Cloud Storage の階層名前空間を使用して AI / ML ワークロードを高速化
Subodh Bhargava
Senior Product Manager
Mohammed Abousaleh
Staff Software Engineer
※この投稿は米国時間 2025 年 3 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
AI と ML のワークロードが増大するにつれ、それらを支えるインフラストラクチャも、その固有のニーズを満たすために進化する必要があります。Google Cloud Storage チームは、Cloud Storage のパフォーマンス、スケーラビリティ、ユーザビリティを最適化するツールを AI / ML 実務担当者に提供できるよう取り組んでいます。この投稿では、Cloud Storage の新しい階層名前空間(HNS)機能が、AI / ML ワークロードのパフォーマンスと効率を最大限に高めるうえでどのように役立つのかを詳しく見ていきます。
AI / ML ワークロードにおけるストレージの役割
AI / ML データ パイプラインは通常、以下のステップで構成されます。これらのステップは、基盤となるストレージ システムに大きな負荷をかける可能性があります。
1. データの準備と前処理: データの検証、前処理、ストレージへの取り込み、モデルのトレーニングに適した形式への変換を行います。
2. モデルのトレーニング: 多くの GPU / TPU コンピューティング インスタンスを使用して、AI / ML モデルを反復的に開発し改良するプロセスです。
このプロセスには、チェックポインティングも含まれます。チェックポインティングは、モデルの状態を定期的に保存し、最初から再起動する代わりに最後に保存された状態から再開できるようにすることで、貴重な時間とリソースを節約します。これにより、大規模な分散トレーニングでよく発生する障害に対してフォールト トレランスが提供されます。また、それまでの進捗を失うことなくハイパーパラメータを試したり、トレーニングの目標を調整したりできます。
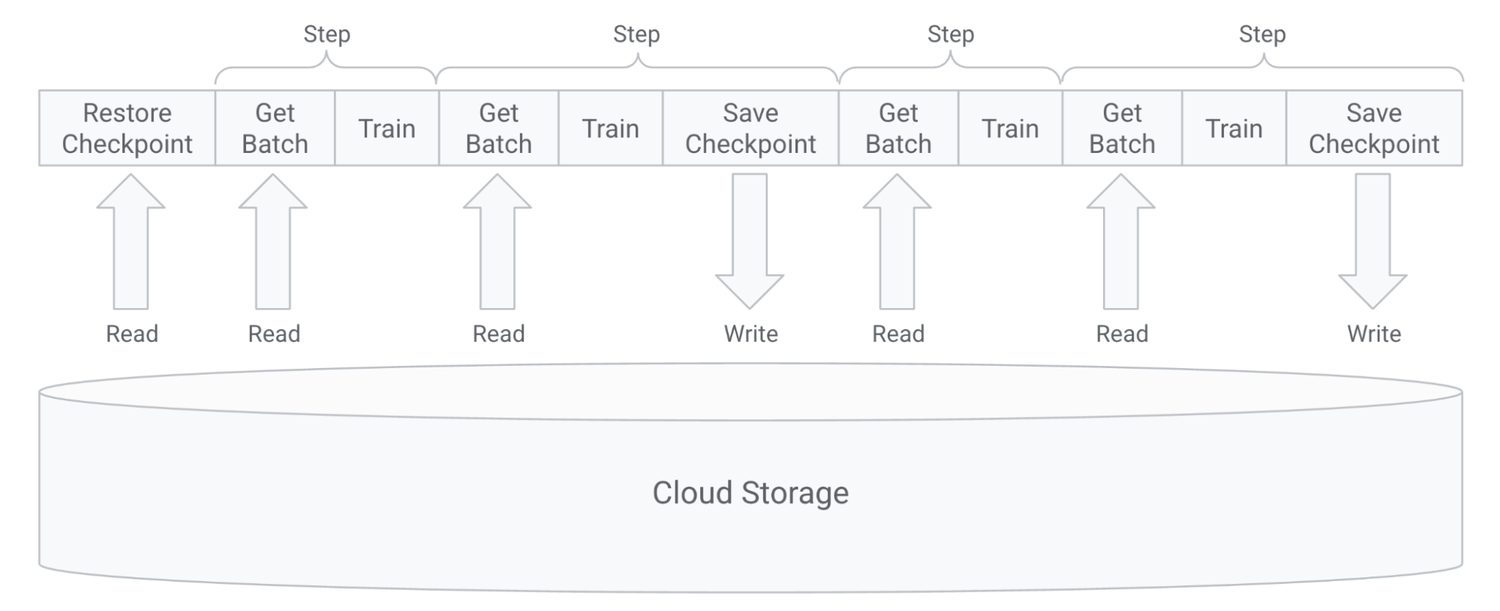
3. モデル提供: 通常は、モデルで推論を行うためにモデル、重み、データセットを GPU / TPU を備えたコンピューティング インスタンスに読み込みます。
