ハイパーパラメータ調整を自動化して最良のモデルを見つける方法についての無料のトレーニング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
今日の投稿では、BigQuery ML の最近リリースされた自動ハイパーパラメータ調整機能を使用して、最適な機械学習モデルを簡単に作成する方法について解説します。8 月 19 日の無料トレーニングに登録すると、ハイパーパラメータ調整についてさらに経験を積み、質問に対して Google の専門家から回答が得られます。ライブでトレーニングに参加できない場合は、8 月 19 日以降にオンデマンドでご覧になれます。
自動調整機能がないと、ユーザーはいくつものトレーニング ジョブを動かし、結果を比較して、ハイパーパラメータを手作業で調整する必要があります。テストに使用する適切な候補が不明な場合は、この作業を行うことさえ不可能なことがあります。
SQL コードを 1 行追加するだけで、モデルを調整し、BigQuery ML によって自動的に最適なハイパーパラメータを見つけることができます。これにより、データ サイエンティストは手動でハイパーパラメータを繰り返しテストする時間を減らし、データから知見を得るための作業により多くの時間を振り分けられるようになります。このハイパーパラメータ調整機能は、BigQuery ML のバックグラウンドで Vertex Vizier を使用することにより可能になります。Vizier は Google Research により作成されたもので、Google 社内でハイパーパラメータ調整に広く使用されています。
BigQuery ML のハイパーパラメータ調整により、データの実務担当者は次のような成果を得られます。
コードを 1 行追加するだけで、ハイパーパラメータを自動的に調整し、検索スペースをカスタマイズして、モデルのパフォーマンスを最適化する
各種のハイパーパラメータを手作業でテストする時間を削減する
ハイパーパラメータが調整済みの過去のモデルからの学習結果転送を活用して、新しいモデルの収束を改善する
ハイパーパラメータ調整を使用してモデルを作成する方法
以下のコードに従い、最初に関連データを BigQuery プロジェクトに取り込みます。BigQuery 公開データセットの一部であるニューヨーク市のタクシーの移動データから、最初の 10 万行を使用して、以下のスキーマに示すように各種の特徴に基づいてチップの金額を予測します。
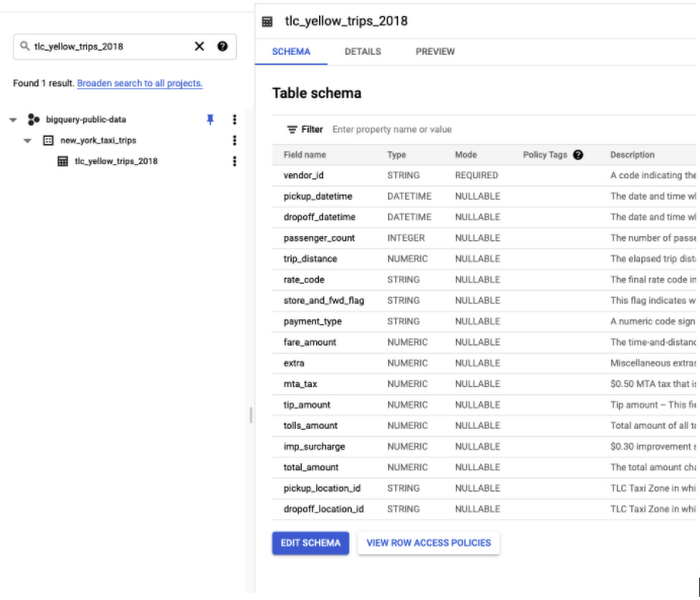
