スパムの検出手法でテクニカル サポートを改善
Google Cloud Japan Team
※この投稿は米国時間 2021 年 11 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
情報技術(IT)チーム、特にヘルプデスクやサポートでは、ユーザーが抱えている問題を追跡する方法を必要としています。特にテクノロジーやポリシーが変化したときには、これらの問題が時間の経過とともにどのように変化するかも把握できれば理想的です。
たとえば、あなたは新聞配達チームをさまざまな周辺地区に送り込む業務を担当しているとしましょう。配達員は各自自転車を持っていて、ルートを渡されると、適切な郵便受けに新聞を配達します。しかし、道路は変化します。日々変わります。まさにカオスです。
ルートが常に変化している場合はどうすればよいでしょうか。コンテキストが四六時中変化している場合に、必要な情報を提供するにはどうすればよいでしょうか。
IT 関連のコンテキストでは、ITIL 4 などの従来の問題管理フレームワークと同様の課題に直面します。これらのフレームワークは、常に明確に定義された固定のサービス カタログを想定する傾向があります。IT 担当者が解決するすべての問題は、この方法で追跡され、説明されます。カタログに戻ることで、問題の原因や、大勢の従業員に影響を与えるサービス停止やインシデントが発生する可能性のある場所に関する分析情報を得ることができます。
Google にはそれがありません。その理由の一つは、Google ではユーザーを最優先にすることに重点を置いており、筆頭ジョブとしてユーザーを生産的な状態に戻すことに重点を置いているからです。また、プロダクト、サービス、問題は道路と同じく常に変化しているため、目標が変わらず一定であっても、ルートは同じにはなりません。そのため、ユーザーは IT サービスデスクに日々新たなタイプの問題を持ち込みます。
TechStop と呼ばれる Google のテクニカル サポートチームは、IT に関するすべての問題を一元管理しており、チャット、メール、ビデオ通話などのチャネルを通じてユーザーをサポートしています。サポートチームは、Google 社員が経験する新たな問題や使用する新しいプロダクトに対応し続ける必要があります。どのような問題が増加傾向にあるかを追跡するために、Techstop チームでは、Google で使用されているツール、アプリケーション、サービスをカタログ化する方法を必要としています。
新聞配達ルートの例に話を戻すと、この場合は詳細な地図ではなく大まかな概略地図を使用して、ほとんどのユースケースに「必要最低限」のサービス分類にしました。そこから有用なデータはある程度得られましたが、きめ細かい分析情報は得られませんでした。
イノベーションの必要性
COVID-19(新型コロナウイルス感染症)により、特に日常的に従業員が抱えている IT に関する問題について、スケーラブルな問題把握の必要性が浮き彫りになりました。多くの従業員が在宅勤務モデルへと移行する中で、従業員がテクノロジーの課題に直面している場所を把握する必要がありました。これはまるで周辺に新しい地区が一夜にして誕生したが、新聞配達員は同じというような状況でした。まったく新しい市街地図を使用して、より多くの地域をカバーする必要がありました。
