Google アナリティクス 4(GA4)と BigQuery ML を使用した、ゲーム デベロッパーのためのチャーン予測

Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
ユーザーの維持は、モバイルゲームのデベロッパーにとって非常に大きな課題です。2019 年版のモバイルゲーム業界分析によると、初日以降のユーザー維持率はほとんどのモバイルゲームでわずか 25% にすぎません。アプリの初回利用後も多くのユーザーを維持するために、デベロッパーは特定のユーザーがアプリに戻りたくなるような動機やインセンティブを用意することができます。しかしそのためには、アプリの初回利用から 24 時間後以降にアプリに戻ってくる特定のユーザーの傾向を把握する必要があります。
このブログ投稿では、ゲームアプリから抽出した Google アナリティクス 4 のデータに対して BigQuery ML を使って傾向モデルを実行し、特定のユーザーがアプリに戻ってくる可能性を判断する方法をご説明します。
このようなエンドツーエンド ソリューションのアプローチは、Firebase 向け Google アナリティクスを使用する他のタイプのアプリや、Google アナリティクス 4 を使用するアプリやウェブサイトでも使用できます。このブログ投稿に書かれている手順を試したり、ソリューションをご自身のデータで実施したりするには、こちらの Jupyter Notebook をご活用ください。
このブログ投稿と付随する Jupyter Notebook を使用して、以下を学ぶことができます。
Google アナリティクス 4 向け BigQuery Export データセットの使い方
ユーザー属性と行動の属性を使ってトレーニング データを準備する方法
BigQuery ML を使って傾向モデルをトレーニングする方法
BigQuery ML モデルを評価する方法
BigQuery ML モデルを使って予測を行う方法
モデルの分析情報を実際の導入に反映させる方法
アプリとウェブサイトの測定を単一のプラットフォームに統合する Google アナリティクス 4(GA4)のプロパティが、Google アナリティクスでデフォルトで利用できるようになりました。GA4 を使用して、ウェブサイト、アプリ、またはその両方を測定することで、ビジネスにおける顧客エンゲージメントをより詳細に把握できます。Google アナリティクス 4 のリリースにより、すべてのユーザーが Google アナリティクスの BigQuery Export データを利用できるようになりました。Google アナリティクス 4 プロパティをすでにご利用中の場合は、こちらのガイドに沿って、GA データを BigQuery にエクスポートする設定を行ってください。
BigQuery Export を設定したら、データを BigQuery で探索できます。Google アナリティクス 4 では、イベントベースの測定モデルを使用します。データ内の各行は 1 つのイベントを表し、追加のパラメータとプロパティを持ちます。BigQuery Export のスキーマでデータの構造を把握できます。
このブログ投稿では、実際のモバイルゲーム アプリ「Flood It!」の公開サンプル エクスポート データ(Android、iOS)を使用して、チャーン予測モデルを構築します。独自のアプリやウェブサイトのデータを使用することもできます。
データは次のようになります。データセット内の各行は一意のイベントで、イベント パラメータ用にネストされたフィールドを含めることができます。
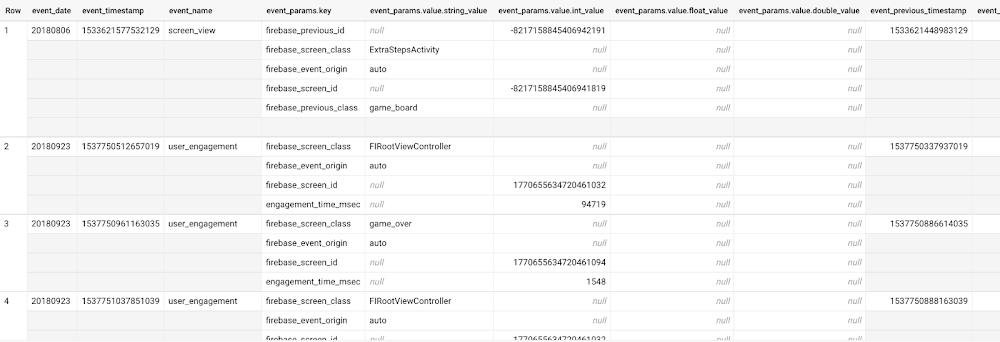
このデータセットには、1 万 5,000 人を超えるユーザーに関する 570 万件のイベントが含まれています。
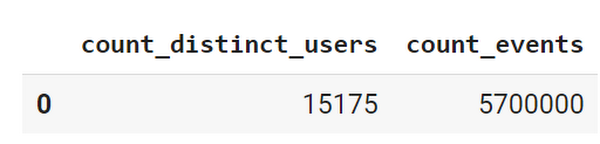
目標は、サンプルアプリのデータセットに対して BigQuery ML を使用し、ユーザー属性とアプリのインストールから 24 時間以内のアクティビティに基づいて、ユーザーがチャーンするかしないかの傾向を予測することです。
