The case of the missing DNS packets: a Google Cloud support story
Antonio Messina
Technical Solutions Engineer, Google Cloud Platform Support
Editor’s note: Ever wonder how Google Cloud Technical Solutions Engineers (TSE) approach your support cases? TSEs are the support engineers responsible for troubleshooting and identifying the technical root cause of issues reported by customers. Some are fairly simple, but, every once in a while, a support ticket comes in that takes several dedicated engineers to troubleshoot. In this blog post, we hear from a Google Cloud Technical Solution Engineer about a particularly thorny support case that they recently solved—the case of the missing DNS packets. Along the way, they’ll show you the information they gathered in the course of their troubleshooting, and how they reasoned their way through to a resolution. Besides uncovering a deep-seated bug, we hope that this story will give you some insight into what to expect the next time you submit a ticket to Google Cloud support.
Troubleshooting is both a science and an art. The first step is to make a hypothesis about why something is behaving in an unexpected way, and then prove whether or not the hypothesis is correct. But before you can formulate a hypothesis, you first need to clearly identify the problem, and express it with precision. If the issue is too vague, then you need to brainstorm in order to narrow down the problem—this is where the “artistic” part of the process comes in.
This is doubly challenging in the Google Cloud environment. Google Cloud works hard to help ensure customer privacy, so we, your technical solutions engineers, do not have write access to your systems. Nor do we have the same visibility into the system as you do, and we absolutely cannot modify the system to quickly test if our hypothesis is correct. Some customers believe that they can send us a VM id, trusting that we will fix it like car mechanics at a garage. But, in fact, a GCP support case is more like a conversation: communicating with you is the main way we collect information, make hypotheses and prove (or disprove) them, all the way to eventually solving the case.
The case in question
This is the story of a support case with a happy ending. One of the reasons it was successful was that the case description was excellent: very detailed and precise. Here is a transcript of the first support ticket, anonymized to protect the customer’s privacy:
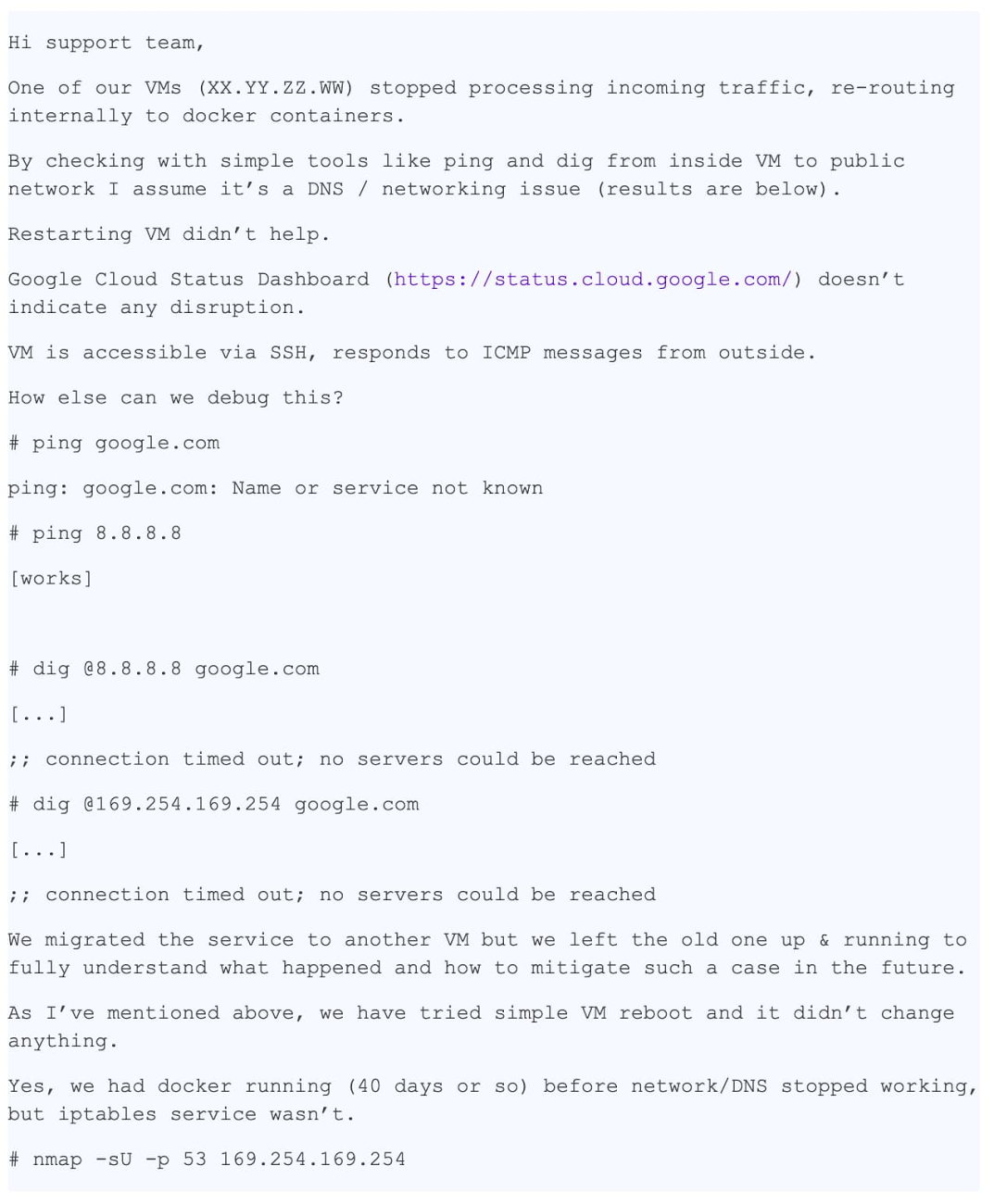
