インテルの AI 対応 AMX CPU アクセラレータのテスト結果について
Erdem Aktas
Staff Software Engineer
Zhimin Yao
Staff Software Engineer
※この投稿は米国時間 2024 年 10 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud は、クラウド コンピューティングの暗号化されたプライベートなサービスへの移行がさらに進んでいくと考えています。それは、ソフトウェアとデータが権限のないアクターに公開されることはないとユーザーが確信できるサービスです。この目標を達成するために、ユーザビリティ、パフォーマンス、規模を犠牲にすることなく、Confidential Computing テクノロジーを Google のクラウド全体に浸透させることを目指しています。
インテルと共同で開発した最新の C3 Confidential VMs には、デフォルトで有効になるアクセラレータ、インテル AMX が組み込まれています。CPU でのディープ ラーニングのトレーニングと推論のパフォーマンスを改善する Intel AMX は、自然言語処理、レコメンデーション システム、画像認識などのワークロードに理想的です。
これらの Confidential VMs に採用されている Confidential Computing テクノロジーは、インテル Trust Domain Extensions(インテル TDX)と呼ばれるものです。Confidential VMs とインテル TDX を組み合わせることで、インサイダー攻撃とソフトウェアの脆弱性からの保護を実現し、データとコードの機密性と完全性を確保できます。インテルの AMX と TDX という 2 つのテクノロジーにより、AI 推論、ファイン チューニング、小規模から中規模のトレーニング ジョブのセキュリティを簡単に確保できます。
