生成 AI アプリケーション向け Google Cloud ネットワーキングの機能強化のご紹介
Anna Berenberg
Engineering Fellow
Muninder Sambi
VP, PM and GM, Networking, Google Cloud
※この投稿は米国時間 2024 年 6 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの企業では、生成 AI をビジネスに導入してそのメリットを活用する方法を模索しています。2023 年の Gartner® のレポート『We Shape AI, AI Shapes Us: 2023 IT Symposium/Xpo Keynote Insights(2023 年 10 月 16 日)』では、「ほとんどの組織が生産性向上のために AI を日常的に使用しているか、その使用を検討している。2024 年の『Gartner CIO and Technology Executive Survey』では、回答者のうち 80% が 3 年以内に生成 AI を導入する計画である」と回答しています1。
大規模言語モデル(LLM)の導入を検討している企業は、従来のウェブ アプリケーションとは異なる LLM 特有のネットワーキング面の課題に直面します。これは、生成 AI アプリケーションが大半の従来のウェブ アプリケーションとは大きく異なる動作を示すためです。
たとえば、ウェブ アプリケーションのトラフィック パターンは通常は予測可能で、リクエストとレスポンスは一般的にはミリ秒単位という比較的短い時間で処理されます。これに対し、生成 AI による推論アプリケーションの場合はマルチモーダルという性質のためにリクエスト / レスポンスの時間が変動し、特有の困難を生じることがあります。これに加え、一般的なリクエストは並列処理が行われることに対して LLM のクエリは GPU や TPU のコンピューティング時間を 100% 使用することもしばしばあります。このようなコンピューティング上のコストにより、推論のレイテンシは数秒から数分にわたります。
結果として、使用量に応じてトラフィックを管理する従来のラウンドロビン法は、概して生成 AI アプリケーションには適さないことになります。Google は最近、生成 AI アプリケーションを使用するエンドユーザーにとっての最良のエクスペリエンスと有限で高価な GPU や TPU のリソースの効率的な使用を実現するため、AI アプリケーションのトラフィックを最適化する新しいネットワーキング機能を複数発表しました。