This message is incredibly useful because it contains a lot of detailed information:
- The specific VM with the issue
- The issue - DNS resolution not working
- Where the issue is visible - the VM and the container
- Which troubleshooting steps were already performed to narrow down the problem
The case was filed as “P1: Critical Impact - Service Unusable in production“. This means that the case will “Follow the Sun” by default, to provide 24/7 support (click here to read more about support case prioritization), and at the end of every regional shift will be assigned to the next regional team. In fact, by the time our Zurich-based team got to it, the case had already bounced to the other regional support teams around the world a couple of times. During this time the customer had already put in place a mitigation. But because they hadn’t found the root cause, they were worried that the issue could present itself again in the production system.
So far, here’s following information we’ve collected:
- Content of
/etc/hosts - Content of
/etc/resolv.conf - Output of
iptables-save - pcap file collected using the
ngrepcommand - And with all that information, we are ready to start the "sleuthing" part of our troubleshooting.
Our first steps
The first thing we do is check the logs and status of the metadata server to ensure it is working correctly. It is. The metadata server responds to the 169.254.169.254 IP address and is responsible, among other things, for resolving the domain names. We also double check that the firewall rules applied to the VM are correct and not blocking packets.
This issue is weird. Until now, our only hypothesis had been that UDP packets are being dropped, but the output of nmap now proves that they are not. We mentally come up with some more hypotheses and ways to verify them:
Are packets being selectively dropped? => check iptable rules
Is the MTU too small? => check output of
ip a showIs the problem UDP-only or does it also involve TCP? => run
dig +tcpAre packets generated by dig not coming back? => run
tcpdumpIs libdns working properly? => run
straceto check it is actually sending and receiving packets
The current owner of the case asks for suggestions, so we decide to jump on a call with the customer to do some live troubleshooting.
During the call we test a few more things:
We flush iptables rules without success.
We check network interfaces and routing tables. We double-check that the MTU is correct.
