Memorystore for Redis Cluster で実現する高可用性、パート 1: 99.99%
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
Memorystore for Redis Cluster は、低レイテンシでスケーラビリティに優れたフルマネージドの Redis Cluster サービスで、高可用性と 99.99% の SLA を実現します。このブログ投稿では、Memorystore for Redis Cluster アーキテクチャが 99.99% の可用性の実現にどのように役立つのか、Redis Engine と Google が設計したコントロール プレーンによる機能強化、セルフマネージド Redis Cluster のデプロイにおける高可用性確保に向けた課題について説明します。
サービスの可用性の定義
本題に入る前に、用語を定義しましょう。
重要なワークロード(キャッシュ、リーダーボード、分析、セッション ストア、または迅速な取り込みによるデータのステージングを目的する場合など)に Redis Cluster を利用する場合、障害に対するリスク許容度は非常に低くなります。リスク許容度は可用性として定義することができ、これは Redis Cluster の稼働時間の割合として測定されます。
可用性 = [ 稼働時間 / (稼働時間 + ダウンタイム) ] × 100%
この式を使って、望ましい可用性を達成するためのダウンタイムを計算できます。たとえば、99.99% の可用性(Memorystore for Redis Cluster での目標)を目標とする場合、システムで許容できるダウンタイムは、1 か月あたりわずか 4.38 分です。これを 99.9% の可用性を目標とする他のサービス(許容できるダウンタイムが 1 か月あたり 43.8 分)と比較してみてください。
さらに、サービスの可用性を設計または確認する際は、次の 2 つの重要な指標を考慮することが有効です。
- 平均復旧時間(MTTR): 総ダウンタイム ÷ 障害数。これは、障害を検出して回復するまでにかかる平均時間です。
- 平均故障間隔(MTBF): 総稼働時間 ÷ 障害数。これは、障害発生間隔の平均時間です。
可用性は、MTBF と MTTR で表すこともできます。
可用性 = (MTBF ÷ (MTBF + MTTR)) × 100%
MTBF が 30 日、MTTR が 20 分である場合、サービスの許容ダウンタイムは、1 か月あたり 22 分、つまり 99.95% の可用性となります((30 日 ÷ (30 日 + 20 分)) × 100%)。99.99% の可用性を実現する 4.38 分にダウンタイムを抑えるためには、MTBF を(たとえば、6 か月ごとに)延ばすか、MTTR を(たとえば、4 分未満に)縮める、あるいはその両方を達成する必要があります。
次のセクションでは、セルフマネージド Redis Cluster のデプロイにて直面する課題と Memorystore for Redis Cluster が MTBF を延ばし、MTTT を縮めることで、どのように高可用性を確保するかについて見ていきます。
