読み取りのスケーラビリティを合理化する Cloud SQL の自動スケーリングを備えた読み取りプール
Phil Sung
Software Engineer
Shahzeb Farrukh
Product Manager
※この投稿は米国時間 2026 年 3 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
データベースから頻繁に読み取りを行うアプリケーションの一般的なパターンは、読み取り負荷の高いワークロードをリードレプリカにオフロードすることです。これにより、アプリケーションをスケールしても、プライマリ データベース インスタンスでの重要な書き込みオペレーションに影響が及ぶことはありません。しかし、このような読み取り負荷の高いワークロードでは、単一のリードレプリカの容量を簡単に超えてしまう可能性があります。デベロッパーはロードバランサの背後に複数のレプリカを手動で実装できますが、この方法は複雑で、保守とスケーリングが困難です。
Cloud SQL は、MySQL と PostgreSQL の読み取りプールを使用して、読み取りをスケールするための簡素化されたフルマネージド ソリューションを提供します。この機能を使用すると、単一の読み取りエンドポイントからアクセスできる複数のリードレプリカをプロビジョニングできるため、アプリケーションを変更することなく、リードレプリカを簡単に追加および削除できます。効率をさらに向上させるために、Google は最近、Cloud SQL の読み取りプールに自動スケーリングを導入しました。これにより、リアルタイムのアプリケーション ニーズに基づいて読み取り機能が動的に調整されます。自動スケーリングを備えた読み取りプールは、 Cloud SQL Enterprise Plus エディションで一般提供されています。詳しくは、MySQL と PostgreSQL のドキュメントとリリースノートをご覧ください。