AI / ML ワークロードは、ペタバイト規模のデータセットで同時 I/O を実行する、数千個のノードからなる大規模なコンピューティング クラスタで実行されることもあります。そのため、基盤となるストレージ システムが AI / ML パイプラインのボトルネックとなることがよくあり、その場合、高価な GPU / TPU サイクルが十分に活用されません。
AI / ML ワークロードに階層名前空間を使用するメリット
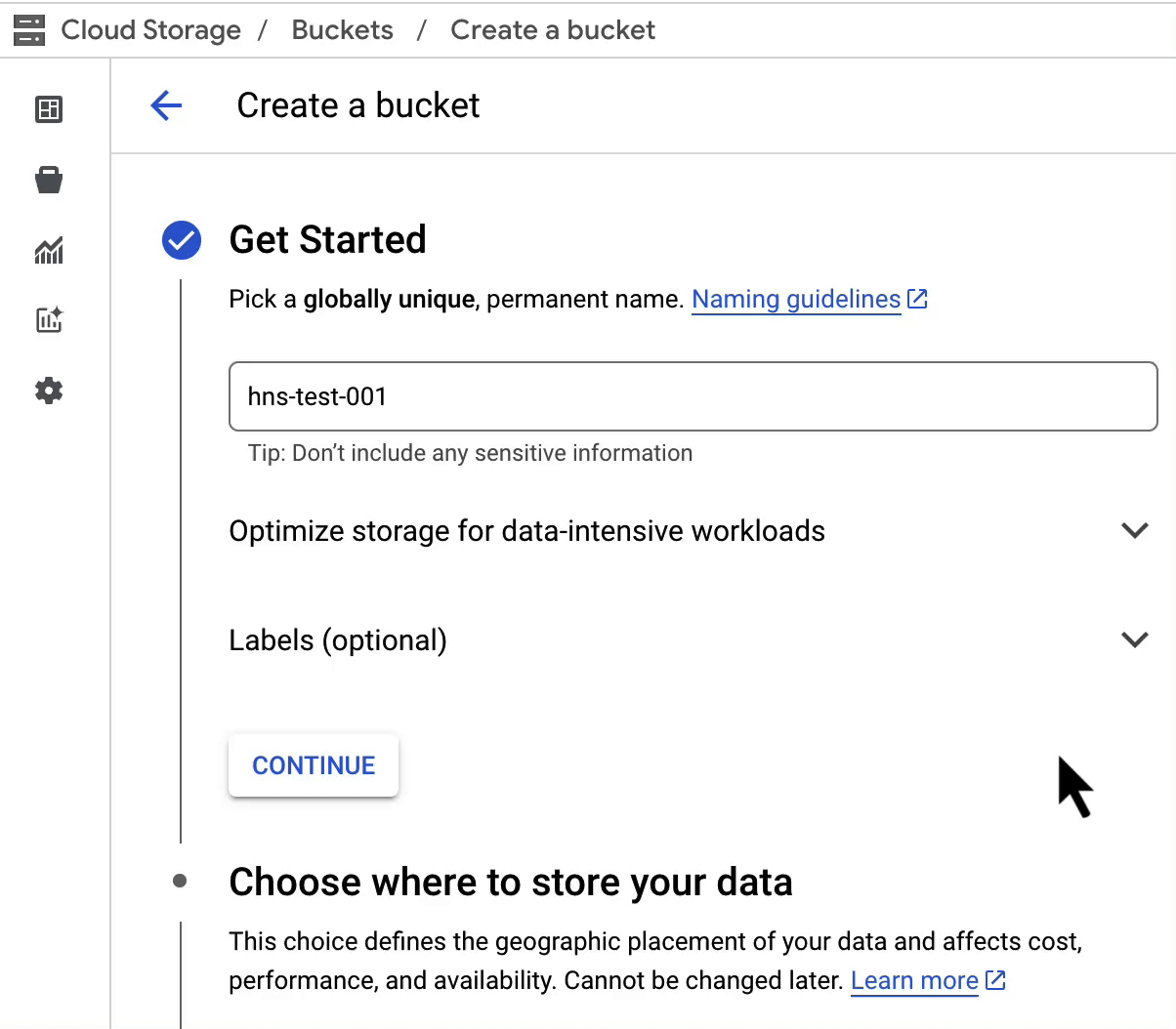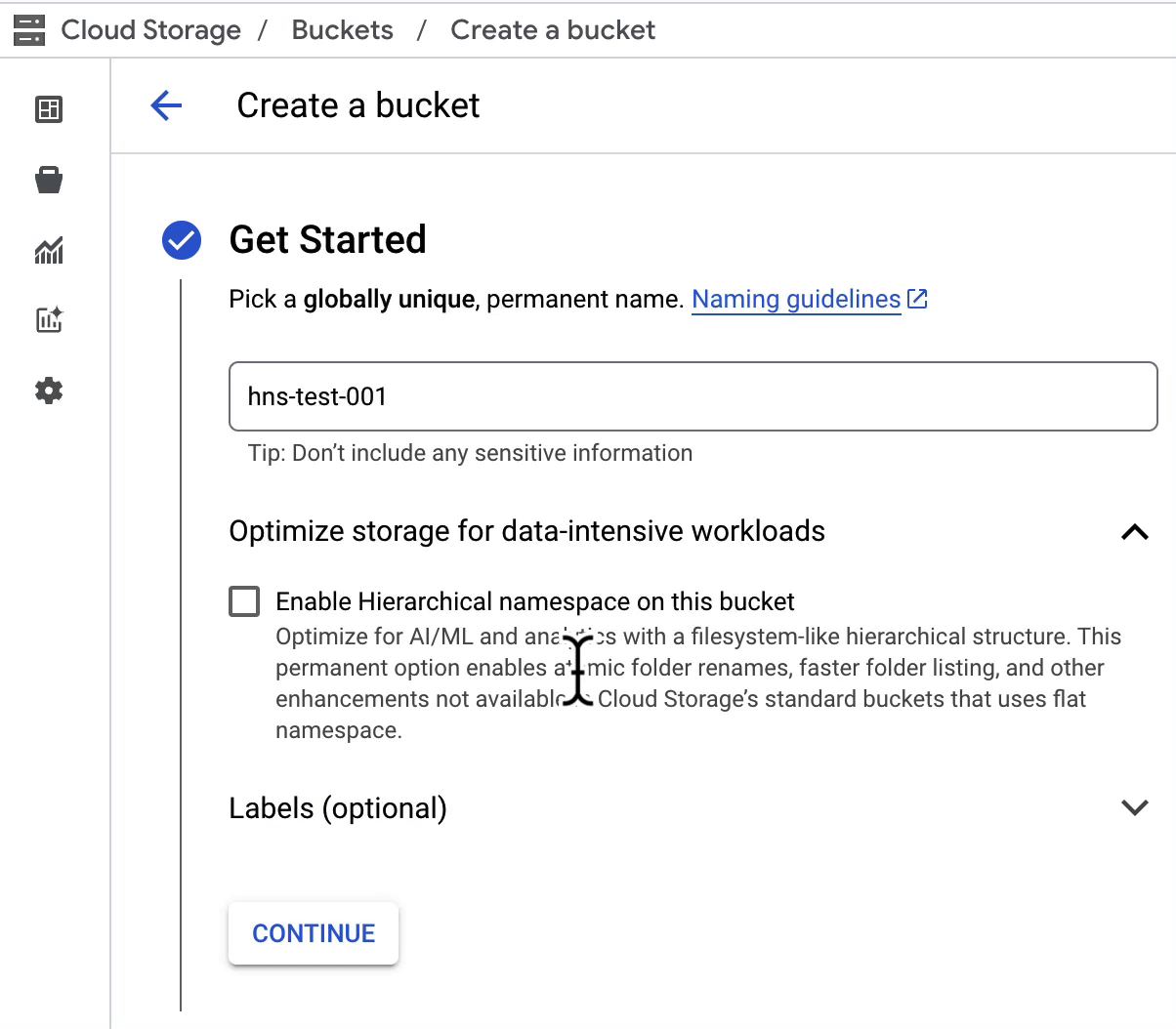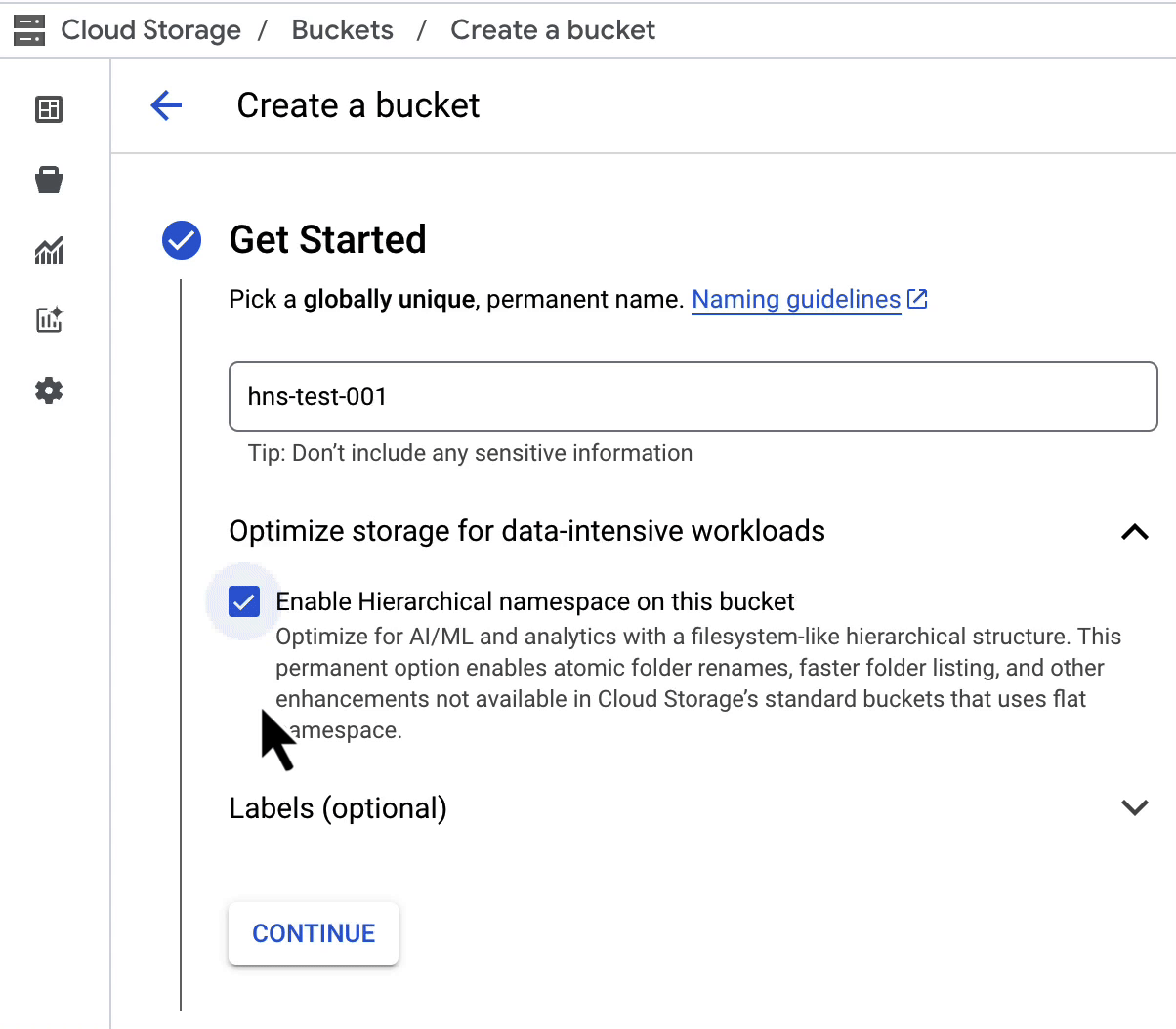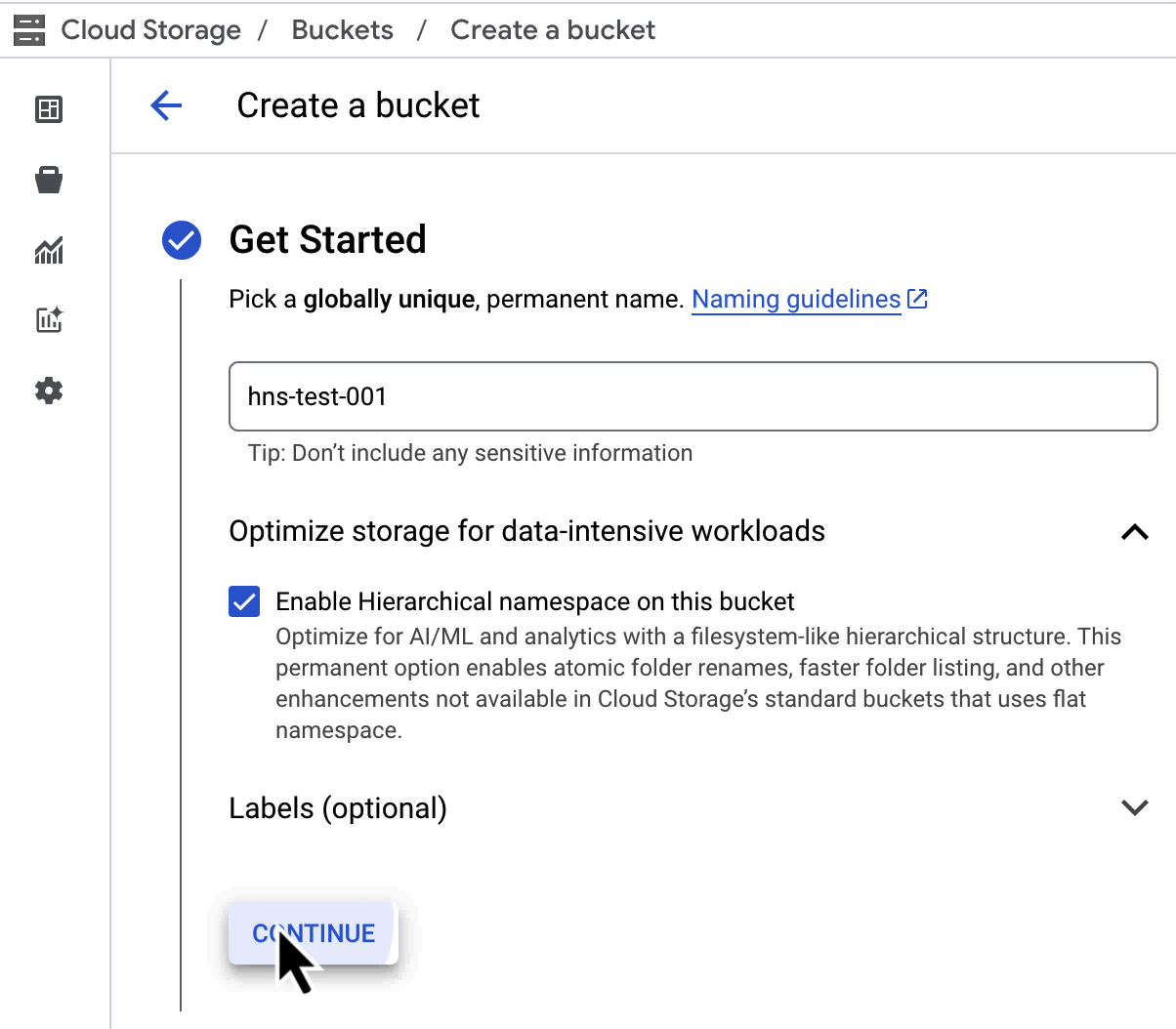
Cloud Storage の階層名前空間は、バケットを作成するときに有効にできます。有効にすると、AI / ML ワークロードに次のようなメリットをもたらします。
-
ファイル システムのセマンティクスに最適化された新しい「フォルダ」リソースタイプと API。
-
アトミックかつ高速なフォルダ名変更によるチェックポインティングの高速化と信頼性の向上。
-
最適化されたストレージ レイアウトによる秒間クエリ数(QPS)の高い読み取り / 書き込み処理。
それぞれのメリットについて詳しく見てみましょう。