まず、米国(US)のマルチリージョン ロケーションにデータセット bqml_tutorial を作成してから、次のコードを実行します。
ハイパーパラメータ調整がない場合、以下のモデルはデフォルトのハイパーパラメータを使用することになり、これはほとんどの場合に理想的なものではありません。データ サイエンティストは、複数のモデルを各種のハイパーパラメータでトレーニングし、すべてのモデル間で評価指標を比較する必要があります。これは多くの時間を費やす処理で、すべてのモデルを管理するのが困難になる可能性もあります。以下の例では、デフォルトのハイパーパラメータを使用する線形回帰モデルをトレーニングし、タクシーの料金の予測を試みます。
ハイパーパラメータ調整がある場合(NUM_TRIALS を指定するとトリガーされます)、BigQuery ML はユーザーの指定した数の試行(NUM_TRIALS)にわたって、関連するハイパーパラメータの最適化を自動的に試みます。調整を試みるハイパーパラメータは、この便利なチャートにあります。
上の例では NUM_TRIALS=20 なので、BigQuery ML はデフォルトのハイパーパラメータから始めて、異なるハイパーパラメータの値をインテリジェントに使用しながらモデルのトレーニングを順に試みます。この例では、l1_reg と l2_reg で、こちらに記載されています。トレーニングの開始前にデータセットは 3 つの部分、つまりトレーニング、評価、テストに分割されます。トライアル用のハイパーパラメータの提案は、評価用のデータ指標に基づいて計算されます。トライアルのトレーニング各回の終わりに、テストセットを使用してトライアルが評価され、その指標がモデルに記録されます。不可視のテストセットを使用することで、調整の終了時に報告されるテスト指標の客観性が保証されます。
ハイパーパラメータ調整が有効なとき、データセットはデフォルトで 3 つに分割されます。このドキュメントに記載されているように、ユーザーはデータを別の方法で分割することも選択できます。
また、調整処理を高速化するため max_parallel_trials=2 を設定します。常に 2 つのトライアルを並列に実行するため、調整全体にかかる時間が、20 回ではなく 10 回のトレーニング ジョブを連続で行う場合と同程度になります。
トライアルの検査
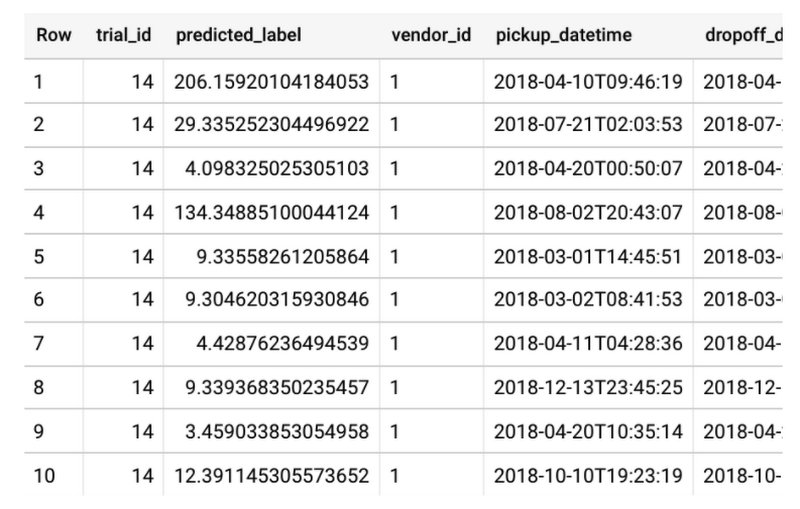
各トライアルで使用される正確なハイパーパラメータを検査するには、ハイパーパラメータ調整ありでモデルをトレーニングするとき、ML.TRIAL_INFO を使用して各トライアルを検査します。
