機械学習用データの収集と準備
Google Cloud Japan Team
※この投稿は米国時間 2018 年 7 月 30 日に Google Cloud blog に投稿されたものの抄訳です。
機械学習(ML)プロジェクトの設計および実行で成功を収めるには、多くの場合、業務や営業、研究、技術などに携わるさまざまなチームの協力が必要です。チーム内の足並みを揃え、プロジェクトを軌道に乗せるためには、データの収集と準備に関する本質的な理解が欠かせません。
この投稿では、ML で使用するデータの評価と準備のための一般的なガイドラインをご紹介します。もしあなたが ML プロジェクトに関わっているのであれば、たとえ最低限の技術的知識しか持ち合わせていなくても、本稿で説明したガイドラインがお役に立てるでしょう。本稿の目標は、役割の異なる人々の認識を統一し、有用な ML モデルの設計とトレーニングをすぐに始められるようにすることです。
本稿は 2 部構成となっています。第 1 部ではデータの共通要件と実際に考慮すべきことをまとめており、お手元のデータが ML に適しているかどうかを評価し、期待値の設定に役立ちます。適切なデータが見当たらない場合は、どのようなデータを収集すべきかを判断するうえで第 1 部の内容を参考にしてください。第 2 部は、ML トレーニング用データの準備に向けて通常行うべきことをまとめた To Do リストです。では、始めましょう。
データの収集
目標を達成できる ML モデルの構築には、モデルにとって学ぶことのできるデータが必要です。ある入力に基づいてターゲット出力を予測することが目標の場合は、過去の入力と出力を含む例からなるデータが必要になります。不正なクレジットカード取引(予測のターゲット)を検出(予測)することが目的なら、モデルのトレーニングに必要な個々のデータは、過去のクレジットカード取引に関する情報と、その取引が不正なものだったかどうかについての情報を含んでいなければなりません。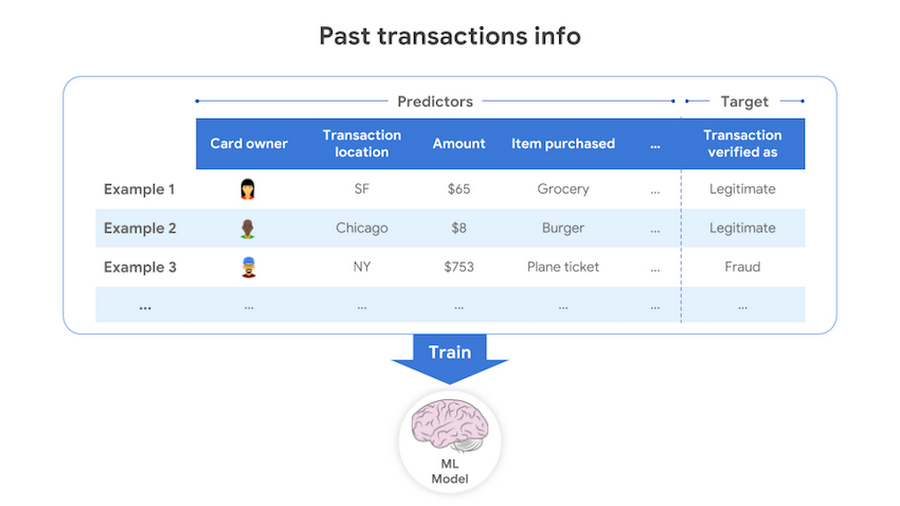
有用なモデルを構築するには、ターゲットの予測に役立つデータを入力に含める必要があります。たとえば、クレジットカード詐欺を見つけるのに必要なのは、取引額、取引場所、カード所有者の主要な居所といった情報です。一方、カード所有者の名前といったデータは、このタスクではあまり役に立ちません。また、データは正確でなければなりません。間違っていたり不正確だったりするデータでトレーニングしても、優れたモデルは期待できないからです。
モデルがさまざまな結果を区別するうえでは、それぞれの結果に対応する例が必要です。クレジットカード詐欺の場合、不正な取引だということがはっきりしている例と、合法的な取引だということがはっきりしている例の両方を含むデータを用意しなければなりません。
モデルがあやふやな予測を行わないよう、十分な量の例(ラベル付きデータとも呼ばれるもの)が必要となります。目安としては、カテゴリー(例 : 取引が合法的か詐欺的か)の予測の場合、予測に使われる属性(特徴量とも呼ばれます)の数の 10 倍程度 1 の例がカテゴリーごとに必要であり、数値(例 : 星の位置)の予測の場合は特徴量の 50 倍が必要です。より多くのデータが用意できる場合は、より複雑なモデルを試してみることで、より良い性能指標(例 : 正確度)を得ることができます。十分な数のラベル付きデータがなくても、場合によっては(例 : 画像分類や自然言語処理)、Cloud AutoML を使用しデータに合わせてトレーニング済みモデルをカスタマイズすれば、素晴らしい結果を得ることも可能です。Google の Human labeling のようなサービスを使用して、手持ちのデータにラベルを付けることも可能です。
予測に使える情報を十分に得るためには、トレーニング データと予測データの粒度を一致させることが重要です。たとえば、1時間ごとの気温の変化を予測したいのに、1 日や 1 週間に 1 度ずつ気温を記録していたのでは、出力に比べて入力の粒度が粗すぎます。
