Google Cloud データベースを使用して生成 AI エージェントを構築
Sean Rhee
Product Management, Google Cloud
※この投稿は米国時間 2025 年 3 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
セキュリティ ポスチャーの強化やカスタマー エクスペリエンスの向上を目的とした企業による生成 AI エージェントの構築には、リアルタイム データへのアクセスが必要になります。こうしたビジネスに不可欠なリアルタイム データのほとんどはデータベースに保存されて処理されるため、エージェント オーケストレーションを動的に実行する方法が必要です。
この投稿では、モデル、ツール、データストア、アプリケーションで構成される新しい技術スタックを定義します。スケーリング、パフォーマンス、セキュリティ、管理性に基づいて、各コンポーネントが、企業のお客様のニーズに応えるうえで重要である理由を説明します。それでは詳しく見ていきましょう。
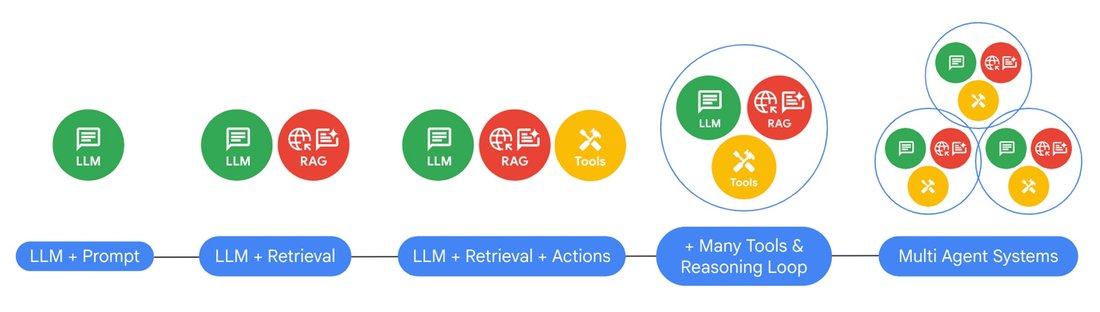
LLM から RAG エージェントへ
エージェント アプリケーションのコンポーネント
サービス業界では、人間のエージェントが何十年もの間、顧客のサポートを担い、旅行の予約、保険の推奨、契約交渉などを手助けしてきました。「AI」エージェントも同じようにユーザーをサポートしますが、さらに多くのメリットがあります。すでに多くの組織が高度な AI エージェントを構築して実現していることは以下のとおりです。
-
履歴に基づいてユーザーのニーズを把握することで、高度にパーソナライズされたエクスペリエンスを提供
-
生産性向上と効率的な共同作業を可能にする自動化ツールを導入して従業員を支援
-
目的に沿ったコンテンツの生成やキャンペーンの実施により、クリエイティブなプロセスを支援