ヒント: モデルのトレーニング中でも ML.TRIAL_INFO は使用できます。
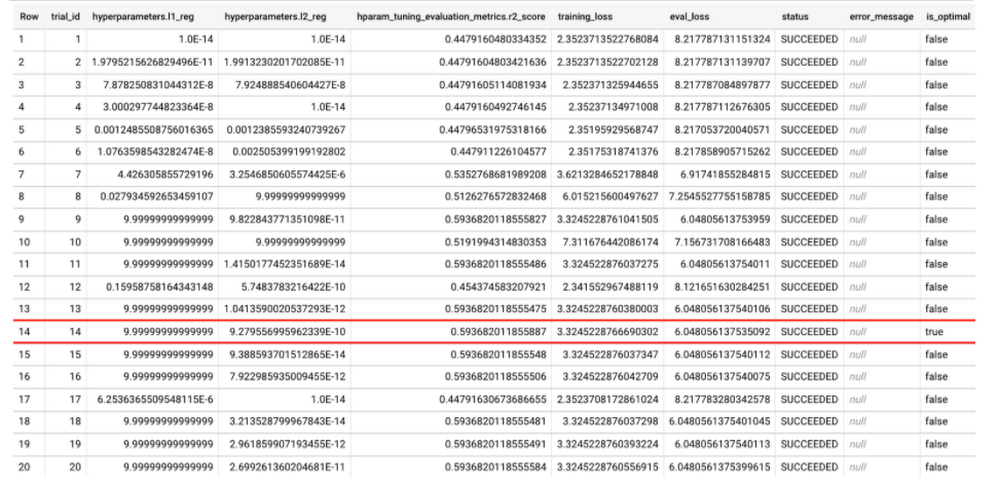
上のスクリーンショットで、ML.TRIAL_INFO には行ごとに 1 つのトライアルが表示され、各トライアルで使用される正確なハイパーパラメータの値が示されています。上のクエリの結果は、is_optimal 列で示されているように、14 回目のトライアルが最適であることを表しています。ここでトライアル 14 が最適なのは、hparam_tuning_evaluation_metrics.r2_score(評価セットの R2 スコア)が最も高いためです。ハイパーパラメータ調整により、R2 スコアは 0.448 から 0.593 へと飛躍的に改善されています。
このモデルのハイパーパラメータは num_trials と max_parallel_trials だけを使用して調整されたもので、BigQuery ML はこのドキュメントに記載されているように、デフォルトのハイパーパラメータとデフォルトの検索スペースを検索することに注意してください。デフォルトのハイパーパラメータ検索スペースを使用してモデルをトレーニングするとき、最初のトライアル(TRIAL_ID=1)ではモデルタイプ LINEAR_REG のデフォルトのハイパーパラメータのそれぞれについて、常にデフォルトの値が使用されます。これは、モデルの総合的なパフォーマンスがハイパーパラメータ調整なしのモデルより悪化しないことを保証するためです。
モデルの評価
それぞれのトライアルがテストセットでどれだけ的確に動作しているかを調べるには、ML.EVALUATE を使用します。これにより、すべてのトライアルについて行が、そのモデルに対応する評価指標とともに返されます。
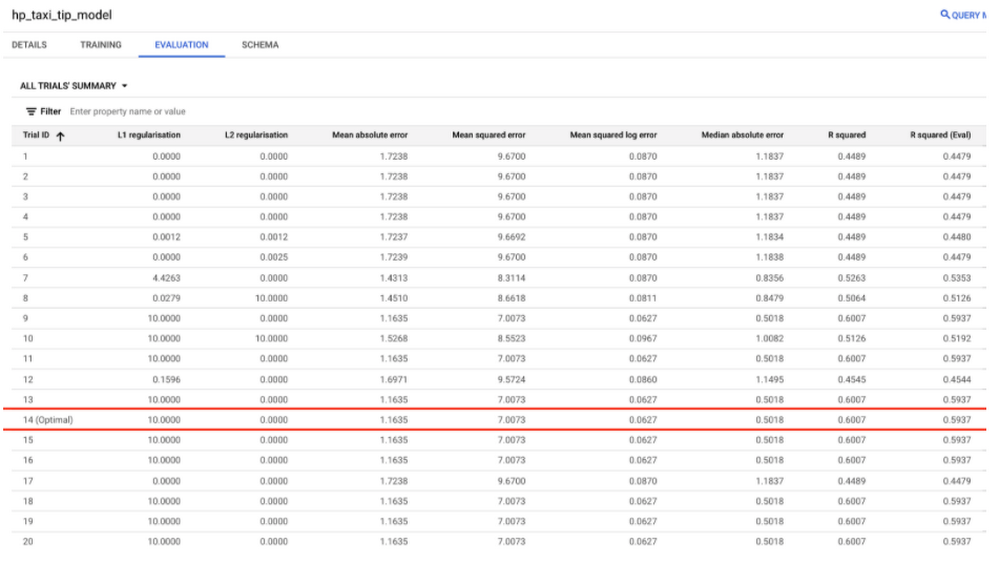
上のスクリーンショットで、列 [R squared] と [R squared (Eval)] は、それぞれテストと評価セットの評価指標に対応しています。詳しくは、このデータ分割についてのドキュメントをご覧ください。
ハイパーパラメータ調整されたモデルによる予測
では BigQuery ML は、予測を行うとき使用するトライアルをどのように選択するでしょうか。ML.PREDICT はデフォルトで最適のトライアルを使用し、予測のためにどの trial_id が使用されたかを返します。手順に従って、使用するトライアルを指定することもできます。
検索スペースのカスタマイズ
