DNS パケット欠落のケース: Google Cloud サポート ストーリー
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: Google Cloud テクニカル ソリューション エンジニア(TSE)がサポートケースにどのように取り組んでいるか気になったことはありますか?TSE はお客様から報告された問題の技術的な根本原因のトラブルシューティングと特定を担当するサポート エンジニアです。かなりシンプルな問題もありますが、数名の専任エンジニアによるトラブルシューティングを必要とするサポート チケットがたまに送信されることがあります。このブログ投稿では、Google Cloud テクニカル ソリューション エンジニアから聞いた、最近解決した特に厄介なサポートケース(DNS パケットが欠落する問題)についてご紹介します。トラブルシューティングの過程で収集した情報と、どのように方法を推論して解決に至ったかについて、下記でエンジニアが説明します。根深いバグを明らかにするだけでなく、このストーリーにより、お客様が次に Google Cloud サポートにチケットを送信した際に想定される内容についてなんらかの知見を提供できればと思います。
トラブルシューティングには科学と芸術の両面があります。最初のステップは、予期しない方法で動作している原因について仮説を立て、次にその仮説が正しいかどうかを証明することです。ただし、仮説を立てる前に、まず問題を明確に特定し正確に表現する必要があります。問題が曖昧すぎる場合、問題を絞り込むためにブレインストーミングを行わなくてはなりません。ここで、プロセスの「芸術的な」側面が表れます。
これは Google Cloud 環境では二重の意味で困難になります。Google Cloud はお客様のプライバシーを保護するために努めています。ですから、私たちテクニカル ソリューション エンジニアには、お客様のシステムへの書き込みアクセス権がありません。また、システムに対する可視性がお客様の場合と異なり、仮説が正しいかどうかを迅速に検証するためにシステムを変更することは不可能です。お客様によっては、VM ID を Google に送信すれば、自動車修理工場の整備士のように直してもらえると信じている方もいらっしゃいます。しかし、実際の GCP サポートケースはむしろ会話に似ています。つまり、情報収集に始まり、仮説を立て証明または否定し、最終的にケースを解決するための主な方法は、お客様とのコミュニケーションなのです。
問題のケース
ここでは、解決できたサポートケースのストーリーをご紹介します。うまくいった理由の 1 つは、ケースの説明が的確であり、とても詳細かつ正確であった点です。以下は最初のサポート チケットの記録です。お客様のプライバシーを保護するために匿名化しています。
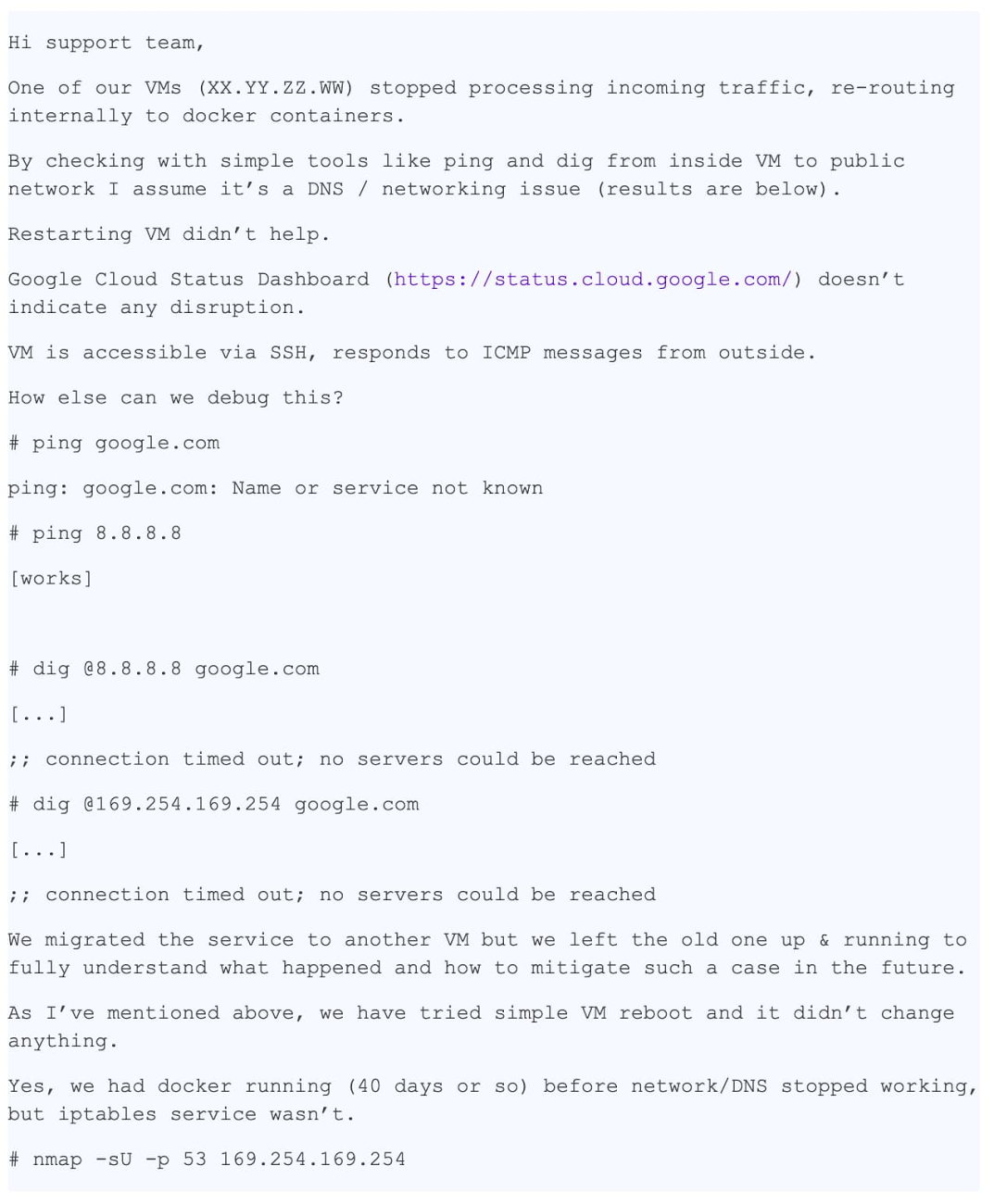
このメッセージには以下に示す詳細な情報が多数含まれているため、非常に役立ちます。
●問題のある具体的な VM を識別するための情報
●問題の概要 - DNS 解決が機能しない
●問題が生じている場所 - VM とコンテナ
●問題を絞り込むためにすでに実施したトラブルシューティング手順
