エージェント型 chatbot に高速で信頼性の高い長期メモリを提供
Aishwarya Prabhat
AI Solutions Acceleration Architect
Yun Pang
Principal Architect
※この投稿は米国時間 2026 年 2 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
会話エージェントを大規模展開する際は、データレイヤの設計が成否を左右することが少なくありません。数百万人規模のユーザーを支えるには、会話の継続性が欠かせません。つまり、応答性の高いチャットを維持しつつ、バックエンドのモデルが必要とするコンテキストも保ち続ける能力です。
この記事では、Google Cloud のソリューションを用いて、AI の 2 つのデータ課題(リアルタイムチャットのコンテキスト更新を高速化すること、長期履歴の検索を効率化すること)をどう解決するかをご紹介します。また、Redis、Bigtable、BigQuery を組み合わせるポリグロットなアプローチにより、直近のやり取りから数か月前のアーカイブまで、エージェントが細部と文脈の連続性を保てるようにする方法も解説します。
短期、中期、長期の履歴に対応するポリグロット ストレージ アプローチ
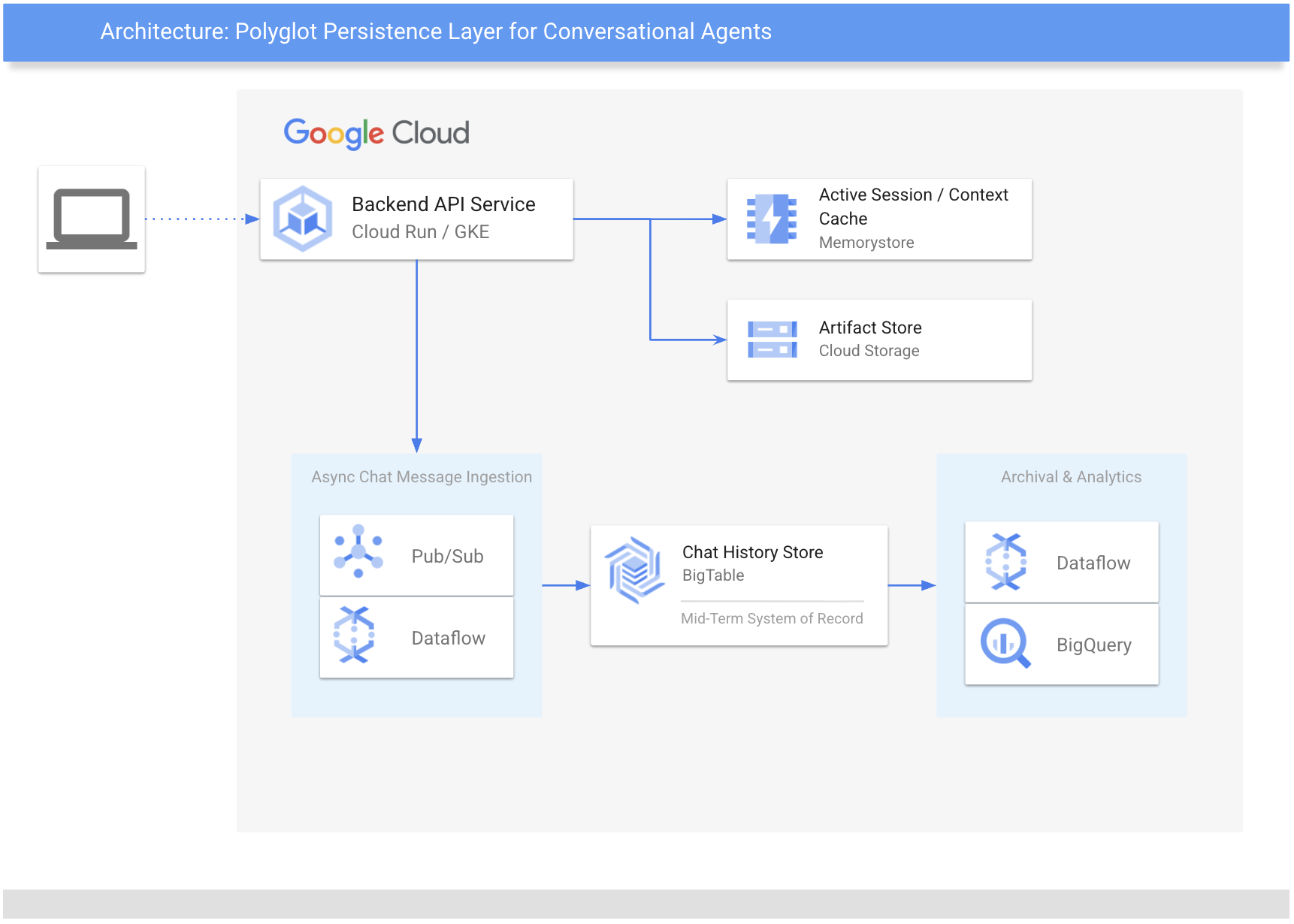
ポリグロット アプローチとは
ポリグロット アプローチとは、単一のデータベースに集約するのではなく、用途に特化した複数のデータサービスを組み合わせ、データのライフサイクルに応じて使い分ける多層型のストレージ戦略です。これにより、たとえば、高速化のためのインメモリ キャッシュ、大規模データを扱うための NoSQL、非構造データを置くための Blob ストレージ、分析のためのデータウェアハウスといったように、それぞれの強みを活かしながら、データの「鮮度」や量に応じて効率的に処理できます。
短期、中期、長期メモリに対する Google Cloud での定義例
