NCAA ロスを乗り越える: BigQuery を使ったマーチ マッドネスのシミュレーション

Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
世界中で COVID-19(新型コロナウイルス感染症)の甚大な影響が続くなか、Google はお客様のサポートや一般公開データの提供を通じた研究支援をはじめ、さまざまな対応策に力を入れています。目前に迫っている重大な問題もそうですが、世界中でほぼすべてのスポーツ団体が活動を停止するという、スポーツファンにとってはこれまで経験したことのない日々が続いています。生活に必要不可欠なものでないとしても、スポーツは人々に勇気や感動を与える一種のエンターテイメントです。
具体例をあげると、数百万人を熱狂させる年に 1 度の恒例行事、マーチ マッドネス(March Madness®)は、今年のアメリカのスポーツ カレンダーから消えてしまいました。マーチ マッドネスとは、大盛り上がりを見せる大学バスケットボールのプレーオフのことで、NCAA®(全米大学体育協会)が主催する年に 1 度のこのトーナメントでは、男女両チームが王者を目指してそれぞれ熾烈な戦いを繰り広げます。スポーツファンはこの一発勝負のエキサイティングな試合を観戦するだけでなく、ブラケット(トーナメント表)にチーム名を記入して、トーナメントの各ステージでどのチームが勝ち上がって行くかを予測します。
NCAA とパートナー提携してから 3 年目となる今年、Google は男子と女子のバスケットボールに関連する大量のデータを分析する計画を立てていましたが、残念ながら 3 月 12 日に、残りのカンファレンス トーナメントと NCAA の両トーナメントの中止が発表されました。トーナメントのセレクションも、ブラケットも、番狂わせも、輝かしい瞬間もない世界に慣れるまでには数日かかりましたが、Google ではこのような状況でも精一杯楽しめるように、Google Cloud の各種ツールとデータ サイエンスのスキルを使ってマーチ マッドネスのシミュレーションを行いました。
シミュレーションは、多数の予測問題に対応したデータ サイエンス ツールキットに含まれる重要なツールです。モンテカルロ法(予測分布からランダム サンプリングを繰り返し行う手法)を使用すれば、科学、工学、金融だけでなくスポーツにおいても実世界のシナリオをモデル化できます。この投稿では、NCAA バスケットボール ブラケットの何万通りものシミュレーションを、BigQuery を使って設定、実行、分析する方法を説明します。コードサンプルと説明を読んだ読者の方が、自分でも同様のテクニックを使って分析を行ってみようと思っていただけることを願っています(あるいは説明を飛ばし、今すぐデータポータルにアクセスして何千通りものシミュレーション済みブラケットをお試しください)。
仮想トーナメントを予測する
NCAA トーナメントを予想するうえで、まず必要になるのがブラケットです。そのためには、出場チームを選び、トーナメント構造を作成し、トーナメントの各ラウンドでの組み合わせを決める必要があります。NCAA バスケットボール委員会は 2020 年のブラケットを発表しませんでした。しかし、試合が中止になったのはセレクションのわずか 2 日前であったため、有名なブラケットロジスト(トーナメントの出場チームや組み合わせ、勝ち上がりを予想する人)が作成した最終「予想」ブラケットは代用として使用するに十分であると判断しました。具体的には、男子には ESPN の Joe Lunardi 氏と CBS の Jerry Palm 氏の予想ブラケットを、女子には ESPN の Charlie Creme 氏と NCAA の Michelle Smith 氏の予想ブラケットを使用しました。これらの予想ブラケットではセレクション、シード順位、ブラケット作成に関連する多様な要素が考慮されていて、委員会もきっとこのようなブラケットを発表していただろうと思えるようなものになっています。
