暗闇に光を当てる: 世界中のインターネット遮断の測定

Google Cloud Japan Team
Censored Planet Observatory の目標: ネットワークの検閲データを誰もがアクセス可能で有用なものにする
※この投稿は米国時間 2023 年 10 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
インターネットのない生活を想像する(人によっては、思い出す)ことは難しいです。仕事から家族、レジャーに至るまで、インターネットは私たちの日常生活の一部として組み込まれています。しかし、もしもそれが突然、警告もなくすべて途絶えたらどうなるのでしょうか?
世界中の多くの人々にとって、それは日常の現実なのです。2022 年、少なくとも 187 件の事例で 35 か国がインターネット アクセスを遮断し、それぞれの停止期間は数時間、数日、または数週間にわたりました。
ミシガン大学の研究チーム Censored Planet Observatory は 2010 年以来、この問題にスポットライトを当てるために取り組んでいます。彼らは政府がインターネット上のコンテンツをどのようにブロックしているかを測定、追跡し、そのデータを Google の Jigsaw との共同開発で作成されたダッシュボードから公開して、分析や探索を可能にしています。検閲によりアクセスがフィルタリングされてしまった場合にそれを復元するため、Jigsaw は Outline などのオープンソースの回避ツールも構築しています。
世界中のインターネット遮断に対抗するには、問題をより良く理解するためのスケーラブルで分散型のさまざまなツールが必要です。Jigsaw と Censored Planet は、検閲キャンペーンの世界的な影響を明らかにするために、データ パイプラインとダッシュボードの作成を Google Cloud チームに依頼しました。
データをクエリする方法
Google チームが 2020 年にミシガン大学のチームと共同で取り組みを開始した際、日々の検閲測定で出力される主なデータは、それぞれ約 5 GB の大規模なフラット ファイルでした。このデータ(合計約 10 TB)をすべて読み込むためには、リアルタイムのクエリ機能を実現するために 100 台以上のオンプレミスのハイメモリ コンピュータが必要でした。この段階に至るまでには果敢な努力が必要でした。このプロジェクトでは、数日ごとに 120 以上の国から検閲測定データを収集しており、記録は 2018 年までさかのぼるため、多くのファイルが多様な形式で多くのソースから集められています。
この統合されたデータセットを構築すること自体が容易な仕事ではありませんでした。さらに、研究者がその内容をクエリして分析できるように開発するのはさらに困難でした。膨大な量のデータを手にした Censored Planet と Google のチームは、インターネット検閲を追跡している研究者にとってこのツールをより有益にする方法に焦点を当てました。
