Google Kubernetes Engine の階層化 KV キャッシュで LLM のパフォーマンスを向上させる

Danna Wang
Software Engineer
※この投稿は米国時間 2025 年 11 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
大規模言語モデル(LLM)は強力ですが、そのパフォーマンスは、キーと値(KV)のキャッシュによる NVIDIA GPU メモリの膨大な使用量が、パフォーマンスのボトルネックになる場合があります。このキャッシュは、Key(K)と Value(V)の行列を保存して LLM 推論を高速化するうえで不可欠な要素であり、コンテキストの長さ、同時実行性、システム全体のスループットに直接影響します。Google の主な目標は、階層化されたノードローカル ストレージ ソリューションを活用して NVIDIA GPU の高帯域幅メモリ(HBM)を効率的に拡張し、KV キャッシュのヒット率を最大化することです。
LMCache チーム(Tensormesh の Kuntai Du 氏、Jiayi Yao 氏、Yihua Cheng 氏)とのコラボレーションにより、Google Kubernetes Engine(GKE)上で革新的なソリューションを開発しました。
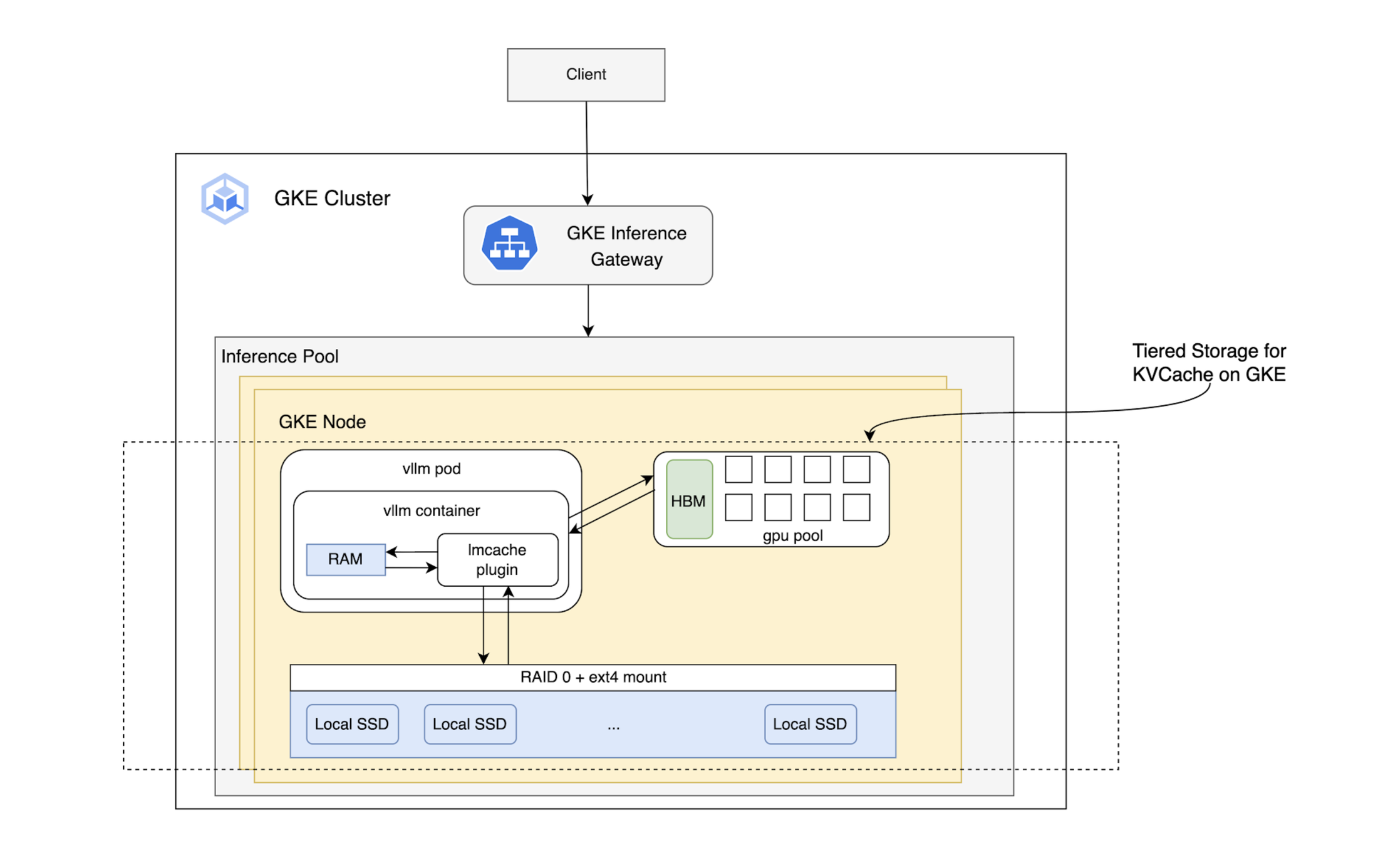
階層化ストレージ: HBM を超えて KV キャッシュを拡張
LMCache は、NVIDIA GPU の高速な HBM(ティア 1)にある KV キャッシュを、CPU RAM やローカル SSD などのより大きくコスト効率の高いティアへと拡張します。これによりキャッシュ全体のサイズが大幅に増加し、より多くのデータをアクセラレータ ノード上にローカル保持できるため、ヒット率が向上し、推論パフォーマンスが改善します。GKE ユーザーは、優れたパフォーマンスを維持しながら、コンテキスト ウィンドウの大きなモデルにも対応できるようになります。
パフォーマンス ベンチマークと結果
階層化 KV キャッシュのパフォーマンスを測定するために、各ストレージ レイヤ(HBM、CPU RAM、ローカル SSD)を順に満たすようにワークロードを構成し、テストを設計しました。これらの構成を、コンテキスト長の異なる複数の条件(1,000、5,000、10,000、50,000、100,000 トークン)でベンチマークしました。これらは次のような多様なユースケースを表しています。
-
1,000~5,000 トークン: 精度の高いペルソナや複雑な指示
-
10,000 トークン: 平均的なユーザー プロンプト(小規模な RAG)やウェブページ、記事コンテンツ
-
50,000 トークン: 大量の情報を詰め込むプロンプト
-
10 万トークン: 長編書籍に相当するコンテンツ
