Cloud Firestore の使用経験がないユーザー向けの Firestore の説明
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
新しいデータベースを使いこなすのは大変ですが、データベースに関する技術的知識を持っていない場合はなおさらです。この記事では、データベースの基礎知識、知っておくべき用語、Firestore とは何か、どのように動作するのか、どのようにデータを保存するのか、そして、データベースに関する既存の知識がないことを前提とした開始方法について説明します。
Cloud Firestore とは何かを説明する前に、知っておくべき重要なデータベースの用語を紹介します。リレーショナル データベースや非リレーショナル データベースに関する基礎知識をすでにお持ちの方は、このセクションをスキップしても問題ありません。
データベースとは
データベースとは、データへのアクセス、データの管理、修正、更新、制御、整理を容易に行うことができるソフトウェアです。情報をどのように保存するかによって、選択するデータベースが異なります。データベースには、大きく分けてリレーショナルと非リレーショナルの 2 つのカテゴリがあります。
リレーショナル データベース
リレーショナル データベースは、スプレッドシートのようなものです。スプレッドシートには、このように情報を保存できます。
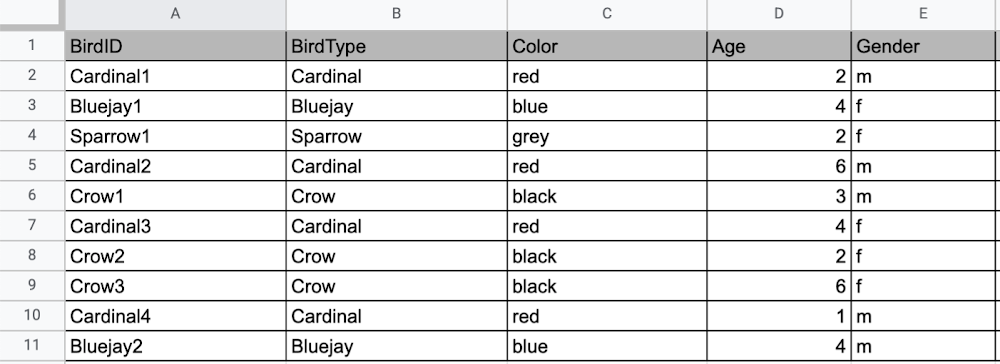
では、Sparrow1 の巣の情報をスプレッドシートに保存したいが、他の鳥の巣の情報は必要でない場合はどうなるでしょうか。スプレッドシートに「Home」という列を追加し、そこに Sparrow に関するデータのみを入れる必要があります。すると、このようになります。
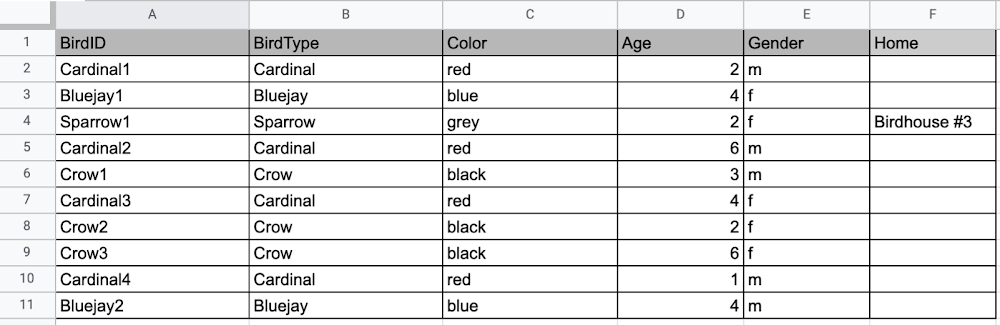
必要な情報は Sparrow の巣の情報のみですが、他の鳥の列には空白の欄も必要になってしまいます。これは、リレーショナル データベースには、スキーマと呼ばれる特定のデータ ストラクチャがあるためです。スプレッドシートの例のように、たとえ必要な情報が 1 羽分であっても、保存する情報のすべての項目で、鳥の巣に関する情報を入れる場所が必要です。これはスキーマによって強制適用されます。スキーマは、基本的にはシートに入れる列のヘッダーであり、厳格なデータ ストラクチャを指示するものですが、これには長所と短所があります。