Censored Planet のデータはオープンで自由に共有されていましたが、操作やクエリを行うには特定の技術的な専門知識が必要でした。すべてのデータが 1 つの場所にあるわけではなく、SQL のような分析に適した形式にはなっていませんでした。このチームとそのパートナーはより良い方法を求めていました。
一日分のデータは夜間にわずか数時間で処理されます。
Jigsaw の検閲測定のリード エンジニアである Sarah Laplante は、この大規模なデータセットを BigQuery に素早く簡単に読み込み、アクセスとクエリが容易に行える方法はないかを考えました。
Laplante は「クラウド技術なしにはこのダッシュボードを構築することはできなかった」と述べています。「パイプラインは 24 時間以内に全データセットを再処理する必要があります。そうでなければ、疑わしいデータが散在してしまいます」
彼女は最初の実用最小限の製品につながるサンプル ワークフローを考え出しました:
- データを Dataprep に読み込む。Dataprep は分析と ML のためにデータを視覚的に探索、クリーンアップ、準備するためのクラウド データサービス
- Datarep を使用して重複の削除、エラーの修正、欠損値の補完を行う
- 結果を BigQuery にエクスポートする
このワークフローによって分析が非常に簡単になりましたが、問題点がありました。検閲を追跡するソースは毎日新しいファイルを作成していましたが、これらの JSON ファイルを BigQuery で使用するためにはドメインの知識とコードによる解析が必要でした。この「実用最小限の製品」はスケーリングできませんでした。さまざまな種類のフィルタリング、制限、およびネットワーク制御がさまざまな出力につながりました。
これは、自動化と標準化を含む解決策が切実に求められる問題でした。チームにはより多くの特定のツールが必要でした。
真のデータ パイプラインの作成
毎日新しいデータファイルが作成されるため、チームは 24 時間以内にこれらを統合、処理、JSON から BigQuery にエクスポートするプロセスを開発する必要がありました。このようにすれば、研究者は当日の検閲データとすべての過去のデータに対してクエリを実行し、レポートを作成できます。
ここで Apache Beam が登場しました。
Apache Beam はバッチとストリーム データの混在を処理するように設計されており、Censored Planet のチームはこれを使用してデータセットを毎晩処理し、翌朝には最新のデータが利用できるようになりました。Google Cloud 上でチームは Dataflow を使用して Beam パイプラインの管理を容易にしました。
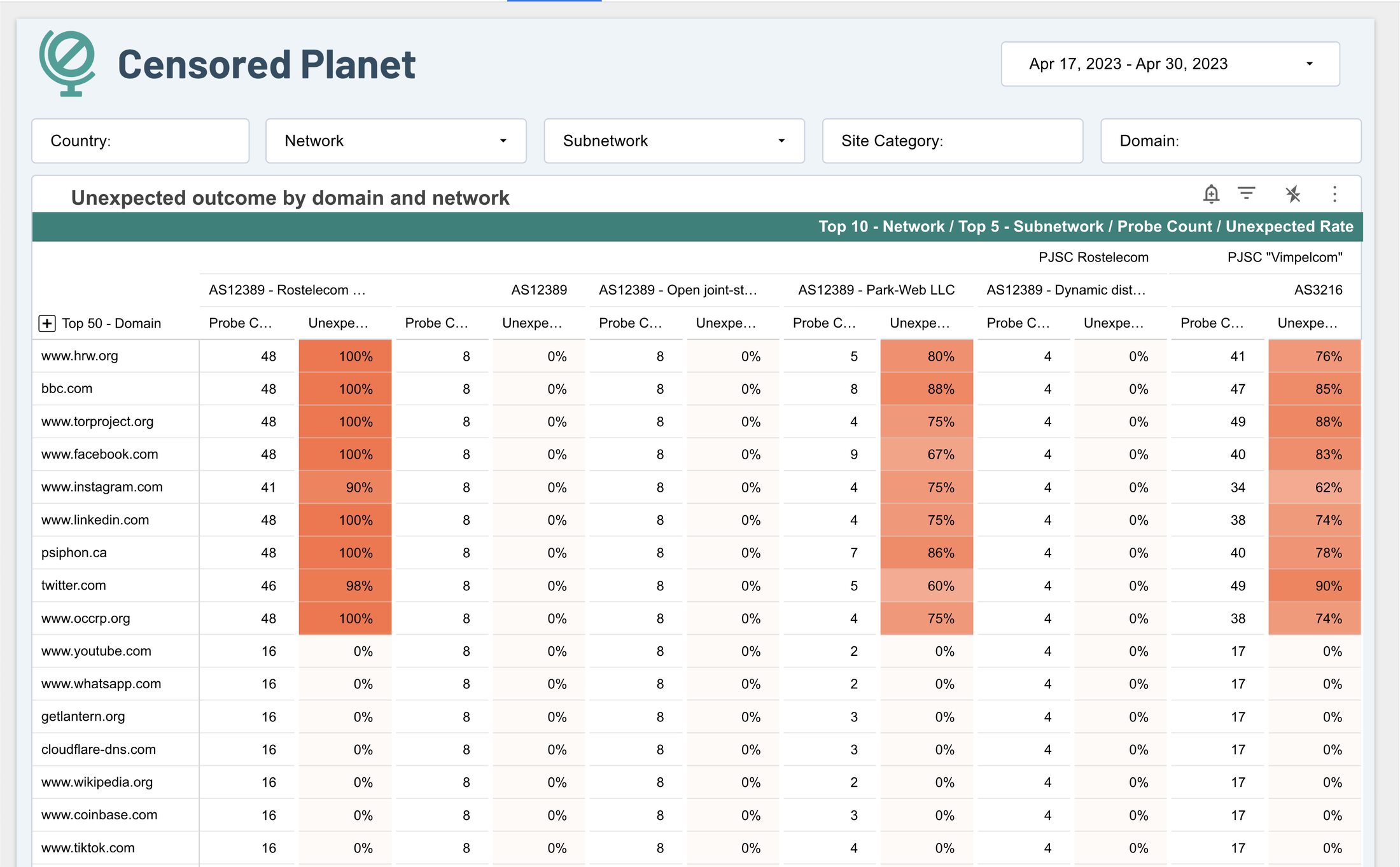
Censored Planet のダッシュボードには、一般的にブロックされているウェブサイトが表示されています。