会話の継続性を保つため、Google Cloud 上では次のように組み合わせて、このポリグロット アプローチを実装できます。すなわち、ミリ秒未満で「ホット」なコンテキストを取得する用途には Memorystore for Redis を、永続的な履歴を蓄積するペタバイト規模の記録基盤には Cloud Bigtable を、長期アーカイブや分析的な洞察には BigQuery を用います。また、画像や音声などの非構造マルチメディアは Cloud Storage で扱い、Pub/Sub と Dataflow による非同期パイプラインで連携させます。
1. 短期メモリ: Memorystore for Redis
ユーザーは、新しいチャットを開始する場合でも、以前の会話を続ける場合でも、チャット履歴が瞬時に読み込まれることを期待しています。会話のコンテキストについては、Memorystore for Redis が主要なキャッシュとして機能します。フルマネージドのインメモリ データストアである Redis は、自然な会話の流れを維持するために必要なサブミリ秒レベルの低レイテンシを提供します。チャット セッションはメッセージが順次追加されていくリスト構造のため、履歴は Redis リストを使って保存します。ネイティブの RPUSH コマンドを使えば、アプリケーションは最新のメッセージだけを追加すればよく、Memcached のような単純なストアで発生しがちな「読み取り → 更新 → 書き込み」というネットワーク負荷の大きい処理を避けることができます。
2. 中期メモリ: Cloud Bigtable
会話が時間とともに増えていくにつれ、エージェント型アプリケーションは、増え続けるチャット履歴をより大規模に、かつ長期的に保存できる設計を考える必要があります。そこで、Bigtable が、永続性を備えた中期ストアとして、また全チャット履歴の正式な記録として機能します。