Anomalo による包括的なデータ品質モニタリングが次世代の分析に必要な理由

Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
データドリブンであることが組織にとって不可欠だという話をよく耳にします。しかし、これでは少し言葉足らずです。つまり、「高品質なデータ」に基づいて判断する必要があります。そうでなければ、まったく間違った方向に進んでしまう可能性があります。
Google BigQuery は、パワフルな次世代の分析と ML のアプリケーションを実現します。高品質なデータで BigQuery を使用するには、データ自体の予期せぬ変化を警告し、その変化の背後にある理由を特定する、包括的なデータ品質モニタリング ソリューションが必要です。
この記事では、BigQuery と Anomalo による包括的なデータ品質モニタリング戦略をセットアップすることで、次世代の分析戦略に対する信頼を醸成する方法について説明します。
データの問題が分析の品質にどのように影響するか
BigQuery のようなフルマネージド データ ウェアハウスを使用すると、さまざまな分析のユースケースをサポートする最新のデータスタックを迅速にスピンアップできます。しかし、かつてないほど多くのデータソースとデータ量を簡単に利用できるようになったのと同様に、データの問題が発生する可能性も高くなっています。データ値の予期せぬ変化は、検出と理解が特に困難な深い問題です。これは、評価すべき変化の要因となり得るものが多数存在することが多いためです。