あらゆる場所に存在するデータを Cloud SQL for SQL Server からレプリケートする
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud SQL for SQL Server に保存しているデータの最新コピーが必要ですか?Cloud SQL では、トランザクション レプリケーションと呼ばれる SQL Server の機能を使用して、Cloud SQL インスタンスから外部サブスクライバー(または別の Cloud SQL インスタンス)へのレプリケーションを設定できるようになりました。これにより、SQL Server データのコピーを継続的に別のインスタンスに作成する新たな方法が提供され、データ保護やデータ分析など、さまざまなシナリオで活用できます。このブログでは、他の Cloud SQL インスタンスのパブリッシャーとして機能する Cloud SQL for SQL Server インスタンスの設定方法についてご説明します。
設定に必要な準備
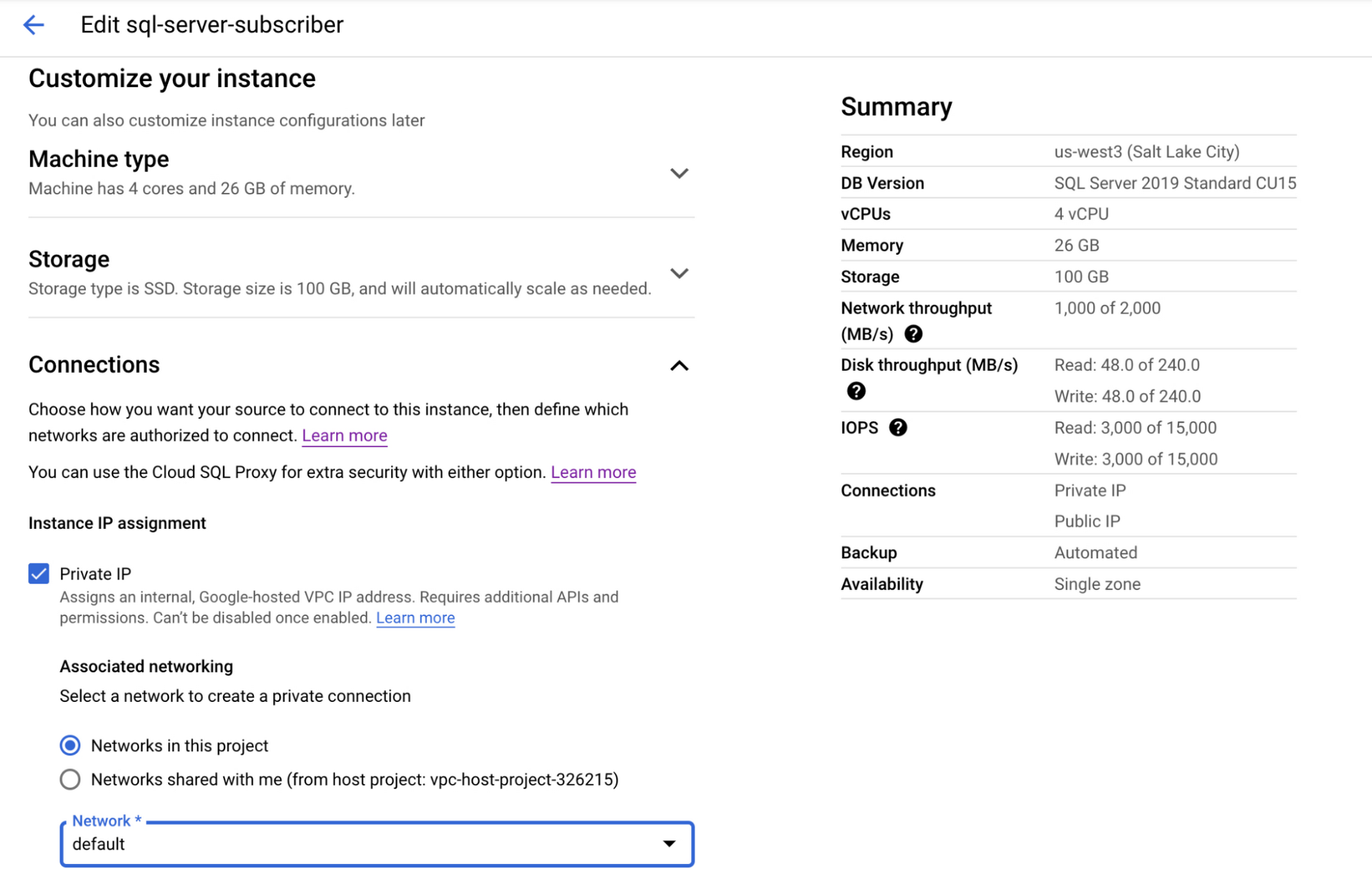
まず、2 つの Cloud SQL インスタンスを作成します。どちらのインスタンスもプライベート IP を有効にして、同じ VPC に配置します。パブリック IP が有効な Cloud SQL インスタンスは、静的送信 IP を持たないため、パブリッシャーとして機能する Cloud SQL インスタンスではプライベート IP を有効にする必要があります。トランザクション レプリケーションには、どのインスタンスをパブリッシャーとして、またはサブスクライバーとして使用できるかについて、エディションやバージョンに対するいくつかの制限があるため、それらの制限と適合性を確認してください。このブログでは、パブリッシャーとサブスクライバーの両方に SQL Server 2019 Standard インスタンスを使用します。
また、Compute Engine VM を作成し、そこで SQL Server Management Studio を実行して、両方のインスタンスに接続します。
まず、Cloud SQL インスタンスを作成します。この例では、us-central1 にパブリッシャーとなるインスタンス、us-west3 にサブスクライバーとなるインスタンスを、それぞれ 1 つずつ作成します。どちらのインスタンスもプライベート IP が有効になっていて、同じ VPC に接続されています。