-
複数のデータソースを使用した複雑なデータ分析を実施して、シグナルやパターンに対応
-
AI 対応のコード生成やサポートによりソフトウェア開発を加速
-
攻撃を軽減し、調査のスピードを向上させることで、セキュリティ ポスチャーを強化
エージェント アプリには、従来の生成 AI アプリにはない機能がいくつかあります。たとえば、さまざまなツールを活用して推論や計画を行うための指示が追加されている、より洗練されたオーケストレーション モジュールを搭載しているエージェント アプリがあります。
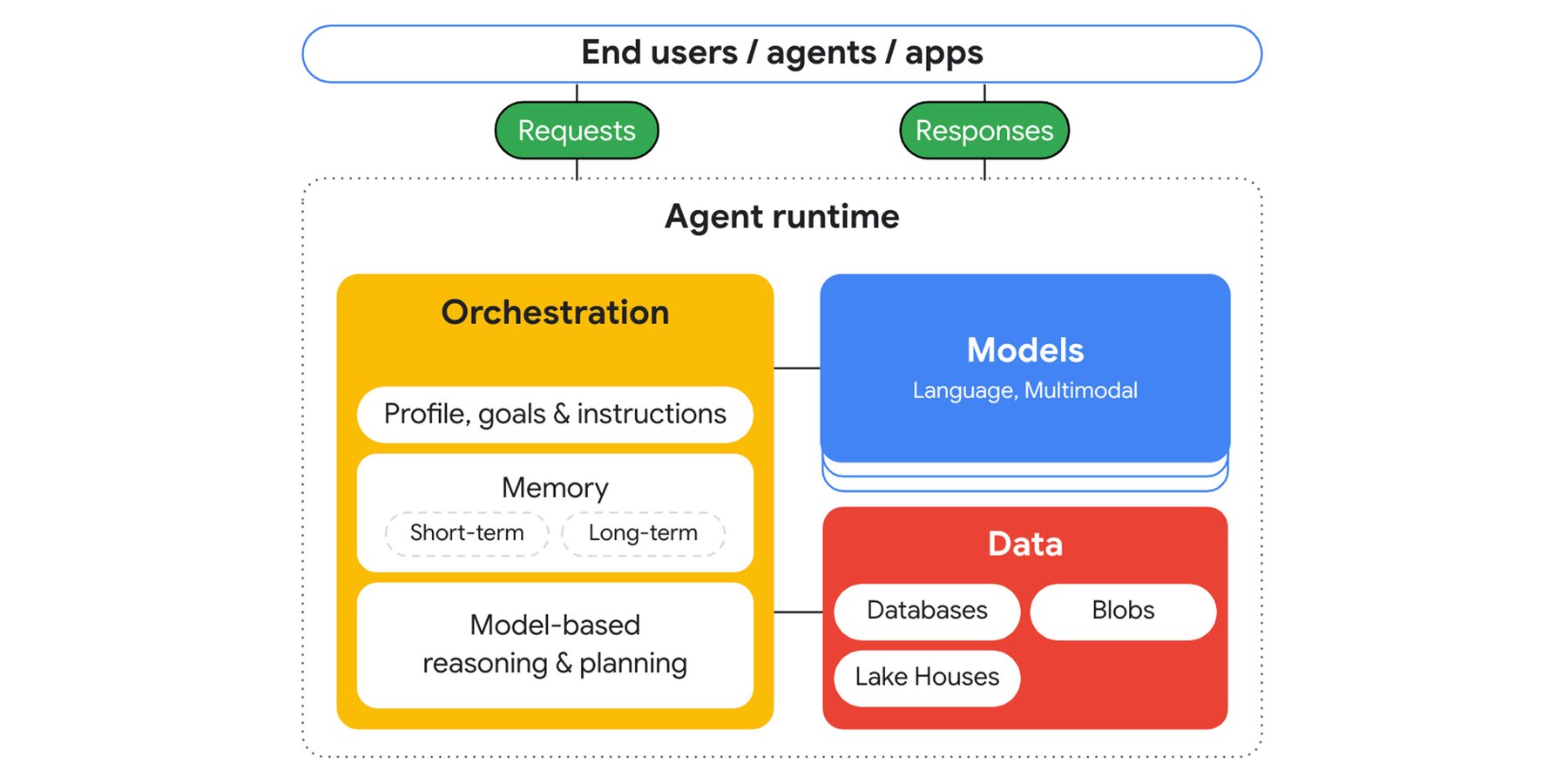
エージェント アプリのアーキテクチャ
エージェント ランタイム内のオーケストレーション システムは、基盤モデルやツールと連携して、サービス API の呼び出し、データベースへの接続、他のエージェントとの連携を行います。エージェント ランタイムを構成するコア モジュールを以下に示します。
-
オーケストレーション: メモリとセッションの状態を維持し、モデルにプロンプトを送信して、レスポンスを解析します。レスポンスにツール呼び出しが含まれている場合、オーケストレーションは対応する API 呼び出しを実行し、その結果を次のプロンプトに含めます。
-
モデル: 目標を推論して次のステップを決定し、レスポンスを生成するために使用されます。
-
データ: 他のサービスの API からアプリケーション データ、データベースから運用データ、レイクハウスから分析データ、blob から非構造化データを取得します。
デベロッパーは、自然言語による指示や例を参考にしてエージェントを構成できます。また、セッション履歴、ユーザー プロファイル、タスク プロファイルなどのさまざまな種類のメモリにアクセスし、タスク分解サービスやプランナー サービスで拡張して、複雑なリクエストをより小さなワーク ストリームに分解することもできます。