問題 1: インフラストラクチャの相関障害への対応
複数の独立したコンポーネントが共有する障害発生ドメインに起因して障害を起こすと、システムは相関障害に見舞われます。障害発生ドメインとは、他のリソースに影響を与えることなく独立して障害が発生する可能性があるリソース(例: Compute Engine VM)またはリソースのグループ(例: Google Cloud ゾーン)です。Google では、電力、冷却機能、ネットワーキングなどの物理インフラストラクチャの停止によって引き起こされる、相関障害のリスクを最小限に抑えるようにゾーンを設計しています。
Redis Cluster をデプロイする際に、障害発生ドメインを見落とすと、多くの場合、同じ物理サーバーまたはゾーン上に存在する複数のノードでデータ損失や利用不能のリスクが高まります。よく発生する一般的な例をいくつか紹介します。
- OSS Redis Cluster では、障害発生ドメインの認識が欠けています。redis-cli がパッケージ化されたスクリプトを使用するセルフマネージド Redis のユーザーは必ずしも障害発生ドメイン全体に Redis ノードを分散させるとは限りません。さらに、ユーザーは OSS Redis のレプリカ移行機能のトレードオフを認識する必要があります。この機能により、Redis Cluster の可用性が向上しますが、障害発生ドメインは考慮されません。
- Google Kubernetes Engine(GKE)の GKE ノード(VM)への pod(Redis ノード)の割り当てでは、障害発生ドメインの認識がデフォルトで欠けています。OSS Redis を GKE にデプロイするユーザーは、Pod のアフィニティ ルールと反アフィニティ ルールをプロビジョニングし、トポロジの分散の制約を使用して障害発生ドメインを確実に認識する必要があります。GKE の Redis Cluster のプロビジョニング プロセスは redis-cli に依存していますが、これには障害発生ドメインの認識が欠けています(上記の #1 を参照)。
- ビンパッキングされたアーキテクチャにおけるインフラストラクチャ障害の影響の範囲は、非常に広範になることがほとんどです。独自のアーキテクチャを所有する他の Redis プロバイダは、リソースを共有することで内部費用を削減するために、単一の VM 上で複数の Redis プロセスを使用します。単一の VM の障害が多くの Redis プロセスに影響を与える可能性があるため、このアプローチには危険が伴います。
問題 1 の解決策: 障害発生ドメインにおけるフェイルオーバーの自動化
よく言われるように、何かを成功させるには、まず計画を立てることが大事です。高可用性を実現する Redis Cluster 構成するには、管理者はフェイルオーバー環境の構成方法に特に注意を払う必要があります。具体的には、次の 3 つのステップを使用して障害発生ドメインにおける冗長性を確保し、フェイルオーバー プロセスを自動化します。
