KRM を使用したプラットフォームの構築: パート 2 - Kubernetes Resource Model の仕組み
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
この投稿は、Kubernetes Resource Model(KRM)を使用したデベロッパー向けプラットフォームの構築に関するシリーズのパート 2 です。
パート 1 では、優れたデベロッパー プラットフォームの条件として、ユーザーにとって理解しやすい抽象化や、拡張性、セキュリティが求められるということを学びました。このパート 2 では、Kubernetes Resource Model(KRM)を取り上げて、Kubernetes の宣言型かつ常時調整型という特性を紹介しながら、デベロッパー プラットフォームに最適な安定したベースレイヤが提供される様子を見ていきます。
まず、KRM の仕組みについて理解するための予備知識として、Kubernetes について学んでおきましょう。
Kubernetes は、オープンソースのコンテナ オーケストレーション エンジンであり、複数のサーバー(ノード)を 1 つの大きなコンピュータ(クラスタ)として扱えるのが特長です。Kubernetes は、空きのあるノードを見つけてそこでコンテナを実行するように自動スケジュールします。Kubernetes のノードはすべて、Kubernetes コントロール プレーンから指示を受けとります。Kubernetes コントロール プレーンは、ユーザーから指示を受けとります。
Google Kubernetes Engine(GKE)は、Google が提供する Kubernetes のマネージド サービスであり、以下のようなアーキテクチャになっています。青で示されている「ゾーン コントロール プレーン」の領域をご覧いただくと、GKE コントロール プレーンが、リソース コントローラ、スケジューラ、バックエンド ストレージという複数のワークロードから構成され、これらのワークロードから API サーバーに向かう矢印があることがわかります。
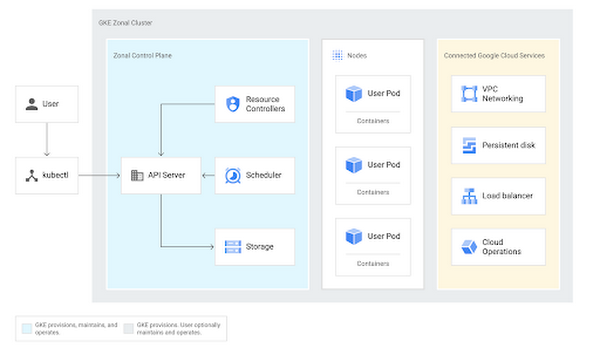
API を中心とした連係
Kubernetes API サーバーは、クラスタにおいて中心的役割を果たす中枢部分であり、クラスタのリソースについて望ましい状態と実際の状態の両方を把握しています。では、Kubernetes クラスタ上でコンテナが実行される仕組みについて詳しく見ていきましょう。
Kubernetes では、宣言型構成ファイルを使用して主な構成を行います。このファイルは、Kubernetes で読み取り可能な Kubernetes Resource Model(KRM)という形式で記述されています。この KRM が、クラスタで実行したいこと(目標とする状態)を伝える手段となります。
