Cloud Spanner の ExecuteQuery リクエストの裏側
Google Cloud Japan Team
※この投稿は米国時間 2021 年 1 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
この投稿では、アプリケーションが Cloud Spanner に対してクエリを実行するときに行われる仕組みを明らかにします。Spanner はどのようにして任意の SQL ステートメントを取得し、データのロケーションを特定して、数ミリ秒でレスポンスを返すのでしょうか。SIGMOD’17 のドキュメントに記載されているコンセプトの一部を取り上げ、どのように実行されるかについて、順を追ってご説明します。
Spanner のデータのロケーションの基礎
この投稿の残りの部分を理解するには、Spanner におけるデータ レイアウトを理解する必要があります。
データはテーブルにまとめられており、テーブルはルートレベルであるか、別のテーブルにインターリーブされています。インターリーブ操作では、「親」行に近い主キー接頭辞を共有する「子」テーブルの行を格納するよう、Spanner に命令します(「スキーマとデータモデル」ドキュメントの親子テーブル関係を参照)。たとえば、Singers テーブルと Albums テーブルを持つ Spanner サンプル スキーマを使用すると、次のようになります。
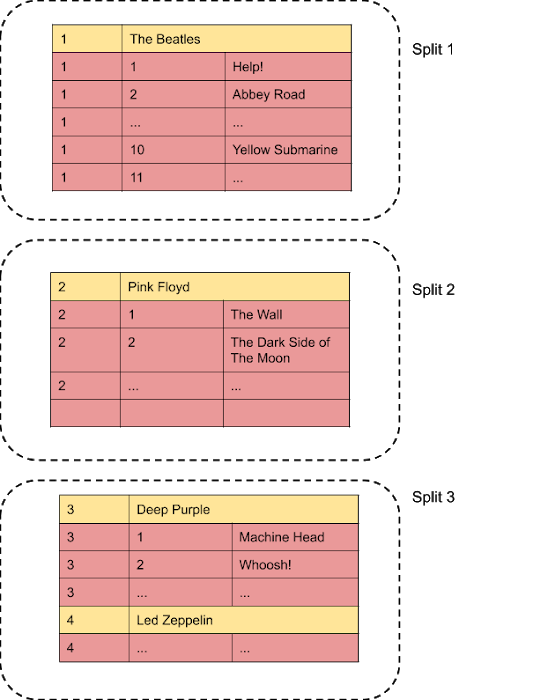
データはスプリットに格納されます。スプリットでは、最上位テーブルの主キーによって分割点が決まります。結果として得たスプリットのキー範囲はそれぞれ、[Singers(-∞), Singers(1)) - 非表示、[Singers(1), Singers(2))、[Singers(2), Singers(3))、[Singers(3), Singer(+∞)) です。
各スプリットは個別に配置され、サーバー上の別のスプリットと同じ場所に配置される場合も、されない場合もあります。スプリットには、分散コンセンサスを維持し、トランザクションのクォーラムを確保するために、複数のレプリカがあります。
Spanner のコプロセッサ フレームワーク
Spanner はコプロセッサ フレームワークを使用します。このコンポーネントにより、Spanner はリモート プロシージャ コールを特定のサーバーではなくデータのロケーションに送信し、データモデルとデータ配置の間の抽象化を行います。
たとえば、コールの宛先には、サーバーの IP アドレスではなく Singers(2) と指定します。その後、コプロセッサ フレームワークは、このデータを所有するスプリットを解決し、クライアントからネットワーク レイテンシにおいて最も近いレプリカにリクエストをルーティングします。このように、データが移動しても、クライアント アプリケーションはそれを認識する必要がなく、コプロセッサ フレームワークを通じてリクエストをルーティングできます。
PrepareQuery
クライアントが Java で executeQuery()(または Go で ReadOnlyTransaction.Query)を呼び出すと、最初に実行されるコプロセッサ コールが PrepareQuery です。クエリ オプティマイザー ロジックはクライアントでホストされないため、このコールはクエリの解析と分析を行うランダムなサーバーにルーティングされ、ロケーションのヒントをクライアントに返します。ロケーションのヒントは、クエリの送信先である最上位テーブルのキーを指定します。たとえば、クエリが「SELECT SingerId, AlbumId, AlbumTitle from Albums WHERE SingerId=2」の場合、ロケーションのヒントは「Singers(2)」となります。
ロケーションのヒントの計算
ロケーションのヒントは、コンパイルされたクエリ表現を分析し、最上位テーブルのキー列の述語を見つけることによって計算されます。ロケーションのヒントには、パラメータ化されたクエリ用にキャッシュに保存できるよう、パラメータが含まれる場合があります。
たとえば、「SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)」というクエリの場合、ロケーションのヒントの抽出ロジックにより、クエリが最上位テーブル Singers の下位のテーブルに対応することが判別されるため、WHERE 句から SingerID 列の最初の述語を抽出することが試行されます。SingerId = 1 が検出されると、ロケーションのヒントとして Singers(1) が生成されます。クエリに SingerId = @id が含まれている場合、ロケーションのヒントは Singers(@id) になります。このパラメータ化された形式は、@id クエリ パラメータの実際の値を求めるために解決され、データのロケーションが取得されます(id=1 なので Singers(1) となります)。