これらのイノベーションの多くは Vertex AI に組み込まれています。現在は Google Cloud ネットワーキングで利用可能になり、ご利用の LLM プラットフォームを問わずお使いいただけるようになりました。
それでは詳しく見ていきましょう。
1. クロスクラウド ネットワークで AI のトレーニングと推論を加速
IDC レポートによれば、66% の企業が生成 AI および AI / ML のワークロードをマルチクラウド ネットワーキングのユースケースの上位に挙げています2。これは、モデルのトレーニングやファインチューニング、検索拡張生成(RAG)、グラウンディングに必要なデータが多数の環境に別々に置かれているためです。LLM モデルがアクセスするために、これらのデータへの遠隔アクセスまたは遠隔コピーが必要です。
Google は昨年、クロスクラウド ネットワークを導入しました。これは Google のグローバル ネットワーク上に構築されており、サービスを中心としてあらゆる環境同士を接続するものです。これにより、複数のクラウドに分散したアプリケーション同士を組み立てて構築することが可能になりました。
クロスクラウド ネットワークに含まれるプロダクトは信頼性と安全性、SLA で保証されたクラウド間の接続性を備え、クラウド間の高速データ転送を支援します。これにより生成 AI モデルのトレーニングに欠かせない大規模なデータ転送がスムーズになります。このソリューションのプロダクトには、10 Gbps または 100 Gbps の帯域幅、99.99% の SLA 保証、エンドツーエンドの暗号化を備え、管理された相互接続を提供する Cross-Cloud Interconnect などがあります。
AI トレーニングのための信頼性と安全性のあるデータ転送に加え、クロスクラウドネットワークによりお客様は AI モデルによる推論アプリケーションをハイブリッド環境全体で実行できるようになります。たとえば、他のクラウド環境で実行されるアプリケーション サービスから Google Cloud 上で実行されるモデルへのアクセスも可能です。
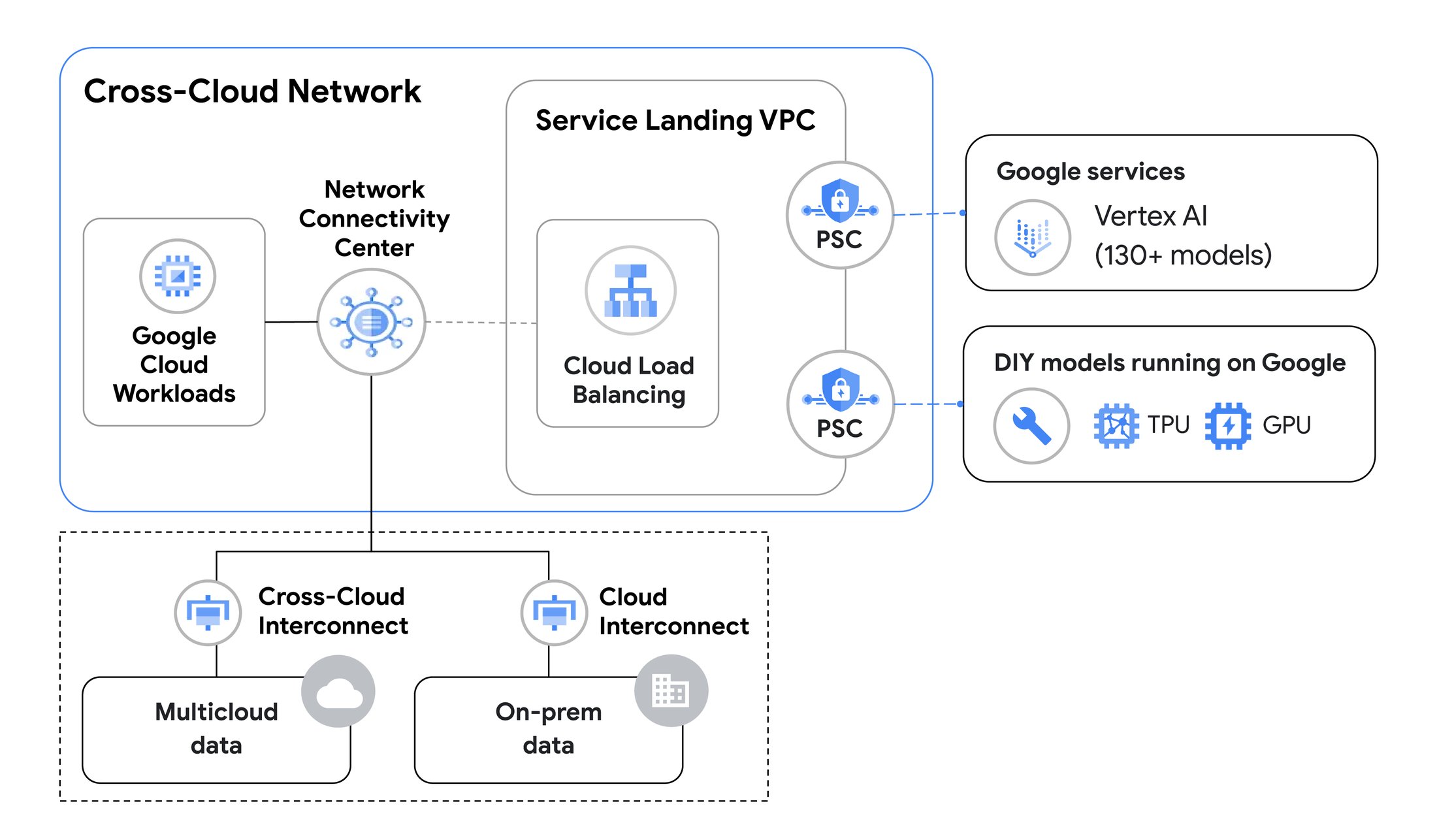
生成 AI のトレーニングのためのクロスクラウド ネットワーキング
