機密データの保護による生成 AI ワークロードの安全確保
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI モデルは、ほぼすべての業界において注目を集めるトピックです。企業は、このテクノロジーを活用して顧客との関わりやビジネス サービスを強化するだけでなく、業務を合理化し、ビジネス プロセスをスピードアップすることを目指しています。ただし、ほとんどの AI / ML アプリケーションと同様、生成 AI モデルはデータとデータ コンテキストによって強化されます。この機密性の高い企業固有のデータを理解し保護することが、デプロイの成功と適切な使用を実現するために重要となります。
サニーベールの Google キャンパスで開催された最新のセキュリティに関するイベントで、参加者を対象に Google が実施した最近のアンケートでは、「あなたの会社にとって、今日の AI に関するリスク、危険性、セキュリティ上の問題のトップ 3 は何だと思いますか?」という質問に対し、回答者は「データ漏洩」と「プライバシー」が懸念事項トップ 3 のうちの 2 つであると回答しました。さらに、「データ漏洩」はプロンプト インジェクションに関連するリスクの一つでもあり、OWASP はこれを基盤アプリケーションのトップ 10 リスクの一つとして特定しています。トレーニング データと基礎レスポンス データの保護は、堅牢な生成 AI アプリケーションを構築するための重要なステップです。
以下では、Google の機密データの保護を使用して生成 AI アプリケーションを保護するためのデータに重点を置いたアプローチについて探ります。実際の例は Jupyter Notebook で提供します。
データが重要な理由
他の AI / ML ワークロードと同様、生成 AI は、特定のビジネスニーズに合わせたチューニングや拡張のためにデータを必要とします。Vertex AI の生成 AI は、データやモデルが Google の基盤モデルのトレーニングに使用されたり、他のお客様に流出したりしないように、堅牢なデータ コミットメントをすでに提供しています。しかしながら、組織が抱える懸念の一つは、モデルのカスタマイズとトレーニングに、個人情報(PI)や個人を特定できる情報(PII)のような機密性の高い要素を含む可能性のある独自データを使用するリスクをどのように軽減するかということです。多くの場合、この個人データの周囲には、モデルが適切に機能するために必要なコンテキストがあります。