Bigtable は、高速で書き込みが集中するワークロード向けに設計されたペタバイト級の NoSQL データベースで、数百万件の同時チャットを取り込む用途に適しています。大量のデータを扱いつつも、ガベージ コレクション ポリシーを設定すれば、アクティブなクラスタを必要最小限に保てます。たとえば、高性能ティアには直近 60 日分だけ残すといった運用が可能です。検索を高速化するため、キーは user_id#session_id#reverse_timestamp というパターンで設計します。これにより、同一セッションのメッセージが近接して格納され、範囲スキャンで直近のメッセージを効率よく取り出せるため、履歴の再読み込みがスムーズになります。
3. 長期メモリと分析: BigQuery
アーカイブと分析のため、データは BigQuery に移されます。BigQuery は、このシステムにおける長期メモリの役割を担います。Bigtable が稼働中のアプリケーション向け処理に最適化されているのに対し、BigQuery は大規模な複雑 SQL クエリを実行するために設計された Google のサーバーレス型データ ウェアハウスです。これにより、チームは単なるログ保存にとどまらず、そこから分析的なインサイトを引き出せるようになります。最終的には、この運用データがフィードバック ループとして機能し、ユーザー向けコンポーネントのパフォーマンスに影響を与えることなく、エージェントやユーザー体験の改善につながります。
4. アーティファクト ストレージ: Cloud Storage(GCS)
ユーザーが分析のためにアップロードしたものでも、生成モデルが生成したものでも、画像や音声などの非構造データ(マルチメディア ファイル)は、非構造アーティファクトの保管に適した Cloud Storage に格納します。ここではポインタ戦略を採用します。Redis や Bigtable のレコード側には、実体データそのものではなく、オブジェクトを指し示す URI(例: gs://bucket/file)を保持します。セキュリティ面では、アプリケーションが署名付き URL を使ってファイルを配信し、バケットを公開することなく、クライアントに期限付きのアクセス権だけを付与します。