2. Model as a Service Endpoint: AI アプリケーション向けに構築されたソリューション
Model as a Service Endpoint は、AI による推論アプリケーション特有の要件に適合したソリューションです。生成 AI が持つ特殊な性質により、多くの組織ではモデルの作成者がモデルをサービスとして提示し、これをアプリケーション開発チームが使用しています。Model as a Service Endpoint はこうしたユースケースのサポートに特化したものです。
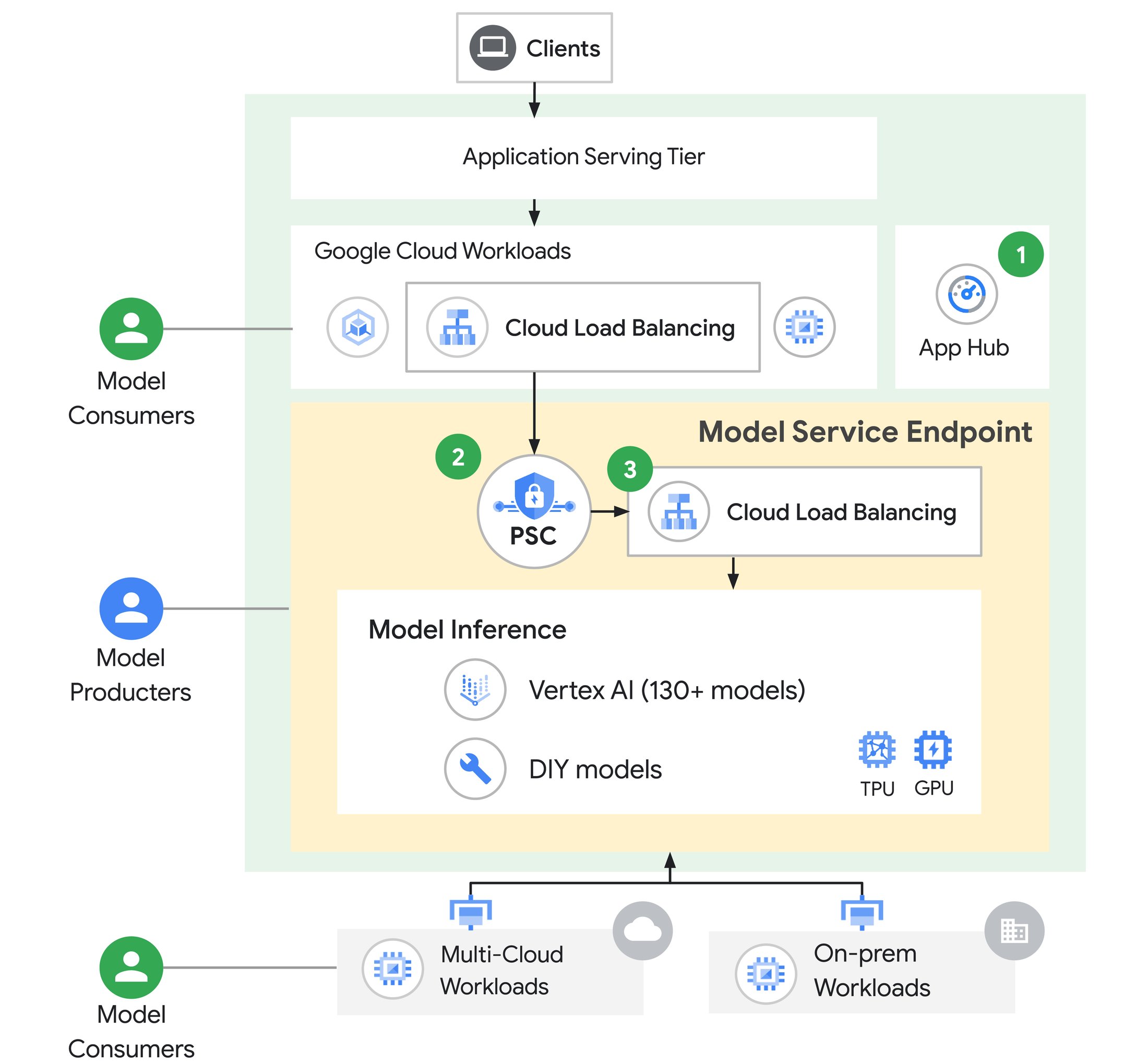
Model as a Service Endpoint
Model as a Service Endpoint はアーキテクチャにおけるベスト プラクティスで、以下の 3 つの主要なクラウド コンポーネントから構成されます。
-
App Hub は最近、一般提供が開始されました。App Hub はお客様のクラウド プロジェクト全体でアプリケーション、サービス、ワークロードを追跡するための一元的な場所です。お客様の AI アプリケーションやモデルなどのサービスの記録を維持し、見つけやすく、再利用しやすくします。
-
Private Service Connect(PSC)は、AI モデルへの安全な接続性を確保します。これによりモデル プロデューサーは PSC サービス アタッチメントを定義でき、モデル利用者はこの PSC サービス アタッチメントへ接続することで推論用の生成 AI モデルへアクセスできます。モデル プロデューサーはその生成 AI モデルにアクセスできるユーザーについてのポリシーを定義します。また、PSC は利用者のアプリケーションとプロデューサー モデルとの間のネットワークを超えたアクセスを簡素化します。Google Cloud の外部に位置する利用者もこの対象に含まれます。
-
Cloud Load Balancing には、LLM へのトラフィックのルーティングを効率化するためのイノベーションが複数含まれます。たとえば Cloud Load Balancing の新しい AI 対応の機能は、お客様のモデルへのトラフィック分散を最適化します。これらの機能はモデル プロデューサーも AI アプリケーション開発者も使用できます。詳しくはこのブログ投稿の後半で述べます。
3. カスタムの AI 対応ロード バランシングにより推論のレイテンシを最小化