また、パブリッシャーとサブスクライバーの両方に接続するために、SQL Server Management Studio(SSMS)を実行する Compute Engine VM も作成しました。この VM も、プライマリおよびセカンダリと同じ VPC に接続されています。このブログで説明されている手順に沿って、SSMS がインストールされた VM を作成し、Cloud SQL インスタンスに接続します。
データベースの作成とパブリケーションの設定
まず、パブリッシャーとして機能するインスタンスに新しいデータベースとテーブルを追加します。
テーブルにデータを挿入します。
これで、サブスクライバーにレプリケーションを開始するテーブルが作成されました。
レプリケーションの設定
トランザクション レプリケーションを設定する 10 の手順に従い、パブリッシャーとサブスクライバーを準備します。まず、この 10 の手順について説明します。次に、パブリッシャーとサブスクライバーを準備するために実行するストアド プロシージャの例を詳しく説明していきます。
パブリッシャーと同じインスタンスに配置されたディストリビューション データベースを作成します。ディストリビューション データベースには、メタデータ、データ、過去のトランザクションが格納されます。
パブリケーションに含めるすべてのデータベースでパブリケーションを有効にします。こうすることで、データベースのパブリッシュをサポートするのに必要な内部オブジェクトが作成されます。
各データベースに、パブリッシュに際しデータベースに加えられた変更を追跡するログリーダー エージェントを追加します。こうした変更は、トランザクション ログファイルから読み取られます。
パブリケーションを作成します。
パブリケーションのスナップショット エージェントを作成します。このエージェントは、スキーマとデータを含むスナップショット ファイルを生成します。
アーティクルを作成してパブリケーションに追加します。アーティクルとは、サブスクライバーにレプリケートする特定のオブジェクトのことです。
サブスクライバー データベースをサブスクライバーに作成します。
パブリッシャーにサブスクリプション情報を追加します。
push サブスクリプションを同期するスケジュール設定されたエージェント ジョブをパブリッシャーに追加します。