さらに、Google Meet など、生産性向上のために日々使用されるプロダクトの使用量が指数関数的に増加し始めたため、スケーリングの問題やサービス停止が生じていました。これらのプロダクト チームは、日々提出されてどんどん増えていく機能リクエストやバグのリストに優先順位を付けられるよう、Techstop 組織に支援を求めていました。
最終的には、「必要最低限」の問題分類では、真に役立つ分析情報を得ることはできませんでした。どのプロダクトが最も影響を受けているかは確認できましたが、ユーザーがそれらのプロダクトでどのような問題を抱えているかはわかりませんでした。さらに悪いことに、在宅勤務モデルの下で急速に変化している問題空間を捉えられるようにカタログを迅速に更新できなかったため、在宅勤務モデルに固有の新たな問題は露呈しませんでした。
スパム技術の借用
Techstop チームは、Google の他の取り組みについて見ていくうちに、同様の問題の解決例を見つけました。それは、急速に変化するデータの中から新しいパターンをすばやく検出する方法です。
Gmail では、10 億人を超えるユーザーの迷惑メールフィルタを処理しています。Gmail のエンジニアは、「新しいスパム キャンペーンをすばやく検出するにはどうすればよいか」を熟考していました。スパム送信者は、コンテンツをわずかに変えて(ノイズ、ミススペルなど)大量のメッセージを一気に送信します。分類器が新しいパターンについて学習するにはある程度の時間がかかるため、大半の分類の試みはいたちごっこになります。

非構造化テキストで管理対象外の密度クラスタリングを使用してトレンド識別エンジンを呼び出すことで、Gmail では短期的なスパム キャンペーンをより迅速に検出できるようになりました。
Techstop が対処すべく問題はこれと似ていました。急速に変化するプロダクトによって生じた問題は、従業員と、これらの問題をトラブルシューティングする IT 担当者のどちらにも、非常に動的なユーザー ジャーニーを引き起こしました。提出されたサポート チケットは、迷惑メールのようにスペルや単語の選択がわずかに異なるだけで、ほぼ同じでした。
密度クラスタリング
重心ベースのアルゴリズムである k 平均法のような厳密な手法とは対照的に、密度ベースのクラスタリングは、大量の不均一なデータセットで、サイズが大きく異なるクラスタが含まれる可能性がある場合に適しています。会社全体にわたって問題を特定するタスクに取り組むには、大量でも安定しているパターンの中から少量でも重要な不安材料を検出して区別する機能が必要です。そこで役立つのが、密度ベースのクラスタリングの柔軟性です。
Google の実装では ClustOn を使用しています。これは密度ベースのクラスタリングを組み込んだハイブリッド アプローチを使用する社内テクノロジーです。ただし、DBSCAN(scikit-learn のクラスタリング モジュールを介して利用できるオープンソース実装)などの、より実績のあるアルゴリズムを利用しても、同様の効果が得られます。
ML を使用した道路ソリューションの途中経過
Gmail で密度クラスタリング手法を使用して実行できたことを鑑みて、Techstop チームは、厳密な分類の問題を解決する方法で問題を追跡する堅牢なソリューションを構築しました。密度クラスタリングを使用して、分類バケットをトレンド クラスタとして再定義し、社内でリアルタイムに発生している問題のインデックスを提供します。重要なのは、これらのバケットがエンジニアリング チームやテクニカル サポートチームによって事前に定義されるのではなく、自然に出現することです。