購入額の急増は、データ パイプラインのなんらかのエラーが原因なのでしょうか、それとも季節的なトレンドが原因なのでしょうか。ML モデルのパフォーマンスが悪いのは、入力データが突然変化したためでしょうか、それともモデル設計に欠陥があったためでしょうか。
データ品質に自信がないと、チームは次のような問題に直面します。
ある経営幹部がダッシュボードに通常とは異なる数値が表示されていることに気付き、データ品質にバグがあるのではないかと疑った結果、根本原因を突き止めようとして分析 / データ エンジニアリング チームが出動することになる。
ある ML モデルで、本番環境データの分布とトレーニング データの分布にずれが発生し、チームの誰もこの変化に気付いていないために、パフォーマンスが異常を示し始め、お客様に影響が及ぶ。
2022 年の前半に Equifax が数百万件のクレジット スコアの誤りを報告したとき、どのような問題が発生する可能性があるかを示す顕著な例がありました。問題を検出するために必要な自動化されたデータ品質がなかったため、金融機関はこのデータを本番環境で使用し、結局、適格な個人への融資を拒否することになりました。
包括的なデータ品質により、複雑な問題を大規模に検出できる
企業は、BI のダッシュボードとレポートやダウンストリームの ML モデルに影響が及ぶ前に、複雑なデータの問題を検出して解決できる、データ品質ツールを必要としています。こうしたツールは次のような質問に答えることができます。
最近の状況と、データがどのようであるべきかという対象分野の専門家の想定に基づいた場合に、このデータは正しいか。一貫性があるか。