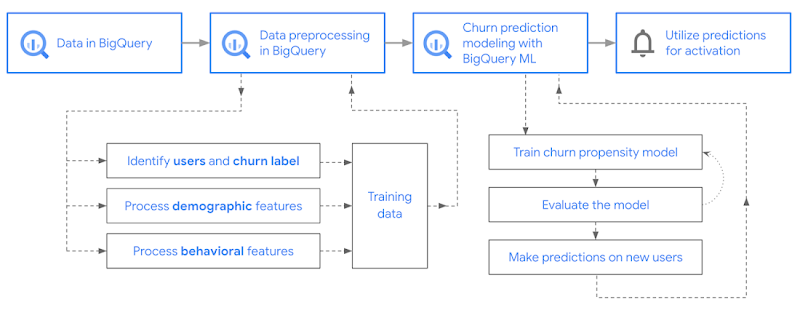
以降のセクションでは、次の方法についてご説明します。
GA4 の未処理のイベントデータを前処理する
ユーザーの識別とラベル機能
ユーザー属性の特徴を処理する
行動の特徴を処理する
BigQuery ML を使用して分類モデルをトレーニングする
BigQuery ML を使用してモデルを評価する
BigQuery ML を使用して予測を行う
予測を有効化に活用する
未処理のイベントデータを前処理する
未処理のイベントデータは、トレーニング データとして使用するのに適した形状や形式になっていないため、そのまま機械学習モデルのトレーニングに使用することはできません。そこでこのセクションでは、分類モデルのトレーニング データとして使用するために、未処理のデータを適切な形式に前処理する方法をご説明します。
このセクションの操作を完了すると、ユースケースのトレーニング データは次のようになります。
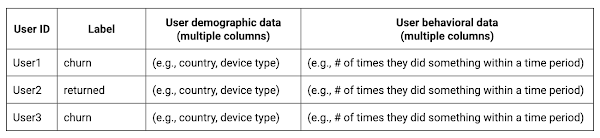
このトレーニング データの各行は一意のユーザーを表し、それぞれに異なるユーザー ID(user_pseudo_id)を持ちます。
ユーザーの識別とラベル機能
まず、データセットをフィルタして、アプリに戻る可能性が低いユーザーを除外しました。アプリの使用時間が 10 分未満のユーザーを「バウンス」ユーザーと定義し、それ以外のすべてのユーザーは次のようにラベル付けしました。
churned(チャーン): アプリを最初に利用してから 24 時間後のイベントデータがないユーザー。
returned(リピート): アプリを最初に利用してから 24 時間後に少なくとも 1 つのイベントが記録されたユーザー。
バウンスやチャーンの定義は、ユースケースに合わせて変えることができます。また、次に挙げるような、チャーン以外のことを予測することも可能です。
ユーザーがゲーム内通貨を購入する可能性が高いかどうか
ゲームを n レベルまで完了する可能性
ゲームを n 時間プレイする可能性
このようなケースでは、各レコードをラベル付けして、ラベルの列から予測対象を特定できるようにします。
今回使ったデータベースからは、およそ 41% のユーザー(5,557 人)がバウンス ユーザーであることがわかりました。そして、残りのユーザー(8,031 人)のうち、およそ 23%(1,883 人)は 24 時間後にチャーンしました。
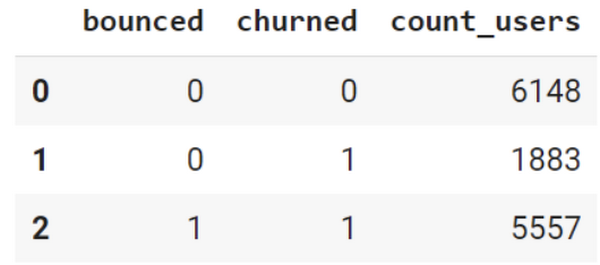
これらの bounced(バウンス)列と churned(チャーン)列は、以下の SQL コードのスニペットを使用して作成しました。
Jupyter Notebook では、bounced ラベルと churned ラベルを具体化するために使用したすべてのクエリを確認できます。
ユーザー属性の特徴を処理する
次に、複数の列にまたがっているユーザー属性データと行動データの両方に特徴を追加しました。ユーザー属性データと行動データの両方を組み合わせることで、より予測性の高いモデルを作ることができます。
各ユーザーの次のフィールドをユーザー属性の特徴として使用しました。
geo.country
device.operating_system
device.language
1 人のユーザーがこれらのフィールドで一意の値を複数持つ場合があります。たとえば、ユーザーが 2 つの異なるデバイスからアプリを使用している場合などです。そこで単純化するために、ユーザーが最初にアプリを使用したときの値を使用しました。
行動の特徴を処理する
GA4 エクスポート データセットには、app_info、device、event_params、geo などの追加のユーザー属性情報もあります。user_properties を使用して、ヒットごとにユーザー属性情報を Google アナリティクスに送信することもできます。さらに、お使いのシステムに自社データがある場合は、user_id に基づいて、そのデータを GA4 エクスポート データと結合できます。
