Lightning Engine のご紹介 - Apache Spark を次世代のパフォーマンスに
Abhishek Modi
Principal Software Engineer, Google Cloud
Susheel Kaushik
Group Product Manager
※この投稿は米国時間 2025 年 5 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Spark を使用すると、ETL、データ サイエンス、ML などのユースケースで大量のデータを分析できます。とはいえ、高いパフォーマンスと費用対効果を大規模に達成するのは容易ではありません。クエリの実行速度、データの入出力(I/O)、リソースの使用率に関連するボトルネックが発生し、結果として処理時間が長くなったり、インフラストラクチャ費用が増加したりすることもよくあります。
Google Cloud は、このような課題を深く理解しています。そこで、Spark で最高水準のパフォーマンスを実現するために、Lightning Engine(プレビュー版)を導入いたします。これは、これまでで最も強力な最新の Spark エンジンで、レイクハウスの真の可能性を引き出すように設計されています。
Lightning Engine とは
Lightning Engine は、クエリや実行の最適化などの従来の最適化手法と、ファイル システムレイヤやデータアクセス コネクタでのキュレートされた最適化の両方に焦点を当てた、マルチレイヤの最適化エンジンです。
たとえば、10 TB サイズのデータセットの場合、Lightning Engine により、Spark クエリのパフォーマンスは、同様のインフラストラクチャで実行されるオープンソースの Spark と比較して、TPC-H のようなワークロードで 3.6 倍* 高速化されます。

* クエリは TPC-H 標準から派生したものであり、TPC-H 標準仕様のすべての要件に準拠していないため、公開されている TPC-H 標準の結果と比較することはできません。
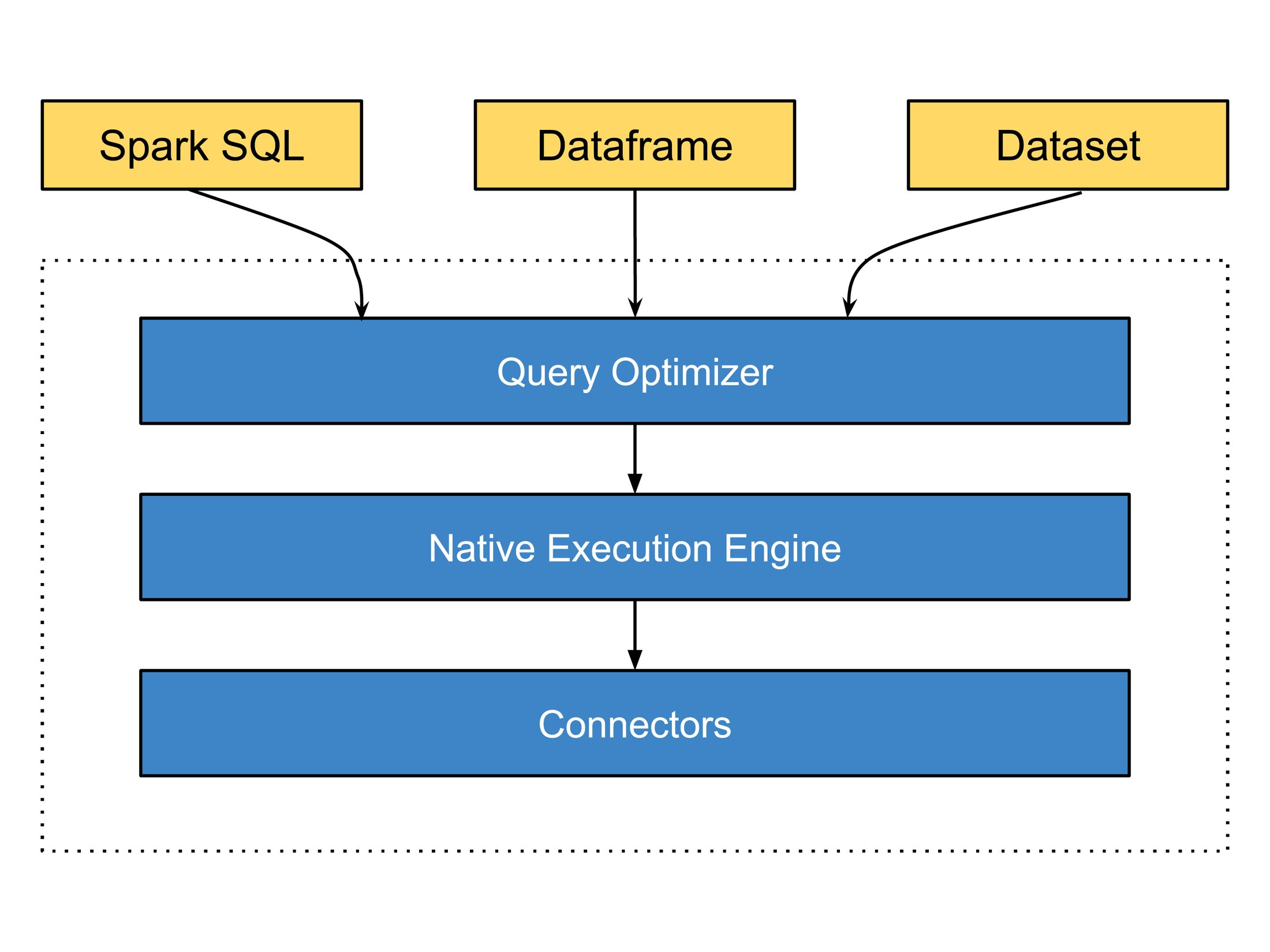
*図 1
図 1 に示すように、Lightning Engine の主な機能強化には次のようなものがあります。
-
クエリ オプティマイザー: Lightning Engine には、F1 や Procella などのエンジンから得た Google の専門知識を活用して、大幅に改善された Spark オプティマイザーが組み込まれています。この高度なオプティマイザーには、リスト呼び出しの統計情報に基づく最適化された Bloom フィルタの実装、スキャンを統合するサブクエリの融合、シャッフルを最小限に抑える部分集計のプッシュダウン、結合の削除とエクスチェンジの再利用のための適応型クエリ実行の強化、セミ結合のプッシュダウンのための高度な推論フィルタ、Iceberg テーブルと Delta テーブルで効率的な行グループのプルーニングを行うための動的フィルタ生成など、さまざまな最適化機能が導入されています。これらを組み合わせることで、スキャンとシャッフルを大幅に削減できます。
-
実行エンジン: Lightning Engine の実行エンジンは、Google のハードウェアを利用することを想定して設計された Apache Gluten と Velox に基づくネイティブな実装によってパフォーマンスを向上させます。これには統合メモリ管理が含まれており、既存の Spark 構成を変更することなく、オフヒープ メモリとオンヒープ メモリを動的に切り替えられます。また、Lightning Engine は、演算子、関数、Spark データ型への対応を拡張しているほか、ネイティブ エンジンを活用してオペレーションのプッシュダウンを最適化する機会を自動的に特定するインテリジェンスも備えています。
-
シャッフル: Lightning Engine は、最適化されたシリアライザとデシリアライザを使用した列シャッフルを組み込むことで、シャッフル データを最小限に抑えます。
-
ファイル パーサー: Lightning Engine には、プリフェッチ、インテリジェント キャッシング、高度なインフィルタリングを行うための特殊な Parquet パーサーが含まれており、データスキャンとメタデータ オペレーションを削減します。
-