指標に重大な変化はあるか。
データに予期せぬ変化があったのはなぜか。そうした問題の原因は何か。
ML の入力にずれが発生しているか。その理由は何か。
基礎的なデータ オブザーバビリティには、データ パイプラインが正常に完了したか、取り込まれたデータ量が期待どおりであったか、といった基本的なテストがいくつか含まれます。こうしたテストは、データそのものよりも、プロセスに重点を置いています。一方、包括的なデータ品質モニタリングでは、基本的なオブザーバビリティ チェックだけでなく、データの実際の内容に着目します。データドリフトのトラッキングや指標の変化のモニタリングなど、データ品質で最も困難な部分を支援します。
データ ジャーニーの初期段階であれば、データのオブザーバビリティで十分かもしれません。しかし Google のお客様のように、データを意思決定や ML モデルへの入力に使用している場合、データが正確かつ信頼できるものであることを確認するには、基本的なチェックでは不十分です。
Dataplex は、分散データの大規模な管理、モニタリング、統制を可能にするインテリジェントなデータ ファブリックです。Dataplex にはデータ品質を検証する方法が 2 つあります。自動データ品質(公開プレビュー版)と Dataplex データ品質タスクです。Dataplex AutoDQ とデータ品質により、データ品質のルール作成と大規模なデプロイを自動化する、次世代のデータ品質ソリューションが実現しました。また、Anomalo のような多才なパートナーとも連携し、お客様に提供するソリューションの完全性を高めています。