ロケーションのヒントは、キーとして SQL テキストのハッシュを使用してキャッシュに保存されます。つまり、アプリケーションが複数の異なるエンドユーザーに対して同じクエリを実行する場合は、パラメータ化されたクエリを作成してキャッシュ ヒット率を上げるほうが良いということになります。このキャッシュがヒットすると、PrepareQuery のコールが完全に回避されるため、全体的なパフォーマンスが向上し、クエリのレイテンシが短縮されます。これは、処理時間がラウンド トリップ時間よりも短い「シンプル」なクエリで非常に大きな効果をもたらす場合があります。PrepareQuery のコールをスキップすることで、レイテンシを約半分に短縮できるためです。
ExecuteQuery
ロケーションのヒントが使用可能になると、次のコプロセッサ コールは ExecuteQuery です。このコールはロケーションのヒントに基づいてルーティングされ、受信サーバーがクエリのルートサーバーになります。次に、このサーバーはクエリをコンパイルし、実行プランを作成して、必要なオペレーションの実行を開始します。コンパイルされたクエリプランと実行プランはキャッシュに保存されます(この場合も、繰り返し実行するクエリでこのステップを省略するために、クエリのパラメータ化が重要です)。
実行プランには、1 つ以上のスプリットでデータアクセスを処理するための分散ユニオン演算子が含まれます。具体的には、実行ツリーの最上位に分散ユニオン演算子があります。追加の分散ユニオン演算子も、クエリの他のスキャン(2 つの最上位テーブルの結合時など)で挿入されることがあります。
分散ユニオンは範囲抽出(以下を参照)を実行し、サブクエリを他のスプリットにディスパッチして、これらのサブクエリを実行するリモート サーバーから呼び出し元に結果をストリーミングします。
分散ユニオンの範囲抽出
Spanner は述語をコンパイルし、フィルタツリーを構築して、キーの述語の評価と範囲計算を効率化します。たとえば、上述の例のクエリ「SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)」の場合、フィルタツリーは次のようになります(赤字のテキストについては、下でご説明します)。
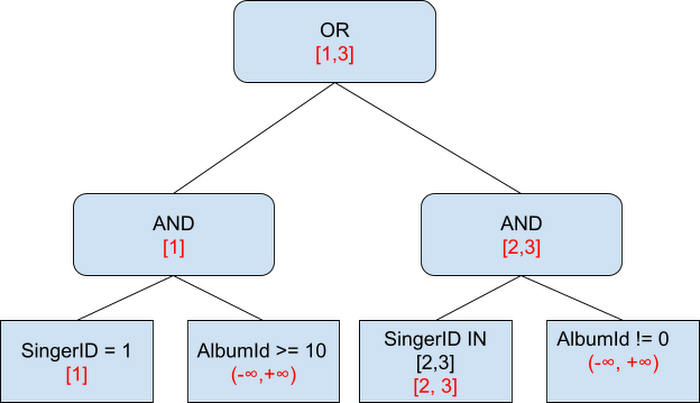
分散範囲の計算では、最上位テーブルのキー(SingerID)の抽出を試行します。フィルタツリーでは、赤字で示している範囲が考慮されます。たとえば、ノード「SingerId = 1」は [1] の範囲を生成します。ノード「AlbumID>=10」はこのキーに関連しないため、範囲は (-∞, ∞) です。上の AND ノードはこの 2 つの範囲を交差し、範囲は最終的に [1] になります。このようにして上へ進み、全体的な SingerId の範囲は最終的に [1,3] になります。
クエリから分散キーを抽出できない場合(キーの述語がない「SELECT * FROM T」など)、クエリはテーブルの一部を含むすべてのスプリットにディスパッチされます。
ExecuteInternalQuery の送信
分散範囲 [1,3] は可算である(少数の個別のキーを含む)ため、分散ユニオンは SingerID の各値を反復処理し、サブクエリをそのロケーションにディスパッチすることができます。いくつかの最上位の行が同じスプリットに存在する場合、単一の ExecuteInternalQuery リモート プロシージャ コールがそのスプリットに送信されます。
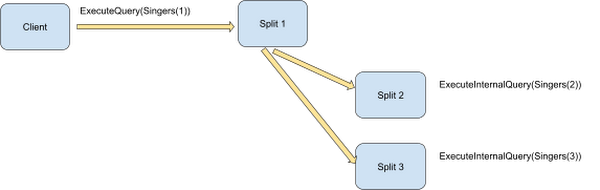
内部クエリでも、データのロケーションの特定にコプロセッサ フレームワークが使用される点に注目してください。これにより、データの一部を柔軟に移動して、各サーバーへの負荷の均等な分散を実現できます。また、コプロセッサ フレームワークは、不安の種となるクエリ処理コンポーネントがなくても、更新されたロケーションに新しいリクエストをルーティングできます。
分散ユニオン演算子は、リモートのスプリットから結果を取得し、それをまとめて、結合した結果を呼び出し元に返すという役割を担っています。スプリットの数が多い場合は、USE_ADDITIONAL_PARALLELISM クエリヒントを指定することで、リソース消費量の増加と引き換えに、クエリ実行の実時間を短縮できます。
まとめ
Spanner に対してクエリを実行するには、動的に管理されるデータの配置と移動を考慮する必要があります。Spanner のコプロセッサ フレームワークにより、Spanner のその他のコンポーネントはデータの物理的なロケーションの詳細を取得する必要がなくなり、リクエストは論理データの記述に応じてルーティングされます。
PrepareQuery のコールにおける分散キーの抽出により、Spanner は、クエリを処理する必要がある最初のサーバーで実行を開始できます。また、必要に応じて、追加のサブクエリを、残りのデータ スプリットを含む他のサーバーに送信します。このメカニズムにより、分散したスプリットから必要なデータを収集するためのクエリを任意の複雑さで使用でき、シンプルな executeQuery API がエンドユーザーに提供されます。
この投稿では、複雑なクエリ実行のほんの一部を説明しているにすぎません。Spanner チームが提供している前述のドキュメントでは、再開のメカニズム、ストレージの改善、トランザクション、その他多くのことについて説明しています。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabs でお試しください。
-Google Cloud ソフトウェア エンジニア Leon Dubinsky



