ビジネスに合わせて Composer 環境をスケールする
Google Cloud Japan Team
※この投稿は米国時間 2020 年 2 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
データ パイプラインを構築する際には、現在と将来のビジネスニーズを考慮することが重要です。お客様から Cloud Composer 環境を構成して最適化したいという声をよく聞きます。そこで、この投稿では、Cloud Composer エンジニアリング チームの一員として、Apache Airflow を基に構築された Cloud Composer の仕組みについて説明し、Cloud Composer のパフォーマンスを最適化するためのヒントをご紹介します。
Cloud Composer は、フルマネージドのワークフロー オーケストレーション サービスです。クラウドとオンプレミス データセンターにまたがるパイプラインの作成、スケジューリング、モニタリングを実現します。これは Apache Airflow オープンソース ソフトウェアを基に構築され、Python プログラミング言語を使用して運用されます。
まず、Airflow 構成がパフォーマンスにどのように影響するかを分析し、次にパフォーマンスを高めるために初期設定をすばやくブートストラップする方法についてのヒントをご紹介します。また、こちらのサイジング ガイドが役立つと思われた場合は、コピーを作成してご自分の数値を書き加えてご利用ください。
CeleryExecutor を使用する Apache Airflow スケジューラ アーキテクチャについて
まず、Cloud Composer の Airflow スケジューラやワーカーのアーキテクチャについて詳しく説明します。ここでは、すでに Cloud Composer のアーキテクチャおよび Apache Airflow のコンセプトについての全体的な知識があることを前提としています。
下の図では、DAG の解析プロセスによって、ファイルから DAG が繰り返しロードされることが確認できます。このプロセスでは DAG をチェックし、DAG 実行の開始やタスクの作成などのスケジューリング操作を呼び出します。タスクはワーカーに送信され、Redis ベースのタスクキューを介して実行されます。