このケースは「P1: 重大な影響 – 本番環境でサービスを使用できない」として報告されました。つまり、ケースはデフォルトで「フォローザサン」として 24 時間体制でサポートが提供され(サポートケースの優先順位付けについて詳しくは、こちらをクリックしてください)、各リージョンのシフト終了時に次のリージョン チームに引き継がれます。実際、ケースはチューリッヒに拠点を置くチームに到達するまでに、すでに世界中の他のリージョン サポートチームに数回転送されていました。この間、お客様は暫定対策を適用済みでした。しかし、根本的な原因が見つからなかったため、問題が本番環境システムで再発する可能性を心配していました。`
これまでに収集した情報は以下のとおりです。
●/etc/hosts の内容
●/etc/resolv.conf の内容
●iptables-save の出力
●ngrep コマンドを使用して収集された pcap ファイル
そして、こうした情報をすべて使用し、トラブルシューティングの「調査」部分を開始する準備が整いました。
最初のステップ
最初に行うのは、メタデータ サーバーのログとステータスをチェックし、正常に動作しているか確認することです。確認したところ、正常に動作していました。メタデータ サーバーは IP アドレス 169.254.169.254 に向けられたドメイン名解決のリクエスト等に応答していました。また、VM に適用されたファイアウォール ルールが適切で、パケットをブロックしていないことも再確認します。
この問題には不可解な点がありました。これまでは、UDP パケットがドロップされているという仮説しかありませんでしたが、実際にはドロップされていないことが nmap の出力から確認されていました。私たちは、ほかにいくつかの仮説とそれを検証する方法を思いつきました。
●パケットは選択的にドロップされているか?=> iptable ルールの確認
●MTU が小さすぎるか?=> ip a show の出力確認
●問題は UDP のみか、TCP も関係しているか?=> dig +tcp の実行
●dig によって生成されたパケットは戻ってくるか?=> tcpdump の実行
●libdns は正常に動作しているか?=> strace を実行して、実際にパケットが送受信されていることを確認
ケースの現在の担当者が提案を求めているため、すぐにお客様にビデオ会議をしてトラブルシューティングをリアルタイムで行うことにします。
通話中に、さらにいくつかのテストを実施します。
●iptable ルールをフラッシュするが、成功しない。
●ネットワーク インターフェースとルーティング テーブルを確認する。MTU が正しいことを再確認する。
●dig +tcp google.com(TCP)は動作するが、dig google.com(UDP)は動作しないことが判明する。
●「dig」の実行中に tcpdump を実行すると、UDP パケットが戻ってくることを確認する。
●strace dig google.com を実行すると、dig は sendmsg() と recvmsg() を正常に呼び出すが、後者がタイムアウトすることを確認する。
これで担当者のシフトの時間が終了したため、残念ながらケースを別のタイムゾーンの担当者に任せる必要がありました。このケースはすでに私たちのチームでよく知られるようになっていて、同僚が python scapy モジュールを使用して生の DNS パケットを作成することを提案してくれました。
このスニペットは DNS パケットを作成し、メタデータ サーバーにリクエストを送信します。
お客様がコードを実行すると、DNS 応答が返され、アプリケーションがそれを受信します。これにより、ネットワーク層に問題が存在する可能性はないことを確認できます。