KRM は通常、YAML 形式で記述します。たとえば、クラスタ上で “hello-world” ウェブサーバーを実行するとしましょう。そのために、YAML ファイルに以下のように Kubernetes Deployment を記述し、hello-world のコンテナ イメージを実行するように設定します。
ここでは、hello-world ウェブサーバーの望ましい状態、つまり、ノード上で実行したいイメージや、コンテナのレプリカ(コピー)の数(3)を指定しています。そのほかに、“apiVersion”、“kind”、“metadata”、“spec” などのフィールドがあります。これらは、Kubernetes Resource Model を使用する全リソースに共通の標準フィールドです。これについて詳しくは、シリーズの次回以降で説明します。
望ましい状態を Kubernetes リソースとして定義した YAML ファイルを準備したら、このリソース ファイルをクラスタに「適用」します。適用するにはいくつかの方法があります。簡単なのは、コマンドライン ツールの kubectl を使用して、ローカル ファイルをリモートの Kubernetes API サーバーに送信する方法です。`kubectl apply -f <ファイル名>` と指定して KRM リソースを Kubernetes クラスタに適用すると、このリソースが検証されてから、API サーバーの背後にある保存先 etcd に格納されます。
Kubernetes リソースを巡る処理の流れ
Kubernetes リソースが etcd に到達してからが、興味深いところです。Kubernetes コントロール プレーンにおいて、望ましい状態が新しくなったことが識別されると、現在の状態を Deployment YAML の内容に一致させるための処理が始まります。Kubernetes コントロール プレーンで実行されているリソース コントローラは、API サーバーに対して数秒ごとにポーリングし、なんらかのアクションを実行する必要があるかどうかを数秒ごとに問い合わせています。Kubernetes Deployment にはそれぞれのリソース コントローラがあり、このコントローラには Deployment リソースの処理ロジック(たとえば、コンテナに「ノードへのスケジュールが必要」とマークを付けるなど)が含まれます。このリソース コントローラが、API サーバーの KRM リソースを更新します。
一方で、やはり API サーバーにポーリングしている Pod スケジューラが、スケジュールが必要な Pod(コンテナ)が Deployment(hello-world)にあることを認識します。このスケジューラは続けて、それぞれの Pod がクラスタ内の特定のノードに割り当てられるように KRM リソースを更新します。