We find out that
dig +tcp google.com(TCP) works, butdig google.com(UDP) does not.We run
tcpdumpwhile running“dig”, and we see that UDP packets are coming back.We run
strace dig google.comand we see that dig correctly callssendmsg()andrecvmsg()but that the latter times out.
It’s the end of our shift, so unfortunately we have to let go of the case to a different timezone. The case is already famous in our team, and a colleague suggests using the python scapy module to create a raw DNS packet:
This snippet creates a DNS packet and sends a request to the metadata server.
The customer runs the code, the DNS reply comes back and the application receives it! This confirms that the problem cannot be on the network layer.
After another spin around the world the case comes back to our team. I decide that it’s better for the customer if the case stops spinning around the world, so I will keep the case from here on out.
In the meantime, the customer kindly agrees to provide a snapshot of the image. This is incredibly good news: being able to test the image myself makes troubleshooting very quick—no need to ask the customer to run commands, send me the output and analyze it, I can do everything live!
My colleagues are getting jealous. We talk about the case at lunch and nobody has any idea of what is happening yet. Luckily, the customer isn’t in too much of a hurry because they have a mitigation, so we have more time to investigate. And because we have the image, we can do all the testing we want. This is fun!
Taking a step back
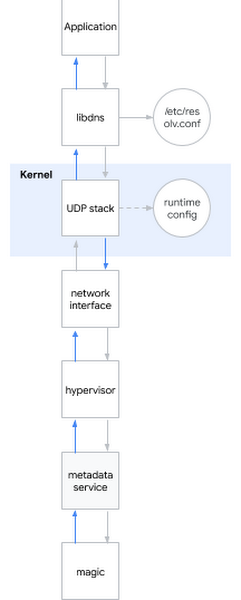
A very famous interview question to ask systems engineers is “What happens when you run ping www.google.com?” This is an excellent question because it requires the interviewee to describe the path from the shell, to userland, to the kernel and on to the network. I smile: sometimes interview questions are actually useful in real life...
I decide to apply this question to the problem at hand. Roughly speaking, when you try to resolve a DNS name this is what happens:
The application calls some system library (for instance libdns).
libdns checks the system configuration to know which DNS server to interrogate (in this diagram: 169.254.169.254, the metadata server).
libdns uses system calls to create a UDP socket (SOCKET_DGRAM) and to send and receive UDP packets containing the DNS request.
The UDP stack can be configured at kernel level using the sysctl interface.
The kernel interacts with the hardware to send the packet(s) on the network using the network interface.
When contacting the metadata server, the packet is actually captured by the hypervisor, who sends it to the metadata server.
The metadata server does some magic to actually resolve the name and then sends back the reply in the same way.
To recap, we have considered the following hypotheses:
Hypothesis: The libraries are broken
Test 1: run strace in the impacted system, check if dig is calling the correct system calls
Result: correct syscalls are invoked
Test 2: use scapy to check if we can resolve names bypassing OS system libraries
Result: resolution via scapy works
Test 3: run rpm -V on the libdns package and md5sum on the library files
Result: library code is exactly the same as the one in a working operating system
Test 4: mount the customer image's root filesystem on a VM where the behavior is not present, run chroot, see if DNS resolution works
Result: DNS resolution works
Conclusion: from Tests 1-4, the libraries are not the problem
Hypothesis: The DNS resolution is misconfigured
Test 1: inspect tcpdump to see whether DNS packets sent and received after running “dig” are correct
Result: they are correct
Test 2: double check
/etc/nsswitch.confand/etc/resolv.confon the serverResult: they are correct
Conclusion: from Tests 1-2, the DNS configuration is not the problem
Hypothesis: The kernel is broken
Test: install a new kernel, verify the signature, restart
Result: same behavior
Hypothesis: The customer’s network (or the hypervisor network interface) is misbehaving
Test 1: check firewall configuration
Result: firewall configuration (both in-host and on GCP) allows DNS packets
Test 2: capture the traffic to check DNS requests are correctly sent and replies received
Result: tcpdump shows reply packets are received by the host
Conclusion: from Tests 1-2, the network is not the problem.
