BigQuery の JSON 型を活用して半構造化データの力を引き出す
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
企業で生成されるデータの量は急激に増えており、その種類は、従来の構造化トランザクション データ、JSON などの半構造化データ、画像や音声などの非構造化データと多岐にわたります。データが多様で大量になると、データ処理、データ ストレージ、クエリエンジンに複雑なアーキテクチャ上の課題が生じるため、デベロッパーは半構造化データと非構造化データを処理するカスタム変換パイプラインを構築する必要があります。
今回の投稿では、BigQuery の半構造化 JSON のサポートを強化するアーキテクチャ コンセプトについて説明します。このコンセプトにより、複雑な前処理の必要がなくなり、スキーマの柔軟性、直感的なクエリ、構造化データで利用できるスケーラビリティのメリットが得られます。ここではストレージ形式の最適化、アーキテクチャがもたらすパフォーマンス上のメリットを確認し、最後に、JSON パスを使用するクエリではそれが課金にどのように影響するのかについて説明します。
Capacitor ファイル形式との統合
カラム型ストレージ形式である Capacitor は、BigQuery の基盤となるストレージ アーキテクチャのバックボーンです。10 年以上にわたる研究と最適化を基盤に、この形式はエクサバイトのデータを保存し、数百万のクエリ処理に対応します。Capacitor は構造化データを保存するために最適化されています。Capacitor は、辞書式、ランレングス圧縮(RLE)、差分符号化などの手法を使用して、列の値を最適に保存します。RLE の効果を最大化するために、レコードの並べ替えも採用されています。通常、テーブルの行の順序は重要ではないため、Capacitor は RLE の効果を高めるために行を自由に並べ替えることが可能です。カラム型ストレージは、埋め込み式表現ライブラリで使用されるブロック指向のベクトル化処理に適しています。
JSON などの半構造化形式をネイティブにサポートするために、スパースな半構造化データ用に最適化された次世代の BigQuery Capacitor 形式を開発しました。
取り込み時に、JSON データは可能な限り仮想列に細断されます。JSON キーは通常、行ごとに 1 回ではなく、列ごとに 1 回だけ書き込まれます。コロンや空白など、そのほかのデータ以外の文字は、列に保存されるデータの一部ではありません。値を列に配置すると、辞書式圧縮、ランレングス圧縮、差分符号化などの構造化データに使用されるのと同じエンコードを適用できます。これにより、クエリ時のストレージと IO コストが大幅に削減されます。さらに、JSON の null と配列は、仮想列の最適なストレージにつながる形式によってネイティブに理解されます。図 1 は、レコード R1 と R2 の仮想列を示しています。レコードはネストされた列に完全に細断されます。