リレーショナル データベースの厳格なストラクチャにより、アプリケーションにどのような種類のデータが存在するか、データの種類を知ることができ、データに一意性を要求したり、保存されているデータの種類を指定したりなどのルールを適用できます。スキーマは、設計上、各行のデータが同じ特性を持つようになっているため、データベースのスキーマを変更しない限り、柔軟性に欠けることになります。つまり、既存のスキーマに合わない別のデータを追加する場合は、スキーマを変更しなければならないということです。上で説明したように、Home など、情報を保存するために使用しているスキーマに変更を加える場合、他の行の情報は保存したくない場合でも、すべての行の情報が保存されます。無駄となるストレージの量は、データベース エンジンやデータの種類などによって異なります。リレーショナル データベースについてもう一つ考慮すべきなのは、従来のリレーショナル データベースの中には、大規模化に対応するために、より高度なデプロイが必要になるものがあるということです。
リレーショナル データベースのスキーマを変更するには、運用中のスクリプトのスキーマを変更し、アプリ内のコード変更との調整を慎重に行う必要があるため、特に負荷の大きなワークロードでは混乱を招く可能性が高いです。また、ロックされることで、ダウンタイムが発生する場合もあります。一方、Firestore のような非リレーショナル ドキュメント データベースでは、データベース内のスキーマの変更やそれに伴うダウンタイムを心配する必要はありません。
また、収集したいデータがたくさんあり、それがデータベースの中のいくつかのものにしか当てはまらない場合、何の情報も入っていない余分なスペースがあると、多くの場合、保存容量を無駄に使ってしまうことになります。非リレーショナル データベースは、この問題を解決するのに役立ちます。
非リレーショナル データベース
一般的に、非リレーショナル データベースは、リレーショナル データベースとは異なる形式で情報を保存します。よく耳にする非リレーショナル データベースには、大きく分けて 4 つのカテゴリがあります。
列ファミリー
ドキュメント(Firestore)
Key-Value
グラフ
この記事は Firestore に焦点を当てているので、このセクションでは、ドキュメント データベースとは何か、どのように使用するのか、どのような場合に使用するのかについて掘り下げていきます。
ドキュメント データベース(Firestore)
ドキュメント データベースは、次のようなエンティティの多層的なコレクションと考えることができます。

ご覧のように、リストがすべて閉じられている状態では、トップの情報しか見ることができません。この例では、BirdID(Cardinal1、Bluejay1、Sparrow1、Cardinal2、Crow1 など)です。リストを開くと「ワード: ワード」が表示されます。たとえば、ドキュメント ID Sparrow1 には、「Type: Sparrow」のドキュメントがあります。また、「Color: grey」、「Age: 2」、「Gender: f」、「Home: Birdhouse #3」も表示されています。