最初はいくつかの問題がありました。たとえば、一部のデータファイルは非常に大きかったため、処理パイプラインの速度が低下しました。その他には、可視化に必要ないメタデータが含まれていました。Sarah と彼女のチームは、処理を高速化しオーバーヘッドを削減するために、クエリを実装しました。これにより、生成されているテーブルとグラフに有用なデータのみを解析しました。今日、そのジョブは一度に数千人の作業者に届き、迅速に完了します。一日分のデータは夜間にわずか数時間で処理されます。
ダッシュボードの最適化
データセットを処理する方法の問題は解決されましたが、そのデータセットを有用にするには、優れたレポートとダッシュボードが必要でした。すぐに着手できるように、チームは迅速なプロトタイピングから始め、Looker Studio でオプションと構成をテストして、速いペースでイテレーションを行いました。使いやすいツールを使うことで、実用的で即座の質問に答えることができます。
これら初期バージョンは、最終的なダッシュボードの形についての情報提供となりました。最終的なダッシュボード デザインに到達するために、Censored Planet チームは研究者との UX 研究を行い、彼らがダッシュボードを使用して質問に答えようとする様子を観察し、ユーザビリティ、機能性、または利便性を向上させるために調整しました。
Censored Planet のデータを使用する研究者は、インターネットの検閲を行っている政府と、使用しているツールを、可能な限りリアルタイムに近い状態で確認したいと考えていました。ダッシュボードの読み込みとレンダリングを迅速にするために、チームはデータテーブルをクラスタリングおよびパーティショニングする作業を開始しました。表示する必要がないデータを削除することで、彼らは Looker Studio のコストも削減しました。
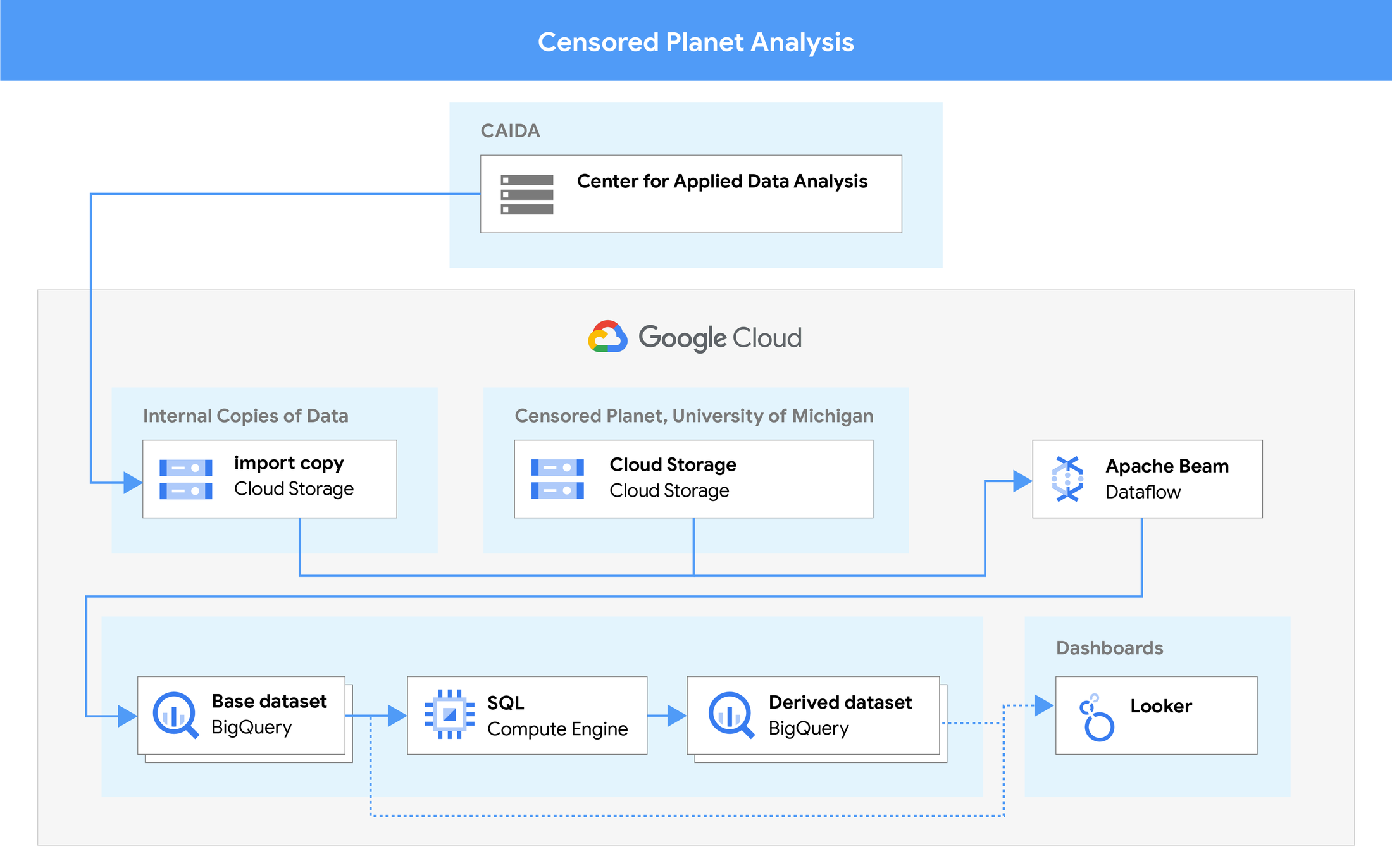
元の測定からダッシュボードまでのデータ パイプライン。
BigQuery 内で、チームは日付ごとにデータをパーティション分割しました。これにより、ほとんどのレポートに必要ない過去のデータを簡単に除外できました。その後、データソース、国、およびネットワークごとにパーティションを設定しました。追跡と対応は一度に 1 つの国に集中することが多いため、これによりクエリとダッシュボードの読み込みが小さくなり、大幅に処理が速くなりました。
データを統合する
目標は、これらすべてのクエリが Looker Studio のダッシュボードに表示され、閲覧者が追跡したいデータソースを選択できるフィルタが用意されることでした。これを実現するために、チームはデータソースを 1 つのテーブルに統合し、そのテーブルを分割してフィルタと表示が容易になるようにしました。
この取り組みには、インターネット検閲研究者のスピードへの要求を満たすという目的以上のものがありました。
