Firestore によるスケーラブルなリアルタイム アプリケーションの構築
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
Firestore は、サーバーレスでフルマネージドの NoSQL ドキュメント データベースです。また、従来のサーバーサイド アプリケーションにとって最適な選択肢であり、ネイティブ モードの Firestore では迅速かつ柔軟なウェブやモバイルアプリの開発に対応した Backend as a Service(BaaS)モデルも提供しています。バックエンド インフラストラクチャの管理を必要としないアプリケーションを構築します。
このモデルの重要な要素は、データがクラウドからユーザーのデバイスに直接同期されるリアルタイム クエリです。これにより、レスポンシブなマルチユーザー アプリケーションを簡単に作成できます。Firestore BaaS は、リアルタイム クエリでデータを消費する数百万人の同時ユーザーを常時スケーリングできますが、これまでは、データベースごとに 1 秒あたりの書き込みオペレーションの回数は 10,000 回という上限がありました。大半のアプリケーションにとっては十分な回数ですが、さらに高いスループットを必要とする極端なユースケースがあることを Google は把握していました。
このたび、この上限を撤廃し、お客様の書き込みトラフィックの増加に応じてシステムが自動的にスケールアップするモデルに移行することをお知らせします。このモデルは、完全な下位互換性を確保しているため、既存のアプリケーションを変更する必要はありません。
システム アーキテクチャの詳細と、より高いスケールの実現に向けた変更点について、続けてお読みください。
リアルタイム クエリのライフサイクル
リアルタイム クエリでは、Firestore データベース内の特定のデータにサブスクライブすることで、データが変更されたときに更新がすぐに反映され、ユーザーのデバイスでローカル キャッシュを同期します。次のサンプルコードでは、Firestore ウェブ SDK を使用して、「cities」というコレクション内の「SF」という鍵を持つドキュメントに対してリアルタイム クエリを発行し、このドキュメントのコンテンツが更新されるたびに、コンソールにメッセージを記録します。