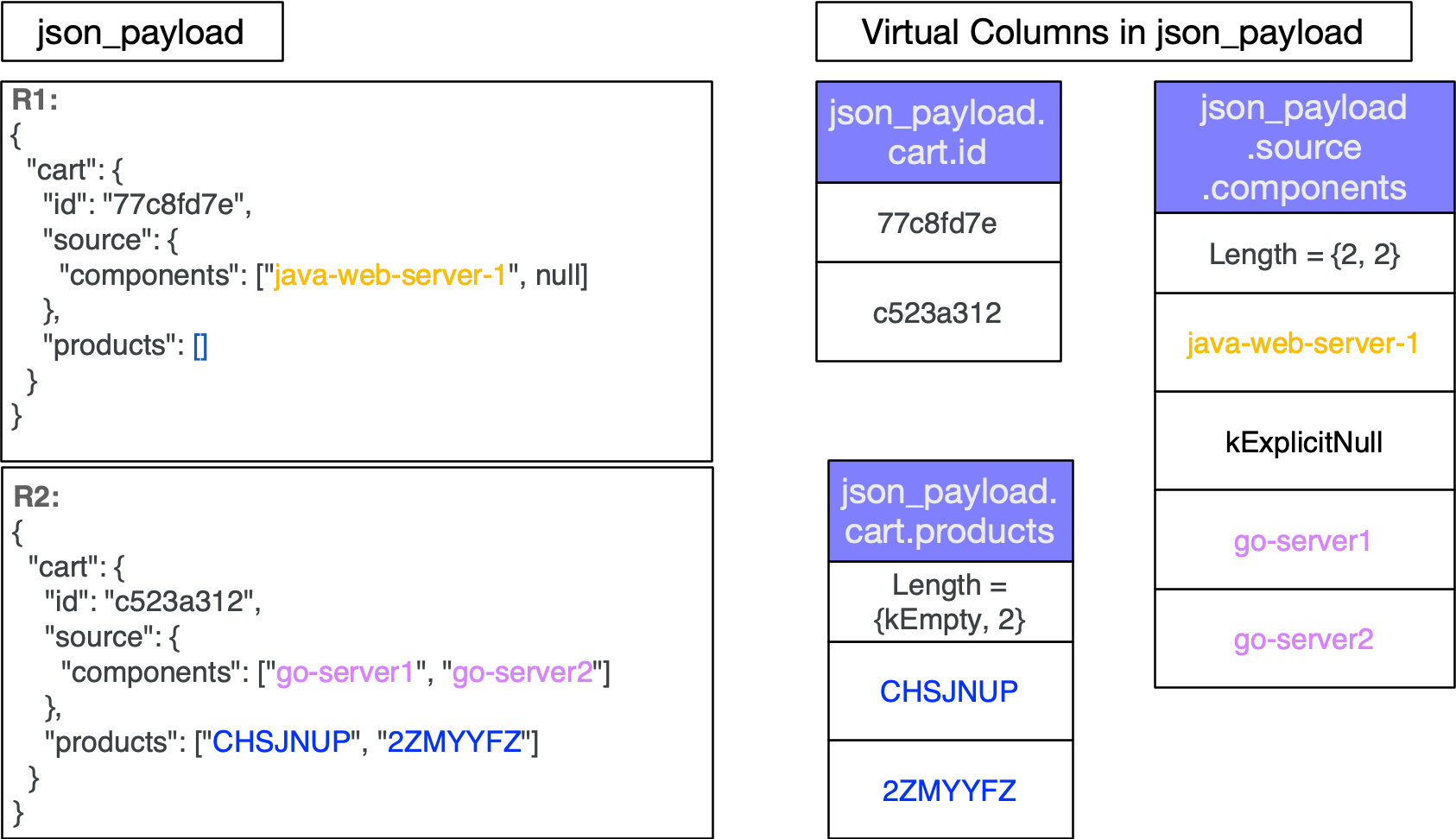
図 1: 指定されたレコード R1 および R2 の仮想列を示しています。
BigQuery のネイティブ JSON データ型は、JSON オブジェクト、配列、スカラー型、JSON null(「null」)、空配列を理解することで、JSON のネスト構造を維持します。
ネイティブ JSON データ型の基礎となるファイル形式の Capacitor は、レコードの並べ替えを使用して類似したデータや型をまとめ、維持します。レコードの並べ替えの目的は、行全体のランレングス圧縮が最大限効果を発揮し、仮想列が小さくなる最適なレイアウトを見つけることです。ファイル内の行範囲において、特定のキーが異なるデータ型(たとえば、整数と文字列)を持つ場合、レコードの並べ替えにより、文字列データ型を持つ行と整数データ型を持つ行がグループ化されます。その結果、両方の仮想列において欠損値のランレングス圧縮されたスパンが発生し、より小さな列が生成されます。列のサイズを説明するため、図 2 に、ソース JSON データ全体で整数または文字列のいずれかである単一のキー「source_id」を示します。これにより、型に基づいて 2 つの仮想列が生成されます。並べ替えて RLE を適用すると、小さな仮想列が生成されることを示しています。わかりやすく欠損値を示すために、「kMissing」を使用します。
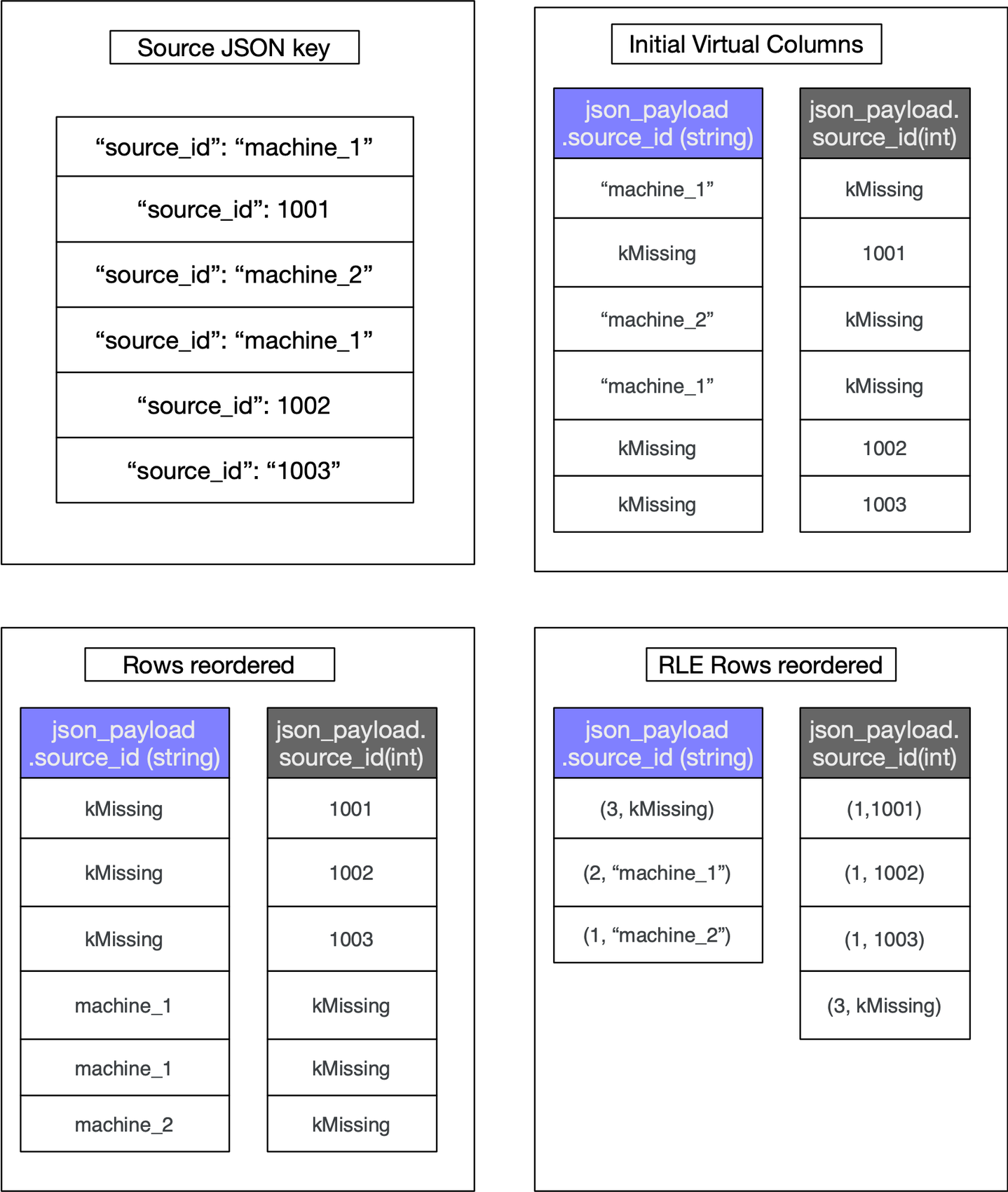
図 2: 行の並べ替えが列サイズに及ぼす影響を示しています。
Capacitor は、適切に構造化されたデータセットを処理するために特別に設計されました。これは、さまざまな型が混在し、さまざまな形状をとる JSON データにとっての課題でした。ここでは、JSON データ型をネイティブにサポートする次世代の Capacitor を構築する中で、私たちが克服した課題の一部をご紹介します。
- キーの追加 / 削除
JSON キーはオプション要素として扱われるため、キーのない行では欠損としてマークされます。 - スカラー型の変更
行をまたいで string、int、bool、float などのスカラー型を変更するキーは、個別の仮想列に書き込まれます。 - 非スカラー型による型の変更
オブジェクトや配列などのスカラー以外の値の場合、値は解析が効率的な最適化されたバイナリ形式で保存されます。
