Google の Tensor Processing Unit (TPU) で機械学習が 30 倍速くなるメカニズム
Google Cloud Japan Team
* この投稿は米国時間 5 月 12 日に投稿されたもの(投稿はこちら)の抄訳です。
Posted by
佐藤一憲, Staff Developer Advocate, Google Cloud
Cliff Young, Software Engineer, Google Brain
David Patterson, Distinguished Engineer, Google Brain
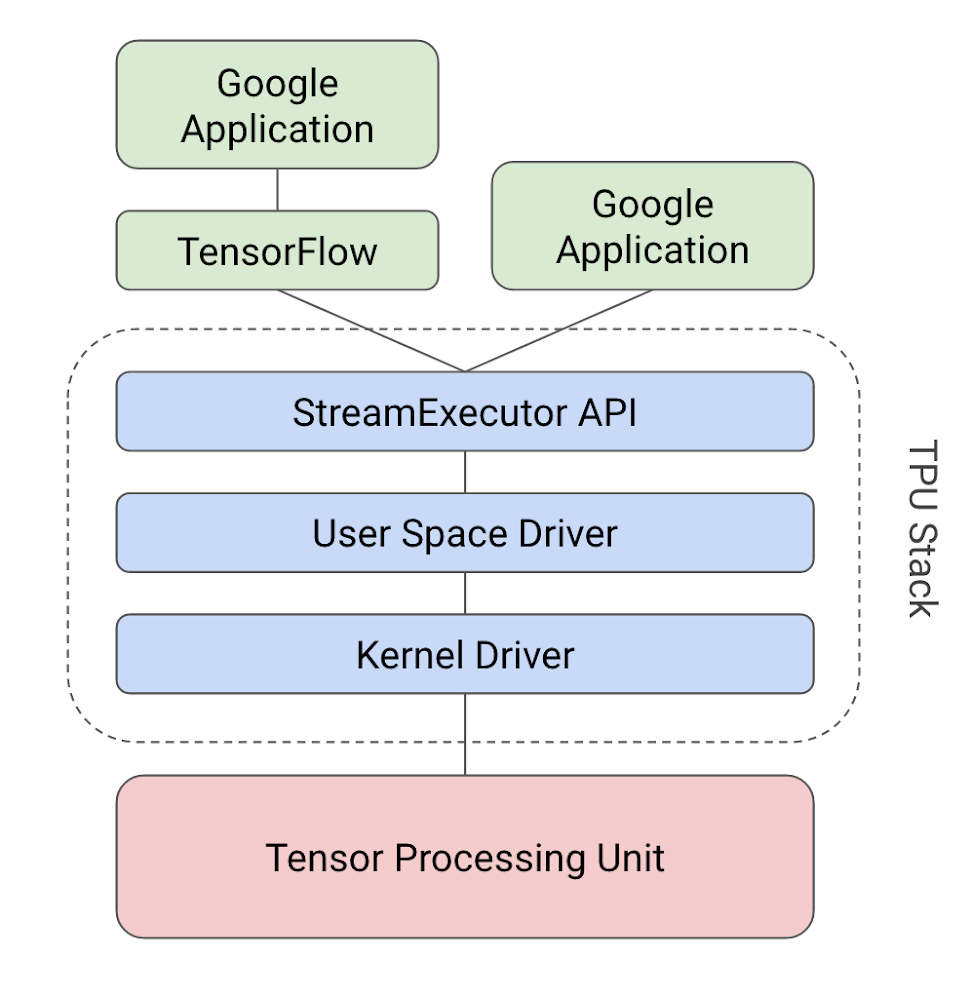
Google 検索、ストリートビュー、Google フォト、そしてGoogle 翻訳。これらのサービスに共通するのは、いずれもニューラルネットワーク(NN)の計算処理の高速化のために Google の第一世代の Tensor Processing Unit (TPU) が用いられている点です。

Google の第一世代 TPU は、昨年の Google I/O で初めて紹介され、今年 4 月にはその性能やアーキテクチャについて詳細に解説した論文が公開されました。TPU は、一般的な CPU や GPU を用いて NN の計算処理を行う場合と比較して、15 〜 30 倍の性能と、30 〜 80 倍の電力性能比を提供します。この大幅な性能改善のおかげで、Google の数多くのサービスにおいて最新の NN を大規模かつ低いコストで提供可能となっています。
本記事では、この Google の TPU の内部で用いられているテクノロジーを掘り下げ、このケタ違いの性能がどのようにして実現されているのか解説します。
TPU が生まれるまで
NN 専用の ASIC(特定用途向け LSI)を Google 自ら開発しよう、というアイディアは、2006 年のころから議論されていました。しかし議論が本格化したのは 2013 年のことです。Google データセンター内での NN 利用が爆発的に拡大し、このままでは当時の全データセンターの 2 倍に相当する計算能力がまもなく必要となることが判明したからです。通常、ASIC をゼロから開発するには数年の期間を要します。しかし TPU の場合は、デジタル回路の設計に始まり、検証、製作、そしてデータセンターへの導入までわずか 15 か月で完了しています。TPU プロジェクトの技術リーダーを担当した Norm Jouppi(MIPSプロセッサの主任アーキテクトとしても知られる)は、当時の慌ただしさをこう振り返ります。