読み取りプールを使用する理由
プライマリ インスタンスからレプリケートする読み取りプールを作成すると、Cloud SQL は 読み取りプールノードと呼ばれる複数のリードレプリカを自動的にプロビジョニングし、クエリをノードにラウンドロビン方式でディスパッチする単一のロードバランサ(読み取りエンドポイント)を作成します。1 つのプールには 1~20 個のノードを含めることができます。
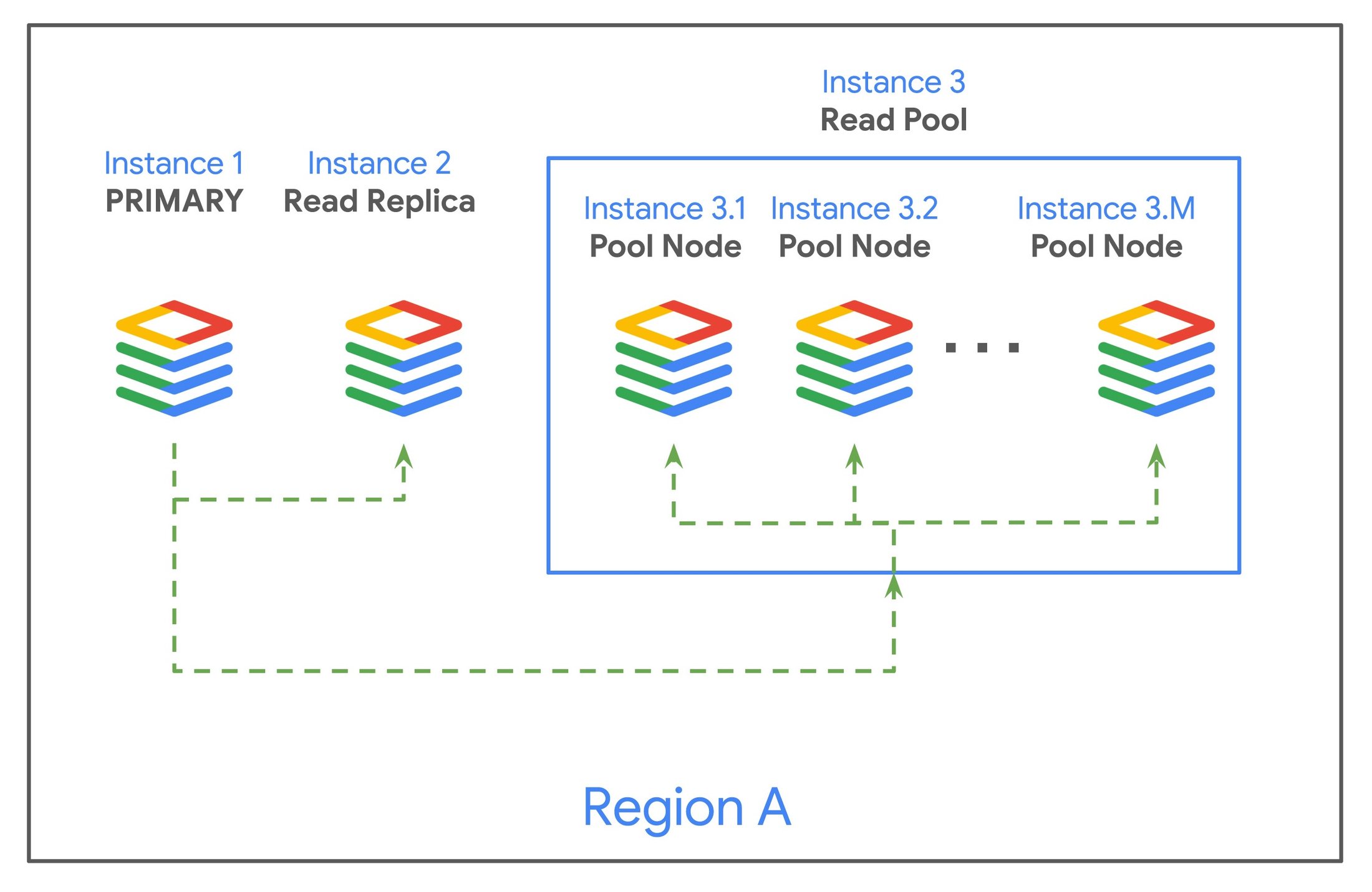
読み取りプールは単一のエンティティとして管理されるため、運用上の負担が軽減されます。プールは同種のノードのセットを表します。データベース フラグ、VM タイプ、その他のパラメータの更新などの構成変更を行うと、その変更はプール内のすべてのノードに自動的に適用されます。また、ワークロードの変化に応じて、プールからノードの追加や削除ができるため、いつでもスケールアウトとスケールインが可能です。すべてのクエリは読み取りエンドポイントのロードバランサを通過するため、プール内のノードが更新、追加、削除されても、アプリケーションを再構成する必要はありません。
読み取りプールの自動スケーリングでスケーリングが容易に
読み取りプールは、ワークロードが変動するシナリオで真価を発揮します。Cloud SQL の読み取りプール向けの自動スケーリングの一般提供が開始されたことで、こうした変動の管理がさらに簡単になりました。
読み取りプールの自動スケーリングの主なメリットは以下のとおりです。
-
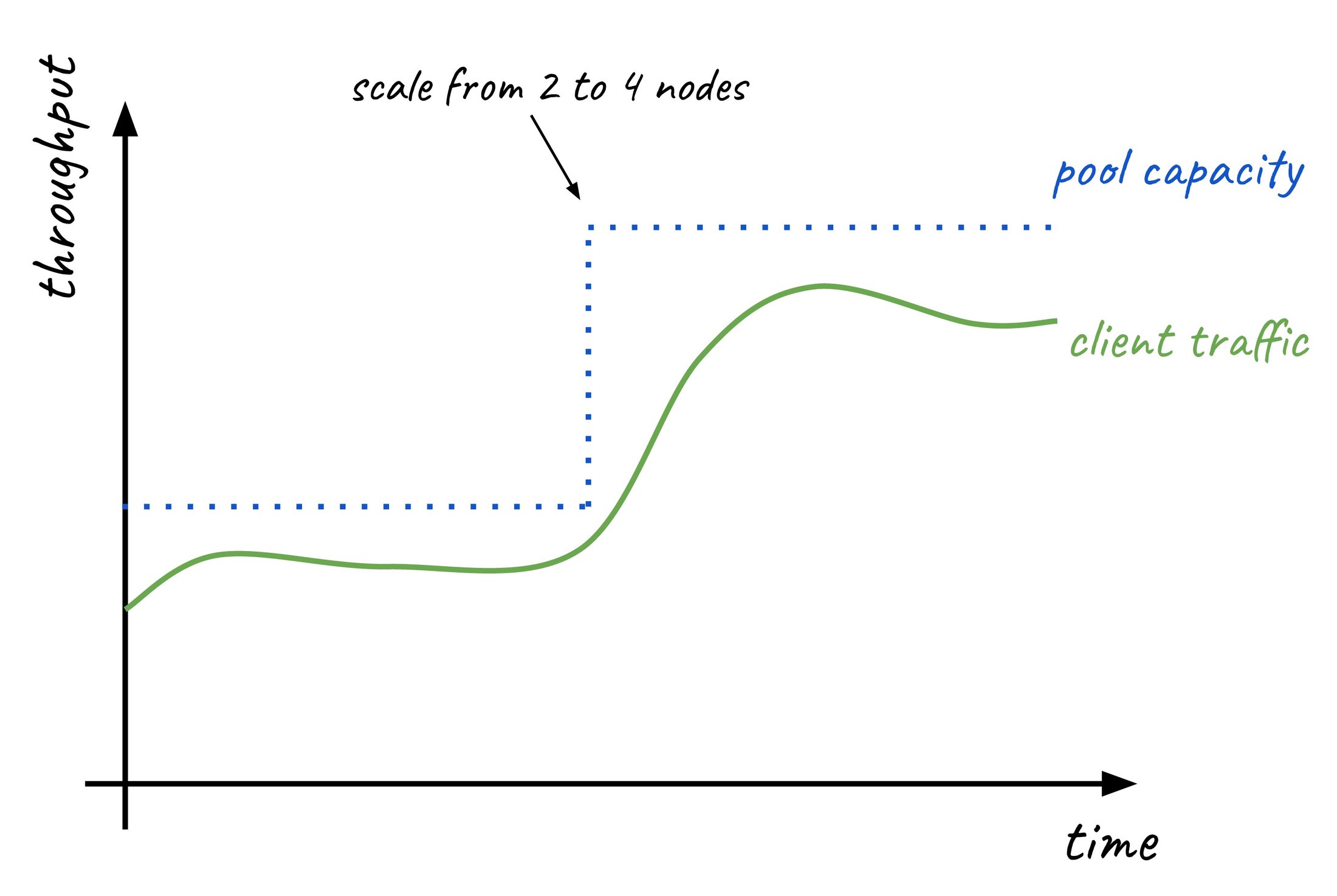