取り込み時に、JSON データを仮想列に細断した後、各仮想列の論理サイズは INT64、STRING、BOOL などの特定の型のデータサイズ [https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#data_type_sizes] に基づいて計算されます。したがって、JSON 列全体のサイズは、JSON 列に保存されている各仮想列のデータサイズの合計になります。この累積サイズはメタデータに保存され、任意のクエリが JSON 列に関わった場合の論理推定サイズの上限となります。
これらの手法により、元の JSON データと比較して個々の大幅に小さい仮想列が生成されます。たとえば、以下で説明する bigquery-public-data.hacker_news.full の移行バージョンを JSON 列として保存すると、STRING と比較して論理非圧縮バイトを 25% 直接節約できます。
JSON ネイティブ データ型によるクエリ パフォーマンスの向上
STRING 列に保存された JSON データでは、特定の JSON パスでフィルタする場合やプロジェクト固有のパスのみでフィルタする場合、JSON STRING 行全体をストレージから読み込んで解凍し、各フィルタと投影式を一度に 1 行ずつ評価する必要があります。
一方、ネイティブ JSON データ型では、必要な仮想列のみが BigQuery によって処理されます。投影とフィルタ オペレーションを可能な限り効率化するために、JSON オペレーションのコンピューティングとフィルタ プッシュダウンのサポートを追加しました。投影とフィルタ オペレーションは、仮想列に対してベクトル化された方法でオペレーションを実行できる埋め込み評価レイヤにプッシュダウンされるため、STRING 型と比較して非常に効率的になります。
クエリが実行されると、SQL クエリでリクエストされた JSON パスを返すためにスキャンされた仮想列のサイズに基づいてのみ、お客様に料金が請求されます。たとえば、以下に示すクエリでは、ペイロードがキー「reference_id」と「id」を含む JSON 列の場合、JSON キーを表す特定の仮想列、つまり「reference_id」と「id」のみがデータ全体でスキャンされます。
注: 見積もりには、クエリ対象の仮想列に関する特定の情報ではなく、常に合計 JSON サイズの上限が表示されます。
JSON 型の場合、オンデマンド課金にはスキャンが必要な論理バイト数が反映されます。各仮想列には INT64、FLOAT、STRING、BOOL などのネイティブ データ型があるため、データサイズの計算はスキャンされた各列の「reference_id」と「id」のサイズの合計となり、標準の BigQuery データ型サイズ [https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#data_type_sizes] に従います。
BigQuery エディションでは、最適化された仮想列は、JSON blob 全体を読み込んで JSON 文字列からパスを抽出するのではなく、特定の列をスキャンするため、JSON 文字列を変更せずに保存する場合と比較して、IO と CPU の使用量がはるかに少ないクエリを実行できます。
