MySQL の障害復旧をサポートするマルチリージョン アーキテクチャ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 3 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
アプリケーションがアクセスするデータベースに対して、企業は極端なまでの信頼性を求めますが、たとえ細心の注意を払って工夫を重ねても、マシンのクラッシュやネットワークの分断によってデータベース エラーは必ず発生します。とはいえ、障害の発生をあらかじめ織り込んだ適切なプランを立てておけば、障害が発生したときに、より迅速に復旧させることが可能になります。
この投稿では、Compute Engine 上の MySQL で高可用性と障害復旧を実現する、リージョン永続ディスクとロード バランサを使用したデータベース アーキテクチャの 1 つをご紹介します。
データベース アーキテクチャは、エラーの発生を想定し、データを失うことなく障害からすばやく回復できるアプローチを提供しなければなりません。このアプローチは、目標復旧時間(RTO)と目標復旧地点(RPO)で表され、サービスを利用できなくなる時間とデータをどこまで保存しておくかを設定して測定する方法を提供します。
データベース エラーが発生したら、RTO に基づいて、できるかぎり短時間でデータベースを復旧させる必要があります。データ損失は極力少なく、可能なら損失が一切ないようにしたいところです。また、理想的な RPO はデータベースの整合性がとれている最後の状態です。
この目標の実現をデータベース アーキテクチャとデプロイメントの観点から支えるのは、高可用性と障害復旧という 2 つの異なる概念です。両者を同時に組み込めば、最も広い範囲の障害やインシデントに対応できるアーキテクチャを実現できます。
回復力の高いデータベース アーキテクチャ
高可用性のアーキテクチャではデータベース インスタンスを 2 つ以上のゾーンに配置します。ゾーンのサーバーに障害が発生したり、ゾーンがアクセス不能になったりした場合は、別のゾーンのインスタンスが処理を引き継ぎます。下の図では、ゾーン zn1 と zn2 にそれぞれ 1 つずつインスタンスがあります。ゾーン手前のロード バランサは、読み取りおよび書き込みのクエリに対応する正常なデータベース インスタンスにトラフィックを誘導します。
一方、障害復旧のアーキテクチャでは第 2 のリージョンに第 2 の高可用性データベース構成を追加します。第 1 のリージョンがアクセス不能になったり障害を起こしたりすると、第 2 のリージョンが処理を引き継ぎます。下の図は Primary と DR の 2 つのリージョンを示しており、データは Primary リージョンから DR リージョンへとレプリケートされ、DR リージョンはデータベースの整合性がとれている最後の状態を引き継ぎます。リージョンの手前のロード バランサは、読み取りおよび書き込みのクエリを処理しているリージョンにトラフィックを誘導します。このアーキテクチャは下図のとおりです。
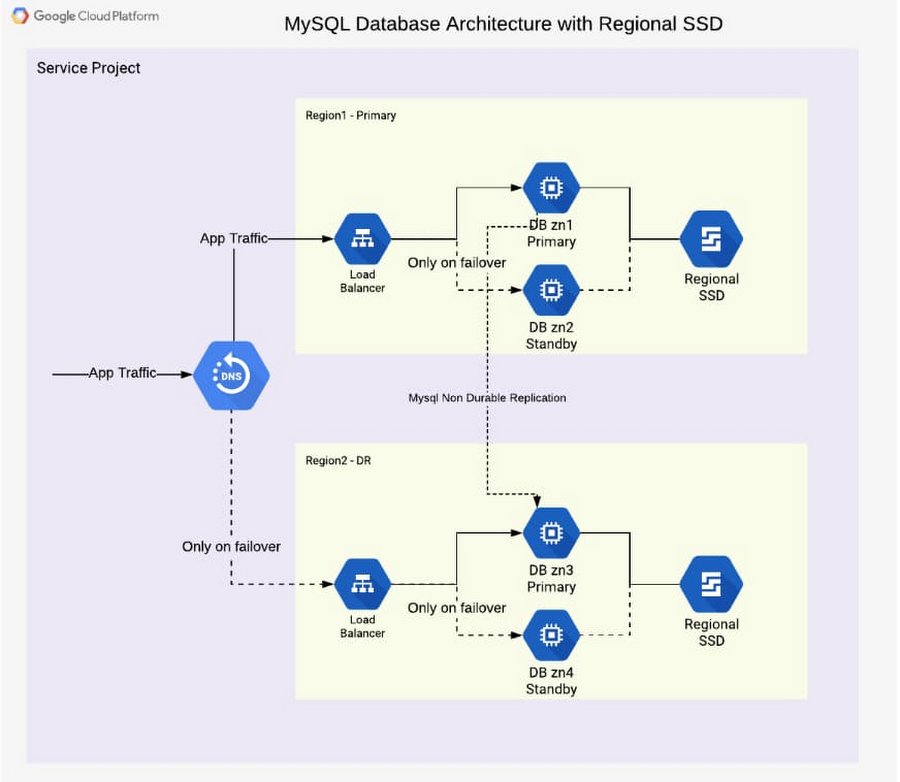
ゾーン障害時のフェイルセーフを保証するため、このような構成のデータベース インスタンスに加え、リージョン永続ディスクをデプロイして同時に 2 つのゾーンにデータが書き込まれるようにします。これは、リージョン内で MySQL レベルのレプリケーションをスキップできる Google Cloud の大きなメリットです。ディスクへの書き込み処理は 2 つのゾーンで同期的に実行されます。Primary ゾーンに障害が発生すると、リージョン永続ディスクに Standby インスタンスがマウントされ、データベース サービス(MySQL)の実行が開始されます。これにより、高可用性の実現にあたってレプリケーションの遅延やデータベースの状態を心配する必要はなくなります。
障害復旧の観点から見ると、障害発生時の流れは次のようになります。
正常な安定状態でのデータベース処理
障害発生により、リージョン使用不能、またはデータベース インスタンス アクセス不能
フェイルオーバー実行の可否を判断(リージョンがすぐに使用可能になったり、インスタンスがすぐに反応したりする見込みがある場合)
手作業による DNS の更新。これにより、アプリケーション トラフィックは第 2 のリージョンにリダイレクトされる
復旧後の第 1 のリージョンへのフォールバック。第 2 のリージョンは完全な形で構築されたデプロイメントなので、フォールバックはオプション
高可用性の観点からは、障害発生時の流れは次のようになります。
正常な安定状態でのデータベース処理
データベース インスタンスの障害、または使用不能
Standby インスタンスの起動
リージョン SSD のマウント、データベースの実行開始
ロード バランサによるアプリケーション トラフィックの Standby インスタンスへの自動リダイレクト
障害または使用不能インスタンスが復旧したあと、フォールバックするかどうかの判断
本稿で紹介したデータベース アーキテクチャは、障害復旧をサポートする高可用性アーキテクチャです。リージョン永続ディスクとロード バランサを使用すれば、回復力のあるデータベース デプロイメントを容易に実現できます。
ロード バランサの詳細はこちらを、リージョン永続ディスクの詳細はこちらをご覧ください。障害復旧と高可用性の一般的なプロセスと詳細な手順については、リファレンス ガイドの最初の部分をご覧ください。実際に試していただき、アーキテクチャと 2 つの主要なフェイルオーバー プロセスに慣れ親しんでいただければと思います。
- By Shashank Agarwal, Database Migration Engineer and Christoph Bussler, Solutions Architect, Google Cloud