TPU の開発はおそろしいスピードで進んで行きました。最初は回路設計エンジニア、その後は検証エンジニアと、エンジニアの採用とチップ開発を並行して進めていく忙しさです。しかし最初にできあがったチップ(ファーストシリコン)はまったく何の問題もなく動きました。
(First in-depth look at Google's TPU architecture, The Next Platform より)
TPU は 28nm プロセスで製造され、700MHz クロック、消費電力 40W の ASIC です。Google の既存のサーバーにできるだけ早く導入するため、SATA ハードディスク スロットにそのまま収まるアクセラレータカードの上に ASIC を搭載しました。サーバー本体との間は PCIe Gen3 x16 バスで接続され、12.5 GB/s の実効帯域で通信が可能です。
ニューラルネットワークの推論演算
TPU の設計思想を理解するために、まずは NN の動作にはどのような計算が必要とされるのかを見てみましょう。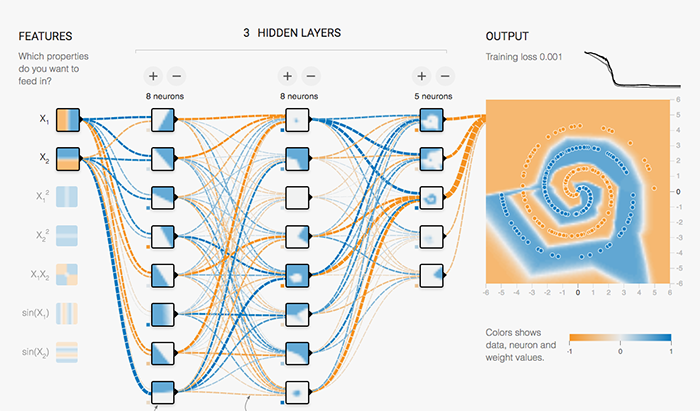
この TensorFlow Playground の例では、NN を学習させることで、画面右の平面上にある個々の点がブルーとオレンジのどちらのグループに属するか識別できるようになります(このデモについて詳しくはこの記事を見てください)。
こうして学習させた NN を実際に使い、データを分類したり未知の値を推測したりすることを推論(inference)と呼びます。推論では、NN に含まれる個々のニューロンについて以下の計算処理を行います。
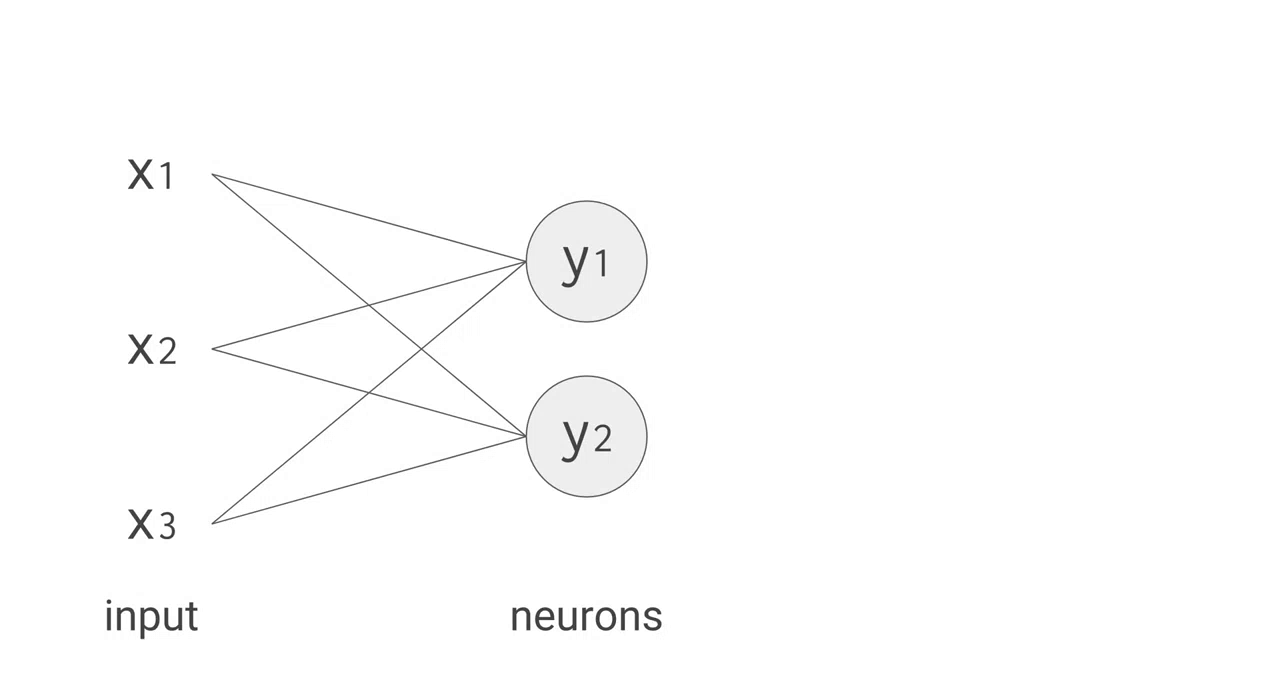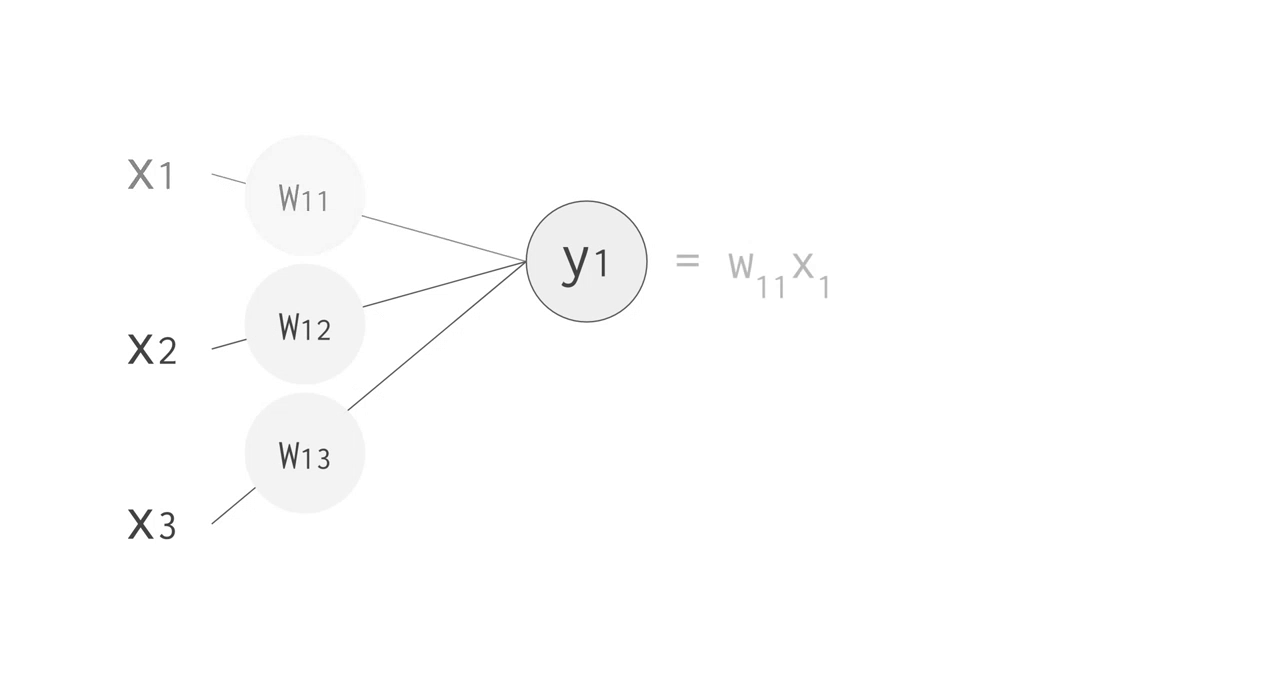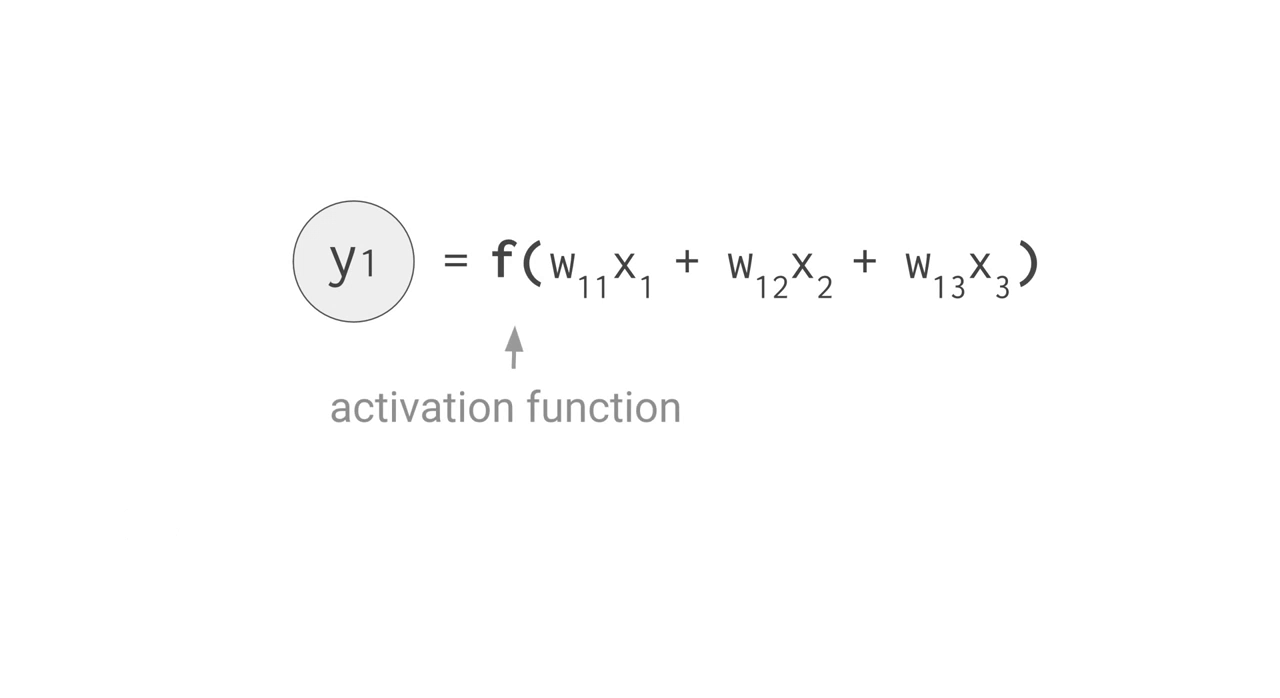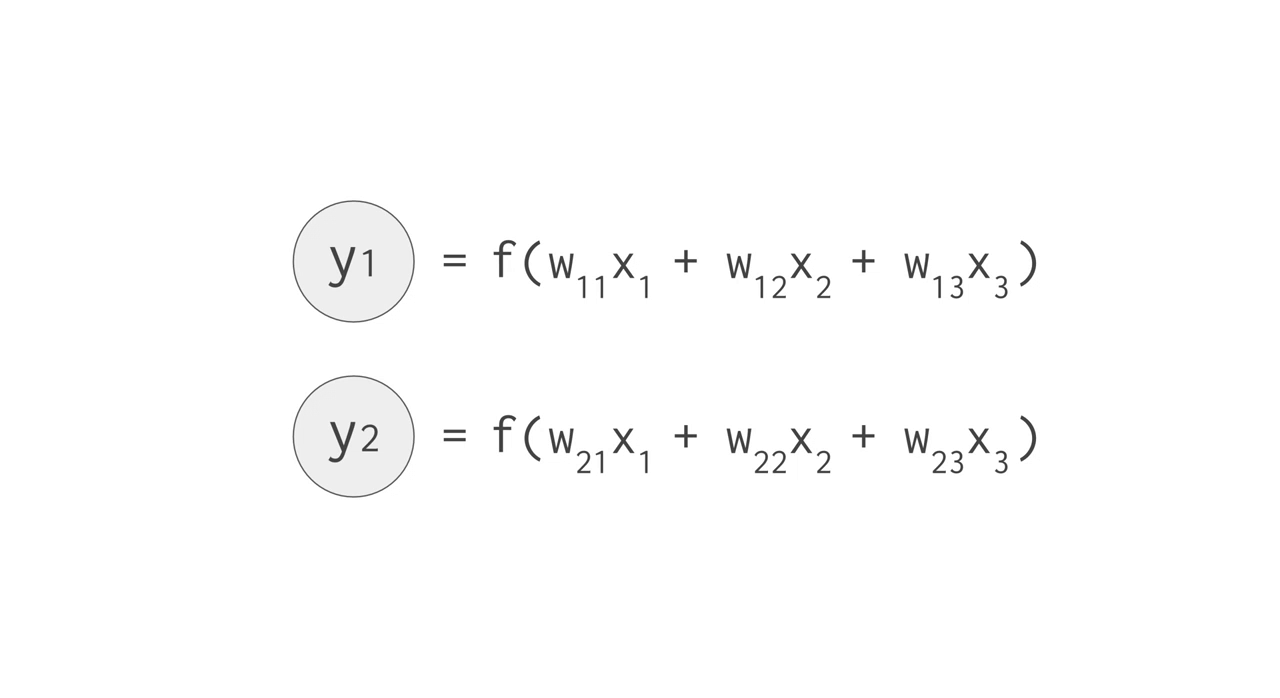
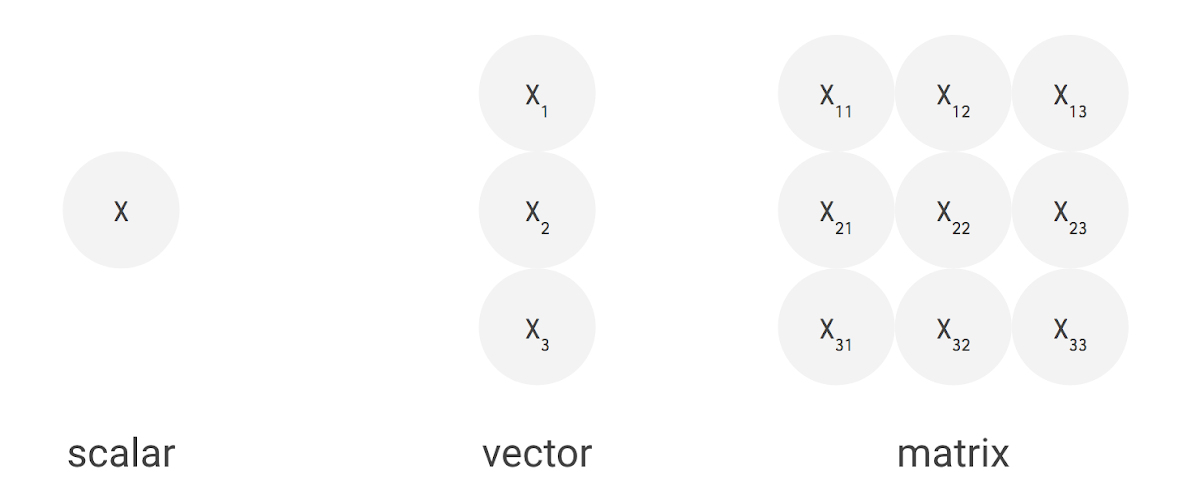
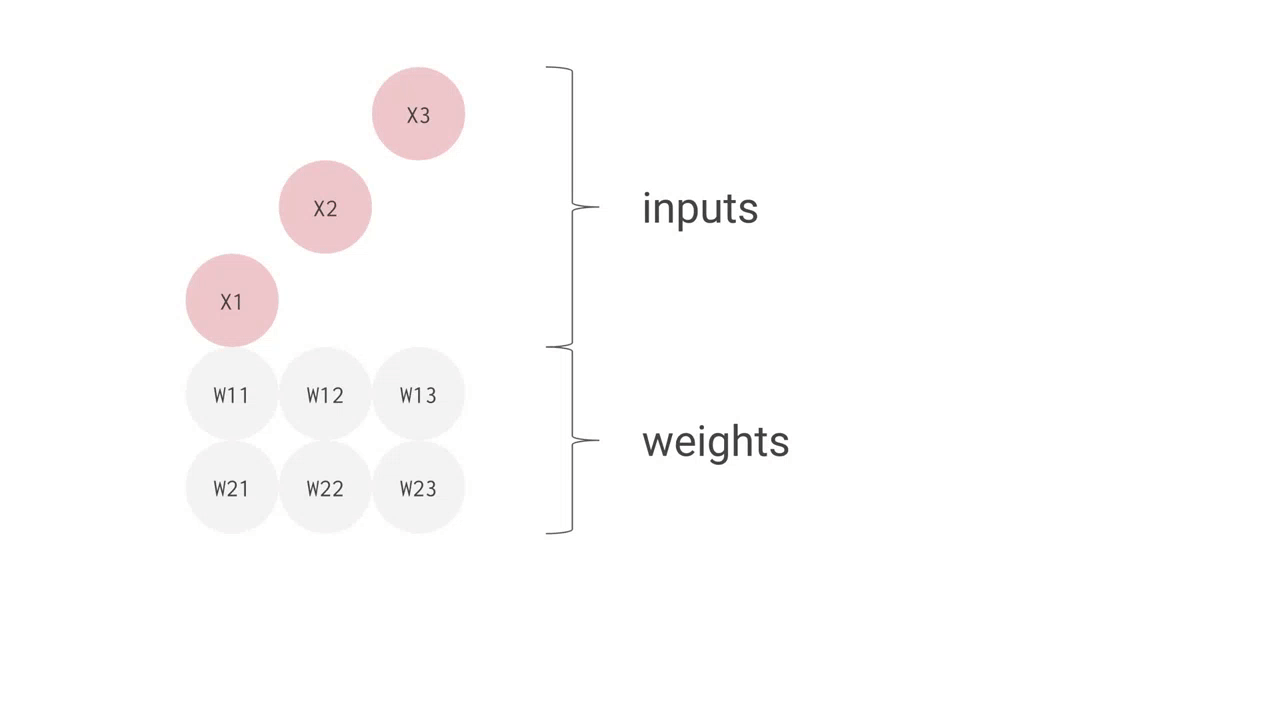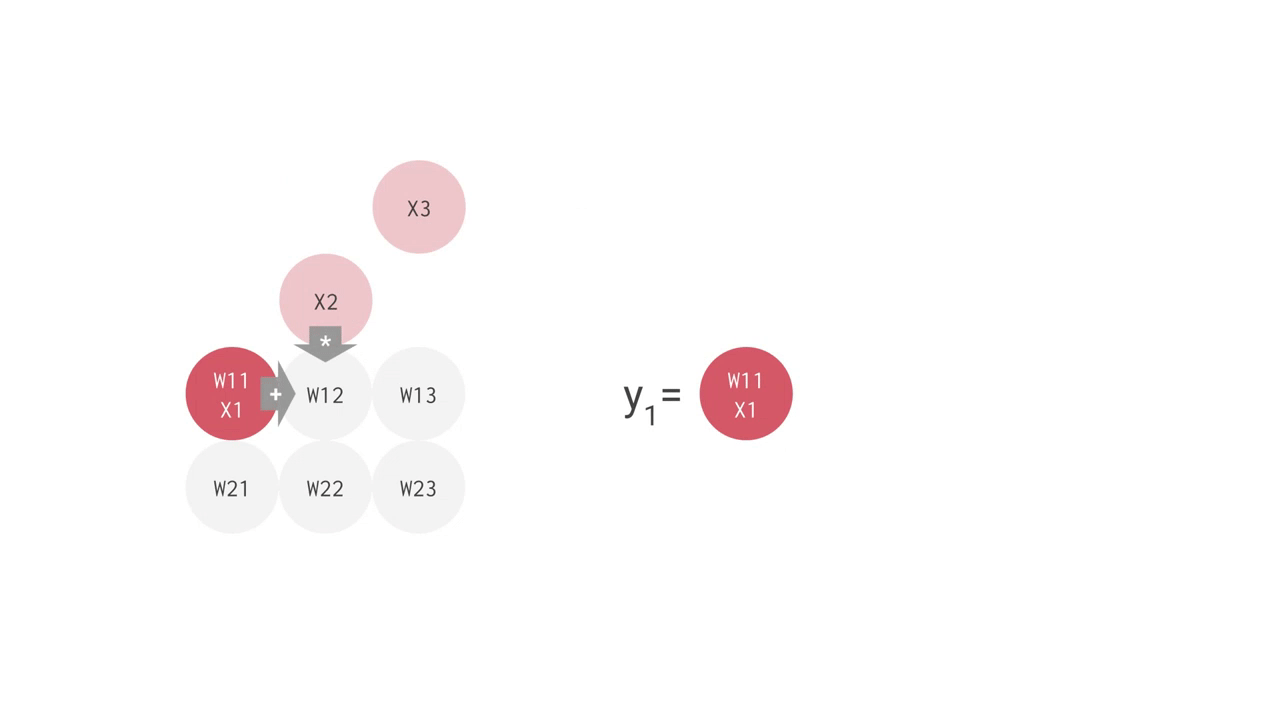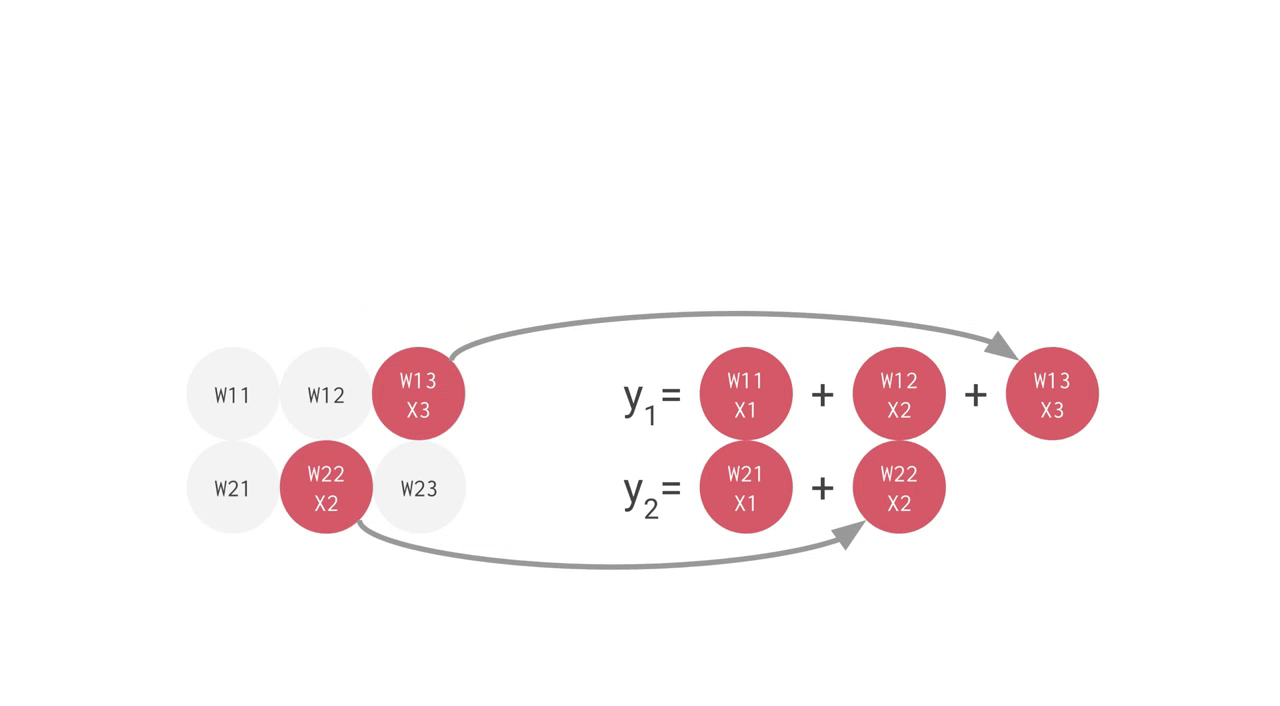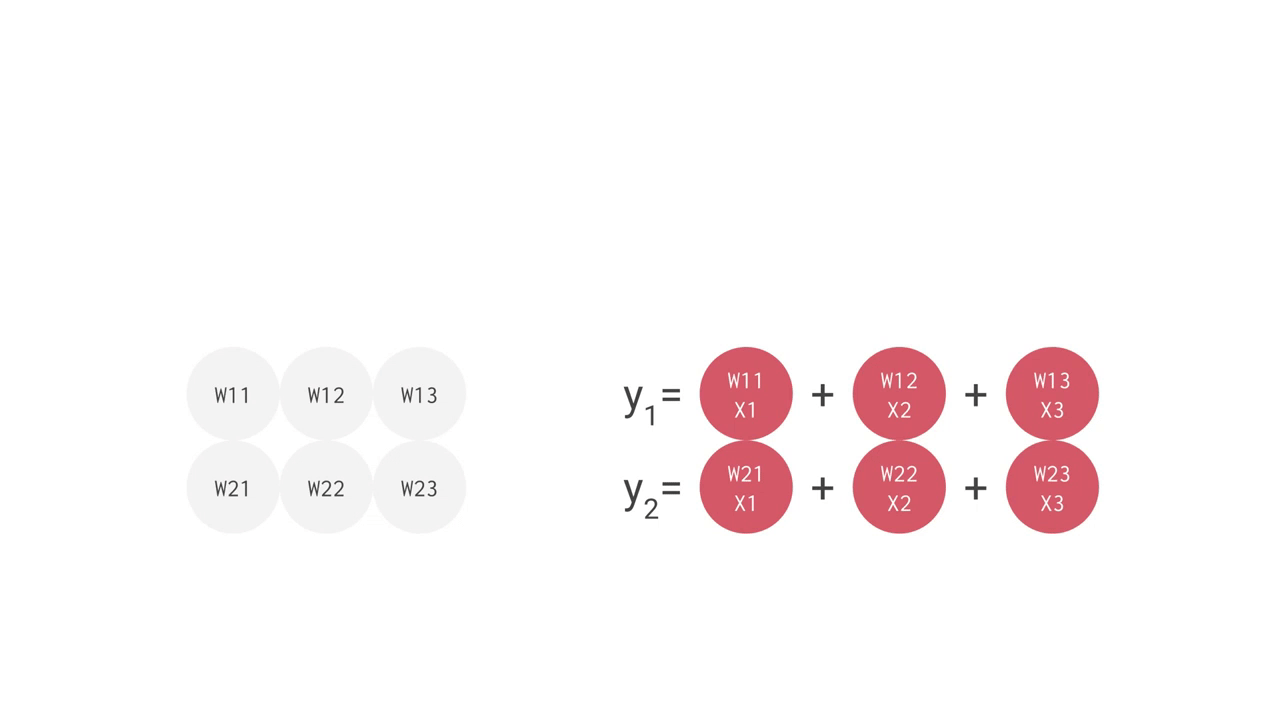
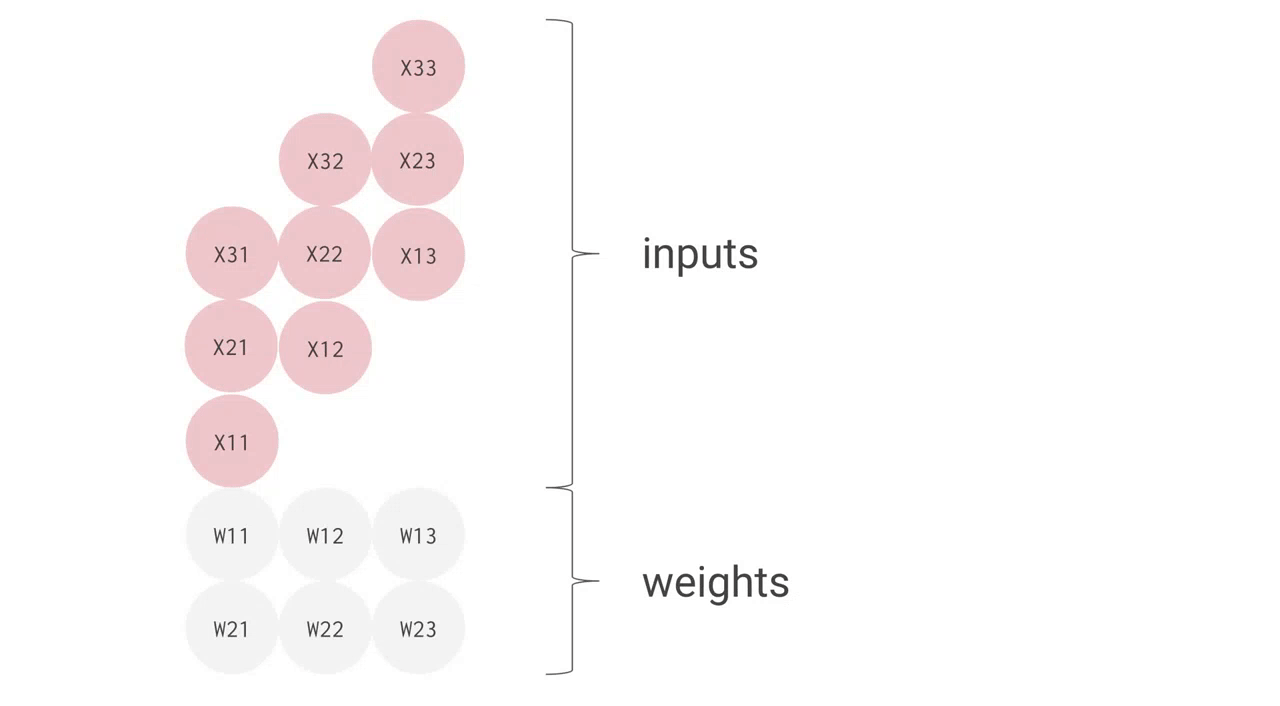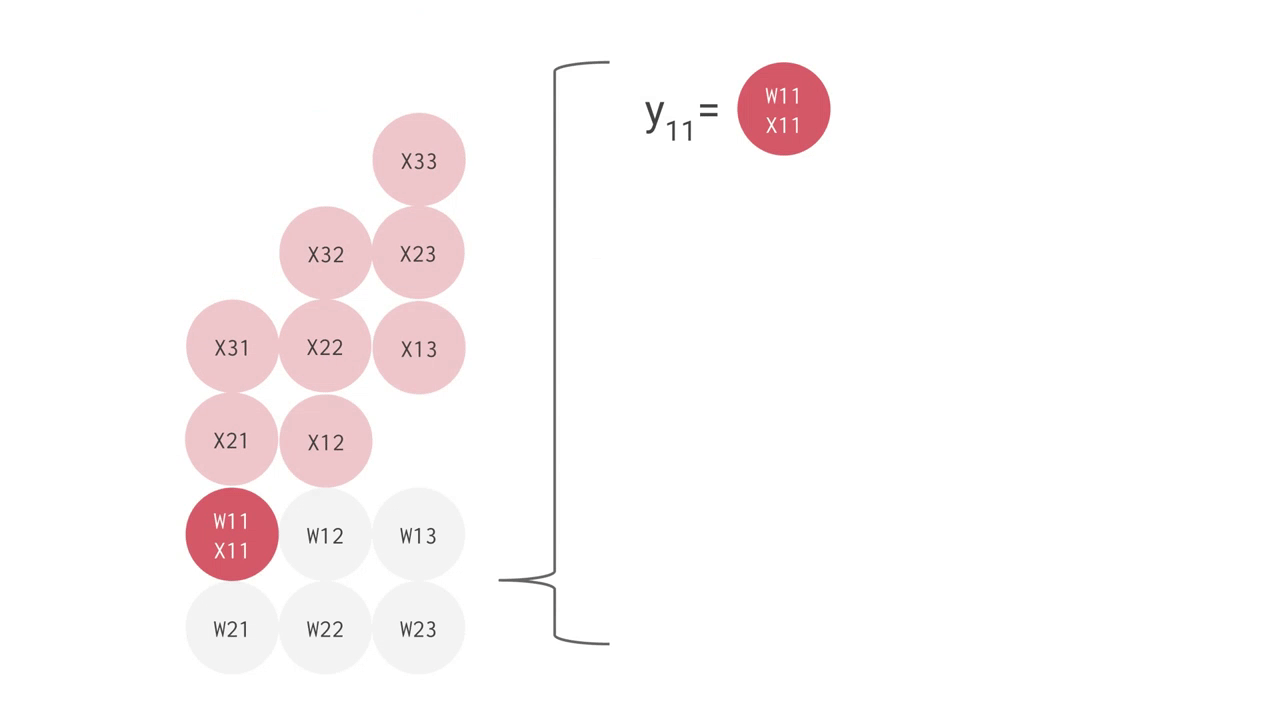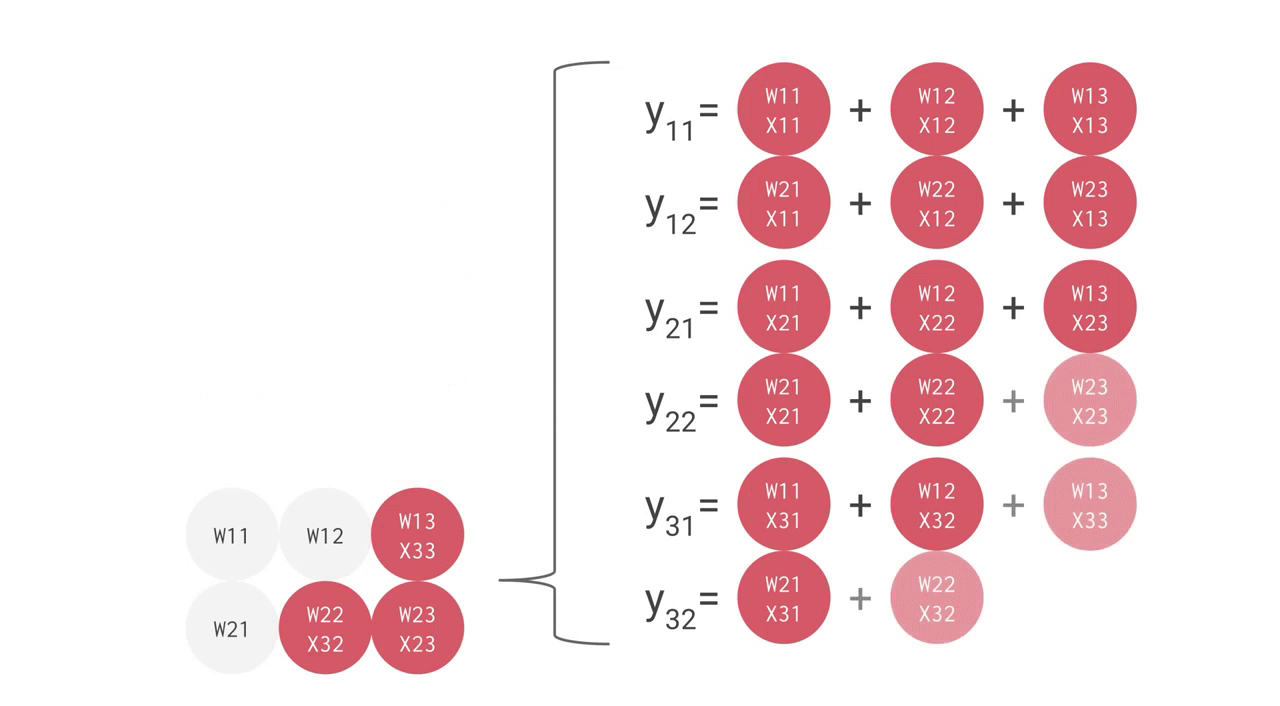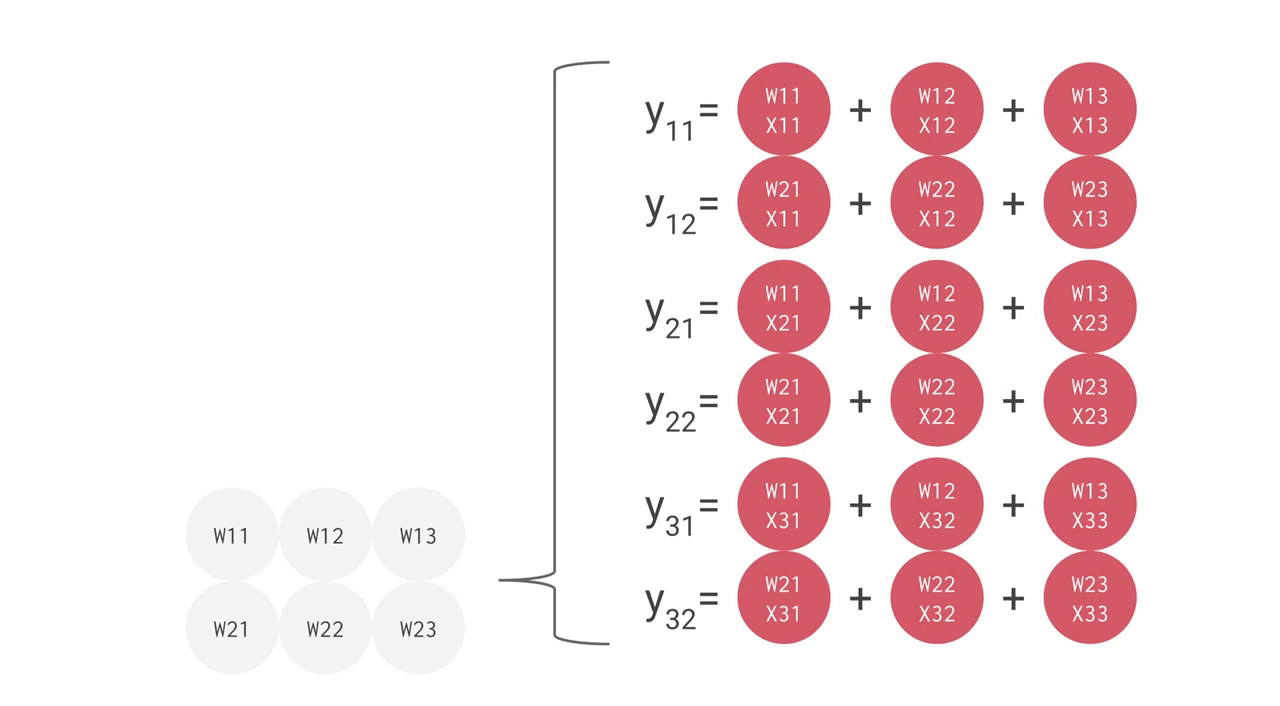