エージェント ジョブを開始します。
実行するコマンドの詳細については、こちらでも説明しています。
1. 次のコマンドを実行して、ディストリビューション データベースを設定します。
EXEC msdb.dbo.gcloudsql_transrepl_setup_distribution @login='sqlserver', @password='<password>'
2. 次のコマンドを実行することで、パブリケーション用の新しいテスト データベースを有効にします。
EXEC msdb.dbo.gcloudsql_transrepl_addpublication @db='to_publish', @publication='pub1
3. 次のコマンドを実行して、データベースのログリーダー エージェントを追加します。
EXEC msdb.dbo.gcloudsql_transrepl_addlogreader_agent @db='to_publish', @login='sqlserver', @password='<password>'
4. 次のコマンドを実行して、パブリケーションを作成します。
EXEC msdb.dbo.gcloudsql_transrepl_addpublication @db='to_publish', @publication='pub1'
5. パブリケーションのスナップショット エージェントを作成します。
EXEC msdb.dbo.gcloudsql_transrepl_addpublication_snapshot @db='to_publish', @publication='pub1', @login='sqlserver', @password='<password>'
6. パブリッシュする特定のアーティクルを追加します。この例では、1 つのアーティクル(INTERESTING_DATA というテーブル)のみをパブリッシュしていますが、追加のテーブル、関数、またはストアド プロシージャをレプリケートするよう指定できます。
7. サブスクライバーにデータベースを作成します。Compute Engine VM 上で動作している SSMS 経由でパブリッシャーに接続し、Cloud SQL Auth Proxy を実行している場合は、指定したインスタンスをプロキシの起動時に切り替えるだけです。
