CI / CD システムとしてのモデル トレーニング: パート I
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
ソフトウェア エンジニアリングには、継続的インテグレーション(CI)と継続的デリバリー(CD)という非常に重要な 2 つのコンセプトがあります。CI は、信頼性と継続性を保ちながらシステムに変更(新機能、承認コードの commit など)を統合する際に実施します。CD は、信頼性と継続性を保ちながらそうした変更をデプロイする際に実施します。CI と CD はそれぞれを分離して実施することも、組み合わせて実施することもできます。
機械学習(ML)システムは本質的にソフトウェア システムです。そのため、そのようなシステムを大規模に運用するには、迅速なテスト、統合、デプロイを容易にするために、CI / CD を実践する必要があります。次のようなシナリオが考えられます。
ML エンジニアは、パフォーマンス向上のために新しいモデル アーキテクチャをテストすることがよくあります。何も損傷することなく、信頼性を確保したままそれらをシステムに統合するにはどうすればよいでしょうか?
新しいデータが利用できるようになった際に、新しいトレーニングの実施を自動的にトリガーし、システムが最新のデータに適合できるようにするにはどうすればよいでしょうか?
新たにトレーニングされたモデルを、ステージング、本番前環境、本番環境などの異なる環境にデプロイするにはどうすればよいでしょうか?
新しいモデルをシステムに統合することは、新機能を追加することに似ています。大規模な運用の場合、これらの新しいモデルの数は短期間で急速に増加することがあります。これが、CI / CD に手動プロセスで対応することが一般的ではない理由です。ML アプリケーション向けに復元性のある CI / CD システムを用意することが成功に欠かせない理由の詳細については、こちらのドキュメントをご覧ください。
この 2 部シリーズのブログ投稿では、特にモデル トレーニングの観点から、CI / CD の 2 つの異なるシナリオを紹介します。今回の第 1 部では、事前構築されたコンポーネントを使用して、完全な TFX プロジェクトをビルドする方法と、コードベースの変更に応じて Vertex AI で自動でパイプラインを実行する方法を紹介します。
この投稿では学習内容を利用してビルドし、それを拡張して異なるトリガーに基づいて実行を自動でトリガーさせます。Pub/Sub、Cloud Functions、Cloud Scheduler を、TensorFlow Extended(TFX)と Vertex AI とともに使用します。
このシリーズの投稿内容を十分に理解していただくには、基本的な MLOps の用語、TFX、Vertex AI、GitHub Action に精通していることが前提になります。
アプローチ
このセクションでは、開発する 2 つのワークフローの概略図を導入し、完成予想図を想像できるようにします。
最初のワークフローでは、以下の手順を行います。
TFX CLI から TFX パイプライン プロジェクト全体を作成します。
一部の構成を変更して Vertex AI を活用し、このプロジェクトのすべてのコードベースが含まれる、tfx-pipeline ディレクトリ内のすべての変更を検出してトリガーさせる、GitHub Action ワークフローを設定します。
GitHub Action が実行されると、Cloud Build プロセスが開始されます。
開始された Cloud Build プロセスはリポジトリ全体のクローンを作成し、変更されたコードベースに基づいて新しい Docker イメージをビルドします。そして、Docker イメージを Google Container Registry(GCR)に push し、TFX パイプラインを Vertex AI に送信します。
ビルドプロセスを管理するため、Google Cloud Platform(GCP)が提供する、サーバーレスでフルマネージドの CI / CD システムである Cloud Build を使用します。他には、CircleCI や Jenkins なども使用できます。また、GitHub Action ワークフローにコードベース内の特定の変更をモニタリングさせ、前述のワークフローを自動で開始できるようにします。
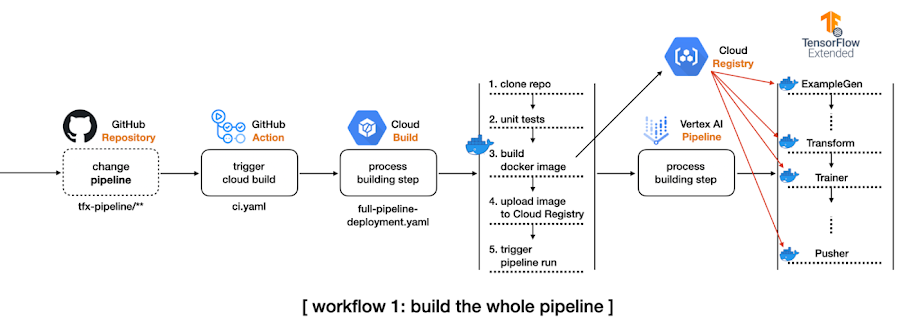