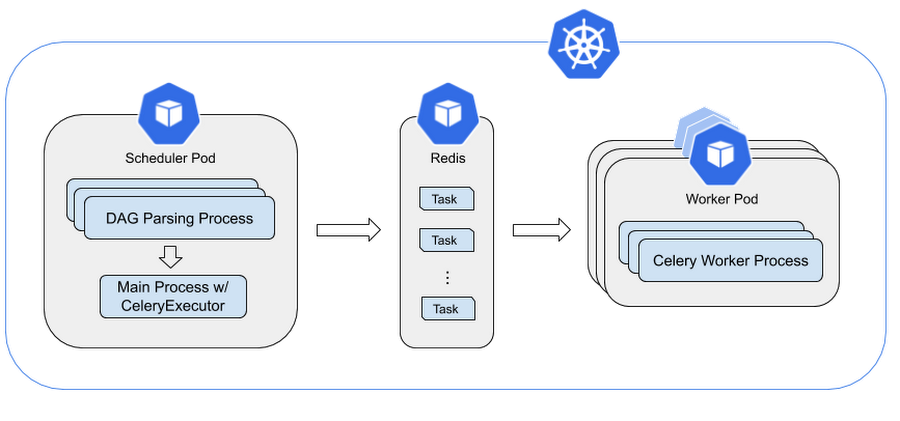
スケジューラは Python の multiprocessing.Process を呼び出して複数のプロセスを開始し、DAG ファイルを並列に解析します。スケジューラが開始できる DAG 処理プロセスの総数は、Airflow 構成(スケジューラ)の max_threads によって制限されます。
DAG 解析プロセスごとに次の手順が実行されます。
●DAG ファイルのサブセットを解析して、DAG 実行とその DAG 実行のタスクを生成します。
●すべての依存関係を満たすタスクを収集します。
●これらのタスクを SCHEDULED 状態に設定します。
スケジューラのメインプロセスでは、次の処理がループで実行されます。
●DAG 解析プロセスからすべての SCHEDULED タスクを収集します。
●有効なタスクを QUEUED 状態に設定します。
●特定数の QUEUED タスクを Celery キューに送信します。この数は、同時実行されるタスクの最大数を表す parallelism 構成パラメータから算出されます。
●残りのタスクは QUEUED 状態のままになります。
Cloud Composer でのタスクのライフ
すべての Airflow タスクは、以下に図示するプロセスと制約を経由した後にワーカーによって実行されます。順番として、Airflow タスクはまずこれらの Airflow 構成の制約を満たしてから、最終的にワーカーによって実行されます。
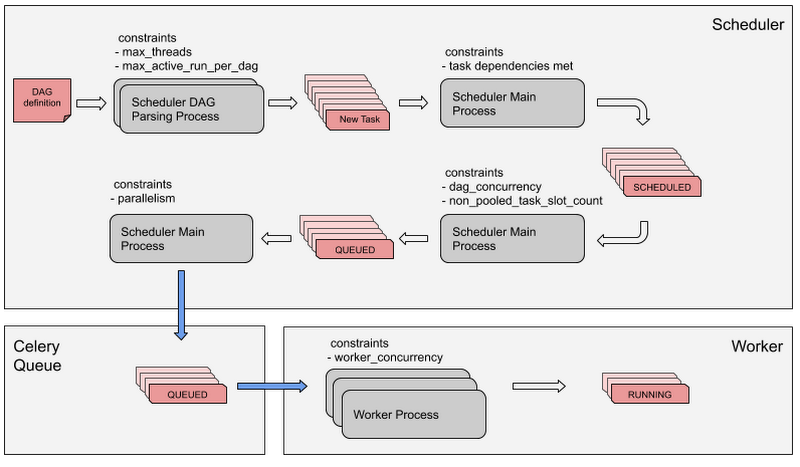
スケジューラの DAG 解析プロセスでは、DAG 定義を解析し、DAG の各タスクのタスク インスタンスを作成します。
タスクの依存関係がすべて満たされると、タスクは SCHEDULED 状態に設定されます。
タスクが SCHEDULED 状態になると、スケジューラのメインプロセスにより、処理するタスクが選択されます。