ステップ 1: レプリカを事前にプロビジョニングする
インフラストラクチャ障害に対処するための最初のステップは、プライマリ ノードがダウンしたときにレプリカノードに自動的にフェイルオーバーすることです。
事前に各シャードのレプリカをプロビジョニングすることをおすすめします。このアプローチは、多くの経験豊富な Redis ユーザーも採用しています。高可用性の実現に関心のあるユーザーにとって、次の理由からレプリカ容量を事前プロビジョニングする費用は正当化されます。
- シャード内の単一ノードの障害に対する Redis Cluster のレジリエンスが高くなります。ノードに障害が発生した場合、数秒で既存のレプリカノードにフェイルオーバーできるため、長時間のプロビジョニングが不要になります。レプリカがなければ、代替容量のプロビジョニングを待機している間に、減少した Redis Cluster が過負荷になり、可用性が完全に失われる可能性があります。
- 何かが故障した場合に、代替容量をプロビジョニングするためにコントロール プレーン システムに依存する必要がありません。代替容量のプロビジョニングは複雑で、多くの異なるサービスが相互に連携する必要があります。危機的状況にあるときに、複雑なプロセスに頼ってことを素早く収めようとするのは危険であり、スタックの深さが増すため、さらなる問題が発生する可能性が高くなります。
- リードレプリカを活用して読み取り容量を増やすことができます。リードレプリカは、高可用性を実現するためのフェイルオーバーだけでなく、読み取りスループットを提供し、プライマリ ノードの負荷の軽減にも役立ちます。リードレプリカに障害が発生した場合は、リードレプリカが修復されるまでプライマリ ノードにフォールバックして読み取りを行うか、前もって追加のレプリカをプロビジョニングできます。
次のように考えてください。運転中にタイヤがパンクした場合でも、スペアタイヤがあれば、比較的早くタイヤを交換し走行を再開できます。スペアがなければ、誰かに電話して修理のために車をレッカー移動してもらうのを待つ、という長い MTTR が発生します。携帯電話がサービス圏外で、助けを呼べない場合はさらにリスクが高くなります。

Memorystore for Redis Cluster によりレプリカの管理が簡単になります。ボタンをクリックするか、簡単な gcloud コマンドを実行するだけで、レプリカがプロビジョニングされ、プライマリとの同期が維持されるため、プライマリ ノードに障害が発生した場合にすぐに自動プロモーションに対応できます。Memorystore for Redis Cluster は OSS Redis Cluster のフェイルオーバー メカニズムを使用して、サービスの停止から数十秒以内にプライマリ フェイルオーバーを実行し、シャードの可用性を回復します。
ステップ 2: Redis シャードを障害発生ドメイン全体に配置する
相関障害に対処するための 2 番目のステップは、Redis のプライマリ ノードとレプリカノードを障害発生ドメイン全体に確実に配置することです。