TFX パイプラインは、ExampleGen から Pusher までの多くのコンポーネントで構成され、各コンポーネントは同じ Docker イメージに基づいて実行されます。最初のワークフローは、コードベースの変更時に毎回 Docker イメージをビルドする方法を示しています。これはこのリポジトリのメインブランチで実証されています。
2 つ目のワークフローでは、ギアを少し上げて次の変更を取り込みます。
TFX Transform コンポーネントと Trainer コンポーネントのデータ処理およびモデリング コードをそれぞれ分離し、TFX パイプライン プロジェクトを個別のディレクトリであるモジュールにします。これらのモジュールは、Cloud Build プロセスのように GCS バケットに保存されます。
パイプラインのソースコードを変更し、TFX Transform コンポーネントと Trainer コンポーネントが GCS バケット内のモジュールを参照できるようにします。このようにして、2 つのモジュールの変更に基づいて新しい Docker イメージをビルドする必要がなくなります。
モジュールのディレクトリ内のすべての変更を検出してトリガーさせる、もう 1 つの GitHub Action ワークフローを設定します。
GitHub Action が起動されると、もう 1 つの Cloud Build プロセスが開始されます。
開始された Cloud Build プロセスはリポジトリ全体のクローンを作成し、モジュールのディレクトリ内のファイルのみを GCS バケットにコピーして、TFX パイプラインを Vertex AI に送信します。
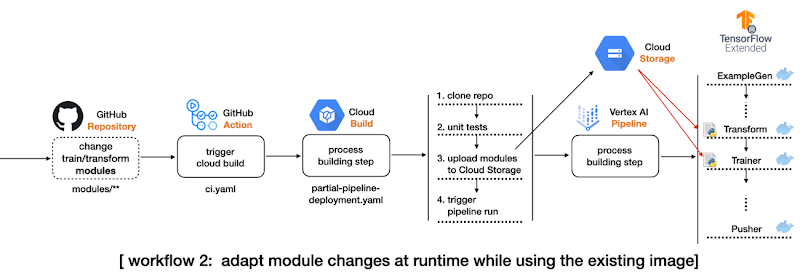
2 つ目のワークフローは、このリポジトリのテスト分離ブランチで実証されます。
実装の詳細
TFX をベースにした MLOps プロジェクトは、入力データセットに対応する ExampleGen から、本番環境向けのトレーニング済みモデルを保存または配信する Pusher までの、多くのコンポーネントで構成されています。これらのコンポーネントの相互接続の仕組みを理解し、各コンポーネントでどの構成が可能なのかを確認することは重要です。
このセクションでは、自分で最初から作成するのではなく、完全な TFX ベースの MLOps プロジェクト テンプレートで開始できるようにする TFX CLI ツールの使用方法を紹介します。
TFX CLI を使用した最初の TFX プロジェクト
現在、taxi と penguin という 2 つのテンプレート プロジェクトがあります。今回の投稿では taxi テンプレートを使用します。次の TFX CLI は、taxi テンプレートに基づいて新しい TFX プロジェクトを生成する方法を示しています。使用するテンプレートは --model で、パイプラインの名前は --pipeline-name で、生成されたプロジェクトを保存するパスは --destination-path で指定できます。
CLI でテンプレートが作成されたら、そのディレクトリ構造を調べてみましょう(caching、testing、__init__.py などの重要でない一部のファイルはスペース削減のために省略されていますが、TFX パイプラインの理解に最も重要なファイルは記載されています)。
この投稿では、すべてのファイルとディレクトリを個別に説明することはしませんが、投稿の目的として最も重要なものをいくつか説明します。kubeflow_v2_runner.py は、Kubeflow 2.x 環境でパイプラインを実行することを明示的に宣言し、Vertex AI をバックエンドのオーケストレーターとして活用するために使用する必要があります。models ディレクトリは、データの前処理とモデリングのための一連の事前定義されたモジュールを提供し、各モジュールにはテスト テンプレートもあります。pipeline.py は TFX パイプラインの作成方法を定義し、configs.py は TFX コンポーネントまで渡されるすべてのパラメータの構成のためのものです。
TFX CLI の概要とテンプレート プロジェクトに含まれる内容の詳細については、TFX CLI の公式ドキュメント と、取り組み中の Codelab をご覧ください。
TFX プロジェクトのコンパイルとビルド
TFX パイプラインの実行方法は 2 つあります。第 1 の方法は Python API をソースコードから直接使用することです。この方法は第 2 回のブログ投稿で取り扱います。このブログ投稿では、第 2 の方法である TFX CLI の使用について説明します。