さらに、クラスタに含まれる個々のノードも、API サーバーにポーリングを行っており、自身に割り当てられた Pod があるかどうかチェックしています。割り当てられた Pod がある場合は、指示に沿ってその Pod のコンテナを実行します。
Kubernetes のすべての要素が、API サーバーに格納された望ましい状態から指示を受けていることにご注目ください。この望ましい状態は、ユーザーおよびクラスタ上のその他の外部要素に由来していますが、それだけではなく、Kubernetes クラスタそのものにも由来しています。Deployment コントローラは、Pod に「スケジュールが必要」とマークを付けることで、スケジューラにリクエストを伝えます。スケジューラは、Pod をノードに割り当てることで、ノードにリクエストを伝えます。一連の流れにおいて、Kubernetes リソースに対する命令的呼び出し(「これを実行せよ」や「あれを更新せよ」)は一切なく、すべては宣言という形で行われています(「これは Pod であり、このノードに割り当てられています」など)。
このデプロイのプロセスは、一度行ったらそれで終わりではありません。クラスタで実行中の Pod を削除する必要が生じたら、Deployment のリソース コントローラがそれに気付き、別の Pod が作成されるようにスケジュールします。続けて Pod スケジューラが、空きができたノードにその Pod を割り当てる、といった具合です。Kubernetes はこのように、現在の状態を望ましい状態と一致させるべく、常に調整を続けています。宣言に基づくこのような自己修復モデルは、Kubernetes API のその他の要素にも適用されます。たとえば、ネットワーキング リソースや、ストレージ、構成にもそれぞれのリソース コントローラがあり、このモデルにのっとっています。
さらに、Kubernetes API は拡張に対応しており、任意のユーザーが Kubernetes のカスタム コントローラおよびリソース定義を記述できます。完全にクラスタの外にあるリソース(クラウドでホストされているデータベースなど)に拡張することも可能です。これについては、シリーズの次回以降で取り上げます。
KRM と GitOps: 動的な連係
YAML ファイルを使って構成をデータとして定義することのメリットの 1 つは、リソースを GitHub に commit し、それを中心として CI / CD パイプラインを作成するというやり方ができる点です。このように、構成を GitHub に保存して自動的にデプロイする運用モデルは、GitOps と呼ばれます(WeaveWorks が作った用語です)。