同じ障害発生ドメイン内のレプリカによる自動フェイルオーバーは、可用性の高い構成ではありません。単一の障害により、シャード(または複数のシャード)のプライマリ ノードとレプリカノードの両方がダウンし、アプリケーションの可用性に悪影響を及ぼす可能性があります。
ここでは、Memorystore for Redis Cluster が自動フェイルオーバーの状況をどのように改善するかについて紹介します。
- Memorystore for Redis Cluster は配置アルゴリズムを適用し、リージョン デプロイ アーキタイプを使用して、各シャードのプライマリ ノードとレプリカノードを複数のゾーン(障害発生ドメイン)に自動的に分散します。
- 単一のゾーン内であっても、Redis ノードは Compute Engine のスプレッド プレースメント ポリシーを使用して複数の物理サーバーに分散配置されます。
下の画像(b)は、Memorystore for Redis Cluster における、複数のゾーンにわたる 3 シャード Redis Cluster のプライマリ ノードとレプリカノードの分散の様子を示しています。
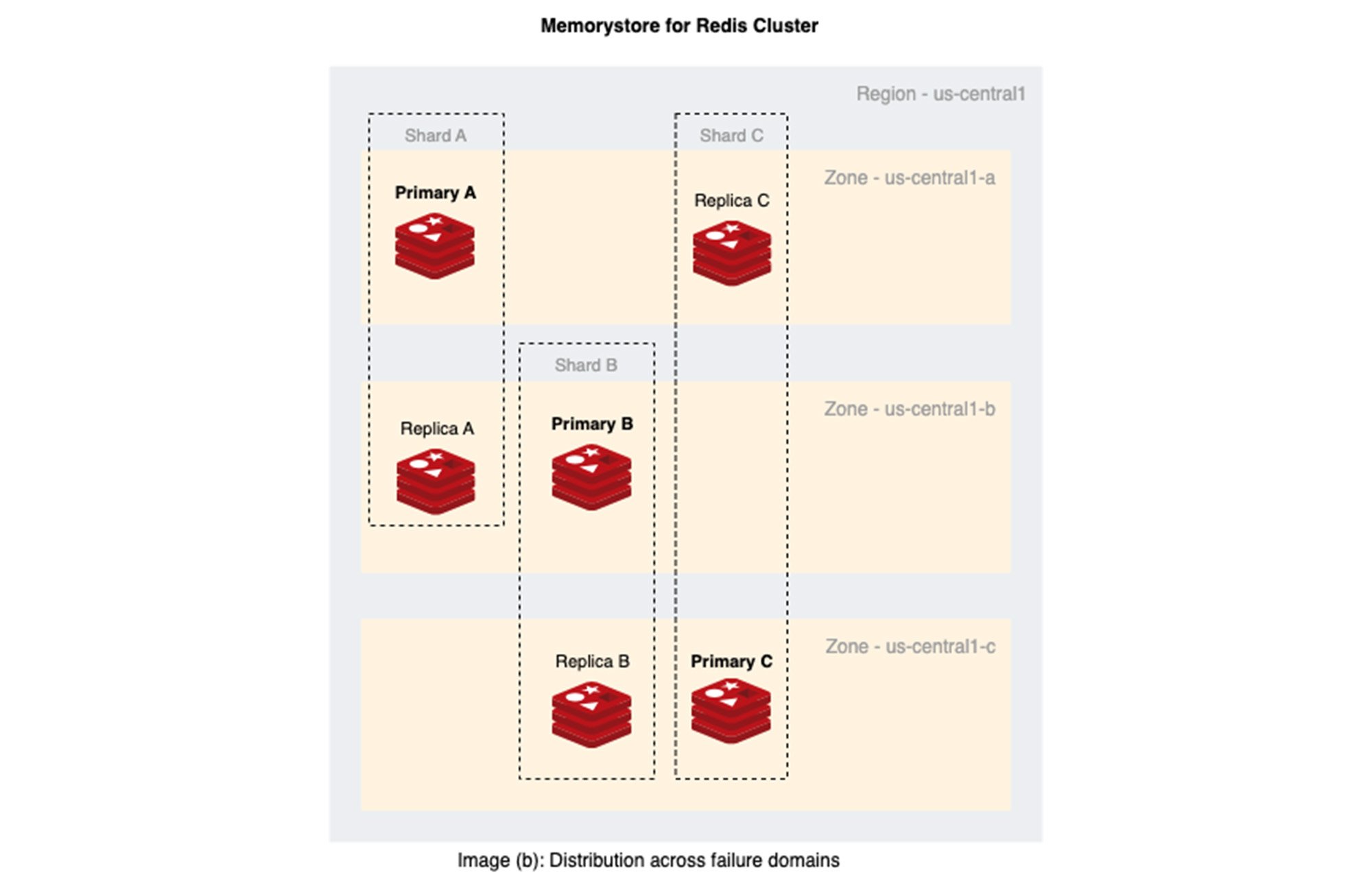
本質的に、これが Memorystore for Redis Cluster が VM やゾーンが提供する 99.9% ではなく、99.99% の稼働率を実現できる理由ですが、複数のゾーンで同時に障害が発生する確率は、単一のゾーンで障害が発生するよりもはるかに低く、効果的に MTBF を長くできます。
下の画像(c)は、ゾーン停止時の Memorystore for Redis Cluster におけるプライマリの自動フェイルオーバーを示しています。
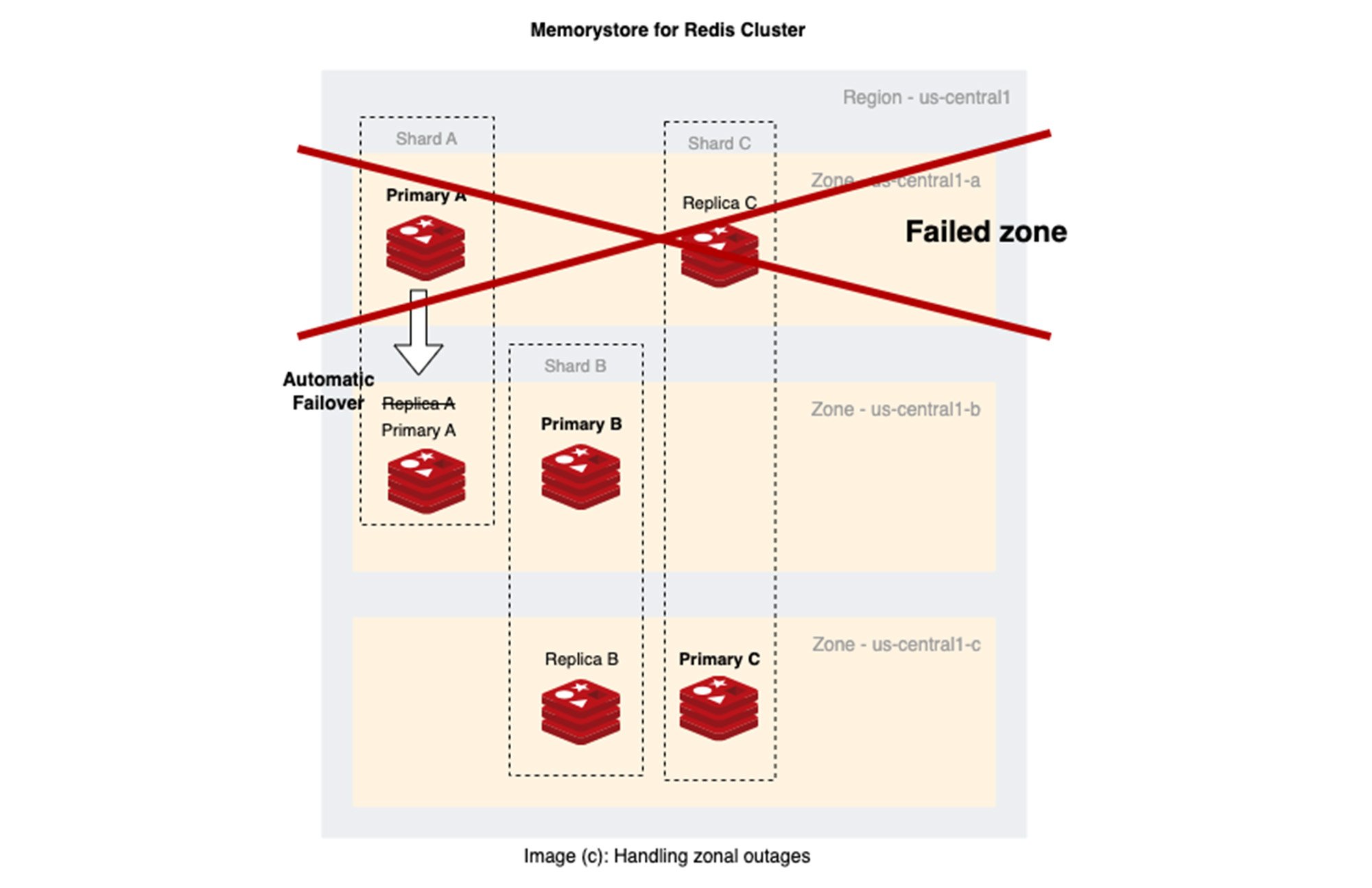
もちろん、より長いダウンタイムを許容できる特殊なユースケースを扱うチームは、クロスゾーン ネットワーキングの費用やクロスゾーンのレイテンシを回避するために、単一ゾーンのデプロイを検討することもできます。ただし、この設計には暗黙の可用性リスクがあることに注意してください。
ステップ 3: フェイルオーバー メカニズムの高可用性を確保する
相関障害に対処するための 3 番目かつ最後のステップは、ゾーンがダウンするような大規模な障害の発生時に、プライマリ フェイルオーバー メカニズムが確実に機能するようにすることです。
ここでは、OSS Redis Cluster の障害検出とレプリカの選出とプロモーションの仕組みについて説明します。
- Redis ノードはヘルスチェックのために「Gossip プロトコル」を使用して通信します。
- あるノードが大多数のプライマリ ノードから到達できない場合、Redis Cluster はそのノードに障害が発生したと宣言します。
- Redis Cluster は、プライマリの多数決に基づき、影響を受けるシャードに対してレプリカをプライマリ ロールにプロモートします。