多くの LLM アプリケーションは、独自のプラットフォーム専用のキューを使用してユーザーのプロンプトを受け取り、処理します。エンドユーザーへのレスポンス時間を一定にするためには、LLM アプリケーションで未処理のプロンプトのキューの深さを可能な限り短くする必要があります。これを実現するためにはリクエストがキューの深さに応じて複数の LLM モデルに分散される必要があります。
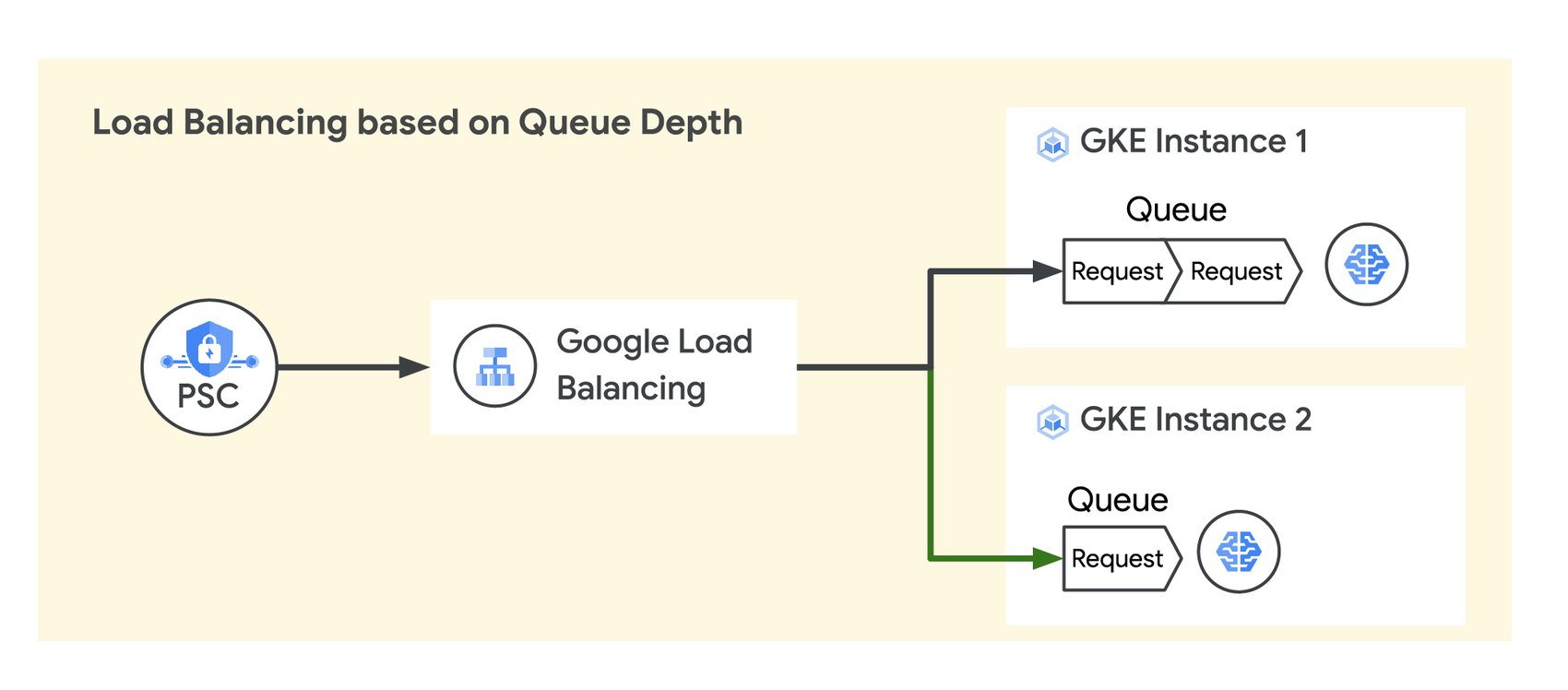
キューの深さに応じたトラフィックの使用量
トラフィックを LLM 特有の指標(キューの深さなど)に応じてバックエンドのモデルに分散させるために、Cloud Load Balancing ではカスタムの指標に応じたトラフィック分散ができるようになりました。この機能では、Open Request Cost Aggregation(ORCA)標準を使用したレスポンス ヘッダー内でアプリケーションレベルのカスタム指標が Cloud Load Balancing にレポートされます。これらの指標によりトラフィックのルーティングやバックエンドのスケーリングが変化します。生成 AI アプリケーションではキューの深さをカスタム指標として設定でき、キューの深さが可能な限り浅く保たれるようにトラフィックは自動的に均等に分散されます。この結果、推論処理時の平均レイテンシやピーク レイテンシを低くできます。実際に、こちらのデモンストレーションで例示するように、LLM のキューの深さを主要な指標としてトラフィックを分散させることですべての AI アプリケーションにおいてレイテンシが 5~10 倍改善されました。Google は今年の後半に、カスタム指標に基づくトラフィック分散機能を Cloud Load Balancing に追加する予定です。
4. AI 推論アプリケーション用に最適化されたトラフィック分散
Google Cloud ネットワーキングには、生成 AI アプリケーションの信頼性、有効性、効率性を向上させるための組み込みの機能が数多くあります。ひとつずつ見ていきましょう。
推論の信頼性向上へ。
処理スタックのいずれかのポイントで発生した問題が原因でモデルが利用できない状態があれば、ユーザー エクスペリエンスが損なわれることになります。ユーザーの LLM プロンプトを確実に処理できるようにするためには、トラフィックはアクティブな状態で実行中の正常なモデルへと送られなければなりません。以下に示すように、Goggle Cloud ネットワーキングには、これをサポートするための複数のソリューションがあります。