次の手順として、トーナメント表の特定の組み合わせでの勝利確率(チーム X とチーム Y が対戦した場合にチーム X が勝つ確率)を判定する方法を探しました。勝利確率を推定するために、過去の NCAA トーナメントの試合をトレーニング データとして使用し、組み合わせごとに次の 3 つの要素を考慮に入れるロジスティック回帰モデルを作成しました。
チームのシード順位の差: 通常、第 1 シードは第 2 シードより上で、第 2 シードは第 3 シードより上というように、第 16 シードまで決まります。
トーナメント前に対戦した相手の強さを考慮して調整したチームの能力値の差: これについては、代表的な KenPom や Sagarin のランキングに類似した、チーム パフォーマンスに基づく強さのランキングと考え、女子チームにも適用しました(詳しい計算方法はこちらの記事をご覧ください)。
ホームコート アドバンテージ: これが該当するのは、トップシードのホーム スタジアムで行われることが多い女子の最初の方のラウンドです。男子の試合はほぼすべてが「中立的」な会場で行われます。
BigQuery を使用すると、過去の試合の結果を反映した各予測変数を使ってデータを準備できます。Google ではデータを準備した後、BigQuery ML を使ってロジスティック回帰モデルを作成しました。使うコードは最小限で、データをウェアハウス外に移動する必要はありません。前述した要素を使用して、男女それぞれのトーナメント試合に対応したモデルを別々に作成しました。以下が女子トーナメント試合のモデルのコードです。
いずれのモデルでも、信頼できる精度とログ損失の指標が使用され、各要素に妥当な重み付けが行われています。モデルができたら、予想した 2020 年のブラケットで起こりえるすべてのチーム対戦にこのモデルを適用します。チーム対戦の生成は、BigQuery を使って、各チームのシード順位、調整後の能力値、ホームコート アドバンテージに沿って行います。次は BigQuery ML を使い、保存したモデルから予測を生成します。次に示すように、今回もコードは最小限で、処理はデータ ウェアハウス内で完結します。
生成されたテーブルには、起こりえるすべての組み合わせでの勝利確率が含まれていますが、重要なのはここからです。このブラケット構造を使い、各ラウンドについて、各チームが勝ち上がる確率を計算します。1 回戦は組み合わせがすでに決まっていて、たとえば Charlie Creme 氏のブラケットの場合は、第 1 シードのサウス カロライナと第 16 シードのジャクソン ステートが対戦します。そこで、1 回戦については、単純に当該組み合わせの勝利確率予想をテーブルで検索します。しかし 2 回戦以降は考慮事項が増えます。そもそもそのチームがそのラウンドに進出する確率を考慮する必要があるうえ、進出した場合には、対戦する可能性のあるチームが複数になります。たとえば、第 1 シードのチームはラウンド 32(2 回戦)で第 8 シードまたは第 9 シードのチームと対戦する可能性があり、スウィート 16(3 回戦)では第 4、5、12、13 シードのチームと対戦する可能性がある、という具合です。
そのため、あるチームが当該ラウンドを勝ち抜く可能性は、「そもそもそのラウンドに進出する可能性」に「勝利確率の加重平均」をかけたものになります。勝利確率の加重平均は、「対戦する可能性のある各相手チームを破る確率」を「それぞれのチームと対戦する確率」で重み付けした値です。例として、第 8 シードのチームがスウィート 16 に進出する場合を考えてみましょう。
ラウンド 64(1 回戦)で第 9 シードに勝つ確率は通常、ほぼ五分五分です。
第 1 シードと対戦した場合はほとんど勝ち目がありません。
第 16 シードと対戦した場合は勝つ可能性が十分にあります。