新しい型では、BigQuery は SQL クエリによってリクエストされた JSON 内のパスだけを処理できるようになりました。これにより、クエリのコストを大幅に削減できます。
たとえば、STRING 型と JSON 型の両方を含む一般公開データセット「biquery-public-data.hacker_news.full」の移行バージョンから「$.id」や「$.parent」などのいくつかのフィールドを投影するクエリを実行すると、同じデータの処理バイト数が 18.28GB から 514MB に減少し、97% の削減が確認できました。
次のクエリは、「str_payload」の STRING 列と「json_payload」の JSON 列の両方を含む一般公開データセットからテーブルを作成し、宛先テーブルに保存するために使用しました。
概要
Capacitor ファイル形式の改良により、今日の半構造化データのワークロードに必要な柔軟性が実現しました。JSON データを仮想列に分割するとともに、コンピューティングやフィルタ プッシュダウンなどの機能拡張を追加したことで、有望な結果が得られています。JSON データは細断されるため、リクエストされた JSON パスに一致する仮想列のみが BigQuery によってスキャンされます。コンピューティングとフィルタ プッシュダウンにより、ベクトル化された方法でデータ評価レイヤに最も近い作業をランタイムが実行できるようになり、より優れたパフォーマンスを発揮します。最後に、これらの選択により、圧縮率が向上して IO / CPU 使用量が削減できるようになった(列が小さい = IO が少ない)結果、定額料金予約のスロット使用量とオンデマンド使用に対して課金されるバイト数が削減されます。
ストレージとクエリの最適化だけでなく、さまざまな JSON SQL 関数を提供することで、プログラマビリティと使いやすさにも投資しています。最近リリースされた新しい JSON SQL 関数に関する最新のブログ投稿もご覧ください。
次のステップ
今すぐ BigQuery で JSON ネイティブ データ型に変換しましょう。
STRING JSON 列を含むテーブルをネイティブ JSON 列を含むテーブルに変換するには、次のクエリを実行して結果を新しいテーブルに保存するか、宛先テーブルを選択します。
JSON 関数やその他のドキュメントは、https://cloud.google.com/bigquery/docs/reference/standard-sql/json_functions でご確認いただけます。
- ソフトウェア エンジニア、Nagesh Susarla
- プロダクト マネージャー、Eric Schmidt