Memorystore for Redis Cluster は、OSS Redis Cluster フェイルオーバー メカニズムを使用します。これは、コントロール プレーンなどの外部依存関係を排除し、Redis ノード自身が障害を検出してプライマリを選出することで、全体的なレジリエンスが向上するからです。Redis Cluster ノードで構成されるデータプレーンはクライアントのリクエストに対応し、コントロール プレーンは Redis を管理します。コントロール プレーンは、そのワークフローと状態管理のために複雑で、障害が発生する可能性が高くなります。コントロール プレーンがダウンしても Redis ノードは引き続きリクエストに対応できるため、フェイルオーバーの処理に対するコントロール プレーンへの依存を排除することで MTBF を長くできます。
しかしながら、自動化されたフェイルオーバーだけでは、高可用性を確保することはできません。上述したように、OSS Redis Cluster では障害検出とレプリカのプロモーションに、プライマリ ノードの大多数の賛成が必要になります。クォーラムが得られなければ、どのシャードでもフェイルオーバーは不可能になります。次に、問題のあるシナリオをいくつか紹介します。
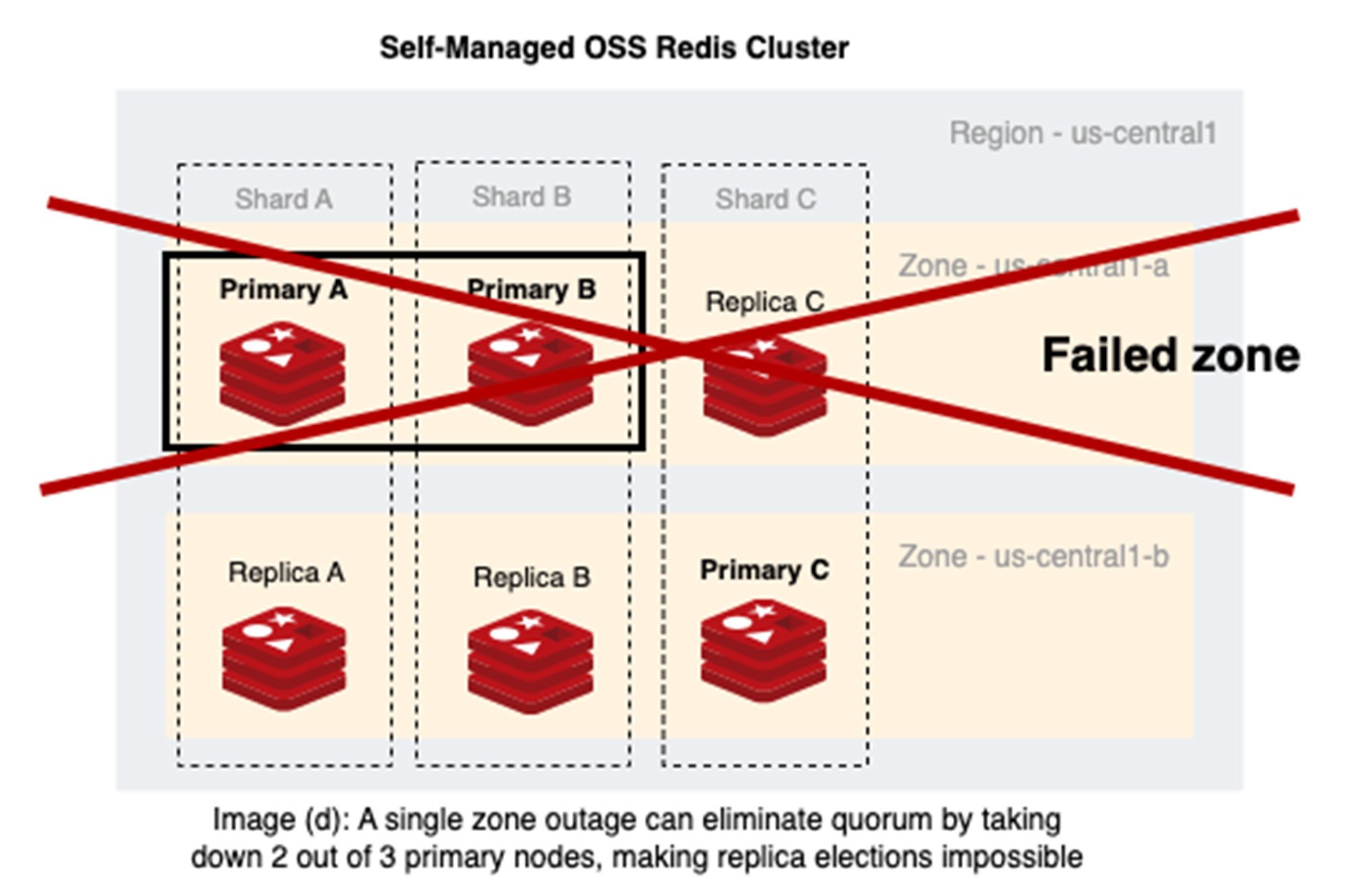
シナリオ 1: 2 つのゾーン(us-central1-a と us-central1-b)にノードが分散された単一の Redis Cluster 内にある 3 つの Redis シャード
画像(d)の見解: Redis Cluster の 2 ゾーン デプロイメントは、1 つのゾーンでのサービス停止時にプライマリの大半で障害が発生する可能性があるため、1 つのゾーンでのサービス停止に対するレジリエンスを得られません。us-central1-a と us-central1-b 両方のゾーンのプライマリ ノードは、フェイルオーバーの決定を行う必要があります(ただし、決定できません)。
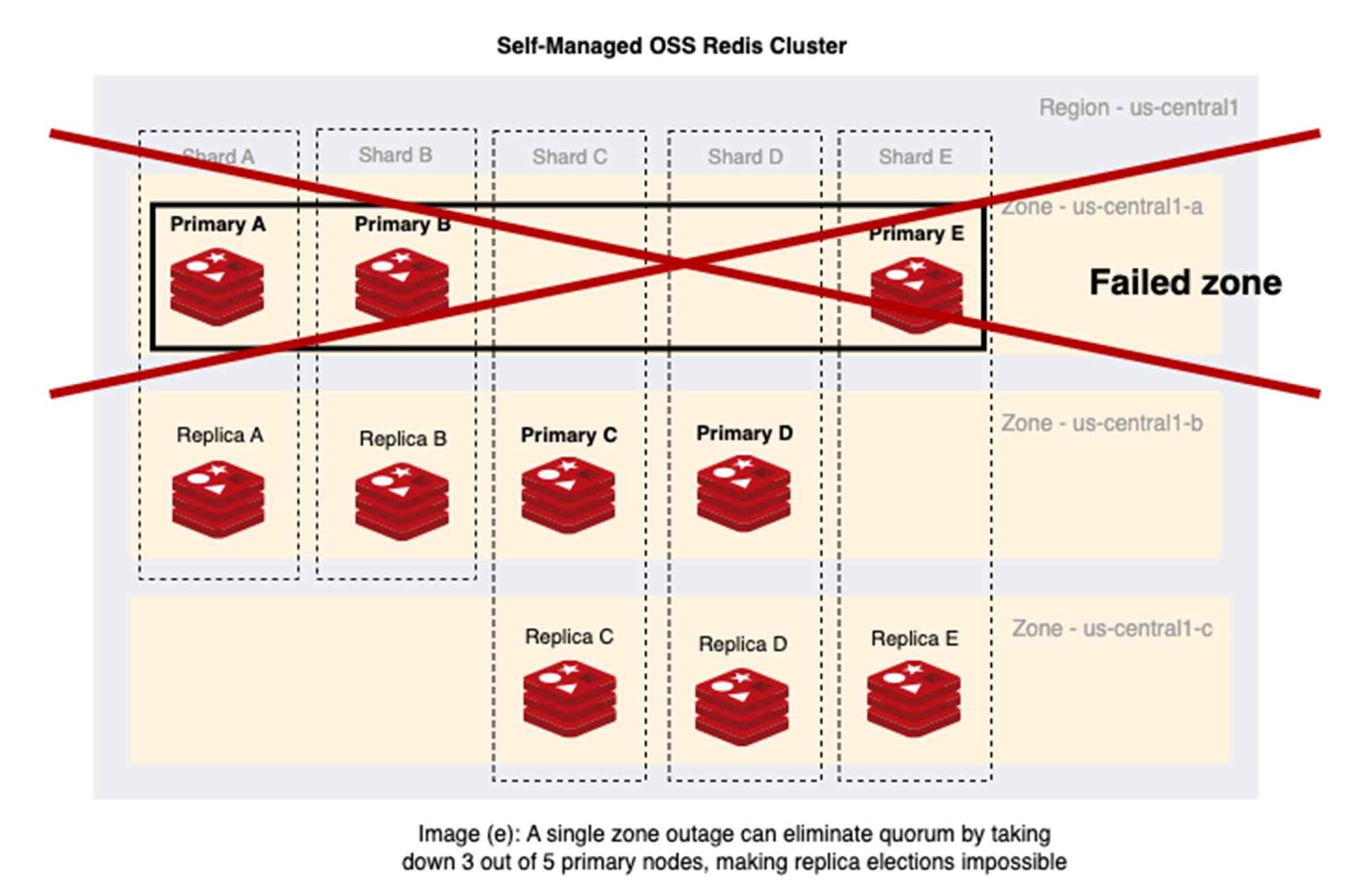
シナリオ 2: 3 つのゾーン(us-central1-a、us-central1-b、us-central1-c)にノードが分散された単一の Redis Cluster 内にある 5 つの Redis シャード
画像(e)の見解: プライマリとレプリカが復元性を備えた設計で分散されていない場合、Redis ノードを 3 つのゾーンに割り当てるだけでは十分な保護とはなりません。1 つのゾーンでのサービス停止によりプライマリ ノードの大半がダウンした場合、Redis のフェイルオーバーにより OSS Redis Cluster が使用できなくなる可能性があります。
- ゾーン us-central1-a には 5 つのプライマリ ノードのうちの 3 つがあり、3 つのゾーンにおけるプライマリ ノードの分布は 3:2:0 となっています。プライマリ ノードが us-central1-a には 3 つ、us-central1-b には 2 つ、us-central1-c にはゼロです。