例えば、上手のように 3 つの入力値と 2 つのニューロンからなる全結合型の単層 NN の場合、合計で 6 回の掛け算を入力とパラメータの間で行い、その結果を合計して 2 つの出力を得ます。この乗算と加算は、行列積(matrix multiplication)として表すことができます。その結果が活性化関数に渡される流れです。より複雑な構造の NN の場合でも、この行列積が計算処理でもっとも負荷の高い部分となります。
では、実運用環境ではどれくらいの量の行列積が必要とされるのでしょうか。2016 年 7 月、Google では実運用サービスで利用されるおもな 6 種類の NN アプリケーションについて、それらのパラメータの数を集計しました。以下の表にその結果がまとめられています。
| NN の種類 | NN の層の数 | パラメータの数 | 導入規模 |
| MLP0 | 5 | 20M | 61% |
| MLP1 | 4 | 5M | |
| LSTM0 | 58 | 52M | 29% |
| LSTM1 | 56 | 34M | |
| CNN0 | 16 | 8M | 5% |
| CNN1 | 89 | 100M |
この表にある通り、個々の NN には 500 万〜 1 億個のパラメータが含まれます。NN を用いて推論を 1 回実行するには、これらのパラメータと入力データの間で乗算と加算を繰り返し、さらに活性化関数を適用する必要があります。
つまり NN を使おうとするたびに、数 100 万〜数 1000 万回の演算を繰り返さなくてはなりません。そこで TPU では、この膨大な演算を一般的な 32-bit や 16-bit の浮動小数点演算として CPU や GPU で実行する代わりに、よりサイズが小さくて高速な整数演算で置き換える量子化(quantization)と呼ばれる手法を導入しました。これにより、NN の推論に必要とされるメモリと計算資源を大幅に節約できます。
ニューラルネットワークの量子化
例えば外出中に雨が降り出したら、それが小雨なのか本降りなのかは気になりますが、「毎秒いくつの雨粒が地表に届いているか」まで気にする人はいません。これと同じように、NN の推論も実は 32-bit や 16-bit といった計算精度を必要としないケースが大半です。ちょっとした工夫により、8-bit の整数演算でも十分な推論精度を得られます。
NN の量子化は、あらかじめ設定した最大値と最小値の間の値を 8-bit 整数で表し、パラメータのサイズを圧縮する手法です。より詳しくは、How to Quantize Neural Networks with TensorFlow で解説されています。