GitOps モデルでは、リソース ファイルに対して “kubectl apply -f” を実行するのではなく、継続的デプロイ パイプラインがこのコマンドを代わりに実行するように設定します。この方法だと、Git に新しく commit された KRM が CI / CD の一環として自動的にデプロイされるので、人為的なミスを回避できます。また、GitOps モデルなら、クラスタでデプロイされている対象を厳密に監査でき、サービス停止時には構成を「最後に動作していた commit」にロールバックすることも可能です。
GitOps と KRM を使用するアプリケーションの例を見てみましょう。
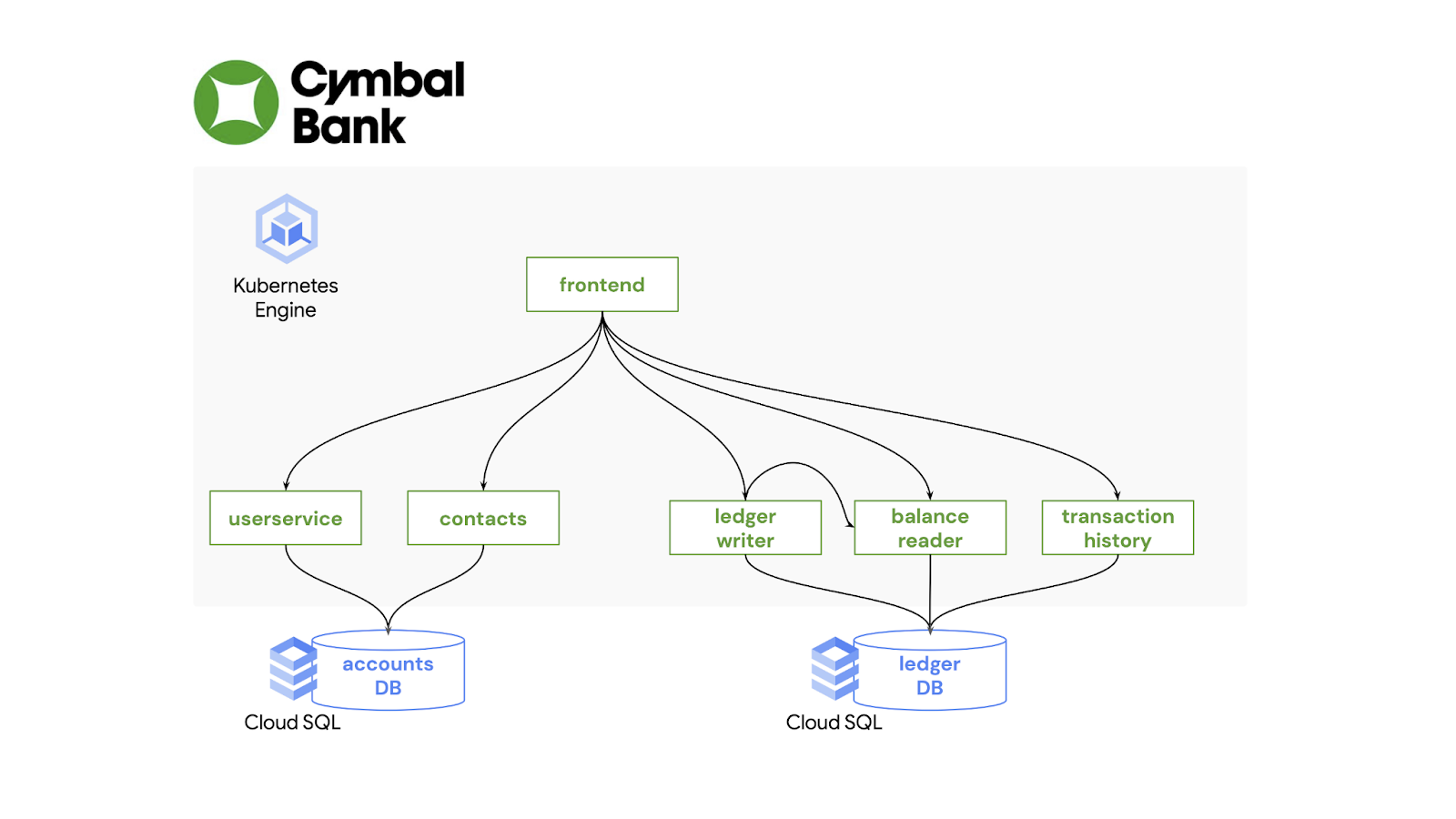
Cymbal Bank はリテール バンキングのウェブ アプリケーションであり、口座への入金や送金に対応しています。Java と Python で記述され、Google Cloud 上の 2 つの SQL データベースを使用しています。先ほどの hello-world の Deployment と同様、Cymbal Bank のフロントエンドおよびバックエンドの 5 つのサービスにはそれぞれの Kubernetes Deployment があります。
各ワークロードに対応するその他の Kubernetes リソースも定義します(クラスタ内での Pod 間のルーティングを行う Service など)。
これらの YAML ファイルをすべて Git リポジトリに commit したら、これらのリソースを GKE に自動デプロイするように Google Cloud Build パイプラインを設定します。構成リポジトリの主ブランチへの Git push が発生すると、このビルドがトリガーされる、本番環境のクラスタに対して “kubectl apply -f” が実行される、最新のリソースが Kubernetes API サーバーにデプロイされるという流れになっています。
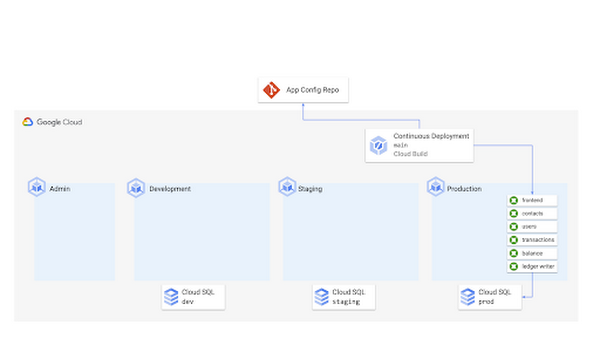
このパイプラインが実行されると、Cymbal Bank のすべての KRM リソースに対する kubectl apply -f コマンドの出力が表示されます。
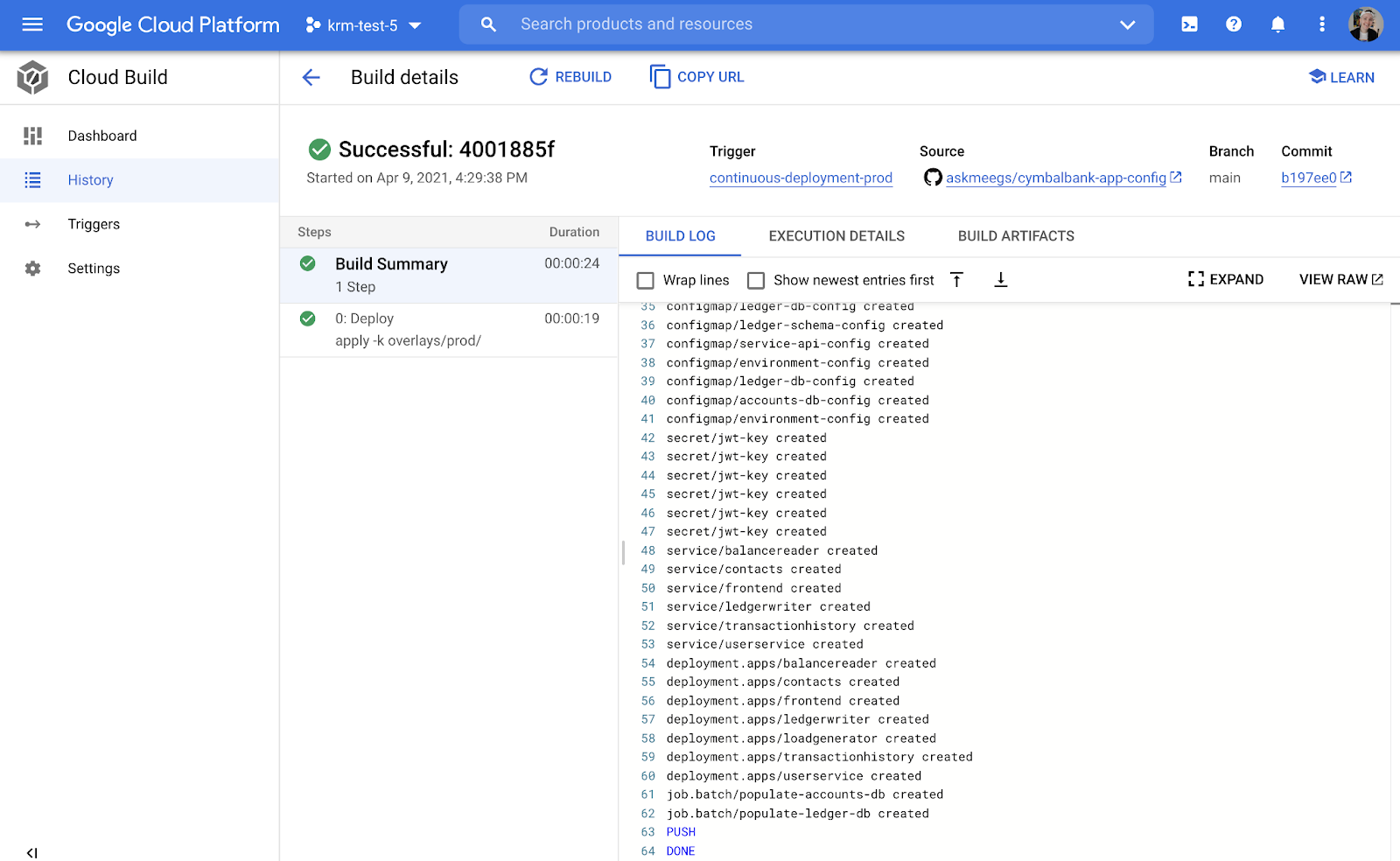
継続的デプロイのパイプラインが完了し、Cymbal Bank アプリの最新バージョンが本番環境で実行されています。
ご自分で試してみるには、パート 2 のデモをご覧ください。KRM を使って Cymbal Bank を GKE 環境にデプロイする方法を学べます。
次回は、この GitOps 環境を土台として、Cymbal Bank のアプリケーション デベロッパーになったつもりで、開発したばかりの最新機能を KRM を使って本番環境に移行してみましょう。
-デベロッパー プログラム エンジニア Megan O'Keefe