tfx pipeline create コマンドにより、指定したオーケストレーターに新しいパイプラインが作成され、基盤となるオーケストレーターは --engine で指定できます。Vertex AI プラットフォームでパイプラインを実行するため、vertex に設定されていますが、kubeflow、local、airflow、beam などの他のオプションも選択できます。
さらに 2 つの重要なフラグとして、--pipeline-path と --build-image があります。最初のフラグの値は、オーケストレーターが vertex または Kubeflow 2.x. である場合にテンプレートにより提供される、kubeflow_v2_runner.py に設定する必要があります。Kubeflow 1.x またはローカル環境でパイプラインを実行する予定の場合は、kubeflow_runner.py と local_runner.py もあります。
--build-image はオプションのフラグであり、カスタムの TFX Docker イメージをビルドまたは更新する場合に設定する必要があります。イメージ名は、パイプライン全体のすべての構成を管理する pipeline/configs.py 内の PIPELINE_IMAGE 変数で変更できます。
tfx pipeline create コマンドの後に、もう 1 つの CLI コマンドである tfx run create を使用して Vertex AI プラットフォームでパイプラインを実行できます。--pipeline_name の値は tfx template copy で使用したパイプライン名と一致する必要があります。pipeline/configs.py の PIPELINE_NAME 変数で後で名前を変更することもできますが、その場合 tfx pipeline create コマンドを再実行する必要があります。
Vertex AI プラットフォームのベースは Kubeflow 2.x ですが、主な違いの一つは GCP にサーバーレスのプラットフォームとしてホストされている点です。つまり、基盤となる GKE と Kubeflow インフラストラクチャの管理が不要となります。Google によって完全に管理されています。Vertex AI よりも前は、GKE クラスタを作成および管理し、その上に Kubeflow プラットフォームを自分でインストールする必要がありました。
このような変更がどのように反映されるかは、--project および --region フラグが明確に示しています。Vertex AI なしでは、Kubeflow が実行中の --endpoint を設定する必要がありましたが、TFX にパイプラインを実行する場所を指定するだけで済み、方法について考える必要はありません。
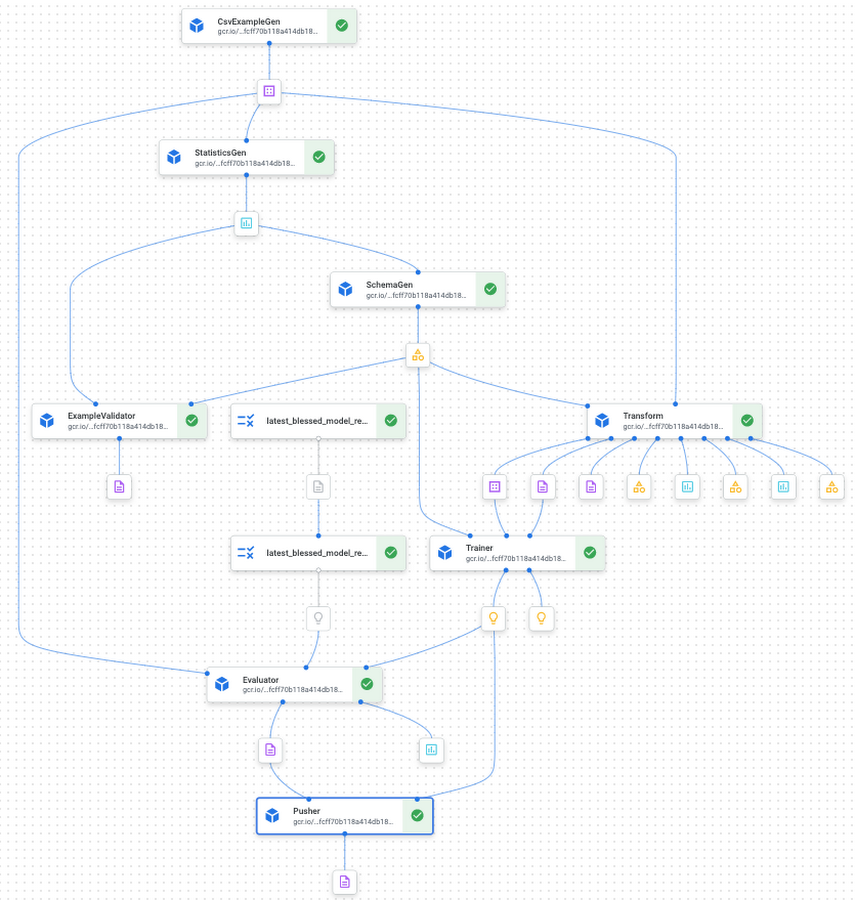
tfx run create コマンドの実行後、GCP Console で Vertex AI パイプラインにアクセスすると、図 3 のような表示になります。テンプレート プロジェクトでは、すべての標準 TFX コンポーネントが相互接続され、コード不要で MLOps パイプラインを提供するため、出発点として優れていることがわかります。
最初のワークフロー用に GitHub Action と Cloud Build を設定する
以下の YAML ファイルは、メインブランチの push イベントによりトリガーされる GitHub Action を定義しています。
dorny/paths-filter GitHub Action により、push の指定されたパスに変更があったかどうかを検出できます。この例では、パスは tfx-pipeline として指定されており、パイプラインを定義しているコードベースの変更により、steps.tfx-pipeline-change.outputs.src が true に設定される必要があります。
steps.tfx-pipeline-change.outputs.src が true の場合、Cloud Build を送信する次のステップに進めます。Cloud Build の仕様は以下のように定義され、$ 記号で始まる環境値は --substitutions によって挿入されます。