「Google との連携によって、インテル TDX とインテル AMX を搭載した C3 インスタンスで Confidential Computing と AI アクセラレーションを実現できることを喜ばしく思っています。また、人気の高い AI ライブラリでのソフトウェア アクセラレーションも可能になります。今後は、安全な高速コンピューティングに誰もがアクセスできるようになるでしょう」と話すのは、インテル フェロー兼データセンター AI アーキテクトの Andres Rodriguez 氏です。
Confidential VMs での AI / ML ワークロードのパフォーマンス テスト
セキュリティ拡張機能を有効にすると、パフォーマンスに関する懸念が生じることがあります。このため、ML トレーニングおよび推論のテストを実施し、インテル TDX とインテル AMX を搭載した Confidential VMs のパフォーマンスを評価することにしました。
今回のテストでは、利用可能な vCPU の中で最大規模のマシンタイプである 3 種類の VM を比較しました。
-
N2 VM: N2 マシンシリーズ。インテル AMX もインテル TDX も有効になっていない VM。
-
C3 VM: C3 マシンシリーズ。インテル AMX のみが有効になっている VM。
-
C3+TDX VM: C3 マシンシリーズ。インテル TDX とインテル AMX の両方が有効になっている VM。
AI トレーニングの結果
前述した VM(N2、C3、C3+TDX)でのトレーニング時間(分単位)を比較しました。N2 VM と比較して、C3 VM のトレーニング時間は 4.54 倍高速で、C3+TDX VM のトレーニング時間は 4.14 倍高速でした。対象のワークロードは 1 つで、グローバル バッチサイズなどのハイパーパラメータと品質基準は同一としました。
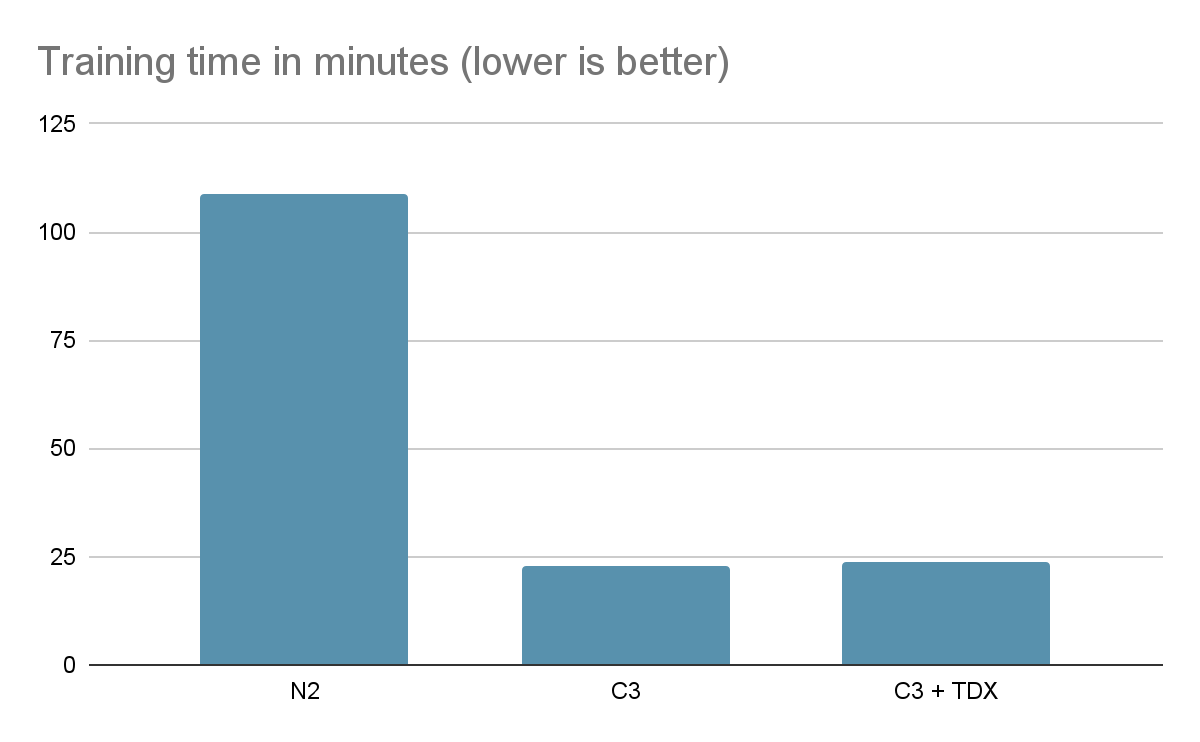
仮想マシン別のトレーニング時間。
インテル TDX を搭載した Confidential VMs で実行されるワークロードの場合、多少のパフォーマンスのオーバーヘッドが発生する可能性があることがわかりました。バッチサイズを増やすと、トレーニングが高速になり、インテル TDX のオーバーヘッドが減少する可能性があります。これは、取り込むデータの量が同じ場合、I/O オペレーションに関連するメモリ暗号化コストが少なくなるためです。
AI 推論の結果