リアルタイム クエリについては、Firestore の内部では、従来のデータベース システムにおけるリクエスト / レスポンス クエリの逆として機能すると考えられます。つまり、インデックスをスキャンしてクエリに一致する行を探すのではなく、システムによってアクティブなクエリを追跡し、データの一部に変更があれば、レジストリへの変更をアクティブなクエリと一致させ、クエリの呼び出し元にその変更を転送します。
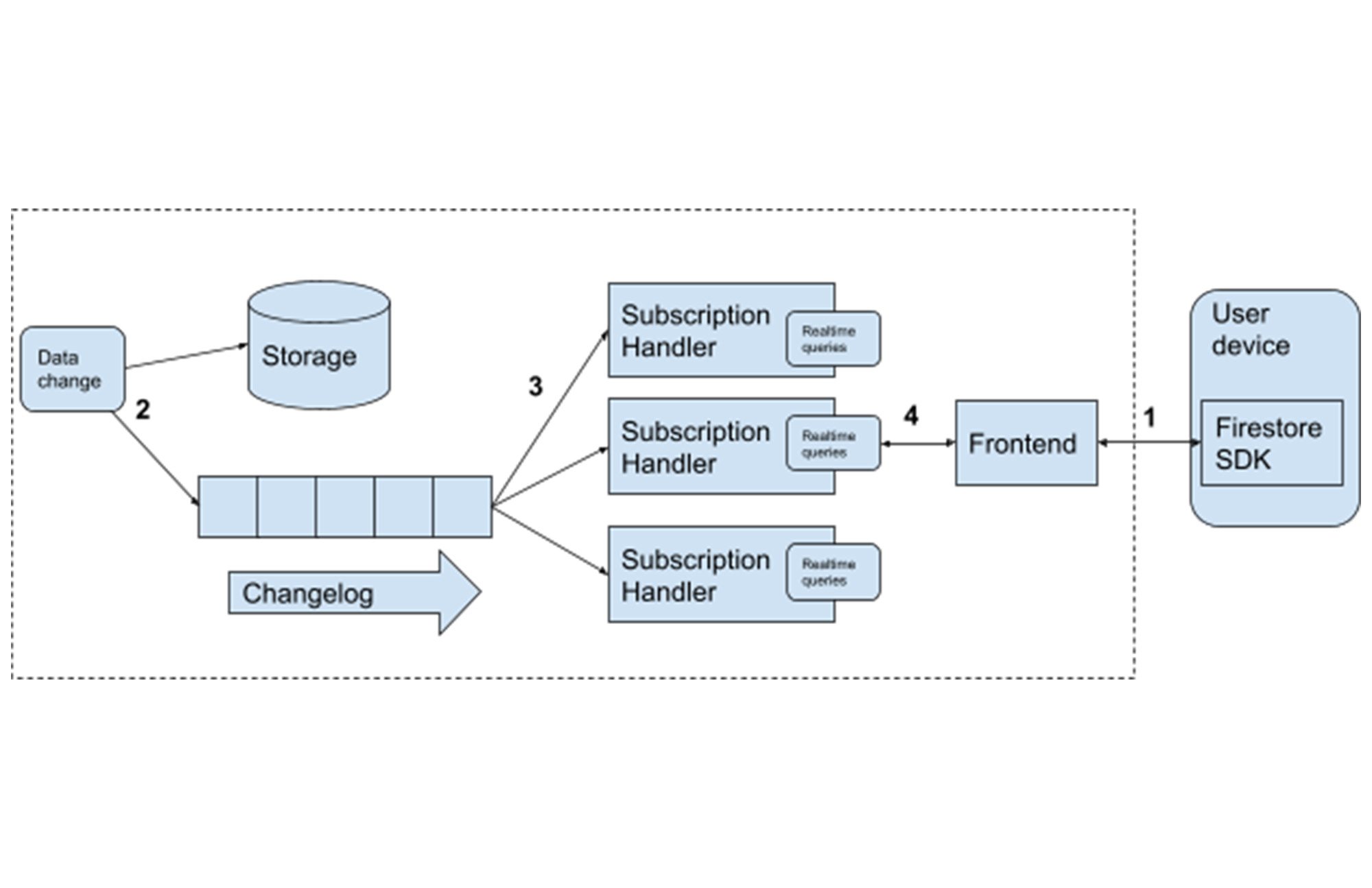
このシステムは次のようなコンポーネントで構成されています。
ユーザーのデバイスから Firestore フロントエンド サーバーへの接続を確立する Firestore SDK。
onSnapshotAPI 呼び出しを使用して、サブスクリプション ハンドラに新しいリアルタイム クエリを登録します。Firestore でデータが変更されるたびに、変更前後のデータは複製されたストレージに保持され、更新の commit 時間順の変更履歴を管理するサーバーにトランザクションとして送信されます。これがリアルタイム クエリを処理する起点となります。
各変更は、変更履歴からサブスクリプション ハンドラのプールにファンアウトされます。
このようなハンドラは、アクティブなリアルタイム クエリが特定のデータ変更に一致するかを確認し、一致した場合(上記の例では、「cities/SF」ドキュメントに変更があった場合)、データをフロントエンドに転送して、その後 SDK やユーザーのアプリケーションに転送します。
Firestore のスケーラビリティで重要なのは、変更履歴からサブスクリプション ハンドラ、フロントエンドへのファンアウトです。これにより、1 つのデータ変更を効率的に伝播させ、何百万ものリアルタイム クエリを処理し接続中のユーザーにサービスを提供できます。高可用性は、こうしたすべてのコンポーネントで構成される多数のレプリカを、複数のゾーン(マルチリージョン デプロイの場合は複数のリージョン)で実行することで実現されます。
これまで、変更履歴は Firestore データベースごとに単一のバックエンド サーバーで管理されていました。そのため、Firestore ネイティブの最大書き込みスループットには、1 台のサーバーが処理できる範囲という上限がありました。
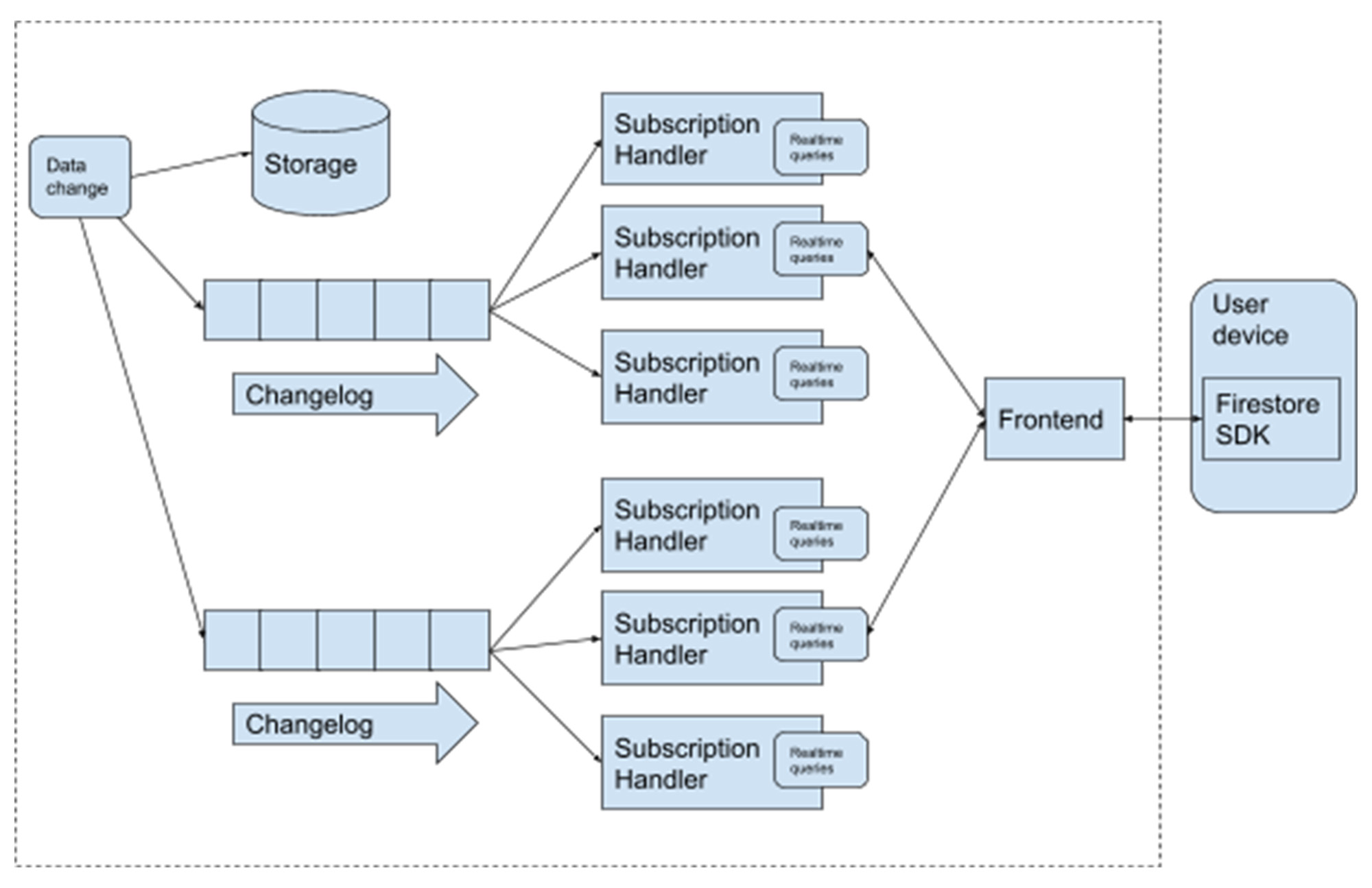