このガイドでは、ソース データベースは「to_publish」と呼ばれているため、サブスクライバーのデータベースを「published」と呼びます。
CREATE DATABASE published;
GO
8. パブリッシャーにサブスクリプション情報を追加します。
9. push サブスクリプションを同期する新しいスケジュール設定されたエージェント ジョブを追加します。
10. パブリケーション スナップショットのエージェント ジョブを開始します。
これで、レプリケーションが設定されました。サブスクライバー インスタンスに接続すると、テーブルが作成され、テストテーブルのデータがコピーされていることが確認できます。
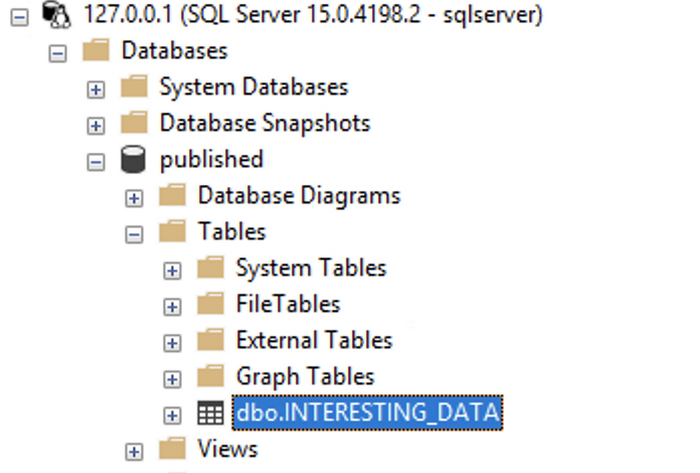
パブリッシャーでテーブルに新しい行を挿入して、そのデータがレプリケートされていることも確認できます。
既存のパブリッシャーの設定にアーティクルを追加する
これで正常にパブリッシャーの設定が作成されましたが、レプリケーションの設定にテーブルなどのアーティクルを追加する必要があるかもしれません。以下の手順では、完全なデータベース スナップショットを生成することなく、アーティクルを追加する方法を説明しています。これは、とりわけ非常に大規模なデータベースの場合、とても便利です。
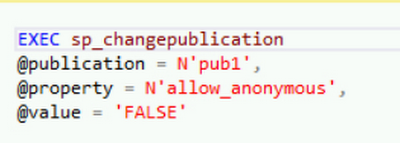
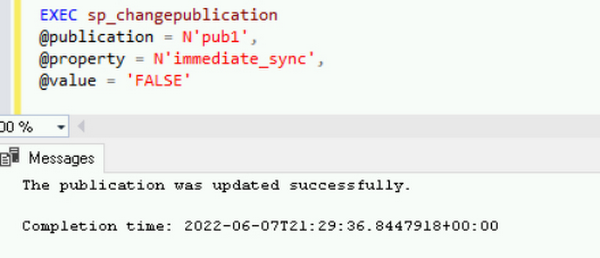
パブリケーション設定の allow_anonymous と immediate_sync のプロパティを「false」に変更します。
この例で使用するいくつかのテーブルを作成します。
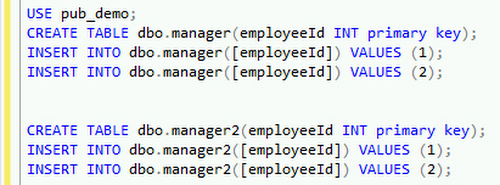
パブリケーションを右クリックし、プロパティを選択します。
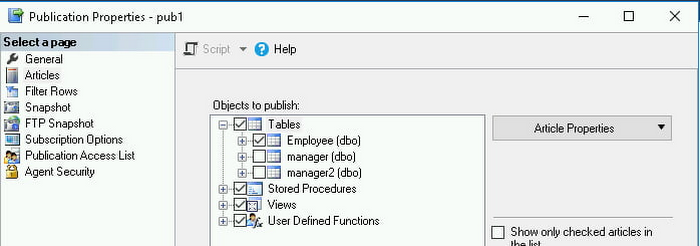
パブリッシュするすべてのアーティクルの横のチェックボックスをオンにして、[OK] をクリックします。すべてのアーティクルを表示するには、「チェックボックスがオンのアーティクルのみ一覧に表示する」のチェックボックスをオフにする必要がある場合があります。
新たにスナップショット エージェントを開始します。
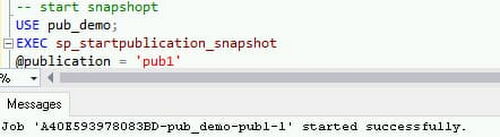
