クラウドでのネットワーク レイテンシの測定
Google Cloud Japan Team
※この投稿は米国時間 2020 年 6 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウド アーキテクトによく寄せられる質問の一つに、「2 つのエンドポイント間でリクエストとレスポンスをどの程度まで迅速に交換できるのですか?」というのがあります。ネットワークのラウンドトリップ レイテンシを測定するツールには ping、iperf、netperf などがありますが、すべてが同じように実装、構成されるわけではないため、ツールによって結果が異なる場合があります。ほとんどの場合、この質問に対する代表的な回答が得られるツールは、netperf であると考えられます。これからその詳細について説明していきます。
Google は、レイテンシ ベンチマークに関する実践的な経験を重ねてきました。このブログでは、Google とサザン メソジスト大学の AT&T Center for Virtualization の研究者が共同開発した手法を紹介します。この手法を利用することにより、ワークロードをクラウドに移行する前後に独自のレイテンシ ベンチマークを取得できます。また、ゾーン内クラスタ レイテンシとリージョン間レイテンシの両方のベンチマークについて、一貫性のある再現可能な実行結果を得るための、推奨コマンドもご紹介します。
最適なツールとその理由
この種のツールはどれも、ほぼ同じことを行います。つまり、トランザクションのラウンドトリップ時間(RTT)を測定します。ping は測定に ICMP パケットを使用し、nping、hping、TCPing などの ping をベースとするツールは TCP パケットを使用します。
たとえば、次のコマンドを実行すると、ping は、指定された IP アドレスに毎秒 1 つの ICMP パケットを送信し、送信したパケット数が 100 に達するまでそれを繰り返します。
netperf などのネットワーク テストツールでは、レイテンシ テストやスループット テストなどを実施できます。netperf で TCP_RR および UDP_RR(RR = リクエスト / レスポンス)テストを実施すると、ラウンドトリップ レイテンシが報告されます。-o フラグを指定すると、出力指標をカスタマイズして、関心のある情報のみを表示できます。以下はテスト用 -o フラグの使用例です。これにより、レイテンシ統計が出力されます。
*注: この例ではグローバル オプションを指定しています。-H はリモートホスト、-t はテスト名、テスト用の -o オプションは出力セレクタです。指定例については、こちらをご覧ください。
以前のブログ投稿で説明したように、Google では、クラウド環境のレイテンシ テストを実施する際、PerfKit Benchmarker(PKB)ツールを使用します。このオープンソース ツールを使用すると、さまざまなクラウド プロバイダでベンチマークを実行しながら、それらのベンチマークに必要な仮想インフラストラクチャを自動的に設定、破棄することができます。
PerfKit Benchmarker を設定したら、以下のコマンドで、最も単純な ping レイテンシ ベンチマークまたは netperf TCP_RR レイテンシ ベンチマークを実行できます。
これらのコマンドは、単一リージョン内の単一のゾーンにある 2 台のマシン間でゾーン内レイテンシ ベンチマークを実行します。このようなゾーン内ベンチマークを使用することで、緊密に連携するマシン間の非常に低いレイテンシをマイクロ秒単位で示すことができます。これらのコマンドを実行する際に私たちがよく使用しているオプションと方法については、このブログ投稿で後述します。
レイテンシの不一致