ファイル システムのセマンティクスに最適化されたデータの編成とアクセス
階層名前空間バケットでは、フォルダにオブジェクトや他のフォルダを含めることができるため、従来フラットな Cloud Storage データを、従来のファイル システムを反映したツリー状の構造に整理できます。これにより、Cloud Storage FUSE などのクライアント ライブラリで、フォルダを直接操作する Cloud Storage API へのファイル システムの呼び出しをマッピングできるようになります。フラットな名前空間バケットでは多くの場合、ファイル システム操作をシミュレートするために、非効率で費用のかかるオブジェクト レベルの操作を実行する必要があります。階層名前空間を使用すると、基盤となるストレージ システムでネイティブに提供されるファイル システム セマンティクスを活用できます。たとえば、ファイル システム ライブラリは通常、リソースを大量に消費する ListObject 呼び出しを使用して、i ノード ルックアップを実装します。階層名前空間を使用すると、これらの呼び出しをより効率的な GetFolderMetadata 呼び出しに置き換えることができます。AI / ML ワークロードは、ファイル システム インターフェースを介してストレージとやり取りする TensorFlow や PyTorch などのフレームワークに依存することが多いため、これにより大きなメリットが得られます。
AssemblyAI をはじめとするお客様からは、AI / ML ワークロードに階層名前空間と Cloud Storage FUSE を使用することで、大幅な改善を実現できたとご報告いただいています。
「HNS と GCSfuse により、GCS のスループットが 10 倍以上増加し、トレーニング速度が 15 倍向上しました。」 – AssemblyAI、スタッフ ソフトウェア エンジニア Ahmed Etefy 氏
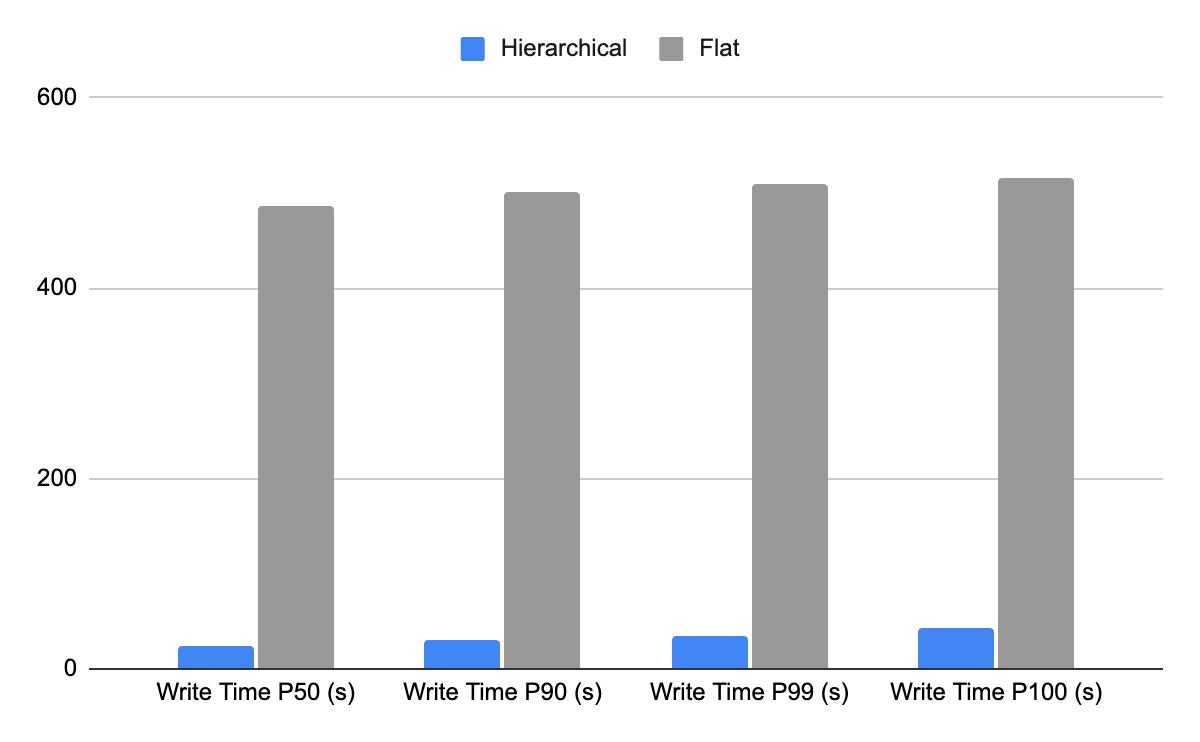
最大 20 倍高速なチェックポインティング
チェックポイントの書き込みや中間出力の管理では、フォルダやオブジェクトの名前が変更されることがよくあります。Cloud Storage の階層名前空間バケットには、高速かつアトミックな新しい RenameFolder API が導入されています。フラットな名前空間バケットでフォルダ名の変更をシミュレートすると、フォルダに含まれるオブジェクトの数によって、オブジェクトの書き換えと削除が数千回必要になることがありますが、階層名前空間サービスでは、フォルダレベルでメタデータのみを操作するだけよく、1 つのアトミック アクションで短時間に完了できます。