以下のように、追加した 2 つのアーティクルについてのみ、新しいスナップショットが生成されているのが確認できるはずです。
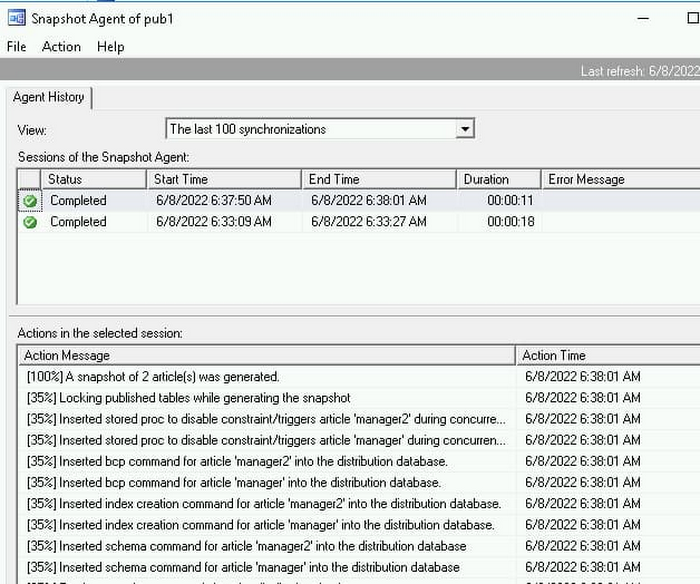
問題のトラブルシューティング
レプリケーションの設定中に、「レプリケートされる LOB データ(65754)の長さが、構成した最大長 65536 を超えています」というエラーが表示される場合があります。このエラーを解決するには、「max text repl」の設定を、上限なしを示す「-1」に調整します。Cloud SQL データベース フラグを使用すると簡単に調整できます。
このコマンドの例を以下に示します
gcloud sql instances patch [INSTANCE_NAME] \
--database-flags="max text repl size (b)"=-1
レプリケーション モニターは、レプリケーションに関する問題のトラブルシューティング、またはレプリケーションの進捗状況の全体像を確認するために活用できます。
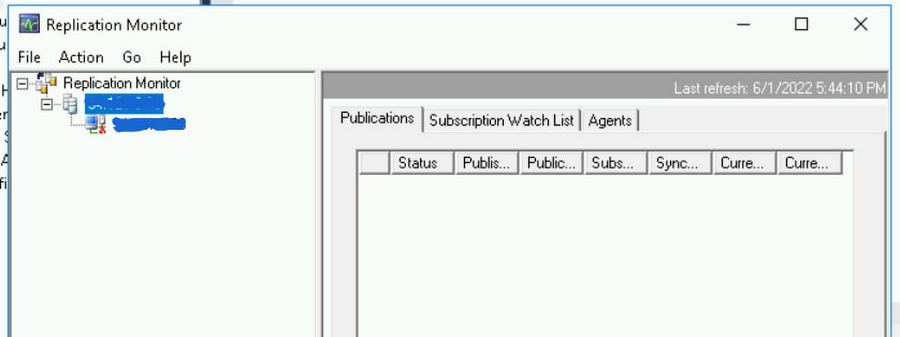
パブリッシャーとしての Cloud SQL の設定例では、各ラッパーで Cloud SQL インスタンス IP アドレスを使用してレプリケーションを構成しました。これには、レプリケーション モニターがパブリッシャーを検出できないという副作用があります。これは使用されたホスト名と IP アドレスのマッピングをレプリケーション モニターが認識していないために起こります。
レプリケーション モニターを起動すると、[パブリケーション] タブが空で、[エージェント] タブにだけデータがあることがわかります。
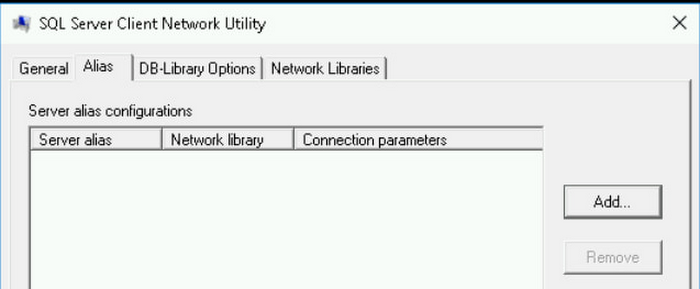
SSMS でこの問題を回避するには、構成マネージャーで、パブリッシャーの SQL Server ホスト名と、SSMS で接続に使用する IP アドレスの間に、別名を作成します。Windows で SQL 構成マネージャーが使用できない場合、SQL クライアント構成ユーティリティも利用できます。
cmd プロンプトを管理者として開きます。
C:\Windows\System32\cliconfg.exe または C:\Windows\SysWOW64\cliconfg.exe を開きます。