トラフィックの急増に対する自動管理: データベース接続または CPU 使用率に基づいてプールが最大 20 個のノードまで動的にスケールアップされるため、需要がピークに達してもアプリケーションの応答性を維持できます。
-
オペレーションの簡素化: 自動スケーリングは単一の読み取りエンドポイントと統合されているため、基盤となるノードが調整されても、アプリケーションは同じアドレスに接続されたままになります。
-
費用の最適化: トラフィックが少ない期間は自動的なスケールインによって、実際に使用したリソースに対してのみ料金が発生するため、オーバープロビジョニングによって発生する費用を回避できます。
Cloud SQL が読み取りプールで可用性を向上させる仕組み
ミッション クリティカルな信頼性を実現するように設計された Cloud SQL の読み取りプールは、可用性が高い読み取りワークロードの基盤となります。ノードを 2 つ以上維持することで、読み取りプールは 99.99% の可用性 SLA によってサポートされ、これにはメンテナンスのダウンタイムも含まれます。これを実現するために、Cloud SQL は次のように環境をインテリジェントに管理します。
-
読み取りプールにノードを追加する際、既存の接続は、既存のノードで中断することなく続行されます。新しい接続は新たに追加されたノードに割り当てられる場合があります。既存の接続が処理を完了すると、負荷はすべてのノード間で均等に分散されるようになります。
-
2 つ以上のノードを含む読み取りプールの場合、VM タイプやデータベース フラグを変更したり、その他の大半の構成更新を実行したりすると、読み取りプールはダウンタイムがほぼゼロで更新されます。
-