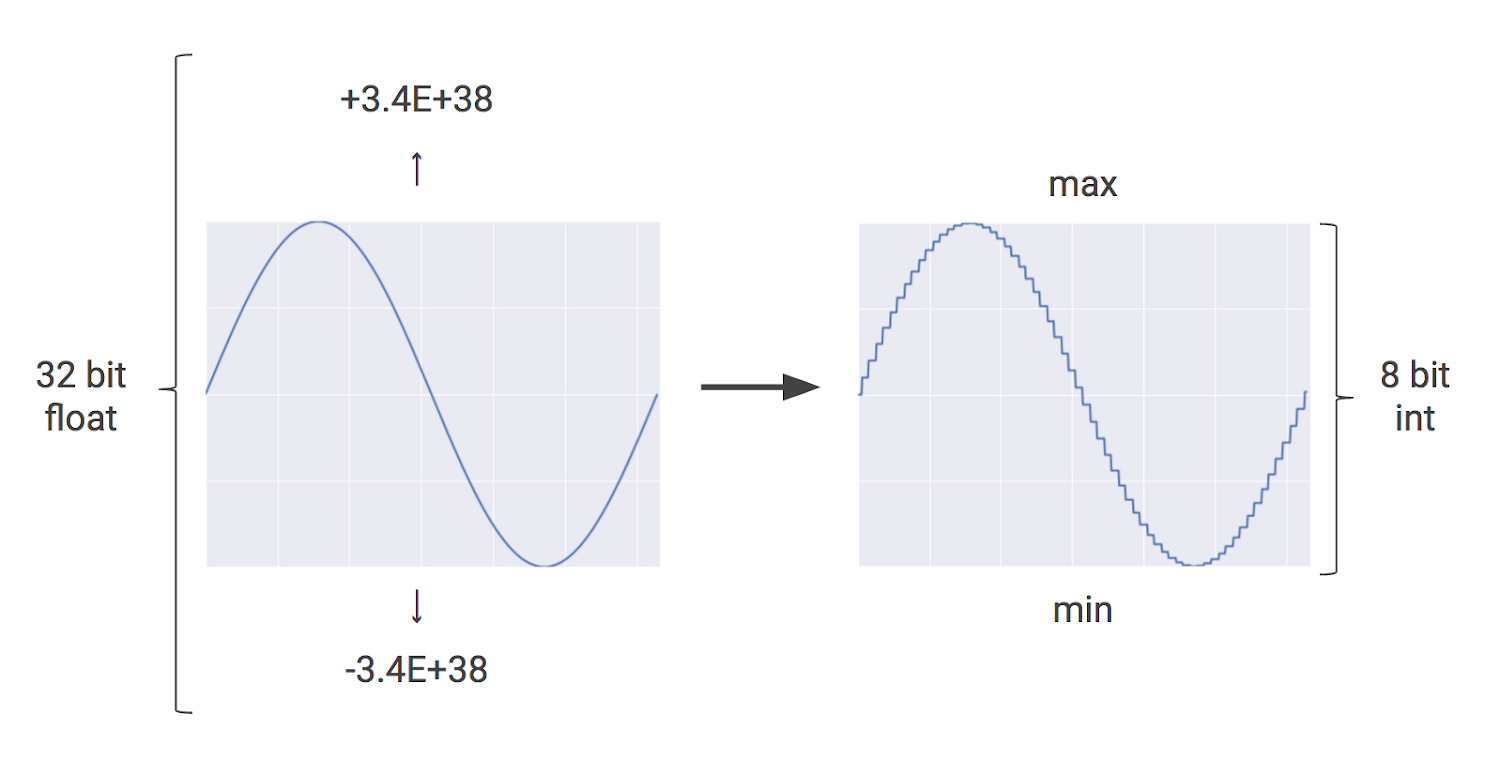
この量子化を用いることで、NN の推論に必要な計算コストを大幅に下げられます。特にスマートフォンや組み込みシステムでの NN 導入には重要な技術です。例えば、広く使われている画像認識 NN モデルである Inception モデルの場合、もともと 91 MB あるパラメータのサイズを、量子化によって 1/4 の 23 MBまで縮小できます。
メモリサイズだけではありません。浮動小数点演算を整数演算で置き換えることで、デジタル回路のサイズと電力消費を大幅に抑えられます。例えば、一般的な GPU は数 1000 個の 32-bit 浮動小数点乗算器を搭載する一方で、 TPU は 65,536 個の 8-bit 整数乗算器を搭載しています。つまり、推論精度のわずかな違いを許容するだけで 25 倍を超える数の乗算器を載せられるのです。
RISC と CISC と TPU の命令セット
TPU のもうひとつの重要な設計目標が、プログラマブルであることです。TPU は、どれか特定種類の NN のみ動かせるよう設計されているわけではありません。様々に異なる種類の NN モデルの計算処理を高速化できる柔軟性を備えています。
現代の多くの CPU は、 Reduced Instruction Set Computer (RISC) と呼ばれる設計思想に多大な影響を受けています。RISC CPU では、数多くのアプリケーションで共通して用いられる少数の簡単な命令(ロード、ストア、加算、乗算など)を命令セットとして定義し、それらをできるだけ高速に実行すべく CPU を設計します。一方、TPU では Complex Instruction Set Computer (CISC) と呼ばれる設計思想のもとで命令セットが定義されています。CISC では、より複雑な処理(乗算と加算を多数繰り返すなど)を個々の命令で実行できます。以下は、TPU のブロック図です。
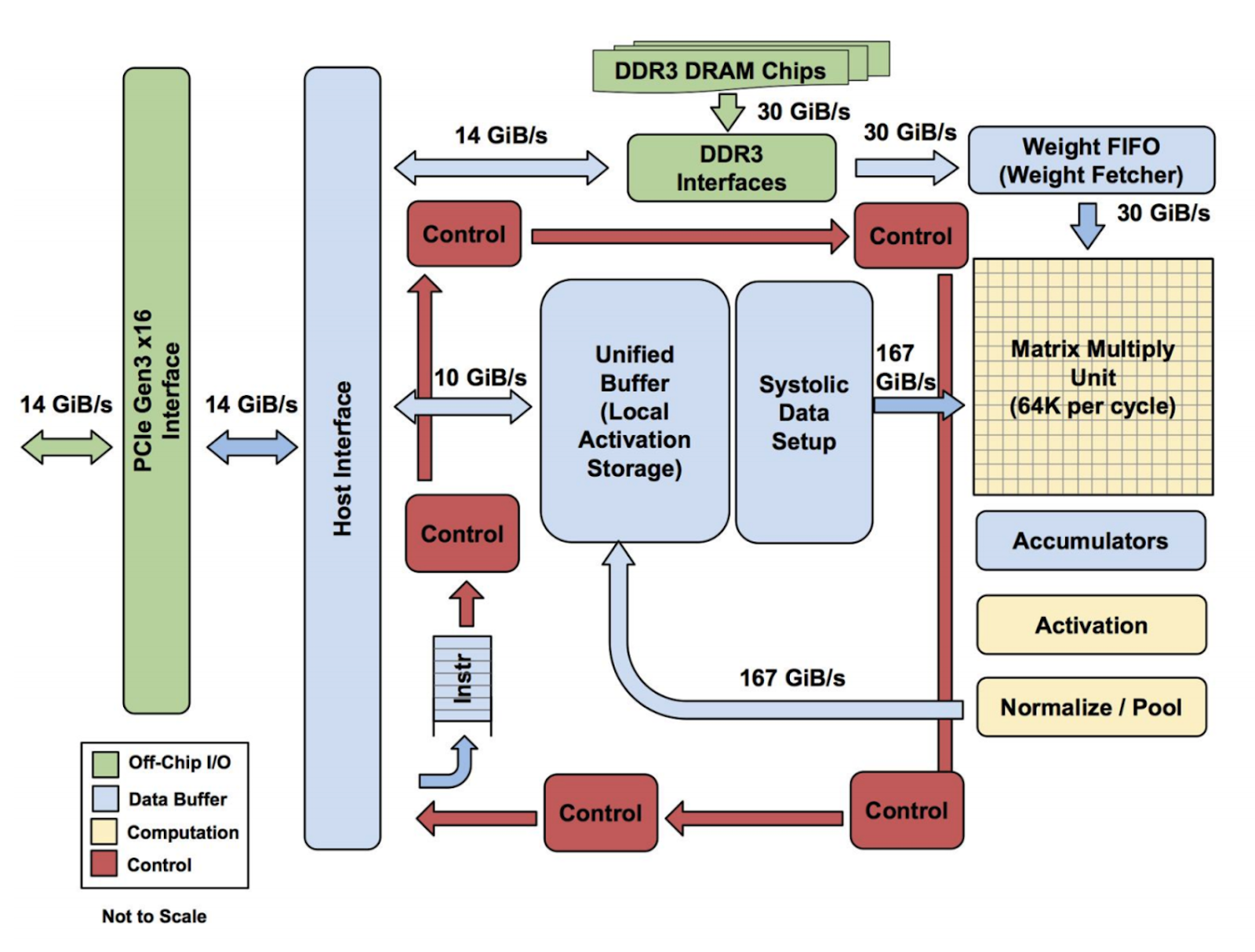
TPU には、おもな計算リソースとして以下の要素が配置されています。
- Matrix Multiplier Unit (MXU):行列演算用の 65,536 個の 8-bit 積和演算器
- Unified Buffer (UB): 24MB SRAM レジスタ
- Activation Unit (AU): ハードウェアで実装された活性化関数
| TPU 命令 | 機能 |
| Read_Host_Memory | メモリからのデータ読み込み |