これを Key-Value ペアと呼びます。「Type: Sparrow」の場合、Type がキー、Sparrow が値となります。Sparrow1 のドキュメントのキーは、Type、Color、Age、Gender、House です。また、Sparrow1 のドキュメントの値は、Sparrow、grey、2、f、Birdhouse #3 です。
キーがコンテキストを提示するのと同様に、鳥の年齢などの特定の情報をコンピュータに求めることができます。集めたデータをプログラムで簡単に読めるように、データごとに使うキーワードを決めておくことが重要です。これは暗黙スキーマと呼ばれ、データがどのように保存されるかについての暗黙知であり、データベースによって強制されるものではありません。暗黙スキーマを使うとどうなるかを見てみましょう。
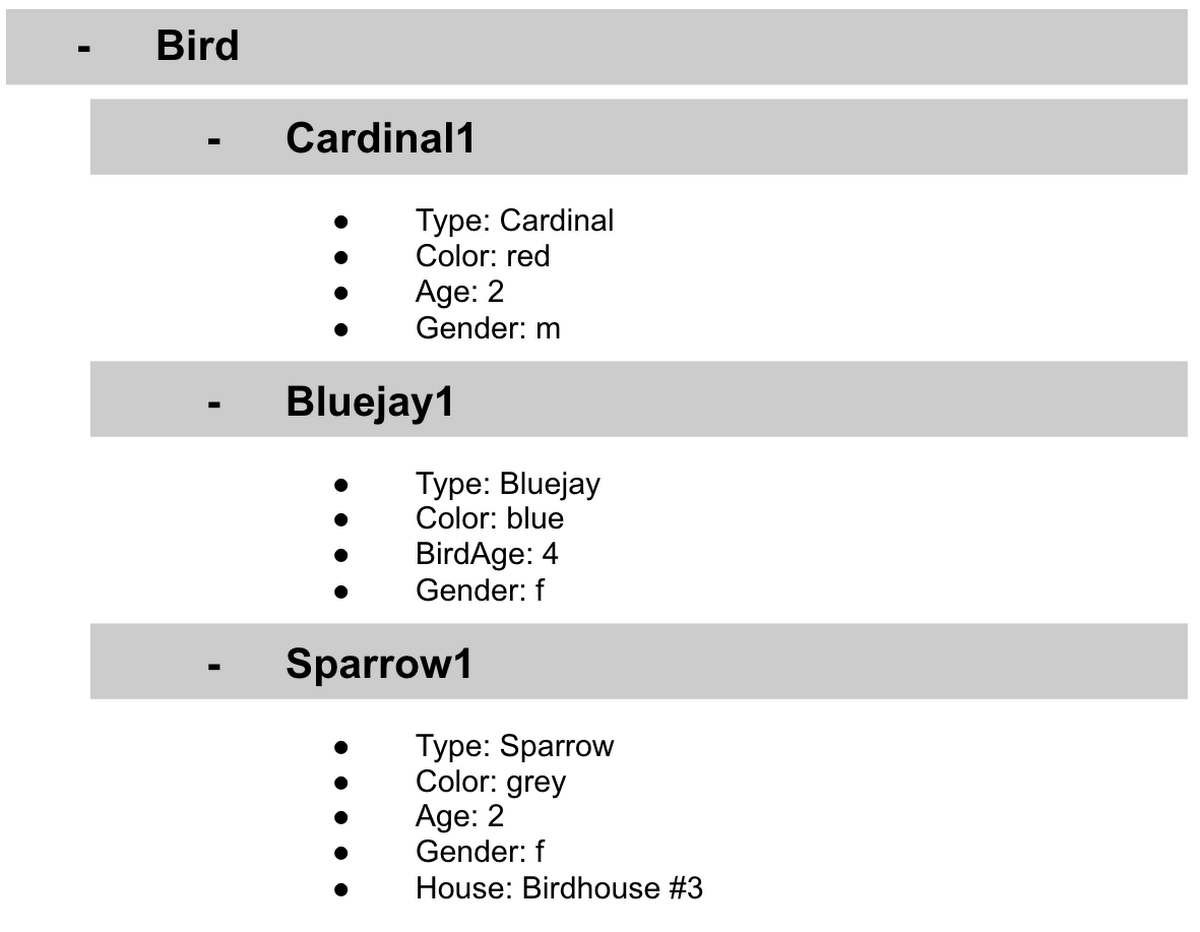
Cardinal1 にも、Type、Color、Age、Gender が表示されていますが、Sparrow1 では、House も表示されています。非リレーショナル データベースでは、データベース内のすべての鳥について同じ情報を保存しなければならないというスキーマが存在しないため、このようなことが可能となっています。他の鳥に関して保存されている情報に関係なく、それぞれの鳥に必要な情報を保存できます。これは柔軟性という点では大きなメリットですが、柔軟性があるからこそ、標準的な命名規則を維持することが非常に重要です。
では、なぜ標準的な命名規則を使うことが重要なのかを見ていきましょう。上の例で、人間に「Cardinal1 の Age はいくつですか」と尋ねると、おそらく「2」という答えが返ってくるでしょう。また、「Bluejay1 の Age はいくつですか」と尋ねれば、おそらく「4」と答えるでしょう。この回答はどちらも正解ですが、人間には「Age」がどのような意味かという前提があるからこそ正解となるのです。一方、コンピュータには前提がありません。コンピュータに「Cardinal1 の Age はいくつですか」と尋ねると、「2」と答えるでしょうが、「Bluejay1 の Age はいくつですか」と尋ねれば、答えることができないでしょう。これは、コンピュータが「Age」というキーワードを探しているので、他に「Age」を意味する単語があるかを判断するためのコンテキスト上の手がかりを得られないために起こります。一方、コンピュータに「Bluejay1 の BirdAge はいくつですか」と尋ねれば、「4」と答えるでしょう。