スケジューラのメインプロセス pProcess で SCHEDULED 状態のタスクが選択されます。このとき、DAG ごとの最大タスク数の制約「dag_concurrency」とシステム内の最大タスク数の制約「non_pooled_task_slot_count」が、キューイングの他の基準とともに考慮されます。実際にキューに入れられたタスクは QUEUED 状態に設定されます。
次のステップとして、スケジューラのメインプロセスでタスクが Celery キューに入れられます。これは Celery キューに入るタスクの数を制限する「parallelism」制約に基づいて行われます。キューに入れられたタスクは QUEUED 状態になります。
最後に、ワーカー プロセスで Celery キューからタスクを取得します。これはワーカー内のタスクの数が制約「worker_concurrency」に達するまで行われます。ワーカーで実際に実行されているタスクは RUNNING 状態に設定されます。
最適なパフォーマンスを得るための Airflow 構成変数の推奨値
以下のクイック リファレンス テーブルに、パフォーマンスに影響する可能性のあるさまざまな Airflow 構成の推奨値を示します。次のセクションで、それぞれの背後にある理論的根拠について説明します。
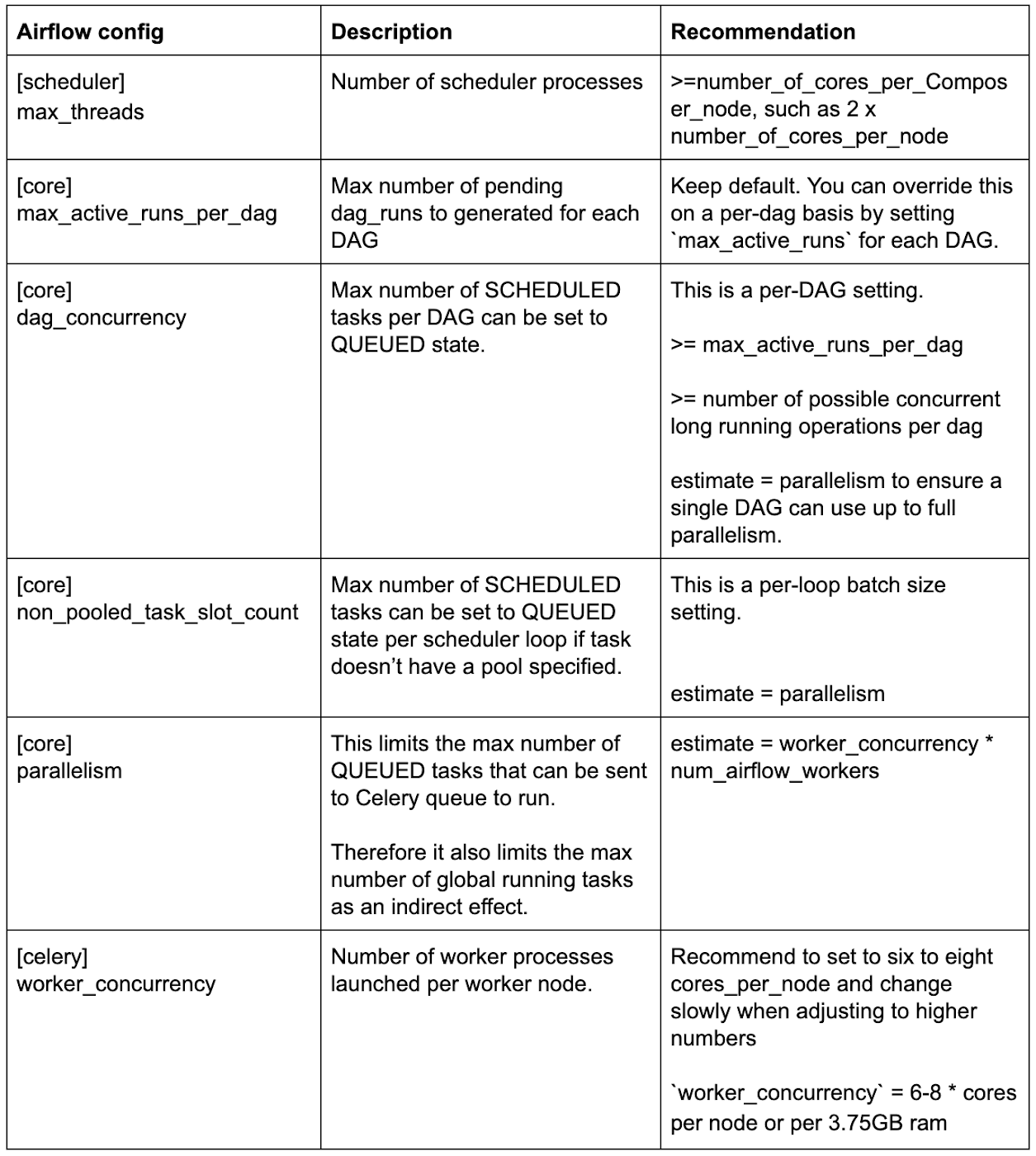
適切な Airflow スケジューラ設定を選択する
Cloud Composer 環境をスケールする必要がある場合は、適切な Airflow 構成と、ノードおよびマシンタイプの設定を選択する必要があります。
スケジューラの Airflow 構成 max_threads のデフォルトはたったの 2 です。つまり、Airflow スケジューラ ポッドが 32 コアのノードで実行されている場合でも、開始できる DAG 解析プロセスは 2 つのみになります。そのため、max_threads をマシン 1 台あたりの vCPU 数以上に設定することをおすすめします。
タスクが長時間 SCHEDULED 状態のままである場合、タスクが dag_concurrency または non_pooled_task_slot_count により制約されている可能性があります。その場合は、この 2 つのオプションの値を大きくすることを検討してください。