他の Cloud SQL インスタンスと同様に、Cloud SQL は読み取りプール インスタンスの基盤となるハードウェアの問題を自動的に検出して修復します。異常が検出されたノードは、ロードバランサのローテーションから削除され、それを置き換えるための新しいノードが作成されます。
自動スケーリングを備えた読み取りプールの有効化と使用
読み取りプールは、ワークロードが大きく変動する環境で優れた性能を発揮します。Cloud SQL の自動スケーリングでは、CPU 使用率やデータベース接続などの主要な指標の目標値を設定すると同時に、ノードの最小数と最大数を定義できます。
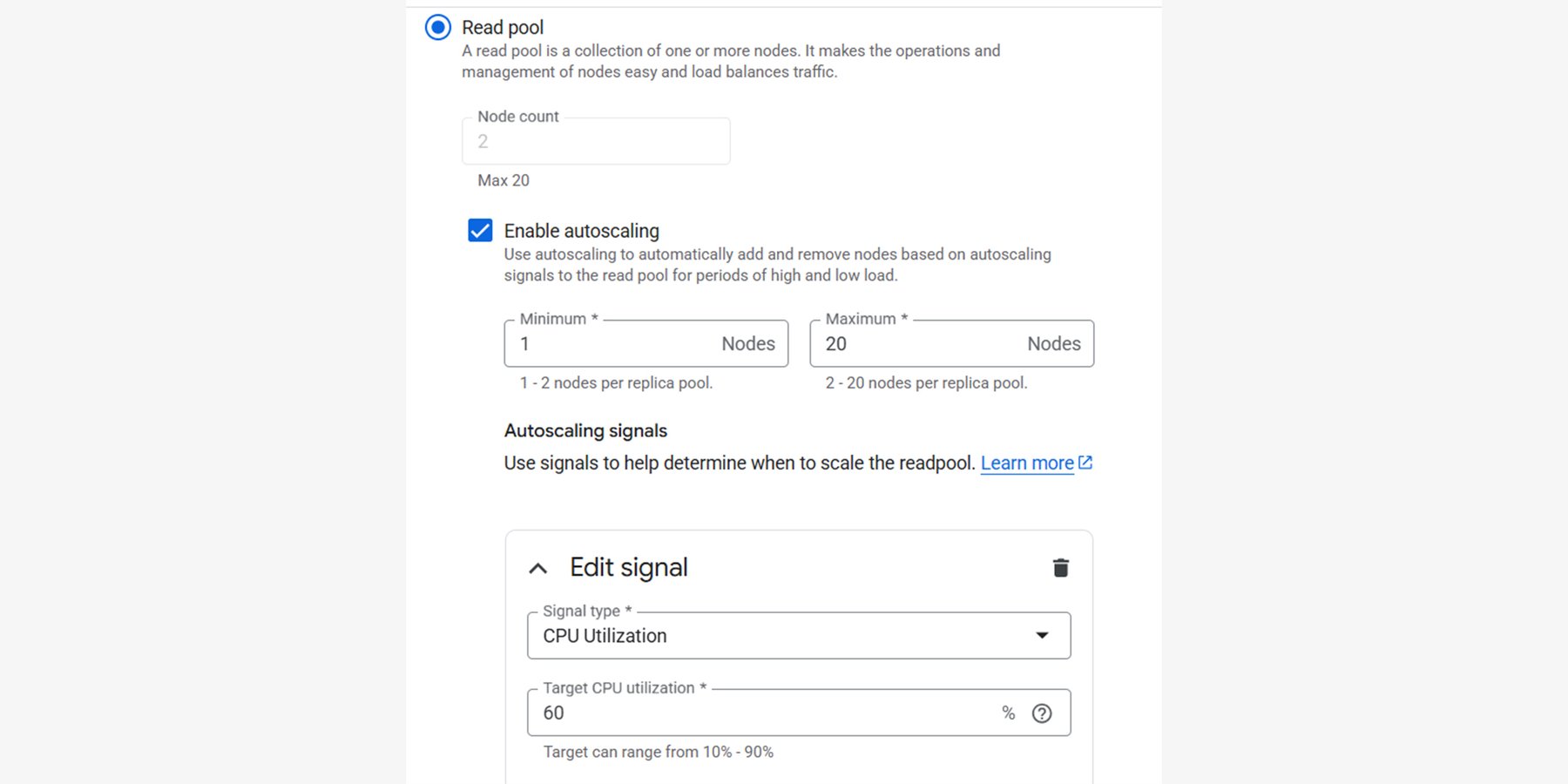
小売業界は良い例になります。トラフィックが、日々のサイクル、季節の変化、期間限定セールなどに基づいてよく変動するからです。こうしたピーク時に動的にスケールアウトし、需要が落ち着いたらスケールインすることで、オーバープロビジョニングされた環境のオーバーヘッドなしに、優れたカスタマー エクスペリエンスを提供できます。
Enterprise Plus エディションのインスタンスをすでに作成している場合は、そのインスタンスからレプリケートする読み取りプールを作成できます。次のコマンドは、2 つのノードを含む読み取りプールを作成し、自動スケーリングを有効にします。自動スケーリングは、CPU 使用率を 60% 前後で維持しながら、ノードを 2~10 個の間でスケールするように構成されています。
読み取りエンドポイントの IP アドレスは、Google Cloud コンソールでインスタンスを確認するか、gcloud CLI を使用して取得できます。この IP アドレスは、プールの存続期間中は変更されません。