エージェントを Google Cloud データベースに接続する
エージェントの能力は、タスクの実行に使用できるツールの能力に左右されます。また、エンタープライズ アプリケーションで単一のデータソースのみを使用することはほとんどありません。これは、エージェント オーケストレーションが台頭してきた理由の一つであり、LLM を活用したアプリケーションがより複雑なタスクを処理するための新しいパラダイムとなりました。エージェントは、「ツール」と呼ばれる一連の機能から選択して、データにアクセスしたり、次のステップを指示するアクションを実行したりできます。この動的かつ反復的なプロセスを使用することで、エージェントは複雑なエンタープライズ ワークフローを自動化できます。
しかし、ツールを大規模に作成および管理することにおいて、デベロッパーが直面する課題がいくつかあります。エージェントは、複数のツールやフレームワークを使用するだけでなく、さまざまなデータソースに接続することが多く、統合が困難になる場合があります。エージェントにとって特に困難なタスクの一つは、データソースの検出と接続です。このプロセスは複雑でセキュリティ上の課題が生じる可能性があり、複数のフレームワークをサポートすると管理が困難になる場合があります。
そこで役立つのが、データベース向け生成 AI ツールボックスです。これは、アプリケーション デベロッパーが本番環境レベルかつエージェント ベースの AI アプリケーションをデータベースに接続できるようにするオープンソース サービスです。これにより、セキュリティが確保されたアクセス、堅牢なオブザーバビリティ、スケーラビリティ、包括的な管理機能を備え、データベースに対してクエリを実行できる高度な生成 AI ツールの作成、デプロイ、管理が簡素化されます。現在、生成 AI ツールボックスは、PostgreSQL、MySQL、Neo4j、Hypermode などの一般的なオープンソース データベースに加え、AlloyDB(+Omni)、Spanner、Cloud SQL などの Google Cloud データベースへの接続を提供しています。