しかし、ラウンド 32 では第 1 シードと対戦する可能性のほうがはるかに高いため、勝ち上がりの計算では、下位の対戦での勝利確率にはるかに高い重み付けがなされます。
総合すると、第 8 シードがスウィート 16 に進出する確率予想は 20% を大きく下回ります。トップシードを相手に、厳しい戦いになる(可能性が非常に高い)試合を制さなければ、そこにたどり着けないためです。
この種の計算をブラケット全体に対して実行するとなると、当然、繰り返し処理を行うことになります。まず、特定のラウンドで起こりえるすべての組み合わせの対戦勝利確率を使用して、次のラウンドに進出する確率をすべてのチームについて計算します。次に、この得られた確率を、各チームと、対戦する可能性のある相手と次のラウンドで対戦する確率の重みとして使用し、そのラウンドで起こりえる組み合わせの対戦勝利確率を使って最初の手順を繰り返します。
これをトーナメントのすべてのラウンドについて行う場合は Python や R といったツールを使用するのが一般的で、その場合は BigQuery からデータを取り出し、いずれかの言語で計算を行い、結果をデータベースに書き戻すことが必要です。しかし今回の問題は、変数と制御ステートメント(ループなど)を使って 1 つのリクエストで複数のステートメントを送信できる BigQuery スクリプトにうってつけのユースケースです。これを使用すると、SQL コードを使って、Python や R などの繰り返しスクリプトに似た機能を実行でき、ウェアハウスを離れる必要もありません。下に示すように、このケースでは WHILE ループを使ってトーナメントのラウンドを順繰りに 1 つずつ処理し、同じスクリプト内で参照される特定のテーブルに、各チームの勝ち上がる確率を出力しています(このケースでは、わかりやすくするために、コードを省略した部分を「[...]」で表しています)。
結果はまとめてこちらの対話型データポータル レポートに出力してあります。このレポートでは、フィルタや並べ替え機能を使って、トーナメントに出場するすべてのチームの勝利確率を(ブラケット予想ごとに)表示できます。Google が行ったシミュレーションの結果を見ると、男子のブラケットではカンザス大学が優勝候補で、優勝する確率は 15~16% 程度です。女子ではオレゴン大学が優勝する可能性が最も高く、確率は 27% または 31% でした(選択したブラケット予想により異なります)。なお、これはカンザス大学とオレゴン大学が優勝していたはずだと言っているのではありません。むしろこの確率予測は、男子トーナメントではカンザス ジェイホークス以外が優勝する確率が 6 分の 5 であること、そしてオレゴン ダックスが女子の優勝チームにならない確率が 3 分の 2 より大きいことを示しています。
シミュレーションは楽しいものですが、こうした結果は特に珍しいものではありません。ESPN、FiveThirtyEight、TeamRankings といった会社は、確率に基づく NCAA トーナメントの試合結果予測を何年も前から提供しています。こうした結果予測は、特定のチームごとの勝利確率を示す指標としてかなり精度が高いのですが、各試合で最も勝ちそうなチームでブラケットを埋めていくと、結局はシード順位が上のチームがほぼ必ず上位に進出するという、非常に白けた結果になります。しかし実際にはそうは行きません。マーチ マッドネスは、ブラケットの 63 試合それぞれで勝者が決まっていく唯一のトーナメントなのです。全体としては、シードやランキングが上位のチームがたいてい勝ち上がって行きますが、番狂わせや無名チームの大躍進、予想外の結果が必ずあるものです。
NCAA トーナメントのシミュレーションを何千回も行う