| Read_Weights | メモリからのパラメータ読み込み |
| MatrixMultiply/Convolve | データとパラメータ間の乗算と畳込み、および結果の加算 |
| Activate | 活性化関数の適用 |
| Write_Host_Memory | メモリへの結果の書き込み |
この TPU 命令セットは、先に説明したような入力データとパラメータ間の乗算と活性化関数の適用など、 NN の推論に必要な計算処理に特化した命令セットとして定義されています。
この TPU のアーキテクチャについて、Norm は以下のように説明しています。
全結合 NNや畳み込み NN などいろいろな種類がありますが、要するに NN の計算とは様々なサイズの行列演算の集まりです。たくさんの乗算と加算の結果を活性化関数へと流し込むことで、たくさんの線形演算の積み重ねから非線形なふるまいを得る。これが NN の本質であり、TPU のアーキテクチャはそれをハードウェアで表現したものです。
(First in-depth look at Google's TPU architecture, the Next Platform より)
つまり TPU は、NN 計算のエッセンスとなるロジックをハードウェアで実装し、あらゆる NN モデルを表現できるプログラミング能力を備えています。また TPU のプログラミング環境として、Google では TensorFlow グラフからの API コールを TPU 命令へ変換するコンパイラとソフトウェア スタックを開発しました。
Matrix Multiplier Unit による大規模並列処理
一般的な RISC CPU は、数値の乗算や加算といった単純な演算のための命令セットを備えます。こうしたプロセッサは、個々の命令ごとに単一の演算(スカラ値の演算)を実行するため、スカラ プロセッサ(scalar processor)も呼ばれます。
現代の CPU はギガヘルツ単位のクロックで動作するとはいえ、大規模な行列演算をスカラ プロセッサによる繰り返し処理でこなすにはとても長い時間がかかってしまいます。そこでそうした行列演算に対しては、たくさんのデータを同時並列に演算するベクタ プロセッサ(vector processor)がよく用いられます。CPU がサポートする SSEや AVX などは、そうしたベクタ 演算命令セットの例です。また GPU が備える SM(streaming multiprocessors)も、1 つの GPUチップ上に数 1000 個のSMを並べることで、実質的にベクタ プロセッサとして動作します。これらのベクタ プロセッサを使えば、クロック サイクルごとに数 1000 回の演算を同時実行できます。