特定のハイパーパラメータを選んで最適化する、またはハイパーパラメータごとにデフォルトの検索スペースを変更することが望ましい場合もあります。各ハイパーパラメータについてデフォルトの範囲を見つけるには、ドキュメントの「ハイパーパラメータと目的」セクションをご覧ください。
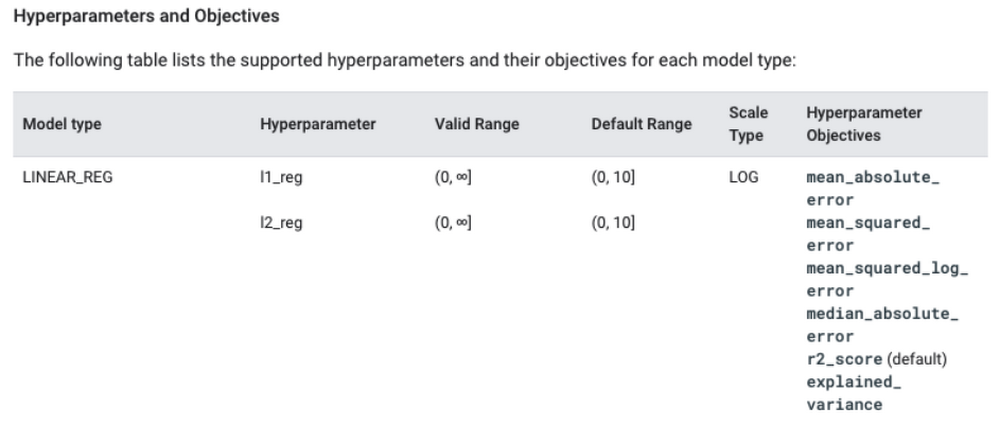
LINEAR_REG については、各ハイパーパラメータの可能な範囲を見ることができます。ドキュメントを参照として使用し、独自のカスタマイズされた CREATE MODEL ステートメントを作成できます。
以前の実施から学習結果を転送する
さらに、BigQuery で Vertex Vizier をバックグラウンドで使用したハイパーパラメータ調整には、こちらに記載されているように、トレーニングしたモデル間で学習結果を転送できるというメリットもあります。
モデルの調整に必要なトライアルの回数
原則として、ここに記載されているように、最低でもハイパーパラメータごとに 10 回のトライアルが必要です(並列トライアルを行わない場合)。たとえば、LINEAR_REG はデフォルトで 2 つのハイパーパラメータを調整するため、NUM_TRIALS=20 の使用をおすすめします。
料金
ハイパーパラメータ調整トレーニングの費用は、行ったトライアルすべての必要の合計です。すなわち、モデルを 20 回のトライアルでトレーニングしたなら、請求額は 20 回のトライアルすべての合計費用です。各トライアルの価格は、既存の BigQuery ML 価格モデルと同じです。
注: モデルを 1 つずつトレーニングする場合よりも費用がはるかに高くなる可能性が高いことに注意してください。
ハイパーパラメータ調整済みモデルの BigQuery ML からのエクスポート
ハイパーパラメータ調整済みのモデルを BigQuery の外で使用する場合、Google Cloud Storage にモデルをエクスポートしてから、オンライン予測用の Vertex AI エンドポイントのホストなどで使用できます。
まとめ
BigQuery ML のハイパーパラメータ自動調整機能を使用すれば、コードを 1 行(NUM_TRIALS)追加するだけで簡単にモデルのパフォーマンスを改善できます。ハイパーパラメータ調整についてさらに経験を積むことを希望される、またはご質問がある場合は、8 月 19 日に行われる Google の無料トレーニングにこちらからご登録ください。
-デベロッパー アドボケイト Polong Lin
-BigQuery ML ソフトウェア エンジニア Jiaxun Wu