こうして何十億ものメール アカウントのために構築されたテクノロジーを使用することで、Google の大規模なサポート リクエストを処理できることがわかりました。また、このソリューションは、厳密に定義される分類法よりも柔軟性が高く、関連性や粒度を犠牲にすることもありません。
チームはさらに一歩進めて、ポアソン回帰を使用してクラスタの動作をモデル化し、異常検出手段を実装して、現在発生しているサービス停止や正しく実行されていない変更について運用チームにリアルタイムで警告できるようにしました。少人数の運用チームとこの新しいテクノロジーにより、Techstop はきめ細かい分析情報を見つけ出し、専任チーム全体で各インシデントを手作業で綿密に調査して集約できるようになりました。
ML と運用を組み合わせることで、Techstop が保有するデータは、ユーザーがエンタープライズ環境でプロダクトを使用する際に直面している問題を把握しようとしているプロダクト マネージャーやエンジニアリング チームにとって貴重なリファレンスになりました。
仕組み
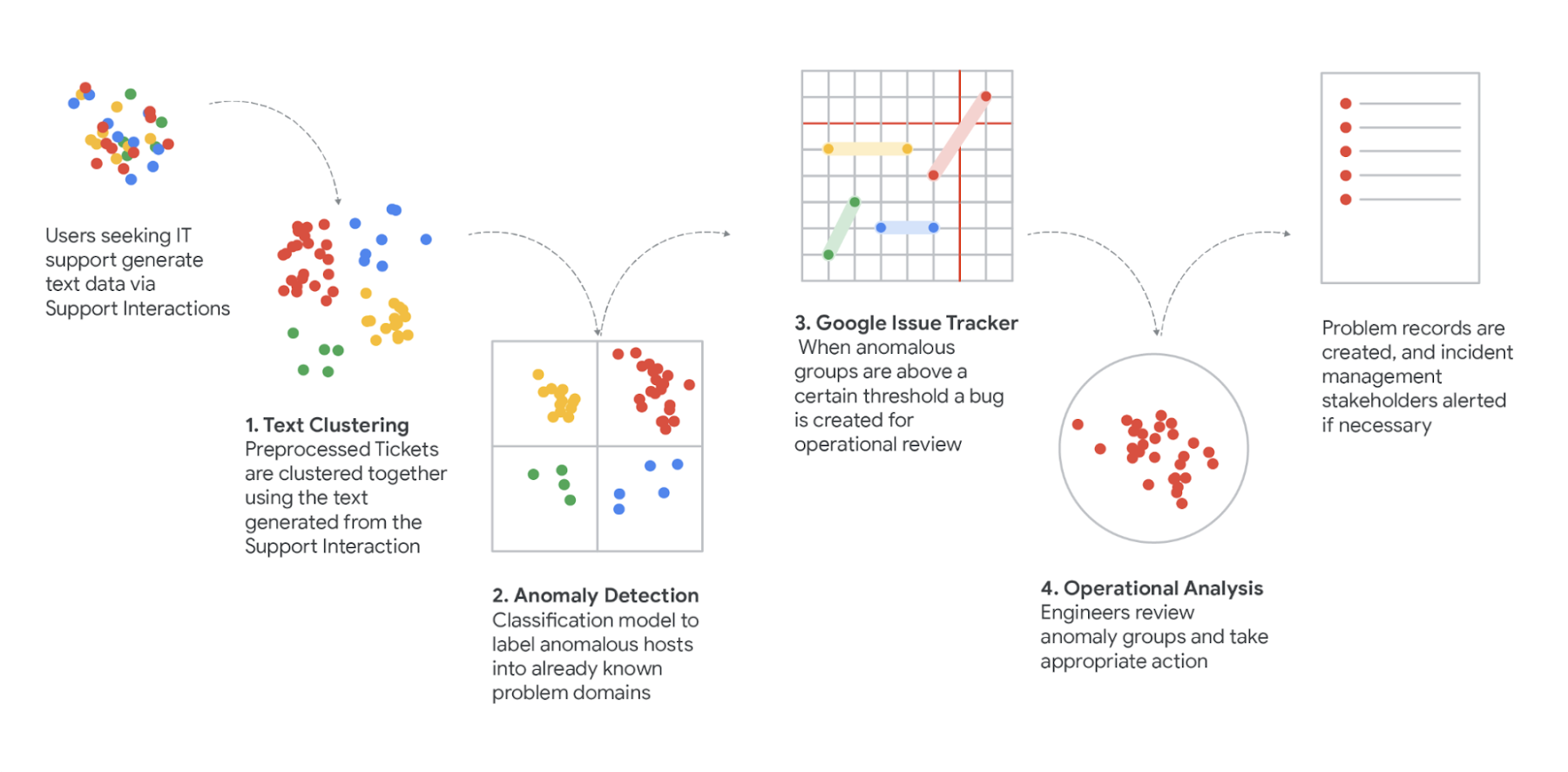
すべてをまとめるために、Google では Support Insights と呼ばれる ML パイプラインを構築しました。これにより、受け取った多数のインタラクションとチケットから要約データを自動的に抽出できるようになりました。Support Insights パイプラインは、機械学習、人間による検証、確率論的分析を組み合わせて、 まとめて 1 つのシステム ダイナミクス アプローチにしたものです。
データがこのパイプラインを移動する流れを次に示します。
抽出 - BigQuery API を使用して、サポートデータの保存、抽出、トレーニング、読み込みを行います。100 万件以上の IT 関連サポートデータを取り込みます。
品詞タグ付け、PII 編集、TF-IDF 変換の処理を行い、クラスタリング アルゴリズムのサポートデータをモデル化します。
クラスタ化 - 重心ベースのクラスタリングが前の実行状態のスナップショットを永続的に取得しながら時間指定されたバッチで実行されます。これによりクラスタ ID が維持され、クラスタの動作が経時的に追跡されます。
スコアリング - ポアソン回帰を使用してクラスタ トレンドの長期と短期の両方の動作をモデル化し、2 つの差を計算して偏差を測定します。この偏差スコアがトレンド内の異常な動作の検出に使用されます。
運用化 - 特定のしきい値を超える異常なスコアを持つトレンドにより、IssueTracker API バグがトリガーされます。このバグが運用チームによって検出され、関連する詳細な調査やインシデント追跡が行われます。
リサンプリング - 統計手法を使用して、トレンド内のカスタマ ユーザー ジャーニー(CUJ)の比率を推定します
分類 / マッピング - 運用チームと協力して、トレンドの比率をユーザー ジャーニー セグメントにマッピングします。
次の投稿では、これらの 7 つのステップで使用したテクノロジーと手法について詳しく説明し、同様のパイプラインをご自身で使用する方法を紹介します。まず、BigQuery にデータを読み込んで、BigQuery ML を使用してサポートデータをクラスタ化します。
- Efficiency Solutions エンジニア Nicholaus Jackson
- Google Cloud Developer Relations シニア エンジニア Max Saltonstall