個人データを見つけ出して機密性の高い要素だけを取り除くことは、簡単ではありません。さらに、秘匿化戦略はデータセットの統計的特性に影響を与えるほか、統計的に不正確な一般化を行う可能性があります。Cloud Data Loss Prevention(DLP)API を含む Google の機密データの保護サービスは、これらの課題に対処するための検出と変換オプションのセットを提供します。
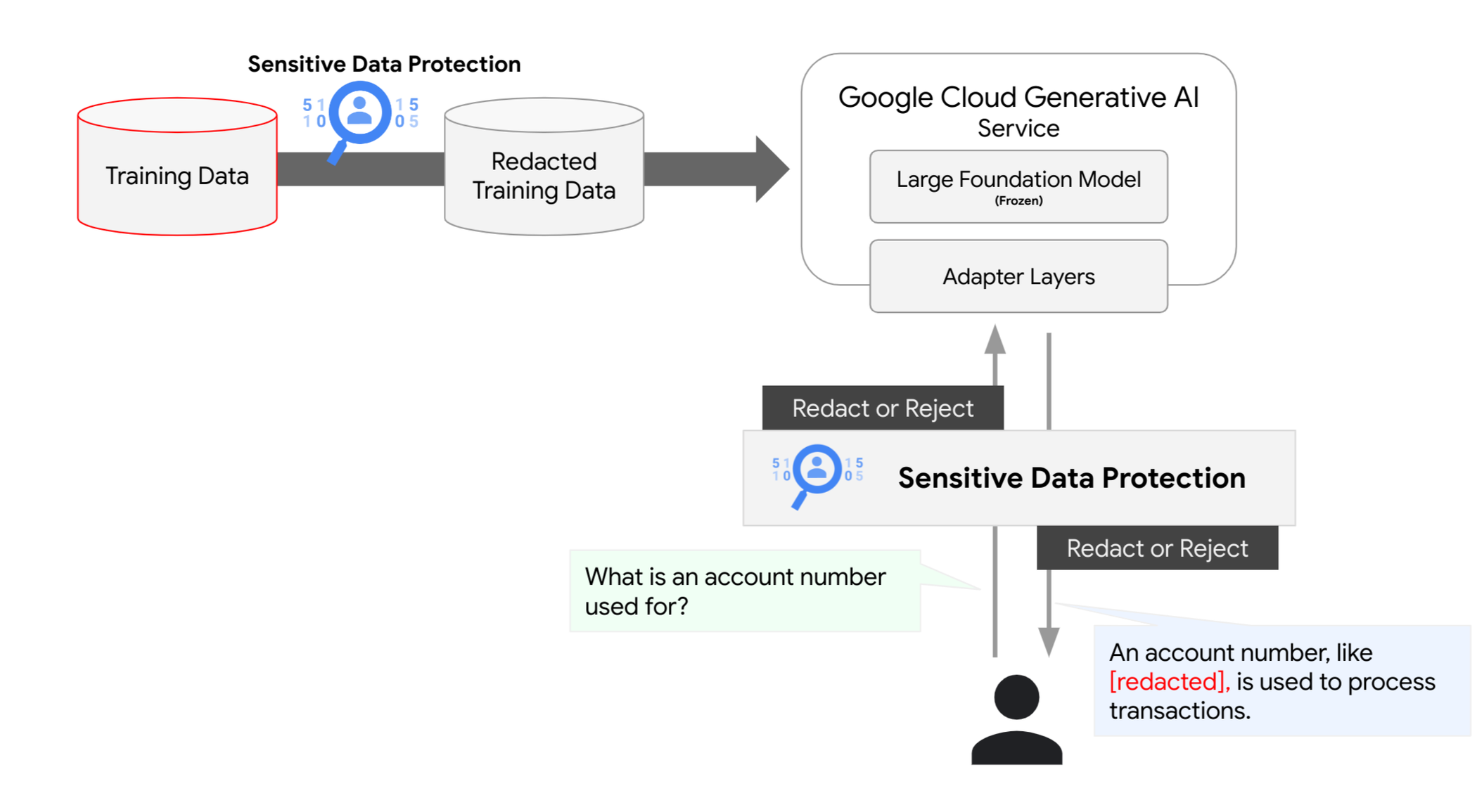
Google Cloud の機密データの保護を使用することで、トレーニングからチューニング、推論に至るまで生成 AI モデルのライフサイクル全体にわたり、一層手厚くデータを保護できます。これらの保護テクニックを早期に導入することで、モデルのワークロードの安全性とコンプライアンスを確保し、再トレーニングや再チューニングにかかる無駄な費用の発生リスクを軽減できます。
データに重点を置いたアプローチの採用
機密データの保護には、名前、個人識別子、財務データ、健康に関する情報、人口統計データなどの機密性の高いデータ要素を迅速に識別できるようにするための、組み込みの infoType が 150 種類以上含まれています。これらの要素を特定することで、パイプラインから削除するレコードの選択や、インライン変換を活用して周囲のコンテキストを保持したまま機密性の高い要素だけを隠すことができ、データの有用性を維持しながらリスク軽減が可能になります。インライン変換は、AI モデルのトレーニング データやチューニング データを準備する際に使用でき、AI が生成したレスポンスをリアルタイムで保護できます。
以下の例では、機密性の高い要素を削除し、データタイプに置き換えています。こうすることで、未加工のコンテンツを明らかにすることなく、データタイプと周囲のコンテキストを把握してモデルをトレーニングできます。
未加工の入力データ:
エージェント: こんにちは、Jason と申します。お名前を伺ってもよろしいですか?
お客様: はい、Valeria です。
エージェント: ご連絡が必要な場合があるので、メールアドレスもお伺いできますか?
お客様: v.racer@example.org です。
エージェント: ありがとうございます。どのようなことでお困りですか?
お客様: 請求に関する問題です。
匿名化された出力:
エージェント: こんにちは、[PERSON_NAME] と申します。お名前を伺ってもよろしいですか?