バイアスのないモデルの構築には、モデリングしようとしている母集団や分布を偏りなく表現するデータを収集して使用します。たとえば、顧客満足度を予測するモデルを作る際にオンライン レビューを使用すると、データセットにバイアスがかかってしまいます。この種のレビューは極端な評価を誇張する傾向があるからです。バイアスをどの程度是正できるかは、問題とデータの両方によって決まります。母集団のあるセグメント全体がサンプルから欠損している場合、母集団全体を代表する推論を導くような調整を加えることは困難です。あるセグメント全体がデータから欠落している場合、可能であれば、そのようなセグメントに関するデータを追加で入手するべきです。
ビジネス上の重要な課題とも言える予測処理、すわなち、過去のデータに基づく未来の結果予測を行うには、十分な期間にわたってデータを収集していなければなりません。たとえば、返済期間が 5 年の融資が焦げ付く可能性を予測したいときに、3 年分のデータしかなければバイアスが発生します。一般的な予測問題には、アイスクリームの売上げのように、周期性があるものが多数あります。こうした周期的な予測では、ビジネス上の意思決定を下す前にモデルの品質を正しく評価することが重要なため、少なくとも 3 サイクル分のデータを用意することが、経験上良い目安となります。周期的な動きをつかむために少なくとも 1 サイクル、モデルが周期内の一般的なトレンド(増加、減少、不変)を学習するためにもう 1 サイクル、モデルの評価のためにもう 1 サイクルが必要ということです。
予測モデルの構築(つまりトレーニング)では、データ例として過去データのスナップショットを再構成し、それを学習用データとしてモデルに示さなければなりません。そのため通常は、アイテムの価格変更やユーザーによる設定変更といった、更新がなされたときのタイムスタンプを知ることが重要になります。ただし、データ値が得られた時期の順序さえわかれば過去の出来事を正確に再現できる場合は、時系列順が分かれば十分で、タイムスタンプまでの情報は不要かもしれません。
どのようなタスクでも、データの中に欠損値を含んでいることがよくあります。欠損値は、同じデータ フィールドであっても None や NULL、NaN、0、-1、9999 などのように異なる形式で表現されることがあり、欠損値が多ければ多いほどデータの有用性は下がります。欠損値のないデータ項目だけを使うことにした場合は、役に立つデータが十分に残っていることを確認してください。また、欠損値が生じた理由を知ることも大切です。欠損値が系統的に発生している場合(つまり、無作為に欠損値が発生しているわけではない場合)、そのデータには偏りがあり、適切に処置しなければモデルにバイアスが生じる危険があります。
データの個々のフィールドに関するドキュメントを作り、何を表しているか、どのように計測したか、いつ収集したか、元の値が更新される可能性があるか、そのユース ケースで役に立つ理由は何かということを記録するようにしましょう。
データの準備
集めたデータが ML に適していることが確認できたら、データをモデリングに使える状態に整えます。意外かもしれませんが、ML アルゴリズムの最適化よりもこのステップのほうが、時間がかかることがよくあります。以下で説明する作業は ML の専門知識を必要としません。また、データの所有者や、データを頻繁に使う利用者がこの準備作業に参加すれば、ML モデルの開発をスピードアップすることができます。データの誤りやノイズ、欠損値を見つけて処置し(修正、みなし値の付与、削除)、Cloud Dataprep を使用して一貫性を持たせ、データをクリーンにしましょう。データ フィールドの値の単位が異なる場合は(例 : 米ドル、ユーロ、元)、個々の値の単位を明らかにして同じ単位に変換します。カテゴリー変数については、同じ値の異なる表現を把握し、1 つの表現に変換します。たとえば、「販売促進部長」「販促部長」「販売促進マネジャー」は 1 つの表現に揃えます。