シフトがもう一度回ったあと、ケースが私たちのチームに戻ってきました。ケースを別のシフトに回さないようにしたほうがお客様には好都合だと判断したため、今後はこのケースを固定で担当することにしました。
その間に、お客様がイメージのスナップショットを提供することに喜んで同意してくれました。これはとても良い知らせでした。自分でイメージをテストできると、トラブルシューティングが非常に迅速になります。分析のためにコマンドを実行して出力を送信するようにお客様にお願いする必要がなく、すべてをリアルタイムで行うことができます。
同僚から羨望の目を向けられるようになりました。昼食時に問題のケースが話題になりましたが、まだ何が起こっているのかわかる者はいませんでした。幸い、お客様は暫定対策があるのでそれほど急いでいませんでした。このため、調査できる時間が増えます。また、イメージがあるので必要なすべてのテストを実行できます。やる気が出てきました。
ステップを振り返る
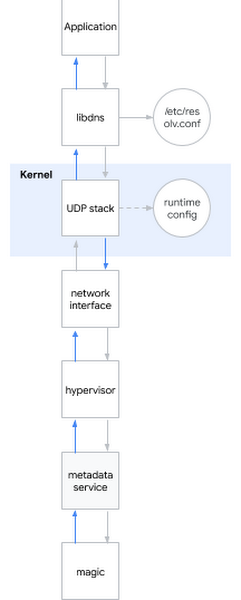
面接でシステム エンジニアが尋ねられる非常に有名な質問はこうです。「ping www.google.com を実行するとどうなりますか?」これは的を射た質問です。面接を受ける人が、シェルからユーザーランド、カーネル、ネットワークまでのパスを説明する必要があるからです。実際、面接の質問が現実生活で役立つこともあるのですね。
この問題を当面の問題に適用することにします。大まかに言えば、DNS 名を解決しようとすると、動作は次のようになります。
1.アプリケーションは特定のシステム ライブラリ(libdns など)を呼び出す。
2.libdns はシステム構成をチェックして、照会する DNS サーバーを把握する(下記の図では、メタデータ サーバーの 169.254.169.254)。
3.libdns はシステムコールを使用して UDP ソケット(SOCKET_DGRAM)を作成し、DNS リクエストを含む UDP パケットを送受信する。
4.UDP スタックは sysctl インターフェースを使用してカーネルレベルで構成できる。
5.カーネルはハードウェアと対話し、ネットワーク インターフェースを使用してネットワークにパケットを送信する。
6.メタデータ サーバーに接続すると、パケットは実際にハイパーバイザによってキャプチャされ、ハイパーバイザはパケットをメタデータ サーバーに送信する。
7.メタデータ サーバーはなんらかの方法で実際に名前を解決し、同じ方法で応答を返す。
まとめると、検討した仮説は次のとおりです。
仮説: ライブラリが破損している
●テスト 1: 影響を受けるシステムで strace を実行し、dig が正しいシステムコールを呼び出しているかどうかを確認する
○結果: 正しいシステムコールが呼び出される
●テスト 2: scapy を使用して、OS システム ライブラリをバイパスして名前を解決できるかどうかを確認する
○結果: scapy による解決が機能する
●テスト 3: libdns パッケージで rpm -V を実行し、ライブラリ ファイルで md5sum を実行する
○結果: ライブラリ コードは稼働中のオペレーティング システムのものとまったく同じ
●テスト 4: 問題の動作が発生しない VM にお客様のイメージのルート ファイル システムをマウントし、chroot を実行して、DNS 解決が機能するかどうかを確認する
○結果: DNS 解決が機能する
結論: テスト 1~4 から、ライブラリに問題はない
仮説: DNS 解決が正しく構成されていない