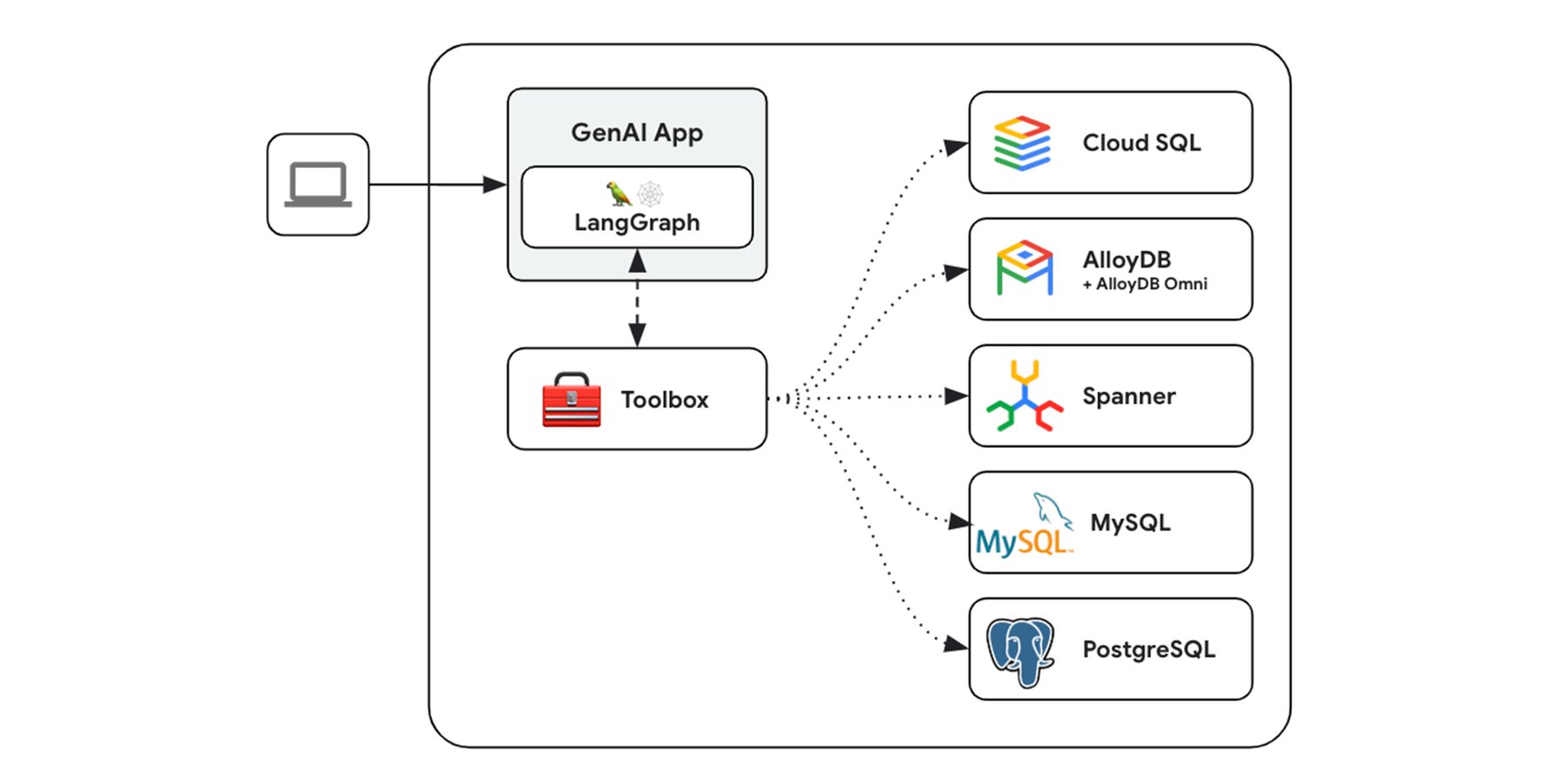
データベース向け生成 AI ツールボックス
データベース向け生成 AI ツールボックスは、生成 AI ツールとデータの相互作用を改善し、生成 AI ツールの管理における一般的な課題に対処します。アプリケーションのオーケストレーション層とデータソース間の仲介役として機能することにより、より迅速な開発とよりセキュアなデータアクセスを可能にし、ツールの本番環境品質を向上させます。
エージェントを使用して自然言語でデータベースにクエリを実行する
エージェントをデータベースに接続すると、さまざまな方法でデータをクエリできるようになります。最近人気が高まっている手法は、自然言語を使用してデータベースにクエリを実行することです。LLM の能力により、次のような自然言語による質問が可能です。
「7 月で一番安いボストンからデンバーへの直行便は?」
これは、次のような SQL クエリに変換できます。
SELECT flight.id, flight.price, carrier.name, [...]
FROM [...]
WHERE [...]
ORDER BY flight.price ASC
AlloyDB は、このような自然言語による質問を SQL ステートメントに変換する機能を備えています。これにより、生成 AI アプリケーションは、「私の荷物はどこ?」や「各部門で最も稼いでいる人は誰?」といった自然言語によるクエリをよりセキュアに実行できるようになります。AlloyDB は、自然言語による入力をデータベース固有の SQL クエリに変換し、アプリケーションのユーザーが閲覧できる結果のみをフィルタすることで、これを実現します。