タスクが QUEUED 状態のまま進行しない場合は、parallelism により制約されている可能性があります。ただし、タスクはワーカーが選択するまで RUNNING 状態に設定されないため、ワーカーの処理能力によって制限される場合もあります。parallelism の値を大きくするか、ワーカーノードを追加することを検討してください。
Airflow ワーカーのパフォーマンスをテストする
Cloud Composer は環境内にある各ノードのワーカーポッドを起動します。各ワーカーポッドで複数のワーカー プロセスを起動でき、Celery キューからタスクを取得して実行します。ワーカーポッドが起動できるプロセスの数は、Airflow 構成 worker_concurrency によって制限されます。
ワーカーのパフォーマンスをテストするために、no-op PythonOperator に基づいてテストを実行したところ、6 つまたは 7 つの並列ワーカー プロセスで 3.75GB RAM を搭載した 1 つの vCPU(デフォルトの n1-standard-1 マシンタイプ)がすでに最大限に使用されていることがわかりました。ワーカー プロセスを追加すると、コンテキストの切り替えで大きなオーバーヘッドが発生し、結果としてワーカーポッドのメモリ不足の問題が生じて、最終的にタスクの実行が中断される可能性があります。
`worker_concurrency` = 6-8 * cores_per_node または per_3.75GB_ram
Cloud Composer は、環境のデフォルトの同時実行数として 6 を使用します。単一ノードでより多くのコアを使用する環境では、上記の式を使用して、使用環境に適した worker_concurrency 数をすばやく取得できます。同時実行数を大きくする場合は、新しい値を有効にした後にワーカーポッドの安定性を厳密に監視することをおすすめします。メモリ不足エラーによってワーカーポッドのエビクションが発生する場合は、同時実行数が大きすぎる可能性があります。実際の上限は、ワーカー プロセスのメモリ消費量に応じて異なる場合があります。