Hypothesis: The metadata server is not working
Test 1: check metadata server logs for anomalies
Result: no anomalies in the metadata server logs
Test 2: bypass the metadata server by using
dig @8.8.8.8Result: resolution fails even when metadata server is not used
Conclusion: from Test 1-2, the metadata server is not the problem.
Final conclusion: our hypotheses tested multiple subsystems, except the runtime configuration!
Digging into the kernel runtime config
To configure the kernel runtime, you can use command line options (grub) or the sysctl interface. I look in /etc/sysctl.conf, and lo and behold, there are several custom configurations. I feel like I’m on to something. I ignore all options that are not network related or tcp-only. What remains is a bunch of net.core configurations. I then take a VM where host resolution works and apply all the settings from the broken VM, one by one. Eventually, I find the culprit:
This is the setting that finally breaks DNS resolution! I’ve found the smoking gun. But why? I need a motive.
net.core.rmem_default is how you set the default receive buffer size for UDP packets. A common value is something around 200KiB, but if your server receives a lot of UDP packets you might want to increase the buffer size. If the buffer is full when a new packet arrives, because the application was not fast enough to consume them, then you will lose packets. The customer was running an application to collect metrics that were sent as UDP packets, so they had correctly increased the buffer to ensure they didn’t lose any data points. And they had set this value to the highest value possible: 2^31 - 1 (if you try and set it to 2^31 the kernel returns “INVALID ARGUMENT”).
Suddenly I realize why nmap and scapy were working correctly: they use raw sockets! Raw sockets are different than normal sockets: they bypass iptables, and they are not buffered!
But why is having *too big of a buffer* causing issues? It is clearly not working as intended.
At this point I can reproduce the issue on multiple kernels and multiple distributions. The issue was present already in kernel 3.x and is present now on kernel 5.x. Indeed, if you run
then DNS stops working.
I start to look for a value that works. Using a simple binary search algorithm, I find that 2147481343 seems to do the trick. This number doesn't make any sense to me. I suggest the customer try this number. The customer replies back: it works with google.com, but it does not work with other domains. I continue my investigation.
I install dropwatch, a tool that shows you where in the kernel a packet is dropped. I should have used it earlier. The guilty function is udp_queue_rcv_skb. So I download kernel sources and add a few printk functions, to follow where, exactly, the packet is dropped. I quickly find the specific if condition that fails. I stare at it for a while, and it all comes together: the 2^31-1, the number that doesn’t make any sense, the domain that doesn’t work. It’s a bit of code in __udp_enqueue_schedule_skb:
Please note that:
rmemis of type int.sizeis of type u16 (unsigned int 16 bit) and stores the size of the packet.sk->sk_rcvbufis of type int and stores the size of the buffer which is, by default, equal to the value innet.core.rmem_default.
When sk_rcvbuf gets close to 2^31, adding the size of the packet can cause an integer overflow. And since it’s an int it becomes a negative number, therefore the condition is true when it should be false (for more, also check out this discussion of signed magnitude representation).
The fix is trivial: cast to unsigned int. I apply the fix, and reboot. DNS resolution works again.
The thrill of victory
I send my findings to the customer and send a kernel patch to LKML. I feel happy: every single piece of the puzzle has finally come together. I can explain exactly why we observed what we observed. But more importantly, by working together, we were able to fix the problem!
Admittedly, this was a very rare case. And thankfully, very few support cases that we work on are this complicated, so we can close them much more quickly. By reading through this support case, though, hopefully you can gain an understanding of how we approach our work, and how you can help us help you resolve your support cases as fast as possible. If you enjoyed this blog post, email us at cloud-support-blog@google.com and we’ll dig around in our greatest hits archive for other tough support cases to discuss.