LLM プロンプトですでに自然言語が使用されており、データベースが自然言語を理解できる場合は、エージェントや生成 AI アプリがクエリを SQL ステートメントに変換することなくデータベースに渡す方が効率的で簡単です。これにより、データのアクセスと取得の新しいアプローチが可能になります。
エージェント向けの複雑なデータモデルの処理
大規模な組織では、さまざまなデータタイプやモデルを扱うことが一般的です。さらに、ナレッジグラフ、レコメンデーション、不正行為の検出などのユースケースでは、相互接続されたデータが顧客にとってますます重要になっています。これは、さまざまなデータシステムを検出して走査し、その結果を結合する必要があるため、エージェントにとって解決が難しい問題でした。
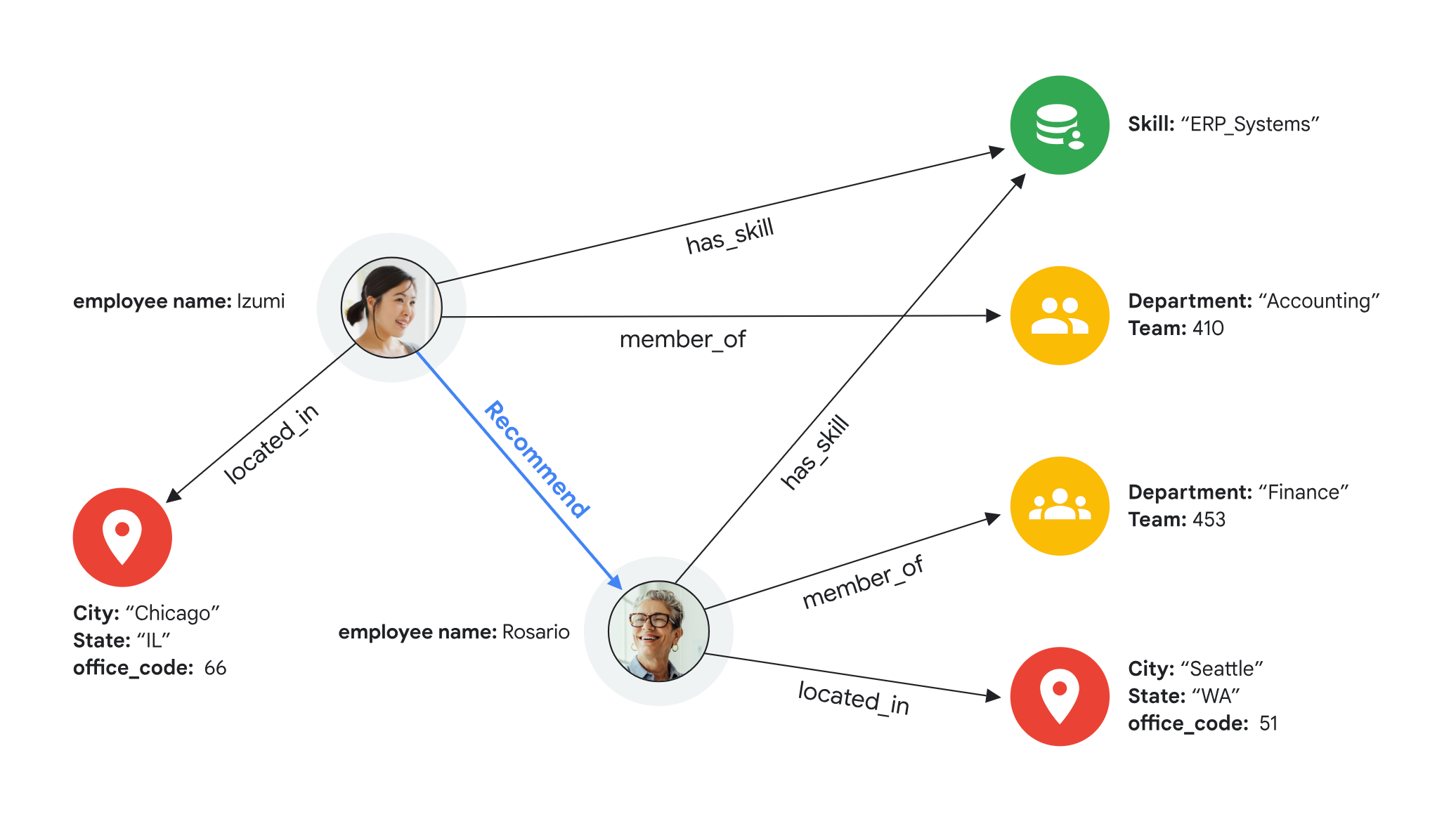
接続されたデータのための Graph ベースのモデル
Spanner に組み込まれた Graph を使用すると、エージェントを呼び出すだけでこの問題を解決できます。Spanner は、差別化されたグラフ検索、ベクトル検索、全文検索をサポートするマルチモデル データベースです。グラフ検索は事前定義された関係に基づいて関連する結果を取得し、ベクトル検索は類似性検索のカテゴリ結果を取得し、全文検索は完全一致を取得します。これらを組み合わせることで、単一のデータベースからのハイブリッド検索が可能になります。
これにより、結果を個別に組み合わせることなく、さまざまなデータモデルにわたって、エージェントが必要とする企業の状況を提供できるようになります。
エージェント アプリとデータベースを使ってみる
Google データベースを使用してエージェント アプリの構築を開始するには、GitHub からデータベース向け生成 AI ツールボックスをダウンロードしてお試しください。
-Google Cloud、プロダクト管理担当 Sean Rhee