データからユーザーの行動を抽出するために、最初のユーザー エンゲージメントから 24 時間以内のユーザーの行動を調べました。Google アナリティクスによって自動的に収集されるイベントのほかに、ユーザー行動分析の調査対象として役立つ、ゲームに推奨されるイベントもあります。このユースケースでは、ユーザーのチャーンを予測するために、最初のユーザー エンゲージメントから 24 時間以内にユーザーのフォロー イベントが収集された回数をカウントしました。
user_engagement
level_start_quickplay
level_end_quickplay
level_complete_quickplay
level_reset_quickplay
post_score
spend_virtual_currency
ad_reward
challenge_a_friend
completed_5_levels
use_extra_steps
以下のクエリは、これらの特徴の計算方法を示しています。
行動データを集計して抽出するために使用したクエリについては、ノートブックをご覧ください。ご自身のユースケースに合わせて異なるイベントセットを使用できます。イベントの完全なリストを表示するには、以下のクエリを使用します。
次に、意図した構造がトレーニング データセットに確実に反映されるように、特徴を組み合わせました。テーブル内の以下の列を使用しました。
ユーザー ID:
user_pseudo_id
ラベル:
churned
ユーザー属性の特徴
country
device_os
device_language
行動の特徴
cnt_user_engagement
cnt_level_start_quickplay
cnt_level_end_quickplay
cnt_level_complete_quickplay
cnt_level_reset_quickplay
cnt_post_score
cnt_spend_virtual_currency
cnt_ad_reward
cnt_challenge_a_friend
cnt_completed_5_levels
cnt_use_extra_steps
これで、BigQuery ML で分類機械学習モデルをトレーニングするためのデータセットが準備できました。トレーニングされたモデルは、トレーニング データに基づいて、チャーン(churned=1)とリターン(churned=0)の間の値で傾向スコアを出し、ユーザーのチャーンの可能性を示します。
分類モデルをトレーニングする
CREATE MODEL ステートメントを使うと、BigQuery ML はデータをトレーニングとテストに自動的に分割します。このため、モデルはトレーニング直後に評価できます(詳しくは、ドキュメントをご覧ください)。
ML モデルでは、次のような分類アルゴリズムをそれぞれの長所や短所に基づいて選択できます。
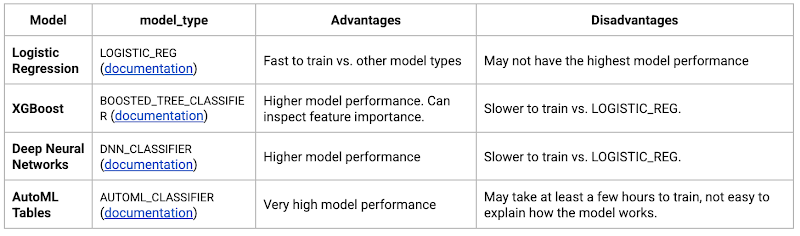
多くの場合、最も高速にトレーニングできるロジスティック回帰が、開始点として使用されます。以下のクエリは、BigQuery ML を使ってロジスティック回帰の分析モデルをトレーニングした方法を示しています。
トレーニング前に特徴を追加して前処理する簡単な一例として、month、julianday、dayofweek を日付とタイムスタンプから抽出しました。TRANSFORM() を CREATE MODEL クエリで使用すると、モデルは抽出された値を記憶できます。そのため、後でモデルを使って予測を行う際、これらの値を再度抽出する必要はありません。別のタイプのモデル(XGBoost、ディープ ニューラル ネットワーク、AutoML Tables)をトレーニングするためのクエリの例は、ノートブックでご覧ください。
モデルを評価する