では、Bluejay1 の年齢を知るためには「BirdAge」を探し、Cardinal1 の年齢を知るためには「Age」を探すようにコンピュータに指示しなければならないと、何が不便なのでしょうか。データのストラクチャに注意しないと、Cardinal1 の年齢と Bluejay1 の年齢を知るために、まったく異なる 2 つの命令セット(つまりソフトウェア コード)を書かなければならなくなります。しかし、データ ストラクチャさえしっかりしていれば、これは問題ではなく、むしろ柔軟性が増すことでメリットとなります。
この例からわかることは、厳格なスキーマがなくても、ドキュメントの形式に関する規則を定義できる(定義すべき)ということです。規則が定義されていないと、すぐに使い勝手が悪くなってしまいます。
情報へのアクセス方法
では、その情報にどのようにアクセスするか説明します。プルダウン リストの例で、どの鳥が青いかという情報を知りたい場合、リストのすべてのセクションを展開して、その鳥が青いかどうかをチェックする必要があります。ご想像のとおり、データベースにたくさんの鳥が登録されるようになると、すべてのプルダウンを開いて、その鳥が青いかどうかを確認するのが面倒になってきます。幸いなことに、Firestore ではこのようなタイプのクエリをデータに対して実行することができ(詳しくはこちらをご覧ください)、条件を満たすすべてのドキュメントを受け取ることができます。一方、Cardinal1 に関するすべての情報を知りたい場合は、Cardinal1 のプルダウンを開くだけで、その鳥に関するすべての情報を得ることができます。
ここからは、Firestore 特有の用語を使ってみましょう。先ほどの例で、こちらを使いました。
Firestore では、データがコレクションに保存されます。コレクションは、スプレッドシートのタブのようなものです。
コレクションは、データを整理するために使用されます。たとえば、鳥と魚のデータを集めたい場合、鳥のデータは「Birds」コレクションに、魚のデータは「Fish」コレクションに入れることができます。

これは、Firestore で使用されるストレージの単位です。この例では、それぞれの鳥がそれぞれのドキュメントになっています。ドキュメントはコレクションの中にあります。これが 1 つのドキュメントに含まれる内容です。
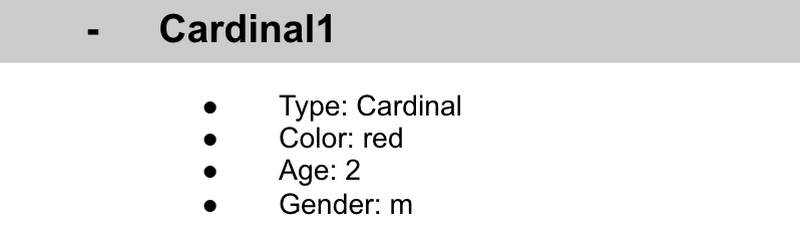
各ドキュメントは、シートの各行に対応しています。次の図は、各列のヘッダーがドキュメント内のプロパティ名に対応し、行内の各値がドキュメント内の値に対応していることを示しています。