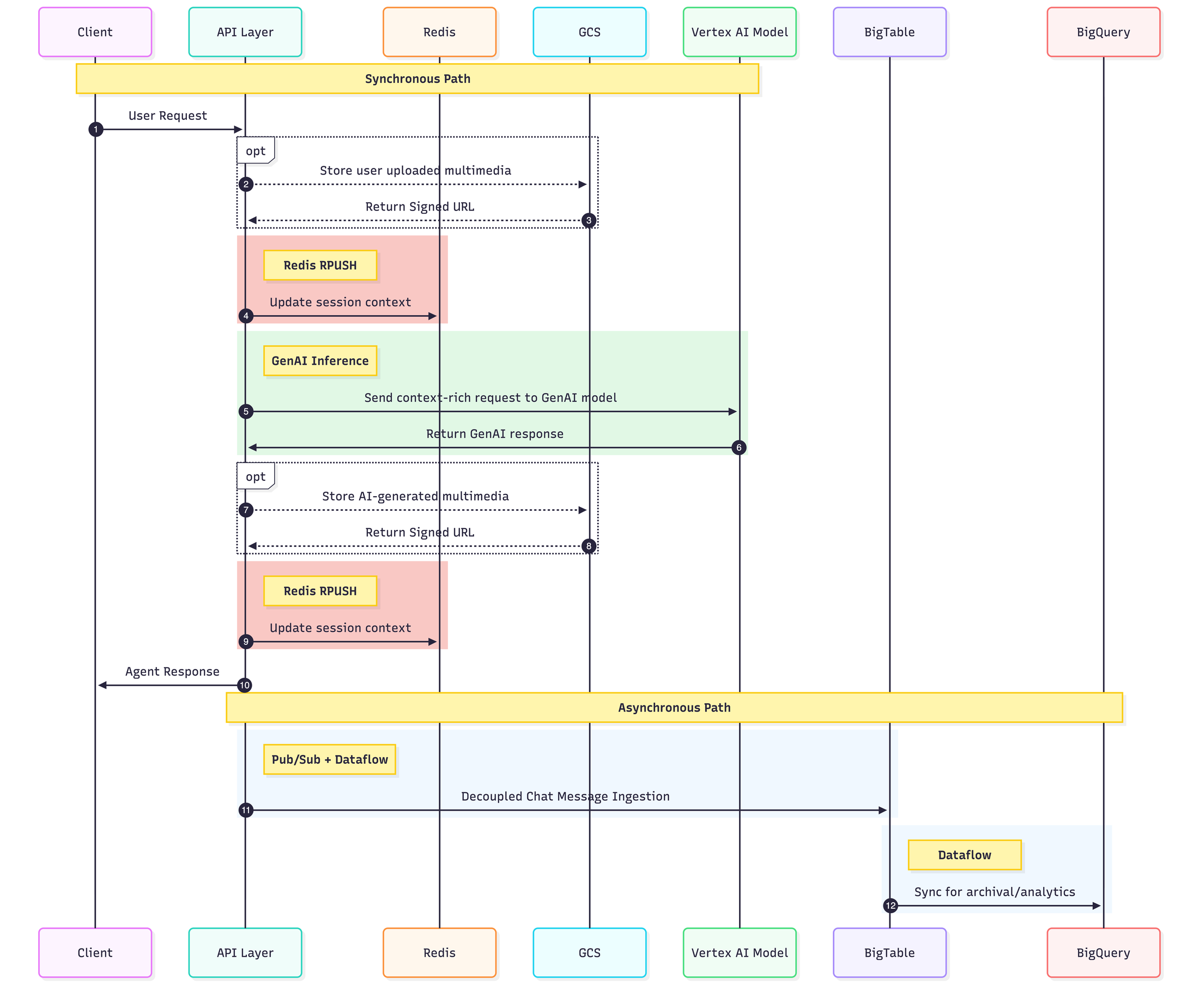
データの流れを最適化するハイブリッド同期 / 非同期戦略
以下のシーケンス図で示すとおり、このハイブリッド同期 / 非同期戦略では、前述のストレージ群を組み合わせることで、高速で整合性のある処理と耐久性のある永続化を両立させます。
次の図は、ユーザーのメッセージと、それに対応するエージェントの応答が、アーキテクチャ内をどのように流れていくかを示しています。
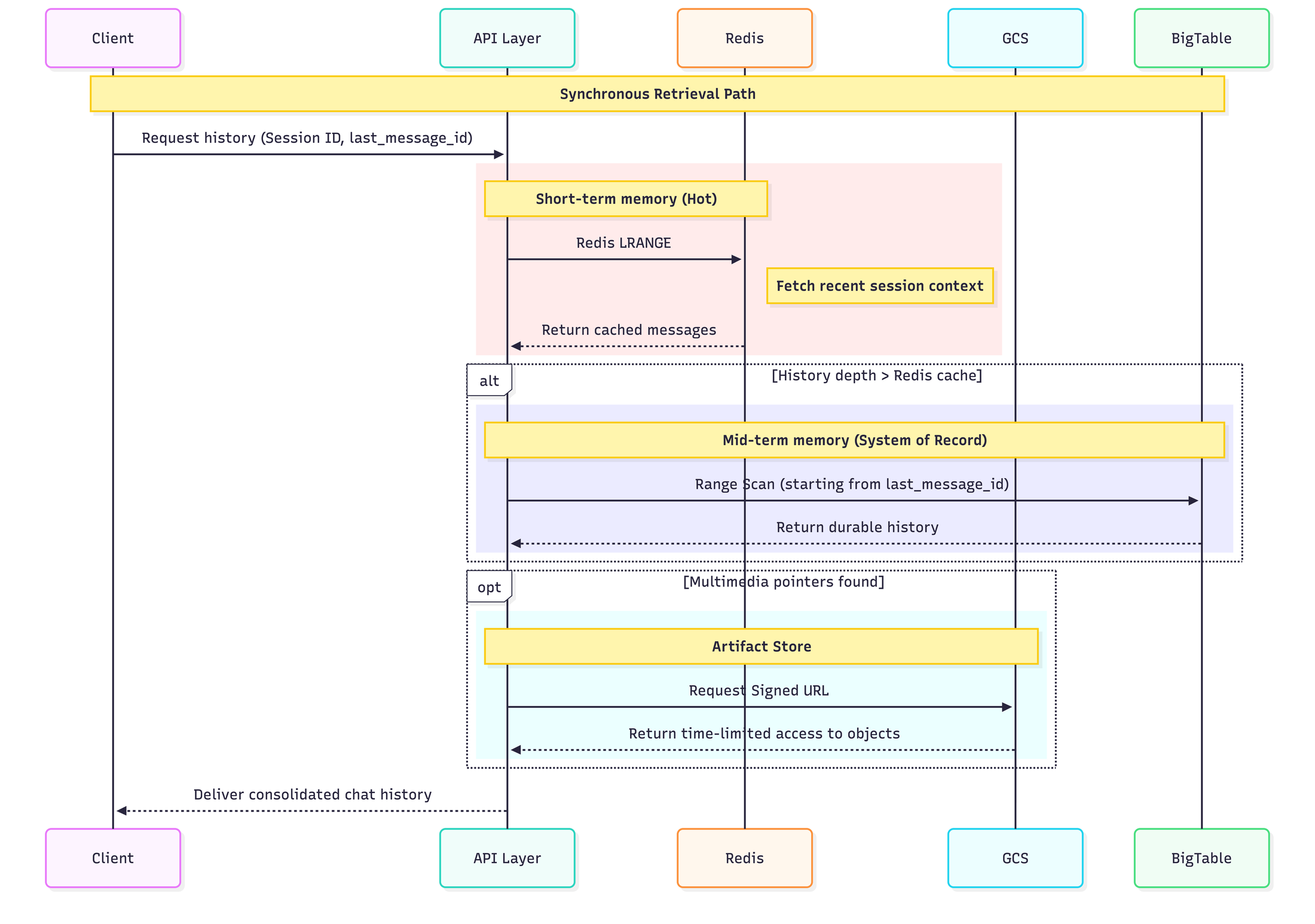
次の図は、ユーザーが特定のセッションのチャット履歴を取得する際に、データがアーキテクチャ全体をどのように流れるかを示しています。
今すぐ構築を開始
堅牢な永続化レイヤを備えたエージェントを構築する準備はできていますか?
-
エージェントをすばやく構築: Vertex AI Agent Builder を使って、エージェント型ワークフローのプロトタイピングを始めましょう。
-
キャッシュを構成する: レイテンシと可用性の要件に合わせて、最適な Memorystore for Redis の構成を決定します。
-
堅牢な Bigtable スキーマを設計する: スキーマ設計のベスト プラクティスを確認しましょう。
-
分析へつなぐ: Bigtable の Change Stream から BigQuery へのテンプレートを活用し、ライブチャット ログを実用的なビジネス インサイトへと変換します。
-
分析でデータを活用する: Looker Conversational Analytics を使って、ビジネス インテリジェンスに基づいたプロダクトの意思決定を行いましょう。
- AI ソリューション アクセラレーション アーキテクト Aishwarya Prabhat
- プリンシパル アーキテクト Yun Pang