●テスト 1: tcpdump を検査して、「dig」の実行後に送受信された DNS パケットが適切かどうかを確認する
○結果: 適切である
●テスト 2: サーバーの /etc/nsswitch.conf と /etc/resolv.conf を再確認する
○結果: 適切である
結論: テスト 1~2 から、DNS 構成に問題はない
仮説: カーネルが破損している
●テスト: 新しいカーネルをインストールし、署名を確認して再起動する
○結果: 動作に変化なし
仮説: お客様のネットワーク(ハイパーバイザのネットワーク インターフェース)が誤動作している
●テスト 1: ファイアウォール構成を確認する
○結果: ファイアウォール構成(ホスト内と GCP 上の両方)で DNS パケットが許可されている
●テスト 2: トラフィックをキャプチャして、DNS リクエストが正しく送信され、応答が受信されたことを確認する
○結果: tcpdump は応答パケットがホストに受信されたことを示す
結論: テスト 1~2 から、ネットワークに問題はない
仮説: メタデータ サーバーが機能していない
●テスト 1: メタデータ サーバーのログに異常がないか確認する
○結果: メタデータ サーバーのログに異常はない
●テスト 2: dig @8.8.8.8 を使用してメタデータ サーバーをバイパスする
○結果: メタデータ サーバーが使用されていなくても解決に失敗する
結論: テスト 1~2 から、メタデータ サーバーに問題はない
最終的な結論: 仮説は複数のサブシステムで検証されたが、ランタイム構成は未確認
カーネル ランタイム構成を詳しく調べる
カーネル ランタイムを構成するには、コマンドライン オプション(grub)や sysctl インターフェースを使用できます。/etc/sysctl.conf を調べると、驚いたことにカスタム構成がいくつかあるではありませんか。何か手がかりが見つかりそうです。ネットワーク関連や TCP 専用でないオプションはすべて無視します。残るは、一連の net.core 構成です。次に、ホスト解決が機能する VM を選び、破損した VM のすべての設定を 1 つずつ適用します。ようやく原因を突き止めました。
net.core.rmem_default = 2147483647
この設定こそが、最終的に DNS 解決が失敗する原因だったのです。決定的な証拠が見つかりました。しかし、なぜこうなってしまったのでしょう。こうなってしまった条件があったはずです。
net.core.rmem_default は、UDP パケットのデフォルトの受信バッファサイズを設定します。一般的な値は約 200 KiB ですが、サーバーが大量の UDP パケットを受信する場合はバッファサイズを増やすことが推奨されます。新しいパケットが到着したときに、アプリケーション側の処理速度が十分でないためにバッファがいっぱいだった場合、パケットが失われます。お客様は UDP パケットとして送信された指標を収集するアプリケーションを実行していたため、データポイントが失われないようにバッファを適切に増やしていました。そして、この値を可能な限り高い値である 2 の 31 乗 - 1 に設定しました(2 の 31 乗に設定しようとすると、カーネルから「引数が無効です」が返されます)。
nmap と scapy が正常に動作していた理由が不意にわかりました。生のソケットが使用されていたからだったのです。生のソケットは通常のソケットとは異なり、iptable をバイパスし、バッファリングが行われません。