各ドキュメントは、一意の識別子によって識別されなければなりません。この例では、「BirdID」です。BirdID の値はリストの最上位に格納されているので、ドキュメントを閉じたときには Cardinal1 しか表示されず、Cardinal1 はドキュメント内に格納されていないことにも注意してください。
すべてのドキュメントは、その場所によって一意に識別できます。コードに移る前に、まずは言葉で考えてみましょう。プルダウン リストから Sparrow に関するデータを取得するように誰かに伝えたい場合は、次のように伝える必要があります。
鳥のプルダウン リストで、Sparrow1 の下にある情報をすべて取得して、sparrow1Info という 1 枚の紙にまとめてください。
では、Firestore の用語を使ってもう一度試してみましょう。
Birds コレクションで、Firestore のデータベース(db)から Sparrow1 のドキュメントを取得し、sparrow1Info として保存してください。
では、コードで試してみましょう。
var sparrow1Info = db.collection('birds').doc('sparrow1');
サブコレクションはドキュメントに関連付けられたコレクションです。プルダウン リストの例で、特定の鳥の目撃情報に関するドキュメントを格納する sightings というコレクションを追加できます。このようになります。
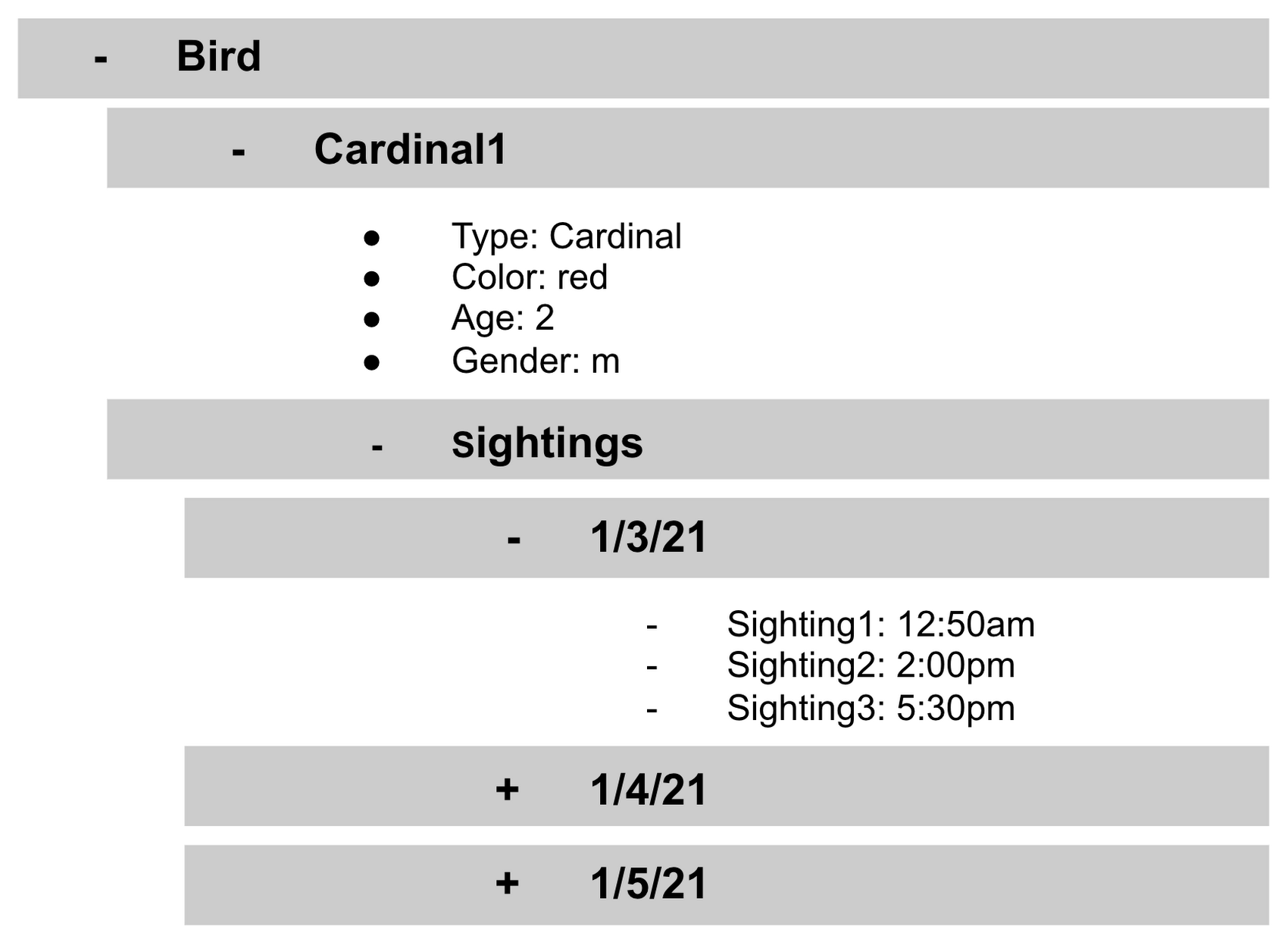
重要なのは、すべてのドキュメントに同じサブコレクションがある必要はないということです。たとえば、Cardinal1 を sightings のサブコレクションを持つ唯一のドキュメントにできます。
Firestore について Google で検索する方法
新しい技術を学ぶうえで最も難しいのは、多くの場合、探している答えを得るために Google 検索に入れる適切な用語を知ることです。ここでは、開始時に役立つキーワードをいくつか紹介します。
質問:
Firestore に保存するには、どのようにデータを配置すればよいですか。
検索:
ドキュメント データベースの暗黙スキーマ設計
質問:
Firestore に似たデータベースにはどのようなものがありますか。
検索:
ドキュメント データベースとは
質問:
Birds コレクションのすべてのドキュメントを取得するにはどうすればよいですか。
検索:
Firestore でワイルドカードを使用する方法
次のステップ
このガイドを参考にし、Firestore を使った初めてのアプリケーションを構築してみましょう。https://firebase.google.com/docs/firestore/quickstart
-Google Cloud テクニカル レジデント Allison Kornher