最初は読みにくいですが、Cloud Build の仕様を注意深く読めば、リポジトリのクローン作成、models ディレクトリの下の 3 つの *_test.py ファイルに基づく単体テストの実行、tfx pipeline create コマンドの実行、tfx run create コマンドの実行という順序で 4 つの手順があることがわかります。最後の 2 つの手順は、前述のセクション「TFX プロジェクトのコンパイルとビルド」で説明しています。
Docker イメージの 'gcr.io/gcp-ml-172005/cb-tfx' が、name: python の手順の標準 Python イメージの代わりに使用されている理由を疑問に思われるかも知れません。これは、標準 Python イメージにより提供される Python のバージョンが 3.9 であり、最新の TFX バージョンは Python 3.8 のみをサポートしているためです。以下は、cb-tfx Docker ファイルをビルドし、TFX CLI および単体テストの実行に必要な、1.0 以降のバージョンの TFX、kfp、pytest を有効化するための Dockerfile です。
tfx-pipeline ディレクトリの下に変更を加えると、Cloud Build プロセスが起動し、図 4 のように、GCP Console の Cloud Build ダッシュボードでステータスを確認できます。
TFX を使用した MLOps プロジェクト用に、CI / CD パイプライン全体をビルドしました。しかし、さらに改善の余地があります。毎回 Docker イメージをビルドするのは、システムで時間と費用がさらにかかる原因となるため、できるだけこの手順を避けるのが理想的です。次のセクションで、この対処法を確認しましょう。
既存の TFX プロジェクトからモジュールを分離する
2 つの標準 TFX コンポーネントである Transform と Trainer を実行するには、元データを前処理する方法とモデルをビルドおよび実行する方法が格納された、別々のファイルでコードを提供する必要があります。それには 2 つの方法があります。
第 1 の方法は、Trainer と Transform 用にそれぞれ run_fn と preprocessing_fn パラメータを使用すること、第 2 の方法は両方のコンポーネントに module_file パラメータを使用することです。最初のオプションは、ファイルが Docker イメージに含まれ、アクションをトリガーする関数を指定する場合に使用できます。たとえば、生成されたテンプレート プロジェクトで、run_fn を run_fn=models.run_fn として設定します。2 番目の方法もファイルが Docker イメージに含まれている場合に使用できますが、ファイルには指定の関数名である run_fn と preprocessing_fn が必要で、コンポーネントにより認識されます。
ただし、最も重要な違いの一つに、ファイルを GCS バケットから直接挿入できる点があります。この場合、ファイルを Docker イメージに含める必要はなく、module_file パラメータに GCS パスを指定するだけです。
そのためには、configs.py 内の PREPROCESSING_FN と RUN_FN 変数を先ほどと同様に変更します。ご覧のとおり、モジュールに関数名ではなくファイルが格納された GCS パスを指定します。
また、GCS バケットは Python ファイル システムについての情報を一切持たないストレージ システムにすぎないため、すべての関数と変数を単一のファイルに含める必要があります。次に、2 つのファイルを別のディレクトリ modules に保存します。
この方法の欠点の一つとして、単一のファイルにすべてを含める必要があります。たとえば、モデル、トレーニング手順、配信用署名などの定義用に個別のファイルを用意することはできません。これによりコード管理と可読性が多少損なわれますが、これらのファイルが変更された際に新しい Docker イメージをビルドする必要がなくなります。そのため、トレードオフとなっています。
2 つ目のワークフロー用に GitHub Action と Cloud Build を設定する
元の GitHub Action スクリプトは、以下のようにこの変更に合わせて修正する必要があります。ご覧のとおり、modules ディレクトリにはもう 1 つのフィルタが定義され、steps.change.outputs.modules が true の場合に Cloud Build プロセスをトリガーするためのもう 1 つのステップが定義されています。