今回の Firestore のアップデートにおける大きな変更点は、変更履歴サーバーが書き込みトラフィックに応じて水平方向に自動スケーリングされるようになったことです。データベースの書き込みレートが 1 台のサーバーで処理できる範囲を超えると、変更履歴は複数のサーバーに分割され、クエリ処理は 1 つのソースではなく複数のソースからのデータを使用します。これはすべて、必要に応じてバックエンド システムによって透過的に行われるため、今回改善された機能を利用するためにアプリケーションを変更する必要はありません。
Firestore を大規模に使用する場合のベスト プラクティス
今回の Firestore の改良により、非常にスケーラブルなアプリケーションを簡単に作成できるようになりました。そこで、アプリケーションが最適に動作するよう、設計する際には以下のベスト プラクティスを考慮してください。
ホットスポットを回避するためのトラフィック制御
Firestore のストレージ レイヤと変更履歴には、自動で負荷を分割する機能があります。つまり、トラフィックが増加すると、自動的に複数のサーバーに分散されます。ただし、システムが反応するまでにある程度時間を要する場合があり、一般的な分割オペレーションでは、反映されるまでに数分かかることがあります。
自動で負荷の分割を行うシステムでよく発生する問題は、負荷の分割機能が追いつかないほど急激にトラフィックが増加するホットスポットです。ホットスポットが発生すると、一般的には書き込みオペレーションのレイテンシが増加し、リアルタイム クエリの場合、ホットスポットが発生しているデータをリッスンしているクエリの通知が遅くなることもあります。
ホットスポットを回避する最善策は、トラフィックの急増を抑制することです。適切な目安として、「555 ルール」に沿って操作することをおすすめします。コールド スタートの場合、オペレーションは 1 秒間に 500 回で開始し、その後、5 分ごとにトラフィックを最大 50% ずつ増やしていきます。トラフィック レートがすでに安定している場合は、より積極的にレートを増加させることができます。
Firestore Key Visualizer は、ホットスポットを検出し把握するための優れたツールです。詳細については、こちらのツール ドキュメントと、こちらのブログ投稿をご覧ください。