既存の読み取りプールがある場合は、簡単に自動スケーリングを有効にできます。
このコマンドは、ノードが 2~10 個の間で自動的にスケールされるように myreadpool を構成します。その際、ノードあたりの平均データベース接続数が最大 100 になるように調整されます。
自動スケーリングは、変動するワークロードのほとんどに推奨されますが、必要に応じてノード数を直接更新することで、読み取りプールを手動でスケールすることもできます。
使ってみる
新しい自動スケーリング機能を備えた読み取りプールを使用することで、多数の読み取りレプリカの管理に伴う面倒な作業を回避できるほか、アプリケーションに必要な読み取り容量を必要に応じて提供でき、過剰な費用を回避できます。今すぐ始めるには、以下のリソースをご覧ください。
-
読み取りプールに関する Cloud SQL のドキュメント
-
読み取りプールについて(MySQL、PostgreSQL)
-
読み取りプールの作成と管理(MySQL、PostgreSQL): gcloud CLI、Terraform、REST API のコマンド例を含む
-
読み取りプールの自動スケーリング(MySQL、PostgreSQL): gcloud CLI、Terraform、REST API のコマンド例を含む
-
新しい Cloud SQL の無料トライアルにご登録ください。これは、新規および既存の Google Cloud ユーザーの皆様を対象とした、Cloud SQL(PostgreSQL および MySQL)が提供するプレミアムなエンタープライズ グレードの機能をご利用いただくことを目的とした 30 日間の専用プログラムです。
- ソフトウェア エンジニア、Phil Sung
- プロダクト マネージャー 、Shahzeb Farrukh