PerfKit Benchmarker が ping および netperf を実行したときにどのような処理が行われるかを詳しく見ていきましょう。また、そのようなテストを実行すると何が発生するかについても説明します。
次の例では、ゾーン us-east1-c で Ubuntu 18.04 を実行する 2 台の c2-standard-16 マシンをセットアップし、内部 IP アドレスを使用して最良の結果を取得します。
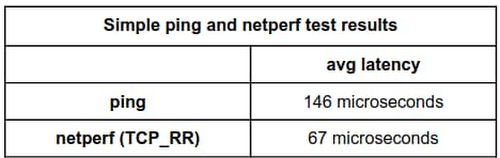
ping テストをデフォルト設定で実施し、パケット数を 100 に設定すると、以下の結果が得られます。
デフォルトでは、ping は毎秒 1 つのリクエストを送信します。サマリーで、100 パケット送信後に平均レイテンシが 0.146 ミリ秒、つまり 146 マイクロ秒になると報告されています。
これと比較できるよう、パケットが同量となるよう netperf TCP_RR をデフォルト設定で実行してみましょう。
ここでは、平均レイテンシが 66.59 マイクロ秒と報告されています。ping で報告された平均レイテンシと netperf で報告された平均レイテンシには、約 80 マイクロ秒の誤差があります。ping で報告された値は netperf で報告された値の 2 倍以上の大きさです。どちらのテストを信用すればいいのでしょうか。
これは主に、デフォルトで使用される間隔が 2 つのツールで異なることが原因です。ping では 1 秒あたり 1 トランザクションの間隔が使用されますが、netperf ではトランザクションが完了するとすぐに次のトランザクションが発行されます。
幸いなことに、どちらのツールでもトランザクション間の間隔を手動で設定できるため、間隔が一致するよう調整して結果を確認することができます。
ping の場合は、-i フラグで秒単位または小数秒単位の間隔を設定します。Linux システムでは、粒度は 1 ミリ秒であるため、ミリ秒単位に切り捨てられます。たとえば、0.00299 秒の間隔を指定すると、0.002 秒、つまり 2 ミリ秒に切り捨てられます。1 ミリ秒未満の間隔をリクエストすると、ping によって 0 に切り捨てられ、リクエストが可能な限り早く送信されます。
10 ミリ秒の間隔を指定して ping を開始するには、次のようにします。
netperf TCP_RR の場合、高い粒度で間隔を指定するためのオプションを有効にするには、--enable-spin フラグを指定してコンパイルします。さらに、間隔を設定する -w フラグと、1 間隔ごとに送信されるトランザクション数を設定する -b フラグを指定します。この方法では、タイマーを待機するのではなく、次の間隔までタイトなループで CPU を回転させるため、より詳細に間隔を設定でき、CPU は 100% 動作したままになります。もちろん、この精度では CPU が待機中に回転するため、CPU 使用率が大幅に高くなります。
*注: より低い粒度で間隔を設定するには、--enable-intervals フラグを指定してコンパイルします。-w オプションおよび -b オプションを使用するには、--enable-intervals フラグまたは --enable-spin フラグを設定して netperf をビルドする必要があります。
以下のテストでは、--enable-spin フラグを設定しています。10 ミリ秒の間隔を指定して netperf を開始するには、次のようにします。
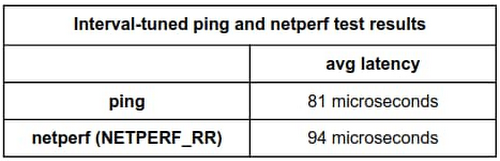
ここで、ping と netperf の両方の間隔を 10 ミリ秒に調整すると、効果が明らかとなります。
ping:
netperf:
各間隔を 10 ミリ秒に設定したところ、ping のテストでは平均レイテンシが 81 マイクロ秒、netperf のテストでは平均レイテンシが 94.01 マイクロ秒と報告されました。間隔を調整する前より、誤差がかなり小さくなりました。
この効果を明確化するには、より多くのテストを実施します。つまり、1 マイクロ秒から約 1 秒までの範囲のさまざまな間隔を設定して、ping と netperf TCP_RR を実行し、結果をプロットします。
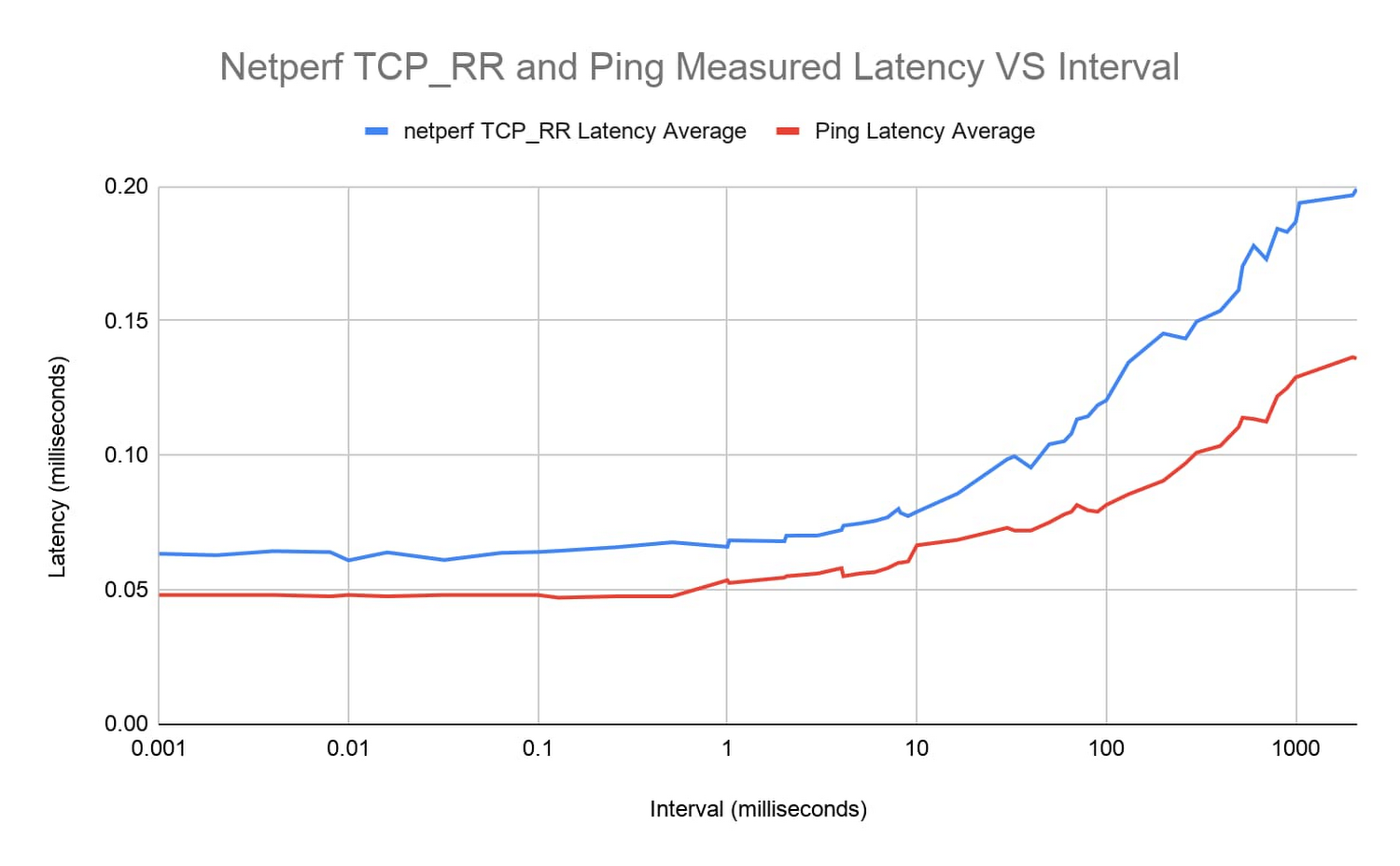
両方のツールのレイテンシ曲線は非常に近似しています。間隔が約 1 ミリ秒未満の場合、ラウンドトリップ レイテンシは 0.05~0.06 ミリ秒程度と、比較的一定になります。そこから、レイテンシは着実に増加していきます。
要点
それでは、ping と netperf のどちらのツールのレイテンシ測定値がより代表的なものなのでしょうか。また、このレイテンシの不一致は実際にはどのようなときに問題化するのでしょうか。
一般的に、レイテンシ テストには ping ではなく netperf を使用することをおすすめします。ただしこれは、デフォルト設定で報告されるレイテンシが低いからというわけではありません。netperf を使用すると、その多彩なオプションから柔軟性が高まります。おすすめは TCP over ICMP です。TCP はより一般的なユースケースであるため、実際のアプリケーションをより効果的に表す傾向があります。ただし、これらのツールを使用して同様に構成された実行の結果における相違は、パス長が長いほど少なくなります。
また、レイテンシ テストを実施する際に忘れてはならないのは、間隔やその他のツールの設定を記録、報告することです。特にレイテンシが低い場合は、間隔が大きな違いをもたらすからです。
一貫性のある再現可能な結果をもたらす、推奨されるベンチマーク テストを実施するには、以下を試してください。
ゾーン内クラスタ レイテンシ ベンチマークの場合:
このベンチマークでは、インスタンス配置ポリシーを使用します。これは、相互に近接しているマシンからメリットを享受できるワークロードの場合に推奨されます。
リージョン間レイテンシ ベンチマークの場合:
netperf TCP_RR ベンチマークでは、間隔が追加で設定されていないことに注目してください。これは、netperf がデフォルトでは、リクエスト / レスポンス トランザクション間に追加の間隔を挿入しないためです。これにより、より正確で一貫性のある結果が得られます。
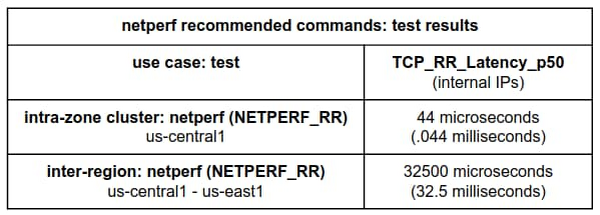
注: この netperf のゾーン内クラスタ レイテンシの結果には 2 つのメリットがあります。1 つはテストで間隔の追加を制御できること、もう 1 つは配置グループを使用できることです。
次のステップ
ネットワーク パフォーマンス ベンチマークに関する次の投稿では、新たに一般公開された Google Cloud グローバル レイテンシ ダッシュボードの使い方を詳しく説明します。これにより、クラウドへの移行がワークロードにどのように影響するかを深く理解できます。
また、ネットワーク ベンチマーク テストを実施するための詳細な手順については、PerfKit Benchmarker ホワイト ペーパーと PerfKit Benchmarker チュートリアルをご覧ください。
この投稿に協力してくれた Google Cloud ラーニング担当テクニカル カリキュラム リードの Mike Truty に感謝します。
- サザン メソジスト大学コンピュータ サイエンス博士課程学生 Derek Phanekhamm
Google Cloud ネットワーク パフォーマンス担当ソフトウェア エンジニア Rick Jones