データを迅速に再処理し、迅速なダッシュボードを通じてデータを探索できるようにすることで、チームは検閲の動作方法に関する理解のギャップをより迅速に見つけて埋めることができるようになりました。彼らは分析方法が特定の測定値やデータポイントを見落としている箇所に気付き、その後、修正を素早く展開し、テストして検証することができました。新しいダッシュボードと新しいデータ パイプラインを作成するだけでなく、Censored Planet はより良い分析プロセスも作成しました。その方法論については、彼らが Free and Open Communications on the Internet で発表した論文で詳細に説明されています。

Looker Studio でダッシュボードを構築することは、運用上の利点ももたらしました。Looker Studio は Google Cloud でホストされているサービスであるため、チームは作成およびメンテナンスのオーバーヘッドを最小限に抑え、新しいダッシュボードを迅速にスピンアップすることができました。それにより、彼らはデータの収集と主要なユースケースに関する価値あるレポートの提供に、より多くの時間を費やすことができました。
Looker Studio は、研究者、エンジニア、非技術的なステークホルダー、およびパートナーのユーザー エクスペリエンスについても迅速にイテレーションできます。編集も容易であり、ダッシュボードを迅速に更新または変更することができ、エンドユーザーにそれをエクスポートしたり、リミックスして視覚化をより有用にする機会を与えたりすることもできました。
クラウド規模での検閲モニタリング
クラウドベースの分析パイプラインへの移行により、インターネットの自由を監視し、インターネット アクセスの拡大を求める 60 以上のグローバル組織にとって、Censored Planet を利用してこのすべてのデータを共有し、フィルタリングすることがより効率的になりました。チームは Google Cloud のツールを使用して、データ パイプラインの迅速なテスト、イテレーション、変更、新しいツールやサービスのプロトタイピングを行いました。
Google のデータ分析ツールキットは、ミシガン大学のスポンサーにかかるコストを抑えるのにも役立ちました。効率が悪いクエリを分離するために、すべての請求ログを BigQuery にエクスポートし、どの Looker Studio のレポートが大量のデータを取得しているかを特定し、フィルタリングして効率化することができました。
Censored Planet の今後の展望
Censored Planet は、DNS 検閲データなど、ダッシュボードに追加するさらなるデータソースに取り組んでいます。同組織は、インターネット検閲の研究に関心のあるすべての人々に対し、データの使用、スクリーンショットの共有、分析結果の公表を推奨しています。Censored Planet と同様のデータ パイプラインを Google Cloud で構築するには、次の 3 つのガイドから始めてみてください。
ー Google Cloud、デベロッパー リレーション エンジニア Max Saltonstall