シャード E のプライマリ ロールが us-central1-c にブートストラップされ、ノードのバランスが 2:2:1 になったとしても、シャード E での 1 回のフェイルオーバーにより、プライマリ ロールが us-central1-a に移動し、3:2:0 という偏った分布に戻ってしまいます。
Compute Engine や GKE のようなプラットフォーム ソリューションには、動的なクラスタ トポロジを管理する仕組みがないため、セルフマネージド デプロイではこのようなシナリオで苦労することになります。この結果、1 つのゾーンでのサービス停止によりプライマリ ノードの大半が影響を受ける可能性があります。
対照的に、Memorystore for Redis Cluster は以下を使用して、プライマリ ノードのクォーラムが大規模なサービス停止に対するレジリエンスを維持できるようにします。
- Redis シャードを 3 つのゾーンに分散し、ゾーンにおけるサービスの停止中にクォーラムを保護する配置アルゴリズム
- プライマリ ノードの分散をモニタリングして修正し、単一ゾーンへの集中を防いでレジリエンスを強化するプライマリ バランシング アルゴリズム
問題 2: Redis Cluster の障害が発生したインフラストラクチャの修復ではエラーが発生しやすい
Redis Cluster の基盤となるインフラストラクチャに障害が発生した場合、直面する課題が 2 つあります。1 つはクラスタの復元可能性、もう 1 つは Redis プロセスの再起動可能性です。
復元可能性
MTTR を短時間に収め、容量を維持して、次の障害に備えるには、障害が発生したノードを迅速に修復する必要があります。ノードの復元は、いくつかの要因により難しく、エラーが発生しやすくなります。
- セルフマネージドの OSS Redis Cluster では、ノードの障害を管理する管理者が必要です。障害発生中にシャードとスロットの割り当てを維持し、復旧後にそれらを復元する必要があります。
- Redis エンドポイント(IP アドレス)は、インフラストラクチャの交換または Kubernetes Pod の再起動後に変更される可能性があり、その結果 Redis Cluster トポロジに不整合をもたらすだけでなく、クライアント アプリケーションに影響を与える可能性があります(Kubernetes StatefulSets を使用している場合でも)。
- Kubernetes クラスタでは、Redis ノードは IP の変更を処理するために永続的な DNS 名を必要とします。DNS の依存関係は、DNS の再構成の遅延により MTTR を延ばすことになり、クライアントのサービス停止を招く可能性があります。Kubernetes と Redis の announce-ip 機能の高度なインテグレーションも選択肢の一つですが、複雑さと管理性のオーバーヘッドが増加します。
- さらに、自動システムがなければ、Redis のシステム管理者が単一障害点になりやすく、数十から数百のノードを持つ Redis Cluster ではスケーリングの課題に直面し、システム全体の MTTR が長くなる可能性があります。