個々のデータ フィールドの値の意味は一貫していなければなりません。商品単価を格納するフィールドに原価と販売価格が混在していたり、測定器のキャリブレーションがまちまちになっていたりすると、それは整合性のあるデータとは言えません。
データ リークの発生要因を見つけて、すべて取り除いておきましょう。データ リークというのは、予測時には入手できない情報を入力の一部としてモデルの構築に利用した際に発生する問題です。たとえば、絶滅危惧種のクジラの鳴き声を検出するモデルを作成するコンテストにおいて、用意されたサンプルデータ内の「正解のファイル(クジラの鳴き声を含む音声ファイル)」がすべて同じファイルサイズであるということが起きました。この場合、ファイルサイズが学習のための入力データとして使われて、特徴量として認識されてしまうと、コンテストでは素晴らしい成績を収めても、実世界では利用できないモデルが出来上がります。
予測問題の場合は、過去の任意の時点におけるデータのスナップショットを簡単に作れるパイプラインを構築しましょう。これは、有用なモデルを作るうえできわめて重要ですが、実際には「言うは易く行うは難し」です。トレーニング用のデータ例としては、ML モデルがすでにあれば、ターゲットを予測する時点で利用可能なデータを使用しなければなりません。たとえば、融資が焦げ付く確率を予測するモデルを構築するとします。個々のトレーニング用データ例としては、融資を申し込んできたときの債務者の FICO スコアを使用し、それ以降の時点での FICO スコアを使ってはなりません。トレーニング時のデータとサーブ時のデータに不整合が発生するのを防ぐには、サーブ時に使ったフィーチャー セットを保存し、それ以降のトレーニングでは、そのフィーチャーを使うようにするとよいでしょう。本来ならすべてのデータ例についてこのようにしたいところですが、それが不可能であれば、トレーニングとサーブの整合性が保証できる程度に多くのデータ例をこの方法で用意してください。
モデルのパフォーマンスを高めるには、外部データセットなどの新しいソースを使ってデータを増やします。そして、ドメインの専門知識を活用し、ターゲットをより適切に予測するうえで有益なフィーチャーを作成します(フィーチャー エンジニアリングと呼ばれます)。モデルに対する入力データは、多様な入力ソースのデータと適切に変換したデータを 1 つにまとめて作ります。
シームレスにデータ変換を行うためにデータ パイプラインを作り、間違いの修正、変換の改良、反復処理を簡単に行えるようにしましょう。また、データの品質保証のために自動テストを実施してください。テストでよく行われるのは、欠損値、誤りのある値、非現実的な値、重複、誤ったテーブル結合がないことのチェックです。特に予測問題については、トレーニングとサーブの一貫性についても追加でテストしたいところです。
使おうとしている ML モデル次第では、正規化や外れ値の置き換えなど追加の変換が必要になることもあります。こういった仕事はデータ サイエンティストに任せればよいでしょう。
さらに深く掘り下げるには
ML プロジェクトの設計ではデータ要件の評価がきわめて重要です。データの準備は ML 開発において時間がかかる部分ですが、プロジェクトの成否を決める部分でもあります。もっと詳しいチェック リストが必要な場合はこちらのドキュメントを参照してください。また、データの準備にまつわる皆さんのアイデアやテクニックを、私たちの Twitter ハンドルにハッシュタグ #mldataprep を付けて投稿してください。私たちのチェック リストからヒントを得ていただくとともに、私たちも皆さんから学びたいと思っています。1 k 種類のカテゴリーを持つカテゴリカル入力フィールド(例 : 取引が行われた “NY”、“SF” などの都市)は、k-1 個のフィーチャーとして数えることを忘れないようにしてください(k 種類のカテゴリーを符号化するためには、k-1 個のダミー変数が必要です)。つまり、入力フィールドに指定できるカテゴリーが多ければ多いほど、必要なデータも増えるということです。
- By Rostam Dinyari, Strategic Cloud Engineer