一方 TPU は、クロック サイクルごとに数 10 万回の演算が可能なマトリックス プロセッサ(matrix processor/行列プロセッサ)として設計されています。これを文書印刷で例えるなら、一文字ずつタイプするのか、一行ずつ印字するのか、一ページずつ印刷するのかの違いに相当します。

TPU の心臓部、シストリック アレイ
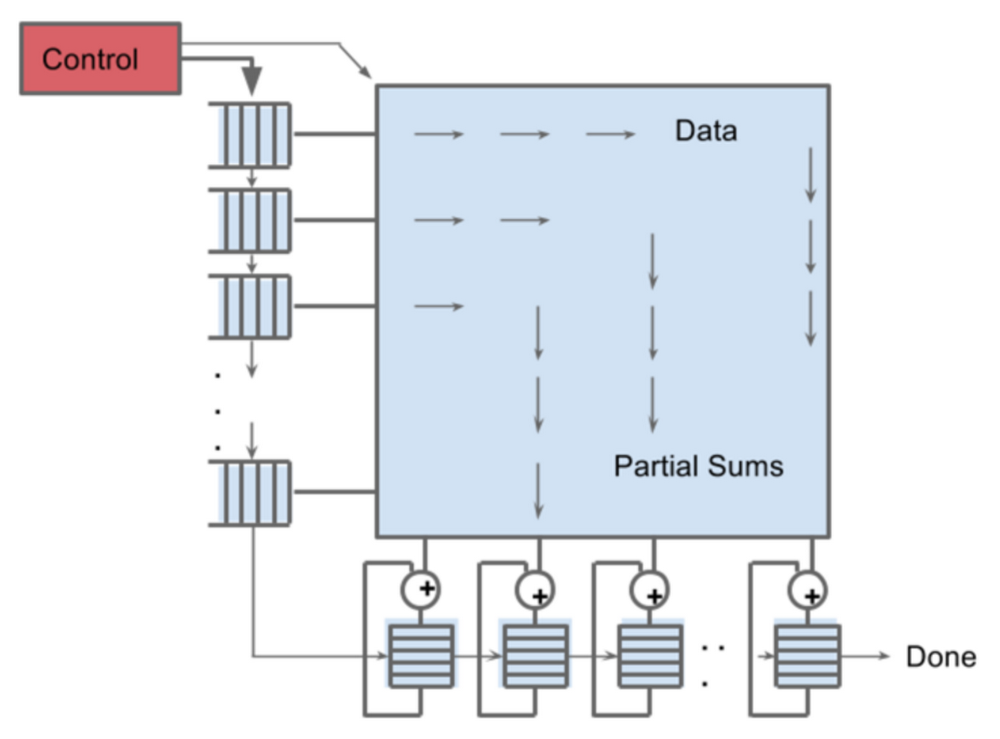
この大規模マトリックス プロセッサを実装する方法として、TPU では CPU や GPU とはまったく方法論の異なるアーキテクチャ、シストリック アレイを採用しています。
CPU は汎用コンピュータであり、あらゆる種類の情報処理をこなせるよう設計されています。その汎用性を得るために、プログラムコードの命令にもとづいて ALU(Arithmetic Logic Units/演算装置)行った乗算や加算、論理積などの演算結果は、レジスタに逐一保存するという設計になっています。レジスタ上のデータに対して、プログラムコードが読み書きや演算を行いながら一連の処理を進める流れです。
これらレジスタ・ALU・プログラムコードの 3 つは、あらゆる用途に使えるという CPU の汎用性を実現する上で欠かせない構成要素であるものの、同時に CPU の電力消費と回路規模をぐんと押し上げる原因にもなっています。
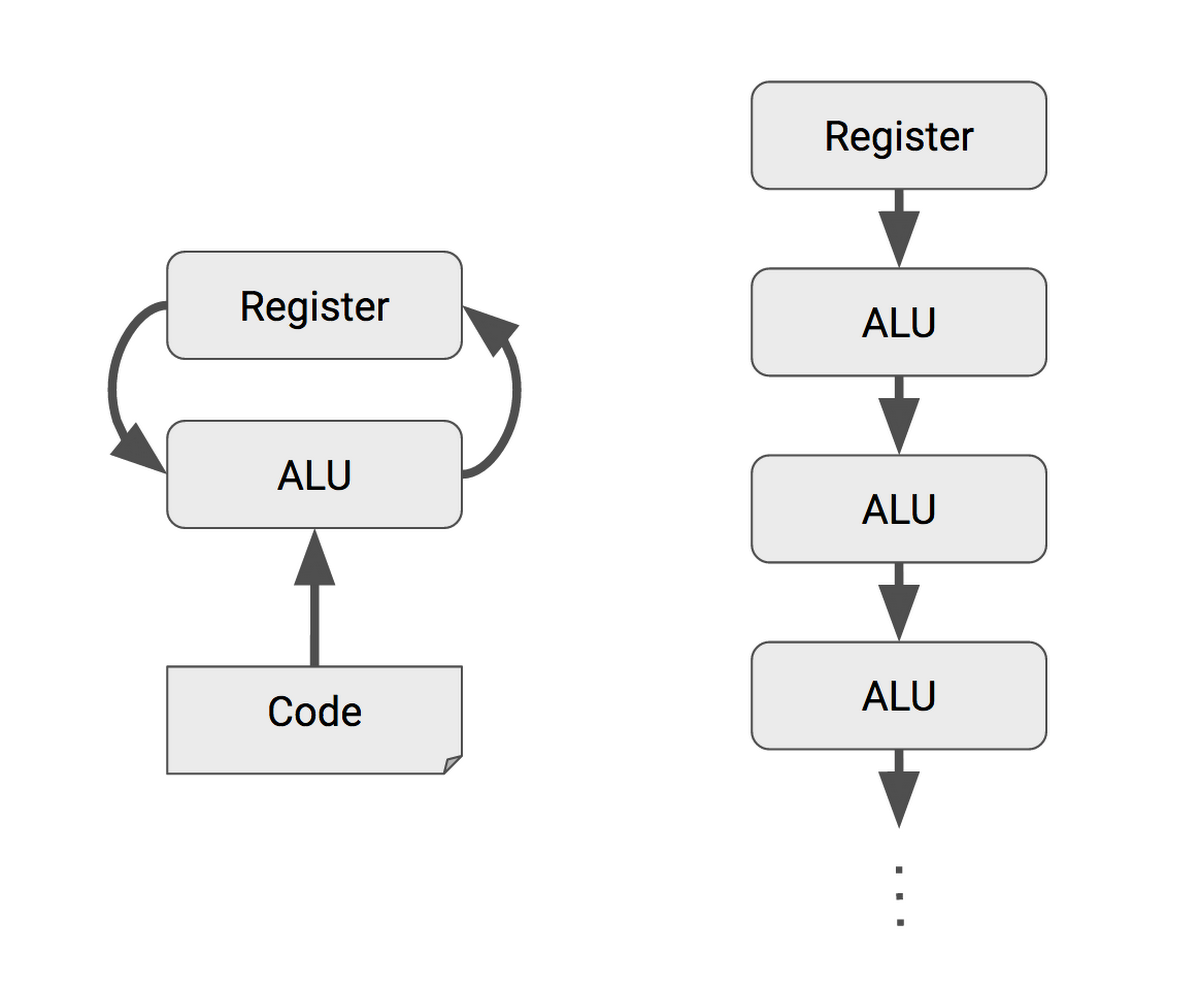
一方、TPU に備わるマトリックスプロセッサ MXU では、個々の ALU からの演算結果をレジスタに書き戻さず、次の演算の入力としてそのまま隣の ALU に渡すため、レジスタの読み書きは発生しません。MXU は NN の行列積と加算のためだけに設計されているので、多数の ALU を数珠つなぎにした非常にシンプルな回路構成を取ることができ、きわめて高い電力効率と演算速度を実現しています。
シストリック アレイのシストリックとは「心臓」を意味しており、あたかも心臓が血液を運ぶような動きでデータが演算器を流れるためそうした名前が付いています。MXU で用いられているシストリック アレイは、あらゆる種類の数値演算で高い性能を発揮できるわけではありません。これは設計上のトレードオフで、レジスタやプログラムコードがもたらす汎用性を制限する代わりに、もっとも高い電力効率と実装密度で行列積を計算するという目的に特化して設計されています。