再起動可能性
OSS ガイドで説明されているように、セルフマネージド Redis Cluster ではカスケード障害が発生しやすくなっています。カスケード障害は、正のフィードバックの結果として、時間の経過とともに障害発生ドメイン全体に拡大する障害です。これは影響の範囲が、根本的な原因によって定義される障害発生ドメインに限定される相関障害モードとは対照的です。
プライマリ ノードはクラッシュ後(おそらくメモリ不足の問題による)、予期せず空の状態(データがフラッシュされた状態)で再起動することがあり、その結果レプリケーション プロパティによってレプリカが消去されてしまいます。カスケード障害は、Redis プロセスのクラッシュの影響範囲を悪化させ、サービス全体の MTBF を短くします。
問題 2 の解決策: 自動化された信頼性の高い修復
障害が発生したインフラストラクチャを大規模に修復する際の主な目標は、次の 3 つのステップを使用して堅牢な Redis 対応の自動修復サービスを構築することです。
ステップ 1: スマートな再起動
カスケード障害シナリオを防ぐため、Memorystore for Redis Cluster はプライマリ ノードで再起動を開始する前に既存のレプリカをプロモートします。その後、クラッシュしたプライマリは空いたレプリカノードのロールを担い、新しいプライマリからデータセット全体を複製します。
ステップ 2: 修復の自動化
Memorystore for Redis Cluster は、OSS Redis のシステム管理者の要件を置き換え、堅牢かつ完全に自動化された方法で信頼性のギャップを埋めるコントロール プレーン サービスを提供します。
- Memorystore for Redis Cluster のコントロール プレーンは、単一の VM であれゾーン全体であれ、あらゆる規模において障害が発生したノードを自動的に修復します。
- コントロール プレーンは、キースペース マッピングとノードの必要な状態をリロードして、同じエンドポイント(IP アドレス)でサービスを復元し、Redis Cluster トポロジのチャーンを回避します。
ステップ 3: コントロール プレーンの高可用性
ラテン語のフレーズ「Quis custodiet ipsos custodes」は、「警備員自身は誰が守るのか?」と問うています。この場合では、「クラスタの可用性を確保するためにコントロール プレーンが配備されているのであれば、コントロール プレーンの可用性は何によって確保されるのか?」と問うべきでしょう。自動化は、Redis Cluster だけでなく、Redis の管理に使用される自動化されたコントロール プレーンの高可用性を確保するという課題をもたらします。Memorystore for Redis Cluster のコントロール プレーンは、以下の特徴を持つ堅牢なワークフローと状態管理を提供します。
- 大規模なサービス停止時の高可用性を実現するために、複数のクラウドゾーンにわたって冗長的にデプロイされている
- 他のリージョンに対する単一障害点のないリージョン サービス