今回のモデルと予想は、そうした不確定要素を考慮して作成されています。そのことを実証するために、実際のブラケットを何度もシミュレーションして実際に結果を確認できます。手順は、予想を作成したときと同様で、BigQuery スクリプトと対戦勝利確率を使用してトーナメント全体の各ラウンドをループ処理します。異なるのは、乱数生成を使用して各対戦での実際の勝者を(勝利確率に基づいて)シミュレーションする点と、多数のシミュレーションでこれを行い、考えられるブラケットを 1 つだけでなく何千通りも生成する、つまり本当のモンテカルロ シミュレーションを行うという点です。詳細は下のコードをご覧ください(ここでも、表示を簡略化するためにコードを省略した部分を「[...]」に置き換えています)。
数分間これを実行すると、男女それぞれに 1 つだけではなく、2 万通りずつ(最初のほうで挙げたブラケット予想ごとに 1 万通りずつ)の NCAA トーナメント ブラケットが完成します。完成したブラケットはいずれも、BigQuery BI Engine で高速化したこちらの対話型データポータル ダッシュボードで公開しています。[Pick A Sim #] を使うと、いくつもブラケットを切り替えて表示でき、上部にあるプルダウンを使えば、性別や開始するブラケットでフィルタ処理ができます。ブラケット内の各チーム名の横に書かれているパーセンテージは、前のラウンドで所定の相手と対戦した場合にそのチームがそのラウンドに進出する確率です(青色は結果が順当であること、赤色は大番狂わせ、黄色は五分五分程度であることを表します)。[Thru Round] を使うと、あたかもラウンドが 1 つずつ進んで行くように、トーナメントの勝ち上がりを表示できます。
一番のお気に入りが見つかるまで、何個でもシミュレーション結果を表示してみてください。中にはとんでもない結果もあります。たとえば Lunardi 氏の男子のブラケット シミュレーション 108 をご覧ください。ボストン大学(著者の母校)が番狂わせを 3 回も演じ、第 16 シードでエリートエイト(ベスト 8)入りを果たしています。
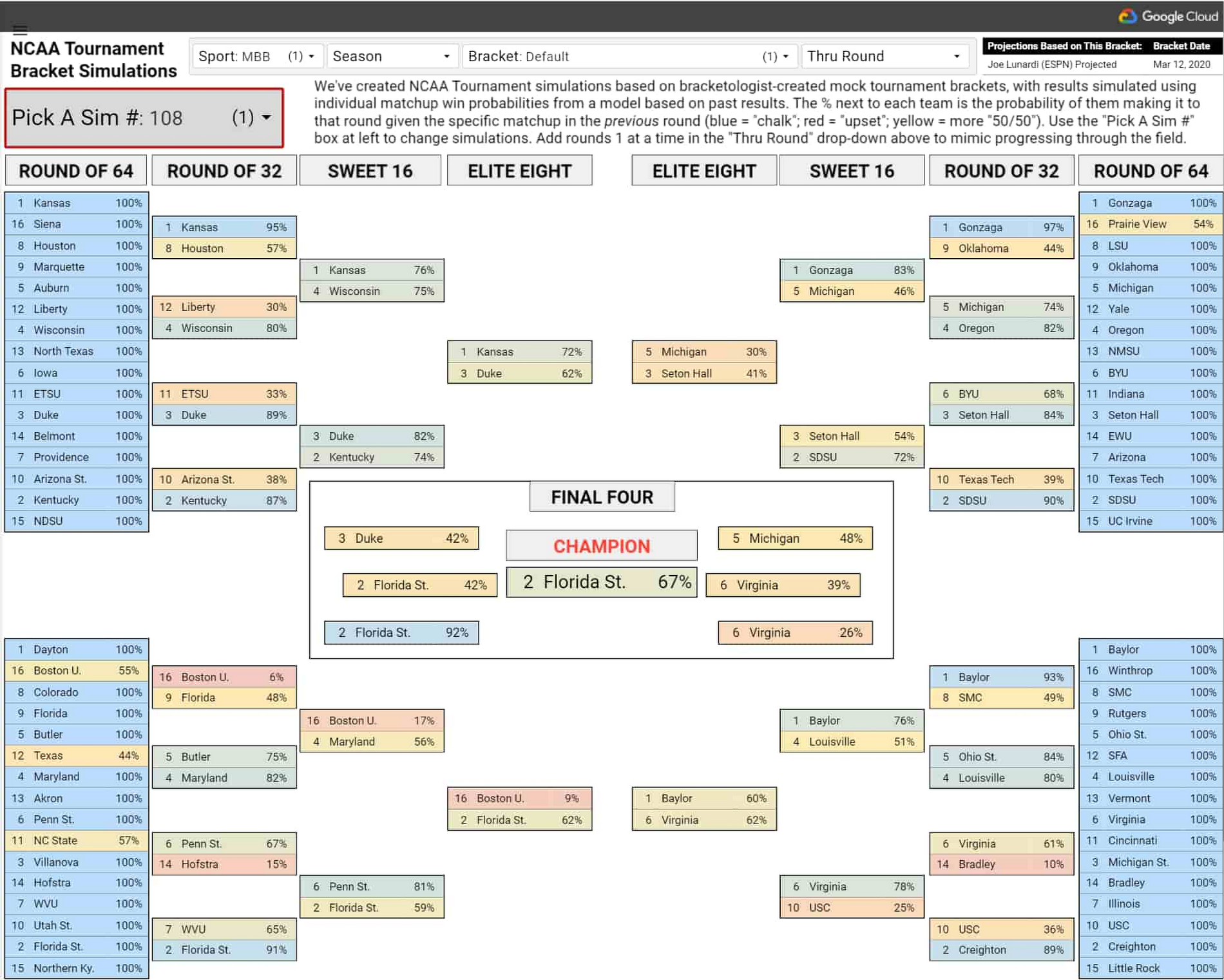
トーナメントがなくて良かったことがあるとすれば、トーナメントが行われていたらきっとこうなっていたに違いないと、気に入ったシミュレーション結果を選んで自分自身を納得させられることではないでしょうか。
もちろん、これらのブラケットは無作為のコイン投げに基づくものではありません。その場合は、まったくのカオス状態のブラケットが、番狂わせが少なく、一見もっともらしいブラケットになってしまうでしょう。シミュレーションしたどのブラケットでもボストン大学はファイナル フォー(ベスト 4)に進出していませんが(ただし、BigQuery のスケーラビリティを活かしてシミュレーションの実行回数を増やすこともできます)、上位シードははるかに高い頻度でファイナル フォーに進出しています。各シミュレーションは、各対戦の勝ち上がり見込みを、前述したモデルに基づいて正確に反映しています。つまり、生成されたそれぞれのブラケットは、3 月に行われる大学バスケットボールの特徴を示す狂乱ぶりを適切に反映しているということです。このようなタイプのシミュレーションを作成して、バスケットボール以外でデータ予測の問題を解決しようとする場合は、不確定要素を適切に捉えることが一般論として重要だということを覚えておくとよいでしょう。
本来であれば数日後に準決勝と決勝戦が行われる予定でしたが、その代わりに数千通りものシミュレーション版ファイナル フォーを楽しんでいただければ幸いです。これが少しでも、2020 年の NCAA バスケットボール トーナメントがなくて寂しい思いをしている方の慰めになることを願っています。また、Medium の NCAA ブログにアクセスすると、Google Cloud を使って行った過去のバスケットボール データ分析をすべてご覧いただけます。来年以降は、みんなが実際のマーチ マッドネスを観戦してお祭り騒ぎできることを楽しみにしています。
- By データ サイエンス デベロッパー アドボケイト Alok Pattani