フラット バケットでシミュレートされた名前変更では、部分的な障害によって不整合が生じることや、複雑な状態管理が必要となることがよくありますが、そのような問題をアトミック性により防ぐことができます。
フォルダ名の変更動作をチェックポイントのベンチマークで確認すると、階層名前空間バケットはフラット バケットと比較して、チェックポイントの書き込みを最大 20 倍高速化できることがわかります。
最大 8 倍の QPS
大規模なクラスタで実行される AI / ML ワークロードは、接続されたストレージ システムに数百万件の I/O リクエストを生成します。モデルのトレーニング中や推論のための読み取りサービング中のチェックポイントの書き込みと復元は、多くのノードが同時にストレージと同期通信する、非常にバースト性の高いワークロードです。高い QPS が可能であれば、ストレージのボトルネックにより高価な GPU / TPU を十分に活用できない状況を回避できます。
階層名前空間バケットではストレージ レイアウトが最適化されており、フラットな名前空間バケットと比較して、初期のオブジェクト読み取り / 書き込みの 1 秒あたりのリクエスト数(QPS)が最大 8 倍になるだけでなく、Cloud Storage のランプアップに関するガイドラインに従って QPS を 20 分ごとに 2 倍に増加する操作もサポートしています。たとえば、階層型名前空間のコールド バケットでは、フラット バケットと比較して、100,000 のオブジェクト書き込み QPS をほぼ半分の時間で達成できます。

まとめ
AI / ML ワークロードには、フレームワークとの緊密な統合のための効率的なデータ構成とファイル システム セマンティクス、GPU / TPU を最大限に活用する高パフォーマンス チェックポインティング、迅速なランプアップをサポートする高い QPS レートなど、独自のニーズに合ったインフラストラクチャが必要です。階層名前空間バケットはこのすべてのメリットを、Cloud Storage の特長であるスケーラビリティ、信頼性、シンプルさ、費用対効果に加えて提供します。AI / ML ワークロード用の新しいバケットでは、階層名前空間を有効にしてそのメリットをぜひ実感してください。
-シニア プロダクト マネージャー Subodh Bhargava
-スタッフ ソフトウェア エンジニア Mohammed Abousaleh