どちらを開くかは、クライアントが 64 ビット版か 32 ビット版かによって異なります。
[別名] タブ、[追加] の順にクリックします。
[TCP/IP] を選択し、[ポートを動的に決定する] が選択されていないことを確認します。
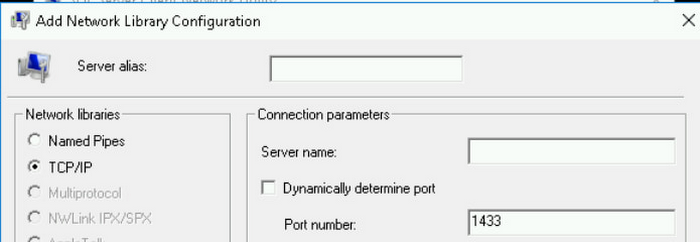
[サーバー別名] フィールドには、以下の SQL から取得した実際のホストを入力します。
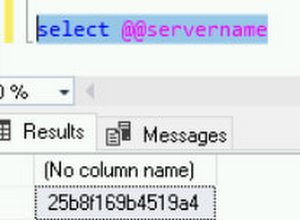
[サーバー名] フィールドには実際の IP を入力し、[OK] をクリックします。
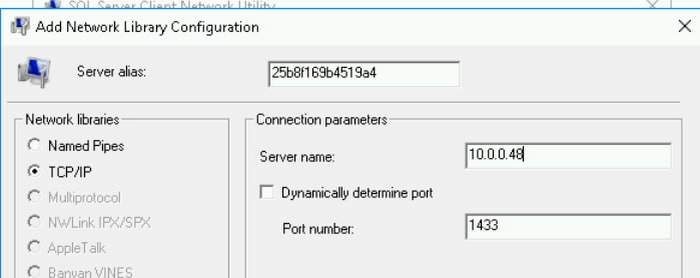
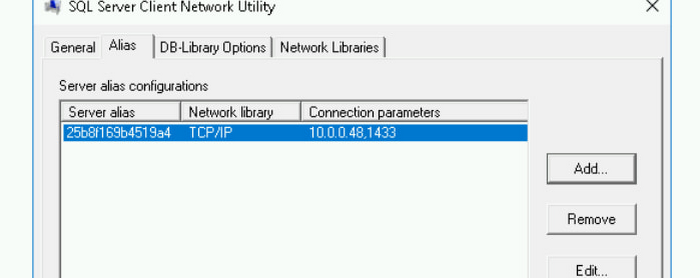
Cloud SQL プロキシを使用している場合、[サーバー名] は 127.0.0.1 を使用して別名を追加します。
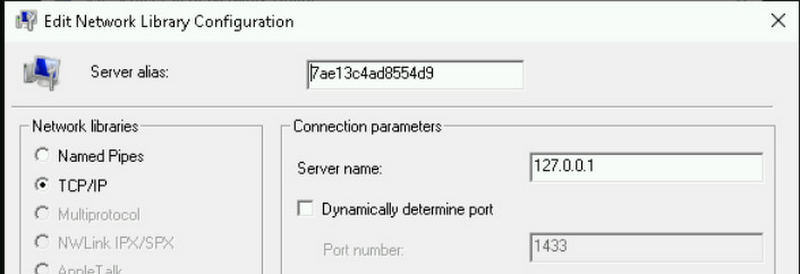
SSMS で、この新しい別名を使用して接続し、[レプリケーション] ノードを右クリックしてから、[レプリケーション モニターの起動] をクリックします。
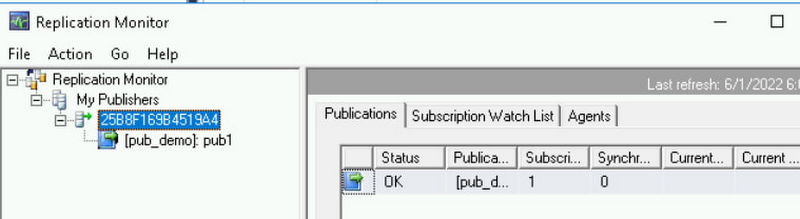
以下のように期待通りのパブリケーションが表示されるはずです。
まとめ
Cloud SQL for SQL Server から別の Cloud SQL インスタンスへのトランザクション レプリケーションの設定方法、より多くのアーティクルを含むようにパブリケーションを更新する方法、問題のトラブルシューティングを行うためのレプリケーション モニターの使用方法について説明しました。この構成は、プライマリ インスタンスのコピーを別のリージョンまたは環境に保持する場合など、さまざまなシナリオで活用できます。このブログでは 2 つの Cloud SQL インスタンスを使用していますが、オンプレミスまたは Google Compute Engine 上で動作するインスタンスなど、外部インスタンスのパブリッシャーとして動作するように Cloud SQL を設定することもできます。Cloud SQL からのレプリケーションの詳細はこちらをご覧ください。ご利用をお待ちしています。
- プロダクト マネージャー Isabella Lubin
- データベース エンジニア Bryan Hamilton