- Redis データプレーンとは分離して別にプロビジョニングされているため、管理運用のための独立したスケーリングが可能
- モジュール化されたプロビジョニングと修復ワークフローにより、障害を分離することで信頼性が向上
要点
このブログでは、可用性の高いセルフマネージド Redis Cluster を構成する際の課題について取り上げました。OSS Redis Cluster のデータ パーティショニング(別名「シャーディング」)は、複数のノードを管理し、ノードを正しくプロビジョニングすることで、障害に耐え、サービスの可用性を最大化する際の負担を増大させます。具体的には、OSS Redis Cluster の可用性に関する主な課題は次のとおりです。
- 障害発生ドメインの認識の欠如
- GKE 上で OSS Redis を実行しているユーザーは、高度な Pod アフィニティ ルールをプロビジョニングし、トポロジの分散の制約を確保する必要がある。それでも、Redis プライマリ ノードのクォーラムが 1 つのゾーンのサービスの停止に耐えられるという保証はありません。
- 障害が発生したインフラストラクチャに対する手動のエラーが発生しやすい修復プロセスにより、MTTR が長くなる
Memorystore for Redis Cluster は、高可用性を実現するために、信頼性が高く、MTTR が短いアプローチ、つまりレプリカの事前プロビジョニングを採用しています。Memorystore for Redis Cluster の可用性に関する主な利点は次のとおりです。
- Redis ノードを 3 つの障害発生ドメイン(Google Cloud ゾーン)にレプリケーションし、分散させることで、インフラストラクチャの相関障害に対応し、99.99% の可用性を実現
- Redis ノードの障害やゾーン停止時の自動フェイルオーバー
- 可用性の高いコントロール プレーンにより、Redis のシステム管理のオーバーヘッドを削減し、障害が発生したノードを大規模に自動修復
次のステップ
Memorystore for Redis Cluster を使用することで、ゼロ ダウンタイムのスケーリングとマイクロ秒単位のレイテンシも提供する、フルマネージドで可用性の高い Redis Cluster の真の可能性を引き出すことができます。Google Cloud コンソールにアクセスして、数回のクリックで可用性の高い Redis Cluster を作成することで、今すぐ簡単に始められます。Memorystore for Redis Cluster への移行の詳細については、こちらの移行の詳細な手順に関するブログをご覧ください。この解説シリーズの次回のブログをお楽しみに。ご意見やご感想がございましたら、cloud-memorystore-pm@google.com までお知らせください。
-Google Cloud Databases、ソフトウェア エンジニア Dumanshu Goyal
-Google Cloud Databases、シニア プロダクト マネージャー Kyle Meggs