-
クラウド ヘルスチェックを備えた内部アプリケーション ロードバランサ: モデル プロデューサーにとっては、モデルサービスのエンドポイントが高可用性を維持することが重要です。個々のモデル インスタンスへアクセスが可能でクラウド ヘルスチェックを備えた内部アプリケーション ロードバランサを追加すれば、これが実現できます。モデルのヘルスチェックは自動的にモニタリングされ、リクエストは正常なモデルにのみルーティングされます。
-
ヘルスチェックを備えたグローバル ロード バランシング: モデル利用者にとっては、レイテンシを最適化するために、クライアント リクエストに近接し利用可能な実行中のモデルサービスのエンドポイントへアクセスできることが重要です。多くの LLM スタックは個々の Google Cloud リージョン内で実行されています。ヘルスチェックを備えたグローバル ロード バランシングを使用して個々のモデルサービスのエンドポイントへアクセスすることで、リクエストが正常なリージョンにあるモデルサービスのエンドポイントに確実にルーティングされるようにできます。これによりトラフィックは、正常なリージョン内で実行中で利用可能なモデルサービスのエンドポイントの中から最も近接したものへとルーティングされます。この手法は、マルチクラウドまたはオンプレミスのデプロイ向けに Google Cloud の外部で実行されるクライアントやエンドポイントにも拡張して機能させることができます。
-
Google Cloud Load Balancing の重み付けによるトラフィック分割: モデルの効率性向上を目的として、Google Cloud Load Balancing の重み付けによるトラフィック分割によりトラフィックのポーションを異なるモデルや異なるモデル バージョンへと転送できます。この手法により、A/B テストによってさまざまなモデルの有効性をテストしたり、Blue/Green デプロイによる段階的な展開で新しいモデル バージョンが正しく機能しているかを確認したりできます。
-