新しい Docker イメージをビルドし、パイプライン自体が変更された際に Vertex AI 上にパイプラインを起動する、元のワークフローは引き続き処理されます。modules ディレクトリになんらかの変更が検出された場合に、別ファイル partial-pipeline-deployment.yaml で定義された別の Cloud Build プロセスをトリガーする、もう 1 つのワークフローを追加しました。
以下は、partial-pipeline-deployment.yaml の定義方法を示しています。
Clone Repository と Create Pipeline 手順の間に、modules ディレクトリのファイルを指定の GCS バケットにコピーする、追加の手順を 1 つ追加しました。また、お気づきかもしれませんが、tfx pipeline create コマンドの --build-image オプション フラグは削除されています。これ以上、新しい Docker イメージをビルドする必要がないからです。
料金
Vertex AI Training は、パイプラインとは別個のサービスです。Vertex AI Pipelines は個別に課金され、パイプライン実行あたり約 $0.03 の料金です。各 TFX コンポーネントのコンピューティング インスタンスのタイプは e2-standard-4 で、1 時間あたり約 $0.134 の料金です。パイプライン全体は終了までに 1 時間かからないため、合計料金は Vertex AI Pipelines の実行あたり約 $0.164 と予想できます。
カスタムモデルのトレーニングの料金は、マシンのタイプと時間数によって決まります。また、サーバーとアクセラレータの料金を別途検討する必要があります。このプロジェクトでは、1 時間あたり $0.19 の料金の n1-standard-4 マシンタイプと、1 時間あたり $0.45 の料金の NVIDIA_TESLA_K80 アクセラレータ タイプを選択しました。各モデルのトレーニングは 1 時間未満で終了したため、料金は合計で約 $1.28 でした。
Cloud Build の料金は、マシンのタイプと実行する時間数にもよります。n1-highcpu-8 インスタンスを使用し、ジョブは 1 時間以内に完了しました。その場合、Cloud Build の実行の合計料金は 1 時間あたり約 $0.016 です。
これらを合計すると、このプロジェクトの合計料金は約 $1.46 です。料金については、公式ドキュメントの Vertex AI 料金リファレンス、Cloud Build 料金リファレンスをご覧ください。
まとめ
ここまでに、3 つのワークフローのデモを行いました。最初の手順では、TFX CLI を使用して TFX MLOps プロジェクト全体を作成し、新しい Docker イメージをビルドして、Vertex AI プラットフォームでパイプラインを起動する方法を紹介しました。2 つ目の手順では、GitHub Action と Cloud Build を統合して CI / CD システムをビルドし、コードベース内のすべての変更に適用する方法を紹介しました。最後に、データの前処理とモデリング モジュールをパイプラインから分離させ、可能な場合は新しい Docker イメージをビルドする必要がないようにする方法を紹介しました。
これは優れた方法ですが、以下のような問題もあります。
スケジュール(通常はユースケースに依存)を維持して Vertex AI でパイプラインの実行をトリガーする場合はどうなるでしょうか。
テスト段階で、新しいアーキテクチャが Pub/Sub トピックとして公開されるたびに、同じパイプラインを実行させる(ただし異なるハイパーパラメータで)システムが必要な場合はどうなるでしょうか。
これは、コードの変更を GitHub に commit し、そこから実行をトリガーするのとは異なります。デベロッパーはまず、最善の結果を出した変更(モデル アーキテクチャやハイパーパラメータなど)をテストおよび commit したいと考えるかもしれません。ブログの第 2 回では、こうしたシナリオに対処し、関連ソリューションについて説明します。
謝辞
Google によるテストをサポートするために GCP クレジットを提供いただいた ML-GDE プログラムに感謝申し上げます。レビューに協力いただいた Google の Karl Weinmeister に感謝します。
- 機械学習 GDE Sayak Paul
- ML Google Developer Expert Chansung Park