インテル AMX を使用する VM の場合、推論のワークロードでも同様の改善が見られました。また、インテル TDX による多少のパフォーマンスのオーバーヘッドが観測されました。
2 つの LLM(Llama-2-7B と Llama-2-13B)で、テキスト生成タスクを実行しました。前述した VM(N2、C3、C3+TDX)を使用して、次の 2 つの指標に基づくタスクのパフォーマンスを評価しました。
-
Time Per Output Token(TPOT): 単一のリクエストに対して出力トークンを生成するまでにかかる時間。この指標は、ユーザーがモデルの「速度」をどう感じるかを示します。たとえば、TPOT が 100 ミリ秒/トークンの場合、約 450 ワード/分(WPM)となります。これは、人間の平均的な読み取り速度よりも高速です。
-
スループット(トークン/秒): バッチ リクエストに対して推論サーバーが生成できる 1 秒あたりの出力トークンの数。
N2 VM と C3 VM / C3+TDX VM を比較したところ、インテル AMX を搭載した C3 VM と C3+TDX VM の方が、レイテンシが約 3 倍高速になり(TPOT、バッチサイズ 1)、スループットが約 7 倍増加しました(バッチサイズ 6)。
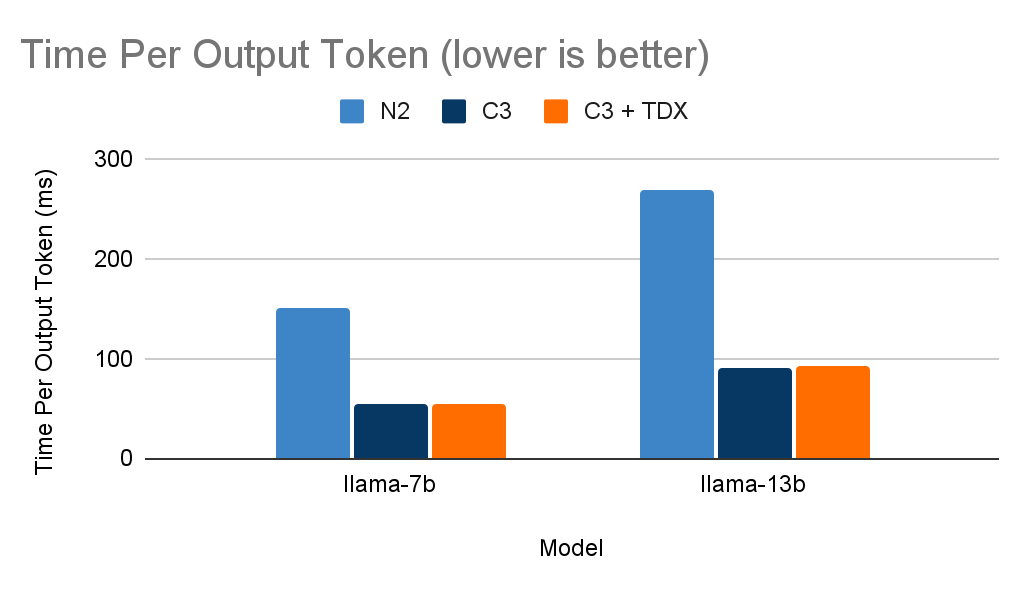
仮想マシン別の Time Per Output Token(TPOT)。
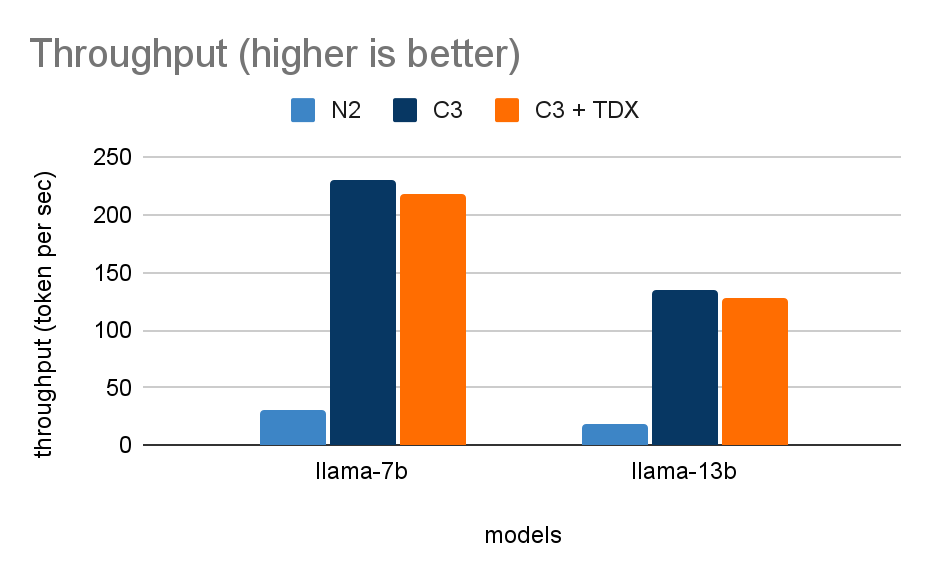
仮想マシン別のスループット。
インテル AMX を搭載した Confidential VMs を今すぐお試しください
テストと結果に関するレポート全文については、こちらのホワイトペーパーをご覧ください。独自に LLM のベンチマークを収集する場合は、Intel® Extension for PyTorch の手順に沿って行ってください。Google Cloud の Confidential Computing プロダクトの詳細をご確認のうえ、今すぐ導入をご検討ください。インテル AMX とインテル TDX を搭載した独自の Confidential VMs をご活用いただけます。