お客様: はい、[PERSON_NAME] です。
エージェント: ご連絡が必要な場合があるので、メールアドレスもお伺いできますか?
お客様: [EMAIL_ADDRESS] です。
エージェント: ありがとうございます。どのようなことでお困りですか?
お客様: 請求に関する問題です。
上記の例のような単純な置き換えだけでは不十分な場合もあります。機密データの保護には、お客様の特定のニーズに合わせてカスタマイズできる匿名化オプションがいくつかあります。まず、顧客として、検出して秘匿化すべき infoType と、そのまま残す infoType を完全にコントロールできます。さらに、単純な秘匿化からランダム置換、形式を保持した暗号化まで、ニーズに最も適したデータ変換方法を選択できます。
ランダム置換を使用した次の例を考えてみましょう。入力サンプルとよく似た出力が生成されますが、特定された機密性の高い要素がランダムな値に置き換えられています。
入力:
エージェント: こんにちは、Jason と申します。お名前を伺ってもよろしいですか?
お客様: はい、Valeria です。
エージェント: ご連絡が必要な場合があるので、メールアドレスもお伺いできますか?
お客様: v.racer@example.org です。
エージェント: ありがとうございます。どのようなことでお困りですか?
お客様: 請求に関する問題です。
匿名化された出力:
エージェント: こんにちは、Gavaia と申します。お名前を伺ってもよろしいですか?
お客様: はい、Bijal です。
エージェント: ご連絡が必要な場合があるので、メールアドレスもお伺いできますか?
お客様: happy.elephant44@example.org です。
エージェント: ありがとうございます。どのようなことでお困りですか?
お客様: 請求に関する問題です。
データ準備に対する保護
予測エンドポイントに AI モデルをデプロイする場合など、お客様は頻繁に独自のデータを使用してデータセットを作成し、カスタム AI モデルをトレーニングします。さらに、LLM レスポンスの関連性とビジネスの目標を高めるために、お客様固有のデータを使用して言語やコードなどのモデルをファイン チューニングします。
一部のお客様は、生成 AI 機能を使用して基盤モデルをチューニングし、特定のタスクやビジネスニーズに合わせて基盤モデルをデプロイします。このチューニング プロセスでは、お客様固有のデータセットを使用し、推論時に使用されるパラメータを作成します。パラメータは、ユーザーのプロジェクト内の「固定された」基盤モデルの前に存在します。これらのデータセットから機密データを確実に取り除くには、機密データの保護サービスを使用して、データセットの作成に使用されたデータをスキャンします。同様に、この方法を Vertex AI Search に使用して、アップロードされたデータに機密情報が含まれていないことを確認できます。
インライン プロンプトとレスポンスの保護
トレーニング パイプラインの保護は重要ですが、これは機密データの保護で提供される防御策の一部にすぎません。生成 AI モデルはユーザーから構造化されていないプロンプトを受け取り、新しい、おそらく見たことのないレスポンスを生成するため、機密データのインラインでの保護も必要になる場合があります。多くの既知のプロンプト インジェクション攻撃が横行しています。これらの攻撃の主な目的は、モデルを操作して意図しない情報を共有させることです。
プロンプト インジェクションから保護する方法は複数ありますが、機密データの保護では、入力プロンプトと生成されたレスポンスをスキャンして機密性の高い要素を確実に特定または削除することにより、生成 AI 基盤モデルとの間で送受信されるデータに対してデータ中心のセキュリティ管理を提供できます。
次のステップ
機密データの保護について詳しく学び、Colab ノートブックを参照して AI / ML および生成 AI のデータとワークロードを保護するためにどのような対策を講じることができるかをご確認ください。Vertex AI を使用すると、ML の専門知識がなくても、基盤モデルを操作、カスタマイズし、アプリケーションに組み込むことができます。Model Garden での基盤モデルへのアクセス、Generative AI Studio のシンプルなインターフェースを使用したモデルのチューニング、データ サイエンス ノートブックでのモデルの直接利用なども可能です。
-シニア プロダクト マネージャー Scott Ellis
-クラウド セキュリティ アーキテクト Assaf Namer