主なパフォーマンス指標は、ファースト トークンまでの時間(TTFT)、トークン入力のスループット、エンドツーエンドのレイテンシです。結果から、KV キャッシュのサイズごとに最も高いパフォーマンスを示したストレージ構成と、その際に得られたパフォーマンス向上が明らかになりました。
テストの構成
A3 メガマシン上に vLLM サーバーをデプロイし、emptyDir を介してローカル SSD をエフェメラル ストレージとして活用しました。
-
ハードウェア: NVIDIA H100 メガ 80GB GPU x 8
-
LMCache バージョン: v0.3.3
キャッシュの構成:
-
HBM のみ
-
HBM + CPU RAM
-
HBM + CPU RAM + ローカル SSD
-
ストレージ リソース: HBM: 640 Gi、CPU RAM: 1 Ti、ローカル SSD: 5 Ti
-
ベンチマーク ツール: SGLang bench_serving
リクエスト: システム プロンプトの長さを 1,000、5,000、10,000、50,000、100,000 トークンに設定してテストを実施しました。各システム プロンプトは、20 件の推論リクエストのバッチに共通のコンテキストを提供し、各リクエストは一意の 256 トークンの入力で構成され、512 トークンの出力を生成します。
コマンドの例:
ベンチマークの結果
テストでは、さまざまな合計サイズの KV キャッシュを検証しました。以下の結果は、サイズごとに最適なストレージ構成と、その際に得られたパフォーマンス向上を示しています。
テスト 1: キャッシュ(110 万~130 万トークン)は HBM に完全に収まる
結果: このシナリオでは、速度の遅いストレージ層を追加しても利点はなく、HBM のみの構成が最適な設定となりました。
テスト 2: キャッシュ(400 万~430 万トークン)は HBM 容量を超えるが、HBM と CPU RAM には収まる
テスト 3: 大規模キャッシュ(1,260 万~1,370 万トークン)では HBM と CPU RAM が飽和し、ローカル SSD にスピルする
まとめ
これらの結果は、階層化ストレージ ソリューションがノードローカル ストレージを活用することで、特に大規模な KV キャッシュを生成する長いシステム プロンプトを扱うシナリオにおいて、LLM の推論パフォーマンスを大幅に向上させることを明確に示しています。
LLM の推論を最適化するには、複数のインフラストラクチャ コンポーネント(ストレージ、コンピューティング、ネットワーキング)の連携を要する複雑な課題です。この取り組みは、推論ゲートウェイでのインテリジェントなロード バランシングから、モデルサーバー内の高度なキャッシュ ロジックに至るまで、エンドツーエンドの推論スタック全体を強化するための広範なイニシアチブの一環です。
Google は、LMCache に追加のリモート ストレージ ソリューションを統合し、さらなる機能強化を積極的に進めています。