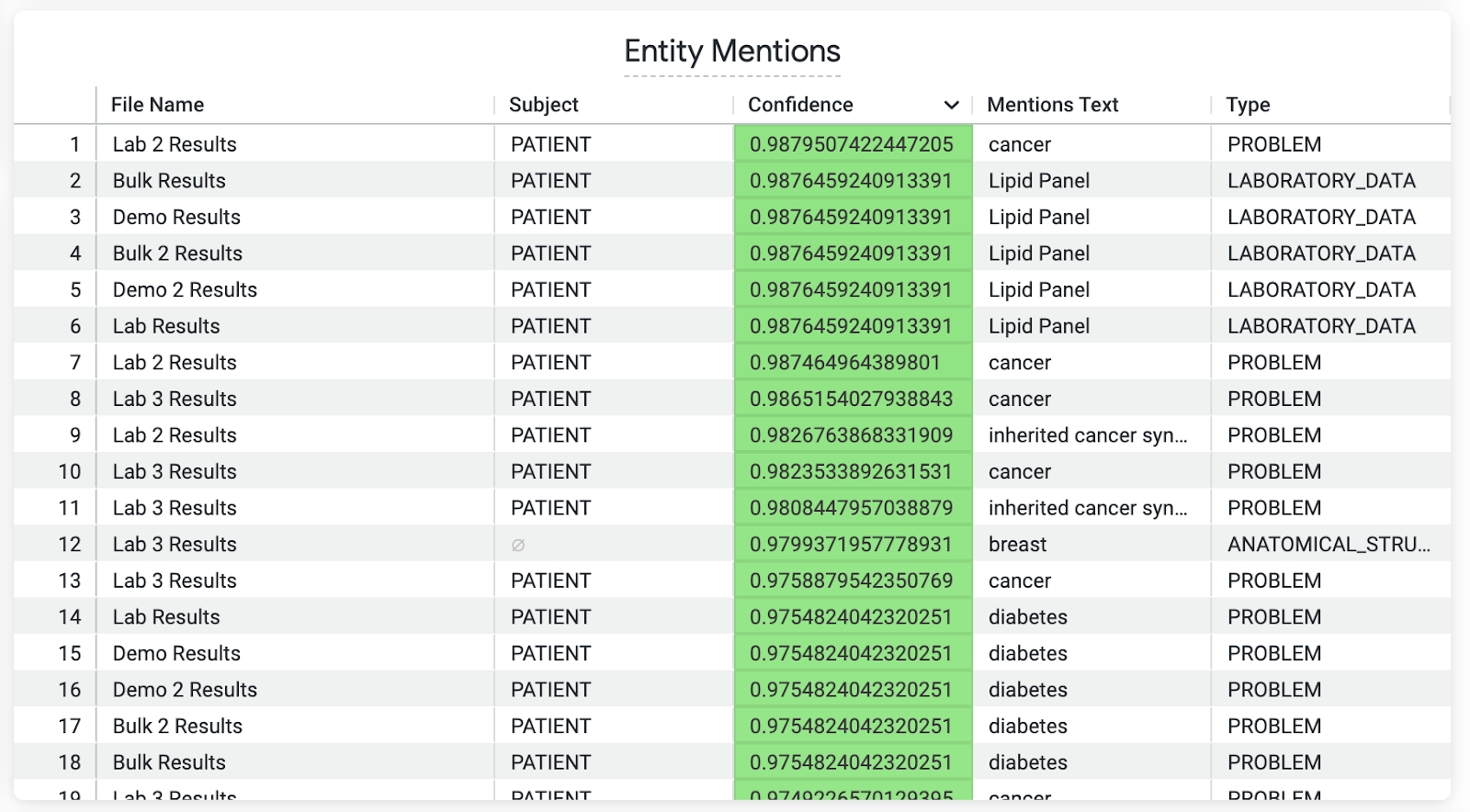
この Look(ビュー)は、エンティティへの言及を示しており、各言及の主題とその信頼度スコアといった情報も表示されます。これにより、生物医学ナレッジグラフに読み込んで、詳細な下流分析を行えます。
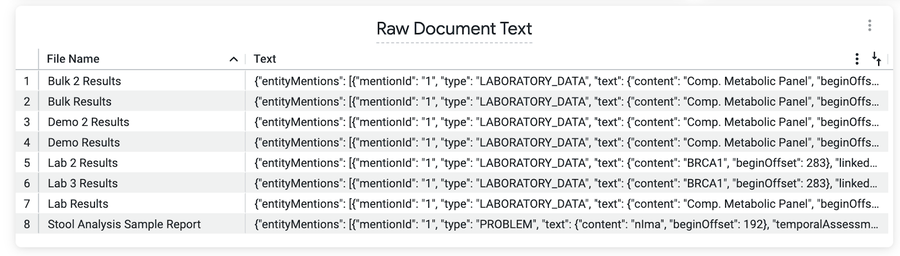
この Look(ビュー)は、未加工のドキュメント テキスト内で見つかったエンティティへの言及を示しています。
今後のトピックと次のステップ
このデモでは、エンティティとドキュメントのメタデータを BigQuery と Looker に読み込みましたが、Healthcare Natural Language API からすぐに使える豊富な関係は読み込んでいません。これらの関係を使用すると、生物医学ナレッジグラフを作成して、疾患・治療・コホートの道筋をたどり、これらの事実を結び付ける新しい仮説を立てられるようになります。
Looker を使用して作成したダッシュボードは、必要最低限の機能しか備えていませんが、Looker には、ドキュメントのレビューが可能なときにチャットなどのチャネルにプッシュする機能や、関連エンティティの医療ナレッジグラフとして患者を可視化する機能、ML 予測を Looker LookML 自体に直接埋め込む機能など、豊富な機能があります。このダッシュボードは、Looker を活用した臨床情報科学の出発点と考えてください。
Healthcare Natural Language API の詳細については、プロダクト ページをご覧ください。ご自身で試してみるには、こちらのデモのリンクをご覧ください。
この医療テキストの例をラベル付けのために Vertex AI データセットに読み込む方法については、Google Cloud バイオテクノロジー チームにお問い合わせください。
データのプライバシー
このブログ投稿には実際の患者データは一切使用されていません。データを制御しているのは、Google Cloud のお客様です。医療現場において、患者データへのアクセスとデータの利用は信頼性の高い Google Cloud のインフラストラクチャと安全なデータ ストレージの実装により保護されます。このインフラストラクチャとストレージは HIPAA コンプライアンスに準拠しており、お客様ごとに異なるセキュリティ、プライバシー管理、プロセスの要件にも対応できます。Google Cloud のデータのプライバシーの詳細については、こちらのリンクをご覧ください。
-カスタマー エンジニア - データ、分析、ML スペシャリストAlex Burdenko
-カスタマー エンジニア - データ、分析、ML スペシャリストJoan Kallogjeri