もう 1 つ考慮する必要があるのが、CPU を集中的に使用しないが長時間実行されるオペレーションです。たとえば、リモート サーバーからのステータスのポーリングなどが挙げられ、これは Airflow プロセス全体を実行するためにメモリを消費します。worker_concurrency 数は少しずつ上げて、調整後に注意深く監視することをおすすめします。
ノード数を増やすかマシンの性能を高めるか
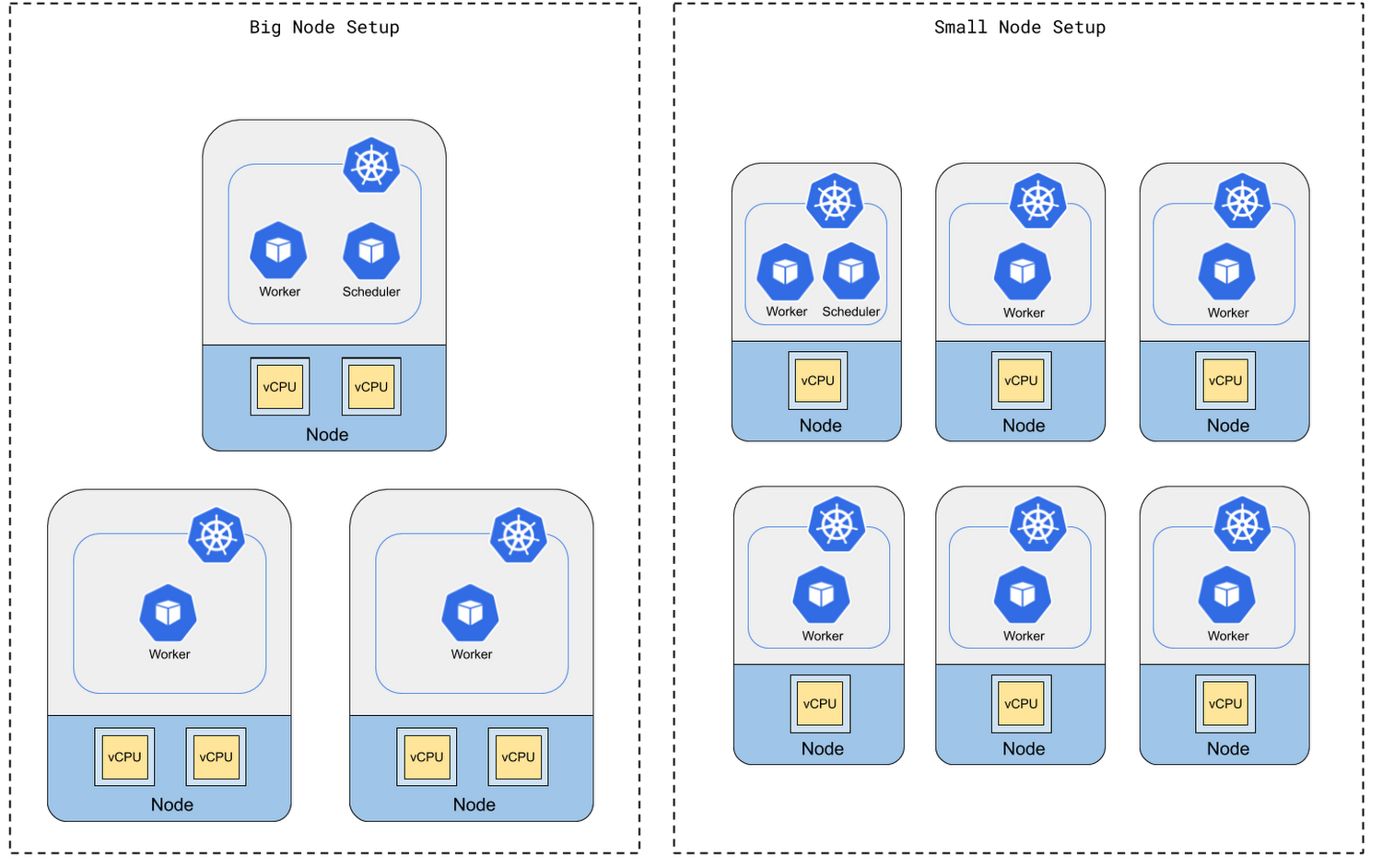
社内テストにより、ワーカーの処理能力が最も影響を受けるのは、マシンタイプではなく vCPU コアの総数であることがわかりました。CPU コアの総数が同じであれば、少数のマルチコア マシンでも多数のシングルコア マシンでもワーカーの処理能力に大きな違いはありません。
ただし、ノード数が多くてもマシンの性能が低い小規模なノードセットアップでは、スケジューラは小規模なマシンで実行されるため、ワーカーが実行するタスクを生成するのに十分な計算能力がない場合があります。
そのため、Cloud Composer クラスタは比較的少数の強力なマシンでセットアップすることをおすすめします。ただし、マシンの数が少なすぎると、1 台のマシンの障害がクラスタに重大な影響を与えることにも留意してください。
社内テストにより、長時間実行されるタスクがなければ、worker_cores と scheduler_cores の比率が約 9:1 までで、コア数が同じシステム性能でのパフォーマンスの違いはないことがわかりました。長時間実行されるタスクがある場合のみ、これを超える比率にすることをおすすめします。以下の式を使用して、worker_cores と scheduler_cores の適切な比率をすばやく計算できます。
たとえば、最初に 1 台のマシンに 3 個のノードと 2 個のコアを搭載した環境を設定し、24 個の長時間実行タスクを同時に実行すると見積もった場合、最大 9 + 24 / (2 * 6) = 11 ノードまでの環境のスケールを試すことができます。パフォーマンスを上げる必要がある場合は、代わりにより強力なマシンタイプを試してみる価値があります。
サイジング ガイドをご利用いただき、Cloud Composer を最大限にご活用ください。
- By Haotian Wu、Zhou Fang