Load Balancing for Streaming: 生成 AI のリクエストの処理に要する時間は大幅に変動することがあり、時には実行に数秒あるいは数分かかる場合もあります。これは特にリクエストに画像が含まれている場合に顕著です。長時間(10 秒を超えるもの)のリクエストに対して最良のユーザー エクスペリエンスを確保し、バックエンドのリソースを最も効率的に使用するために、バックエンドが処理できるリクエスト数に応じたトラフィック分散をおすすめします。この新しい Load Balancing for Streaming は長時間リクエストのトラフィックを最適化することに特化して設計されており、個々のバックエンドが処理できるストリームの数に応じてトラフィックを分散します。Load Balancing for Streaming は、今年の後半に Cloud Load Balancing で利用可能になる予定です。
5. Service Extensions で生成 AI のさらなる活用へ
最後にご紹介するのは、Google Cloud アプリケーション ロードバランサ向けの Service Extensions callouts が一般提供になったこと、そして今年の後半には Cloud Service Mesh で利用可能になる予定であることです。Service Extensions により、データパスにおける SaaS ソリューションのインテグレーションやプログラムを使用したカスタマイズが可能になります。たとえば、カスタムのロギングやヘッダーの変更などを行えます。
Service Extensions は生成 AI アプリケーションと組み合わせて複数の方法で使用することができ、ユーザー エクスペリエンスを向上させます。たとえば Service Extensions にプロンプト ブロッキングを実装し、不要なプロンプトがバックエンドのモデルに到達しないようにすることで、限られた GPU や TPU の処理時間が消費されることを防げます。また、Service Extensions を使用してプロンプトへのレスポンスに最適なモデルを決定し、リクエストを特定のバックエンド モデルにルーティングすることもできます。これを実現するために、Service Extensions はリクエスト ヘッダーの情報を分析し、リクエストを処理するのに最適なモデルを決定します。
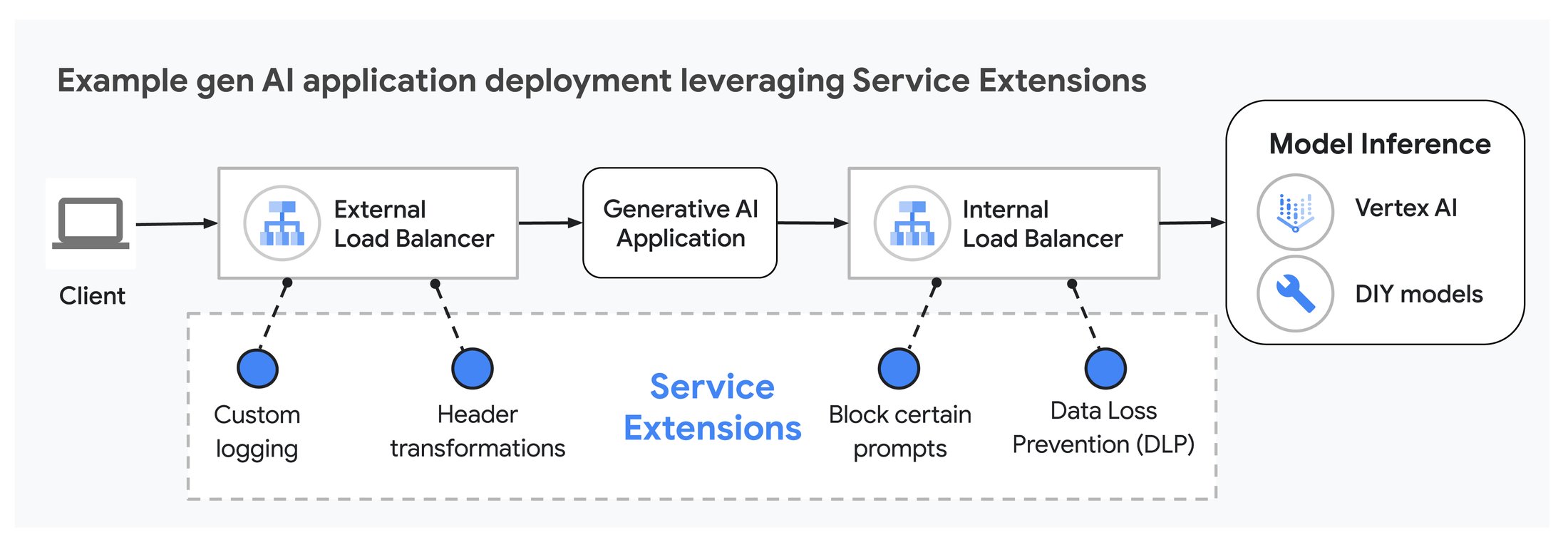
Service Extensions により AI アプリケーションのデータパスがプログラム可能に
Service Extensions コールアウトはカスタマイズ可能なため、お客様の生成 AI アプリケーションに固有のニーズに合わせてプログラムできます。Cloud Load Balancing 向けの Service Extensions コールアウトについて詳しくは、Google によるこちらの公式ドキュメントをご覧ください。