BigQuery と Anomalo で基本的なデータ オブザーバビリティを超える
Google Cloud Ready - BigQuery パートナーである Anomalo は、お客様のデータスタックに直接関わる包括的なデータ品質モニタリング プラットフォームです。Anomalo の深いデータ品質により、データの鮮度などのチェックにとどまらず、主要な指標の変化やテーブルの異常を自動的に検出できます。Anomalo が GCP にデプロイされ、BigQuery や他のサービスと統合されて、お客様のデータ品質の問題を特定する様子を以下に示します。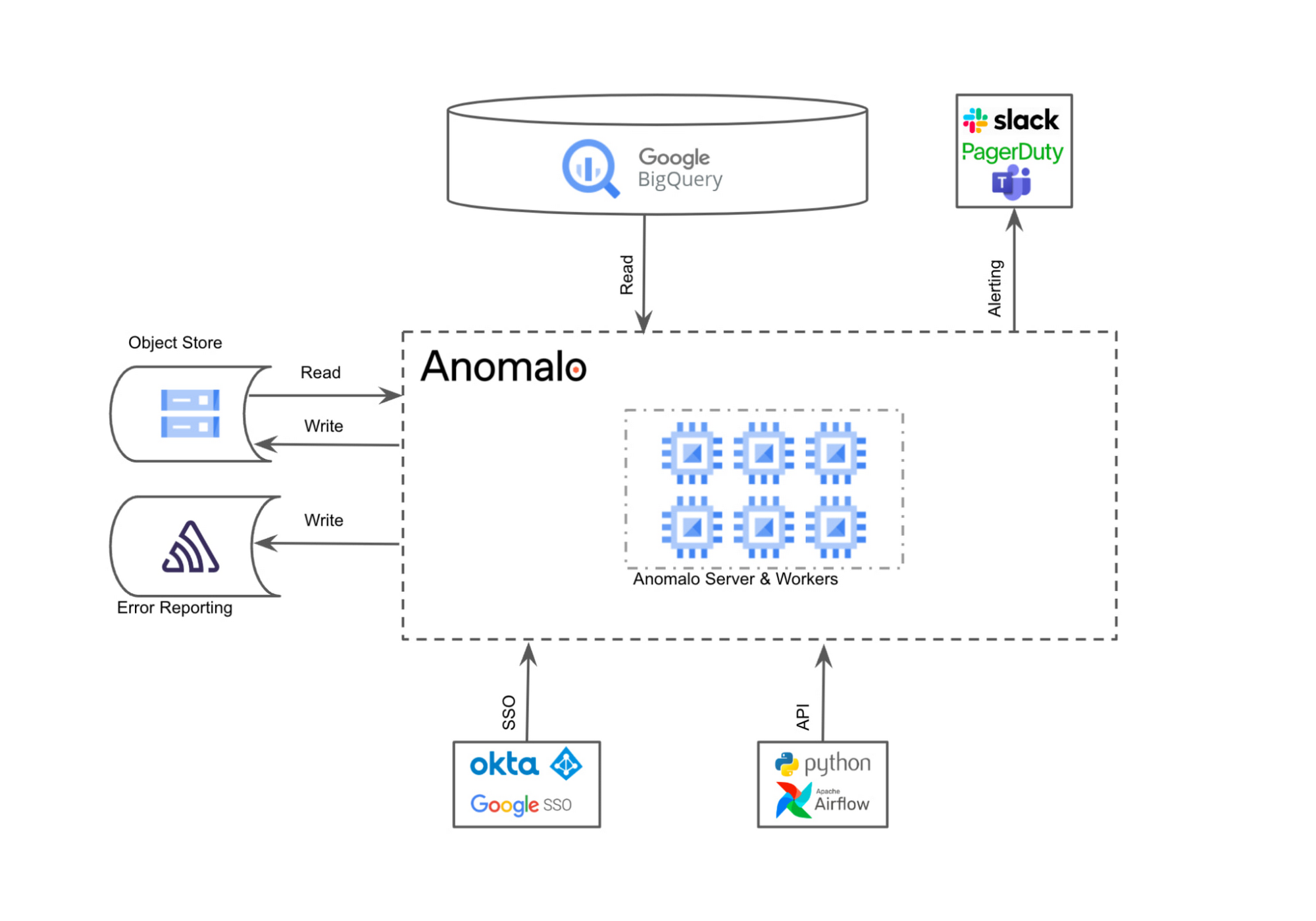
継続的なモニタリングにより、データが時間の経過とともに変化しても常に正確であるという安心感が得られます。このプラットフォームのコード不要な UI により、どなたでも簡単にデータ管理担当者または利用者になることができます。
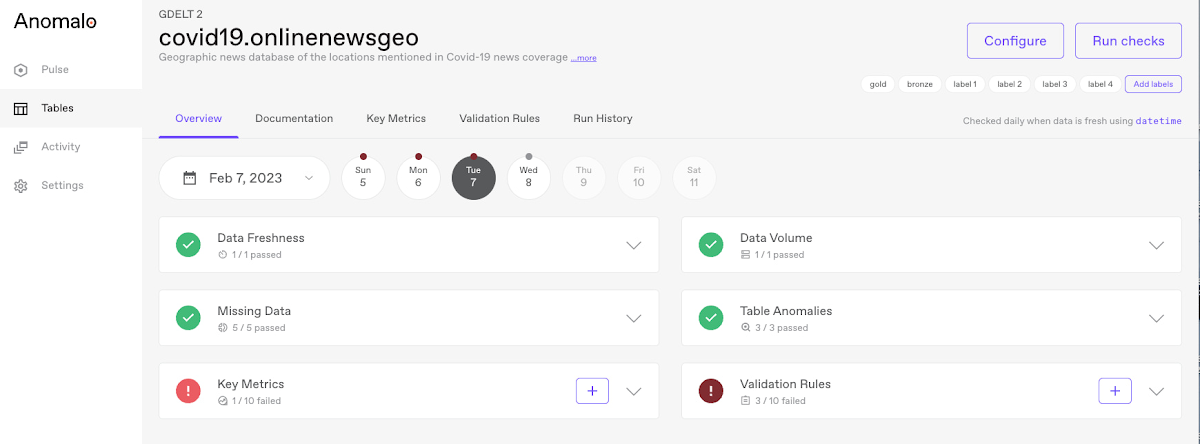
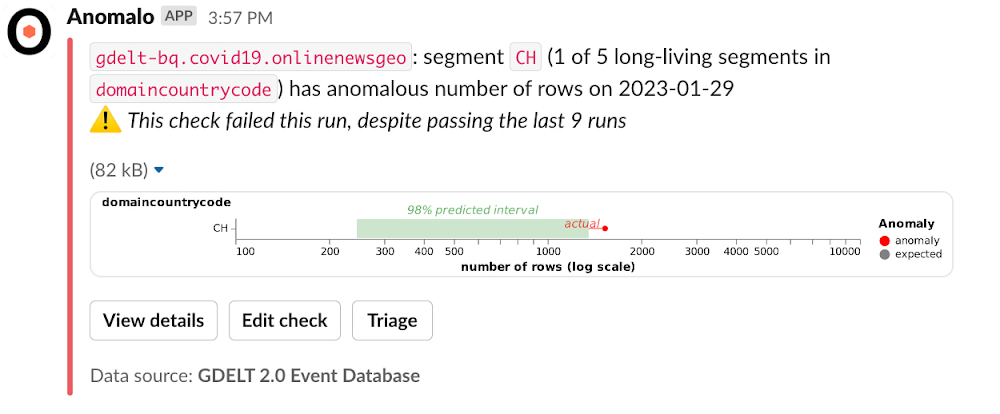
Anomalo は、Slack や Gmail と連携するリッチなビジュアル アラートを提供します。データが予想範囲から外れたことを Anomalo が知らせる方法の例を以下に示します。観測者は、そのデータが通常と比較してどれだけ異常であるのかを素早く把握し、さらに掘り下げて、ずれの原因となったデータ要素の完全な内訳を確認できます。
Slack でのアラート:
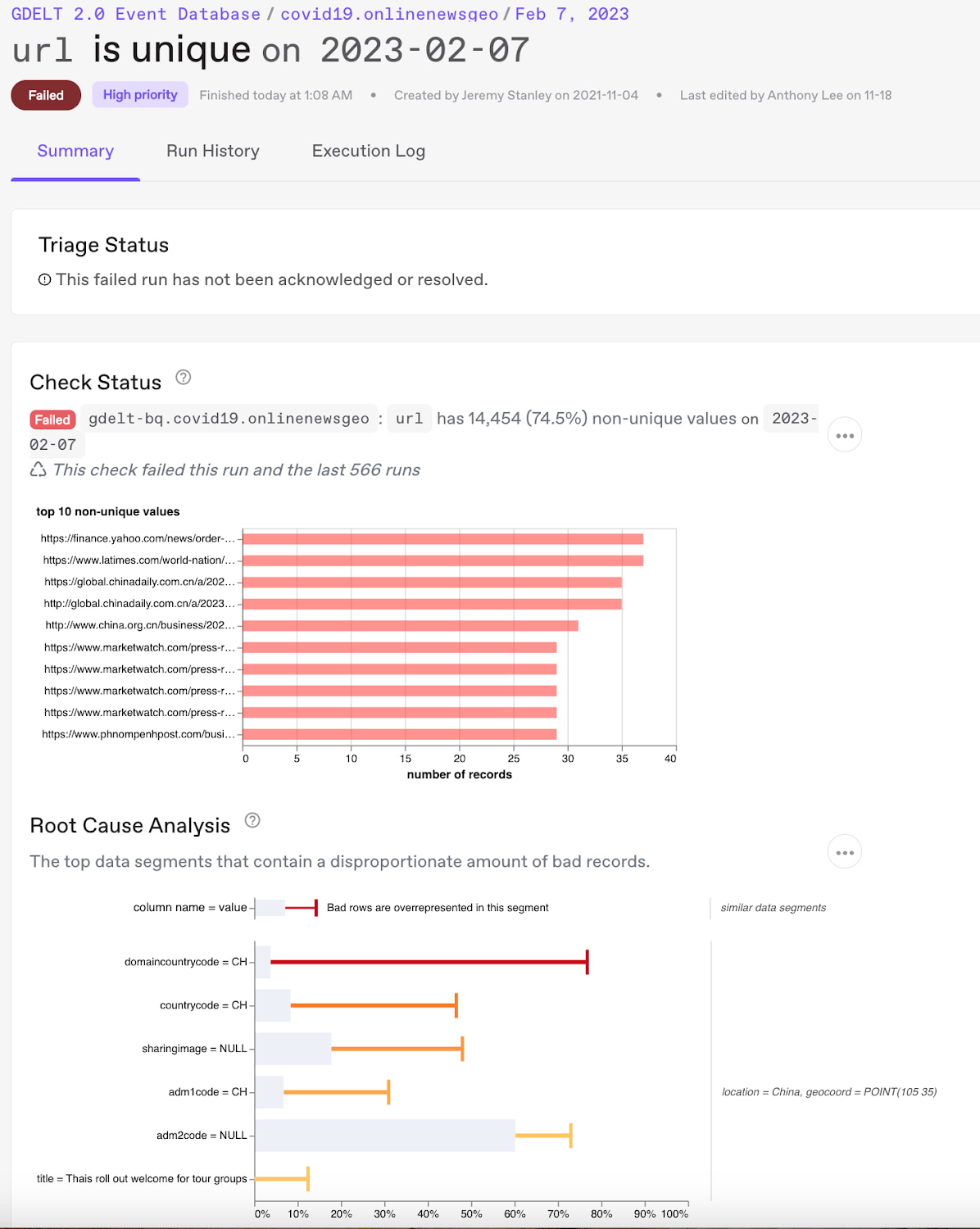
Anomalo の詳細な根本原因分析:
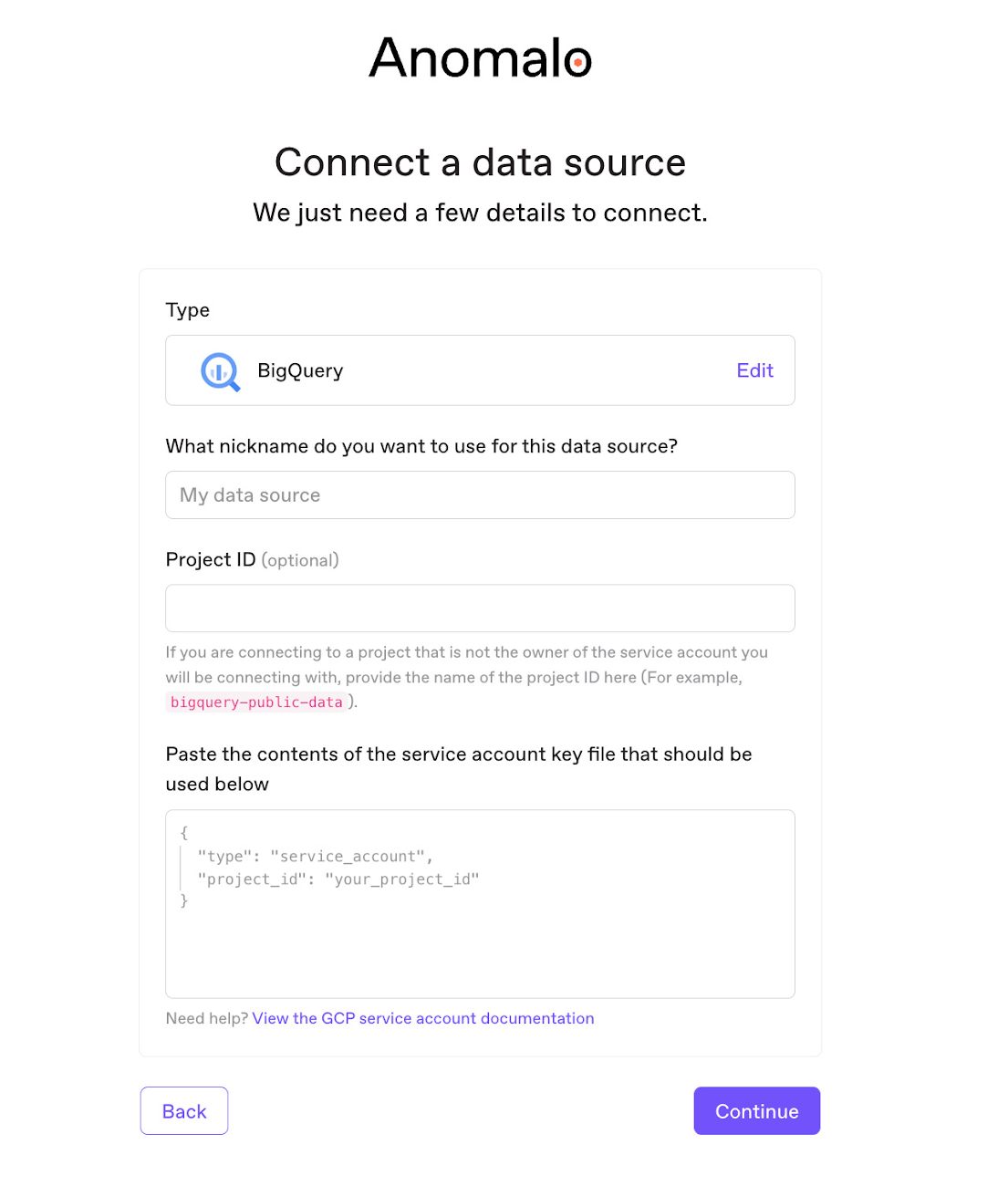
Anomalo は、BigQuery とのワンクリック統合をサポートしています。アカウントに関する詳細情報を入力するだけで、Anomalo は自動的に、選択したすべてのテーブルについて、データ オブザーバビリティと自動化されたデータ品質の両方を提供し始めます。
まとめ
BigQuery は、分析のニーズに対してかつてないスケーラビリティとスピードを提供します。こうした機能を使用してデータをさらに活用するには、データそのものが高品質であるという確信を持つことが重要です。自動化されたデータ品質なしにデータ分析情報を利用すると、ビジネス、プロダクト、ユーザーを、不要なリスクにさらすことになります。品質が確保されていれば、リスクを最小限に抑えられるだけでなく、データを信頼できることが誰でもわかるため、組織全体での分析の導入が促進されます。
Anomalo を使用することで、BigQuery ユーザーはデータの問題をモニタリングし、速やかに解決できます。BigQuery と Anmalo のパートナーシップについて詳しくは、こちらをご覧ください。Anomalo について詳しくは、こちらをご覧ください。
- Anomalo ビジネス開発担当 VP Amy Reams 氏
- クラウド パートナー エンジニアリング、スタッフ ソリューション コンサルタント Jobin George