しかし、「バッファが大きすぎる」と問題が生じるのはなぜでしょうか?意図したとおりに機能していないことは明白です。
現時点では、複数のカーネルと複数のディストリビューションで問題を再現できます。この問題はすでにカーネル 3.x に存在し、カーネル 5.x にも存在しています。確かに次のコマンドを実行すると、
sysctl -w net.core.rmem_default=$((2**31-1))
DNS は機能しなくなります。
そこで、機能する値を探し始めました。単純なバイナリ検索アルゴリズムを使用すると、2147481343 でうまくいくようです。この数値には特に意味がありません。お客様にこの数値を試すように提案しました。送られてきた返信には、google.com では機能するが他のドメインでは機能しないとありました。調査を続けます。
パケットがドロップされたカーネルの場所を示すツール、dropwatch をインストールしてみました。もっと早く使うべきでした。関数 udp_queue_rcv_skb に問題があることが判明しました。そこで、カーネルソースをダウンロードし、printk関数を数か所に追加して、パケットがドロップされる場所を正確に追跡します。失敗する固有の if 条件がすぐに見つかりました。この条件をしばらく凝視していて、2 の 31 乗 - 1、意味のない数値、機能しないドメイン、それらすべてがつながりました。問題のコードは __udp_enqueue_schedule_skb の一部です。
次の点にご注意ください。
●rmem は int 型です。
●size は u16(16 ビットの符号なし整数)型で、パケットのサイズを格納します。
●sk->sk_rcvbuf は int 型でバッファのサイズを格納し、デフォルトでは net.core.rmem_default の値と等しくなります。
sk_rcvbuf が 2 の 31 乗に近づいたときに、パケットのサイズを追加すると整数オーバーフローが発生する可能性があります。また、int 型なので負の数になります。したがって、条件が false であるべきなのに true になります(詳細は、符号付数値表現に関するこちらの説明もご覧ください)。
修正は簡単で、unsigned int にキャストするだけです。修正を適用して再起動します。DNS 解決が再び機能するようになりました。
問題解決を終えて
調査結果をお客様に送信し、カーネルパッチを LKML に送りました。パズルの一つひとつのピースが最終的につながって満足しています。なぜこの問題が発生したのか、正確に説明できるようになったのです。さらに重要なのは、協力して問題を解決できたことです。
確かに、今回は非常にまれなケースでした。幸い、これほど複雑なサポートケースに取り組むことはほとんどないため、通常はより迅速にサポートケースをクローズできます。とはいえ、このサポートケースを通読することで、Google の作業の取り組み方や、サポートケースをできるだけ早く解決するために、いかにお客様から助けられているかをご理解いただけるかと存じます。このブログ投稿をお楽しみいただけたら、cloud-support-blog@google.com までメールでお問い合わせください。その他の難しいサポートケースについて、特に閲覧が多かったアーカイブ関連を調べてお伝えします。
- By Google Cloud Platform サポートのテクニカル ソリューション エンジニア Antonio Messina