コネクタ: Lightning Engine は Google Cloud Storage と BigQuery への接続を強化し、ネイティブ エンジンのパフォーマンスを最適化します。改良された Cloud Storage コネクタにより、メタデータ オペレーションを最小限に抑えることで費用の削減が実現し、最適化されたファイル出力コミッターにより、Spark ワークロードのパフォーマンスと信頼性が高まります。また、新しいネイティブの BigQuery コネクタは、データをApache Arrow 形式でエンジンに直接送信することでデータ転送を合理化し、行から列に変換する際のオーバーヘッドを排除します。
Lightning Engine は、Apache Spark DataFrame および SQL API に対応しており、既存のコードに変更を加えなくてもシームレスにワークロードを実行できます。
Lightning Engine を選ぶ理由
他のクラウド Spark ソリューションと比較して、Lightning Engine は優れたパフォーマンスと費用対効果を発揮します。Apache Iceberg や Delta Lake などのオープン形式に対応しており、BigQuery や Google Cloud の高度な AI / ML と組み合わせることで、ビジネスの効率を向上させることができます。
また、Lightning Engine により、DIY の Spark 実装よりもパフォーマンスが向上し、大幅な費用削減を達成できるため、管理者はプラットフォームのメンテナンスではなく、ビジネスの主要課題に専念できます。
Lightning Engine の主なメリット:
-
パフォーマンスの向上: ベクトル化された実行、組み込みインテリジェント キャッシング、最適化されたストレージ I/O を備えた新しい Spark 処理エンジンを活用しており、クエリ パフォーマンスが大幅に高速化します。
-
業界をリードするコスト パフォーマンス: 優れたパフォーマンスと費用効率を実現し、ユーザーはより少ない費用でより多くのデータを処理できます。
-
直感的なレイクハウス インテグレーション: Apache Iceberg、Delta Lake、BigQuery や Vertex AI などの Google Cloud サービスと連携し、データ分析と AI のための統合されたプラットフォームを提供します。
-
データアクセスの強化: Cloud Storage と BigQuery 向けに最適化されたコネクタにより、データアクセスのレイテンシの改善、メタデータ オペレーションの削減、スループットの向上を実現します。
-
柔軟なデプロイ: サーバーレス構成とクラスタベースの構成の両方で利用できます。
Lightning Engine はパフォーマンスを大幅に向上させますが、具体的な効果はワークロードによって異なります。I/O の制約を受けるオペレーションよりも、Spark Dataframe API と Spark SQL クエリを活用するコンピューティング負荷の高いタスクに最適です。
Google Cloud における Spark の未来
新しい高性能なデータ クエリエンジンである Lightning Engine により、Google のスケール、優れたパフォーマンス、卓越したエンジニアリングを Apache Spark ワークロードに活用することで、イノベーションを推進して、世界中のデベロッパーを支援できることを嬉しく思います。これは始まりにすぎません。今後数か月以内にさらに高速化する予定です。
Lightning Engine は、Apache Spark 向け Google Cloud Serverless と Google Compute Engine プレミアム ティアの Dataproc の両方でプレビュー版としてご利用いただけます。どちらのサービスも、ML ワークロードを高速化するために GPU に対応しており、運用効率向上のためのジョブ モニタリング ツールを備えています。こちらから限定公開プレビュー版への早期アクセスをリクエストしてください。
このブログ投稿の執筆に協力してくれたシニア エンジニアリング マネージャーの Newton Alex に心より感謝します。
-プリンシパル ソフトウェア エンジニア Abhishek Modi
-グループ プロダクト マネージャー Susheel Kaushik