モデルのトレーニングが終了してから、ML.EVALUATE を実行して、モデルの precision、recall、accuracy、f1_score を生成しました。

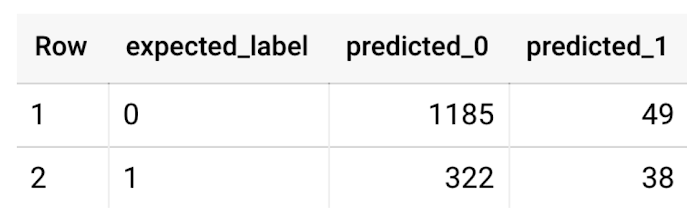
このテーブルは、次のように解釈できます。

BigQuery ML を使用して予測を行う
理想的なモデルができあがったので、ML.PREDICT を実行して予測を行いました。傾向モデルの場合、最も重要な出力は、ある行動が発生する可能性です。次のクエリは、24 時間後以降にユーザーが戻る可能性を返します。値が 1 に近いほど、ユーザーが戻る可能性が高く、値が 0 に近いほど、ユーザーがチャーンする可能性が高くなります。
予測を有効化に活用する
ユーザーに対してモデル予測が可能になったら、この分析情報をさまざまな方法で活用できます。今回の分析では、user_pseudo_id をユーザー識別子として使用しました。ただし、理想的なのは、user_id がアプリから Google アナリティクスに送り返されることです。その場合は、モデル予測に自社データを利用できることに加え、モデル予測を自社のデータに再び結合することもできます。
モデル予測は、ユーザー属性として Google アナリティクスにインポートして戻すことができます。これを行うには、Google アナリティクス 4 のデータ インポート機能を使用します。予測値に基づいて、オーディエンスの作成と編集を行い、オーディエンス ターゲティングを行うことも可能です。たとえば、予測の可能性が 0.4~0.7 のユーザーをオーディエンスに設定して、チャーンするか戻るかがはっきりしないと予測されるユーザーを示すことができます。
Firebase アプリの場合、セグメントのインポート機能を使用できます。Remote Config、Cloud Messaging、アプリ内メッセージングなどの Firebase サービスを介して特定されたユーザーにターゲットを絞って、ユーザー エクスペリエンスを調整できます。このためには、BigQuery から Firebase にセグメント データをインポートします。その後で、ユーザーに通知を送信する、ユーザーのためにアプリを設定する、デバイス間でのユーザーの移動を追跡するといったことができます。
Salesforce などの CRM でリマインダー メールを送信するなどして、ターゲットを絞ったマーケティング キャンペーンを実施できます。
このブログ投稿で使用しているコードはすべて、GitHub リポジトリにあります。
次のステップ
継続的なモデル評価と再トレーニング
ユーザーからより多くのデータを収集するのに伴い、新しいデータでモデルを定期的に評価し、モデルの品質が低下していると思われる場合はモデルを再トレーニングします。
あらゆる ML ワークフローにおいて、継続評価、つまり本番環境の機械学習モデルが新しいデータでも高いパフォーマンスを出せるようにするためのプロセスは不可欠です。継続評価はモデルドリフトの検出に有効です。モデルドリフトとは、モデルのトレーニングに使用されたデータが現在の環境を反映したものではなくなったときに発生する現象です。
継続的なモデル評価とモデルの再トレーニングの詳細については、ブログ投稿、BigQuery ML、ストアド プロシージャ、Cloud Scheduler を使用した継続的なモデル評価をご覧ください。
その他のリソース
この投稿で取り扱ったトピックについて詳しくは、次のリソースをご確認ください。
BigQuery ML を使用して、その他の機械学習ソリューションを簡単に構築する方法について詳しくは、次のリソースをご覧ください。
この投稿についての感想や、今後取り上げてほしいトピックがあればお知らせください。宛先は、Twitter アカウント @polonglin と @_mkazi_ までお願いいたします。
レビューに協力してくれた Abhishek Kashyap、Breen Baker、David Sabater Dinter に感謝します。
-デベロッパー アドボケイト Minhaz Kazi
-デベロッパー アドボケイト Polong Lin