ドキュメント、結果セット、バッチを小さく保つ
リアルタイム クエリによる低レイテンシなレスポンス時間を実現するためには、データを無駄のない状態に保つことが重要です。ペイロード(フィールド数、フィールド値のサイズなど)が小さいドキュメントは、クエリシステムによって迅速に処理され、アプリケーションの応答性を維持できます。一方、サイズの大きなバッチの更新、大量のドキュメント、大規模なデータセットを読み込むクエリでは、処理速度が低下し、データが commit されてから通知が送信されるまでの遅延が長くなる場合があります。これは、多くの場合、高いスループットでバッチ処理が行われる従来のデータベースと比較すると、直感に反することかもしれません。
クエリのファンアウトを制御する
Firestore のシャーディング アルゴリズムでは、同じコレクションまたはコレクション グループ内のデータを同じサーバーに配置しようとします。これは、クエリが接続する必要のあるスプリットの数を最小限に抑えながら、書き込みスループットを最大化することを目的としています。しかし、特定のパターンでは、依然として最適でないクエリ処理が行われる可能性があります。たとえば、アプリケーション データの大部分をひとつの巨大なコレクションに保存している場合、そのコレクションに対するクエリは、たとえクエリにフィルタを適用したとしても、すべてのデータを読み込むために多くのスプリットと接続しなければならない場合があります。その結果、テール レイテンシの変動が大きくなるリスクが高まる可能性があります。
これを回避するには、スプリットの数を減らし、クエリを効率的に処理できるようにスキーマとアプリケーションを設計します。データをより小さなコレクションに分割し、それぞれの書き込みレートを小さくすると良いでしょう。お客様のアプリケーションやユースケースにおける動作や必要な対応を詳細に把握するために、負荷テストをおすすめします。
次のステップ
Firestore を使用したスケーラブルなアプリケーションの構築に関する詳細を読む
Firestore のリアルタイム更新を取得する方法を確認する
- Firestore 用の Key Visualizer の詳細を確認する
- Firestore サービスおよびスケーラビリティ担当テクニカル リーダー兼マネージャー Per Jacobsson