MXU のシストリック アレイは、256 x 256 = 65,536 個の ALU を備えます。つまり、8-bit 整数による乗算と加算をクロックの 1 サイクルごとに 65,536 回分いちどに実行できます。TPU は 700 MHz クロックで動作するので、700 MHz x 65,356 = 46 x 1012 回の乗算と加算を 1 秒間に実行します(92 Teraops per second)。
では、CPU、GPU、TPU とで、1 サイクルあたりの演算回数を比較してみましょう。
| 1 サイクルあたりの演算回数 | |
| CPU | 1〜2 回 |
| CPU(ベクタ演算拡張) | 数 10 回 |
| GPU | 数万回 |
| TPU | 10 数万回(最大 12.8 万回) |
ベクタープロセッサを搭載しない一般的な RISC CPU の場合、1 命令あたりの演算回数は 1 〜 2 回程度に留まります。一方、GPU では 1 命令あたり数 1000 回の演算が可能。TPU では、例えば MatrixMultiply 命令の実行時には、1 サイクルあたり 10 数万回(最大 12.8 万回)の演算をこなします。
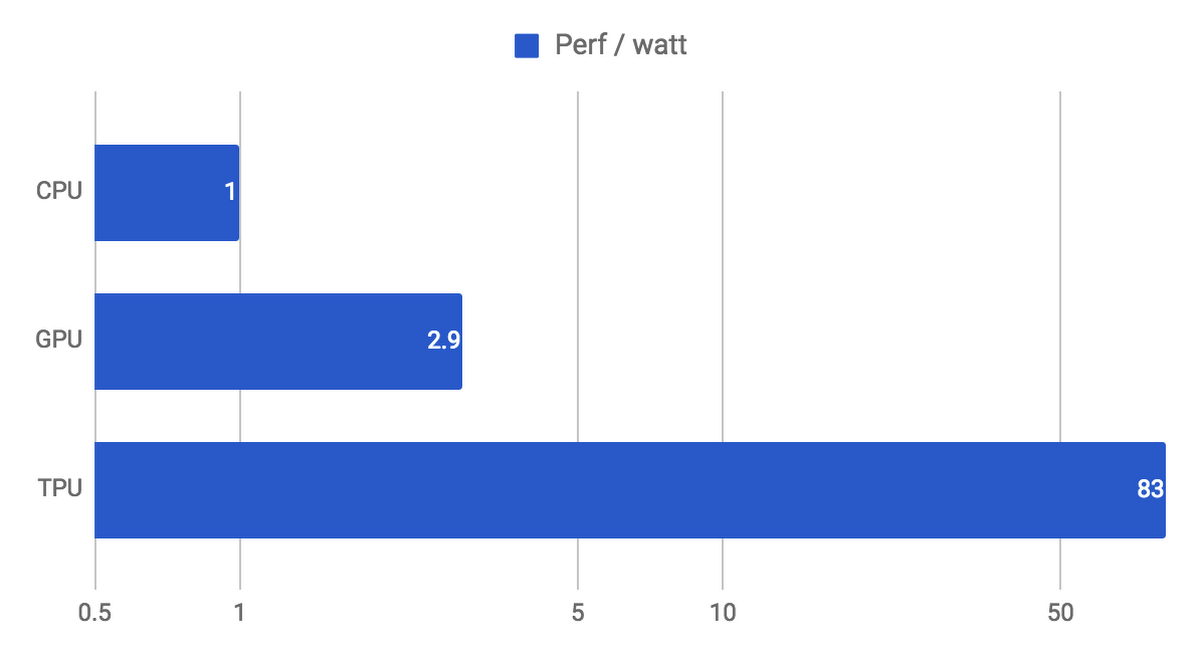
この莫大な規模の行列演算のあいだ、個々の演算結果は 64,535 個の ALU 間で直接渡されるので、レジスタの読み書きは発生しません。これにより、電力効率と演算スループットの劇的な向上が可能になります。この CISC ベースのマトリックス プロセッサ設計により、TPU は一般的な CPU に比べて 83 倍、GPU と比べて 29 倍というケタ違いの電力性能比を達成しています。
「7 ms」のためのミニマル設計
NN の推論専用プロセッサをゼロから開発することで得られる最大のメリットのひとつは、「ミニマリスト」設計に徹せることです。TPU の論文から以下に引用します。CPU や GPU は、現代の汎用プロセッサに必要とされる様々な機能を実装する複雑なアーキテクチャを備えます。例えば、キャッシュ、分岐予測、アウトオブオーダー実行、マルチスレッド、投機プリフェッチ、アドレス計算、コンテキスト スイッチ等々。これらの機構のために多くのトランジスタと電力が費やされていますが、いずれもプロセッサの平均性能を改善するだけで、99パーセンタイルの性能(=性能のばらつきの低さ)の改善にはあまり寄与しません。TPU はシングルスレッド動作の特定用途向けプロセッサであり、これらの機構をすべて廃したミニマルな設計による多大なメリットが得られます。(8ページ)
CPU や GPU などの汎用プロセッサは、ありとあらゆるアプリケーションを相手に一定の性能を出す必要があります。そのため、上述のような多岐にわたる性能改善の機構が組み込まれて来ました。その副作用として、これらの汎用プロセッサでは、一定のレイテンシ制約のもとにNN の推論のスループットを上げることがとても困難です。