「Google Cloud と当社のカスタム ソフトウェアを組み合わせて使用することで、当社のプラットフォームのインフラストラクチャは低レイテンシと高い信頼性を実現しました。これにより、当社のユーザーへ優れたパフォーマンスとスケーリングを提供できています。当社は、ソフトウェアのインテグレーションとスケーリングを支援し、将来のデータプレーンのカスタマイズを可能にして、開発者が AI 搭載アプリケーションをデプロイできるようにしてくれる Service Extensions コールアウトを大変気に入っています」- Replit、インフラストラクチャ責任者、Scott Kennedy 氏。
Google Cloud ネットワーキングで生成 AI の可能性を引き出しましょう
このブログ投稿ではさまざまなイノベーションの概要を述べてきました。これらのイノベーションは、Google が最先端のソリューションを提供し、AI の可能性をビジネスに最大限に活かすための支援に取り組んでいることを示すものです。Google Cloud の高度なネットワーキング機能のスイートの活用で、Google はお客様の AI アプリケーションにおける独自の課題の解決をお手伝いします。
1. We Shape AI, AI Shapes Us: 2023 IT Symposium/Xpo Keynote Insights(2023 年 10 月 16 日)。Gartner は、Gartner, Inc. またはその関係会社の米国およびその他の国における登録商標およびサービスマークであり、同社の許可を得て使用されているものです。権利はすべて同社に帰属します。
2 IDC, Multicloud Networking Starting to Inflect - Top Use Cases Include application and Business Resiliency, Improved Cybersecurity Posture, and Global-Scale Delivery of Internet-Facing Applications、文書番号: US51795623、2024 年 1 月
ー エンジニアリング フェロー Anna Berenberg
ー クラウド ネットワーキング担当バイス プレジデント Muninder Sambi