一方、TPU は NN の推論というひとつの処理のために徹底してミニマルかつ予測可能な設計がなされています。それを表す例として、TPU チップのレイアウトを見てみましょう。
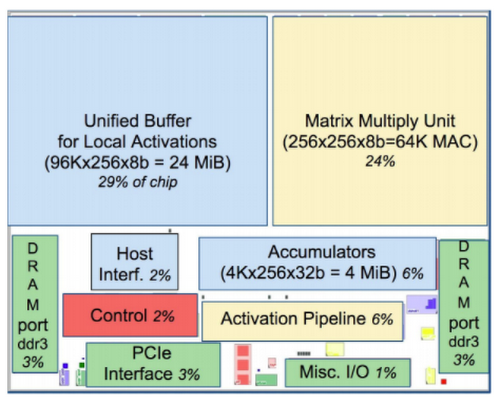
これを CPU や GPU のレイアウトと比べると、赤で示される制御ロジック部分がぐんと小さいことに気づくはずです。汎用プロセッサでは、上述の複雑な機構のために制御ロジックが肥大化していますが、TPU の場合、制御ロジックの占める割合はチップ全体の 2 % に過ぎません。
大規模な ALU シストリック アレイやオンチップ メモリを搭載しながらも、TPU のチップは一般的な CPU や GPU に比べておよそ半分の大きさに過ぎません。LSI チップは、小さければ小さいほどより多くの数をシリコンウェハーから切り出せ、不良品の減少により歩留まりも上がります。その製造コストは面積のおよそ 8 倍に比例して減少するため、TPU のチップは格段に低いコストで製造されています。
また TPU では、NN の推論を一回実行するために必要な時間をきわめて正確に見積もることができます。よって、厳しいレイテンシ制約の下でも、チップ性能の理論上限に近いスループットをほぼすべての推論処理で得られます。例えば、前述した Google における NN アプリケーションのひとつ MLP0 では 7 ms というレイテンシ制限があり、これ以上の時間を推論のために割くことはできません。その制約下では、CPU や GPU と比べて TPU は 15 〜 30 倍のスループットを達成できます。
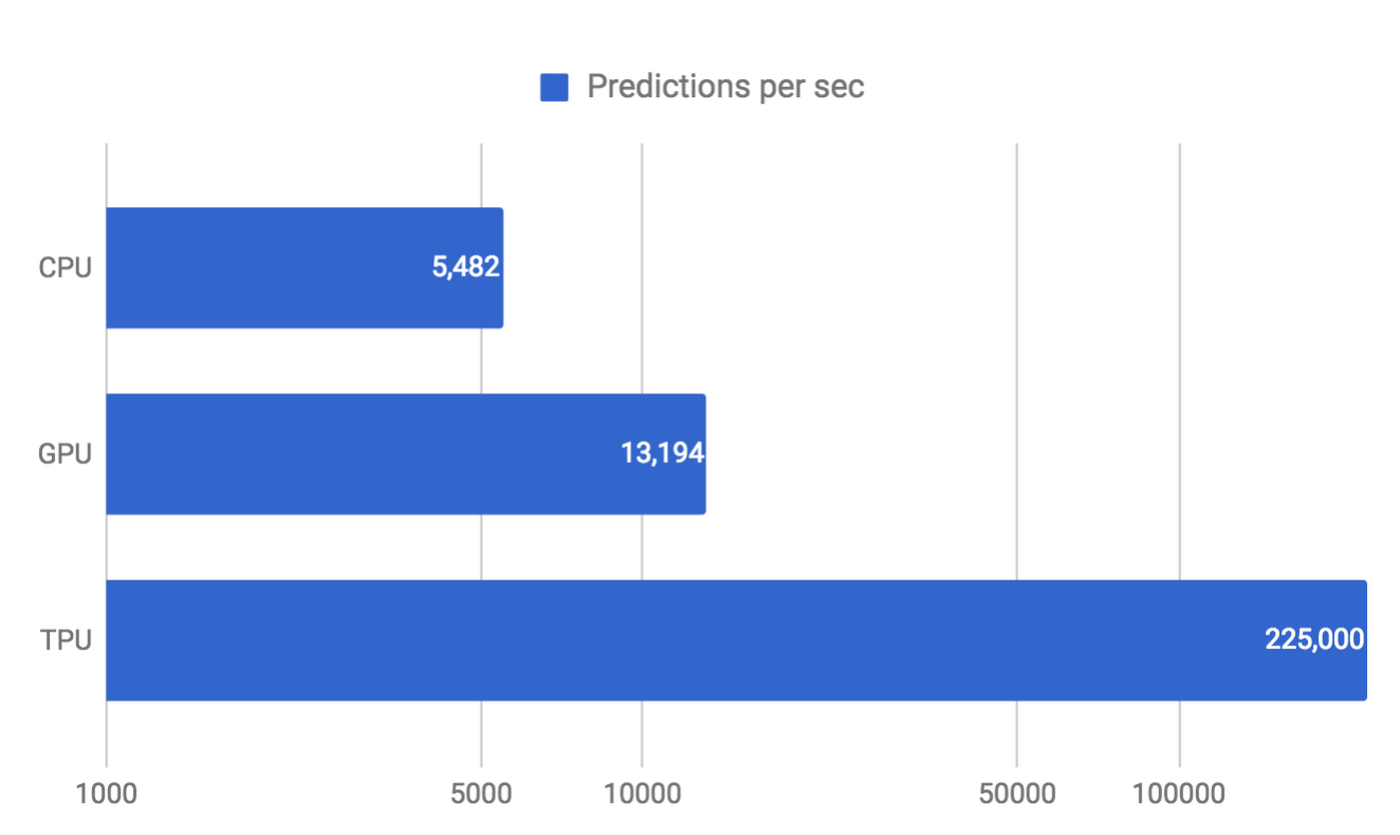
Google では、NN の推論を数多くのエンドユーザー向けサービスに用いています。これらのサービスのレスポンスが伸びれば、ユーザーはすぐさまサービスを使わなくなるでしょう。そのため MLP0 アプリケーションでは、ユーザーエクスペリエンスを一定に維持するため、99 パーセンタイルのレスポンスについて推論のレイテンシが 7 ms を下回るよう厳格に制限されています。
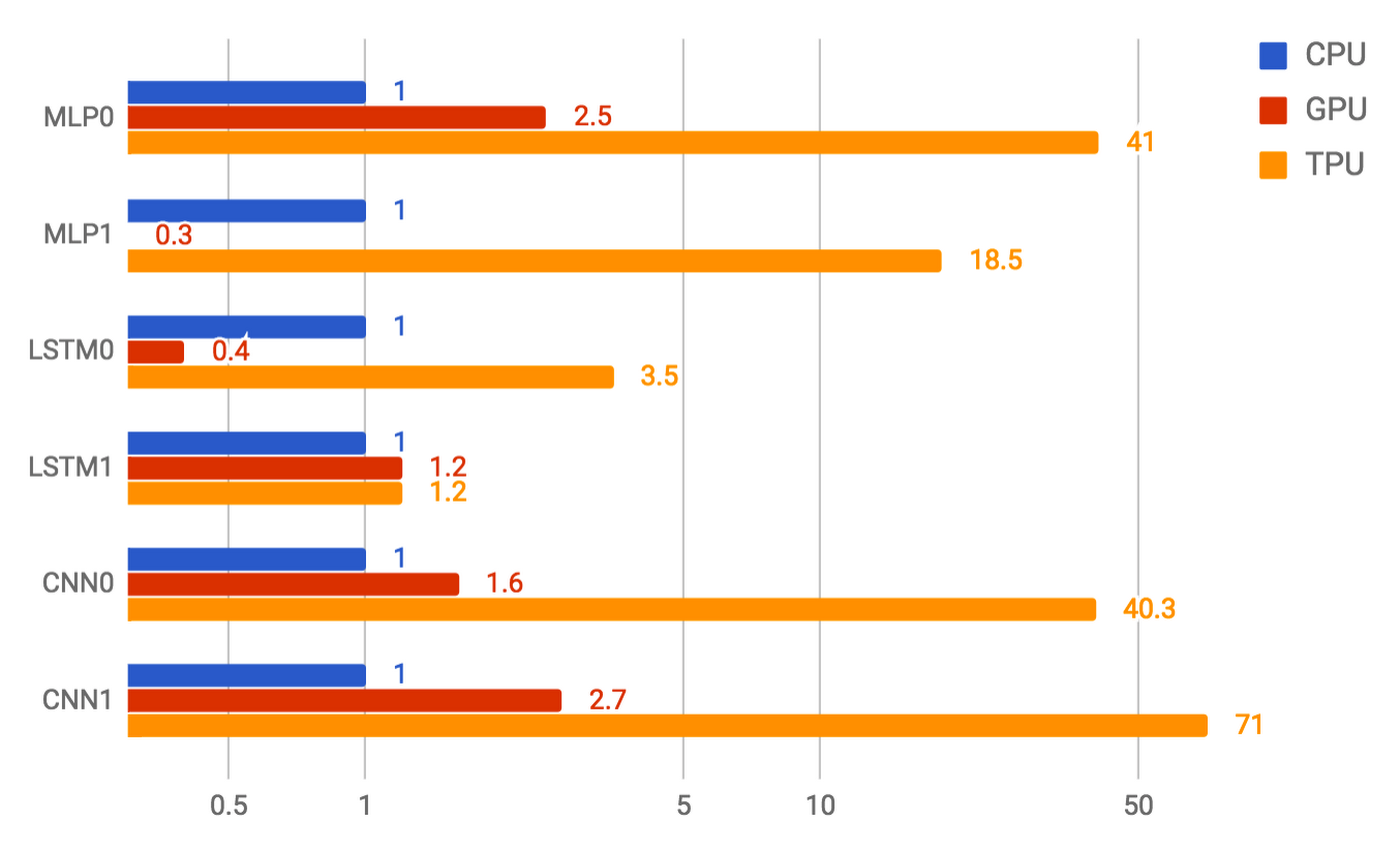
以下のグラフは、Google の 6 つの NN アプリケーションにおいて、一定のレイテンシ制約下での性能(1 秒あたりの推論数)を CPU、GPU、として TPU 間で比べたものです。もっとも差の大きい CNN1 アプリケーションのケースでは、TPU は CPU 比で 71 倍の性能を記録しています。