データの地理的な冗長性を高める BigQuery クロスリージョン レプリケーション
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
地理的な冗長性を高めることは、クラウドで復元力のあるデータレイク アーキテクチャを設計する際の鍵となります。地理的に離れた場所にデータを複製するユースケースとしては、低レイテンシでの読み取り(エンドユーザーに近い場所でのデータ読み取り)、規制要件の遵守、他のサービスとのデータのコロケーション、ミッション クリティカルなアプリのデータ冗長性の維持などがあります。
BigQuery ではすでに、データセット リージョン内の 2 つの異なる Google Cloud ゾーンにデータのコピーが保存されるようになっており、どのリージョンでもゾーン間のレプリケーションで同期二重書き込みが実行されます。これにより、ゾーン障害が発生した場合にも、それがソフトに起因するもの(停電、ネットワーク パーティション)かハードに起因するもの(洪水、地震、台風)かを問わず、データ損失を招くことなくほぼ瞬時に復旧することができます。
このたび、この機能をさらに発展させ、クロスリージョン データセット レプリケーションのプレビュー版をリリースしました。これにより、クラウド リージョン間で、継続的な変更を含むあらゆるデータセットを簡単に複製できるようになります。継続的なレプリケーションのユースケースに加え、クロスリージョン レプリケーションを利用して、あるソース リージョンから別の宛先リージョンに BigQuery データセットを移行することも可能です。
仕組み
BigQuery は、クロスリージョン レプリケーション用にプライマリ構成とセカンダリ構成を提供します。
- プライマリ リージョン: ユーザーがデータセットを作成すると、BigQuery は選択したリージョンをプライマリ レプリカのロケーションとして指定します。
- セカンダリ リージョン: 選択したリージョンにユーザーがデータセット レプリカを追加すると、BigQuery はこれをセカンダリ レプリカとして指定します。セカンダリ リージョンにはユーザーが任意のリージョンを指定できます。セカンダリ レプリカは複数使用できます。
プライマリ レプリカは書き込み可能で、セカンダリ レプリカは読み取り専用です。プライマリ レプリカへの書き込みは、セカンダリ レプリカに非同期で複製されます。各リージョン内では、データが 2 つのゾーンに冗長的に保存されます。ネットワーク トラフィックが Google Cloud ネットワークの外部に出ることはありません。
レプリカは異なるリージョンにありますが、名前は同一です。したがって、異なるリージョンにあるレプリカを参照する際にクエリを変更する必要はありません。
次の図は、データセットが複製されるときに発生するレプリケーションを示しています。
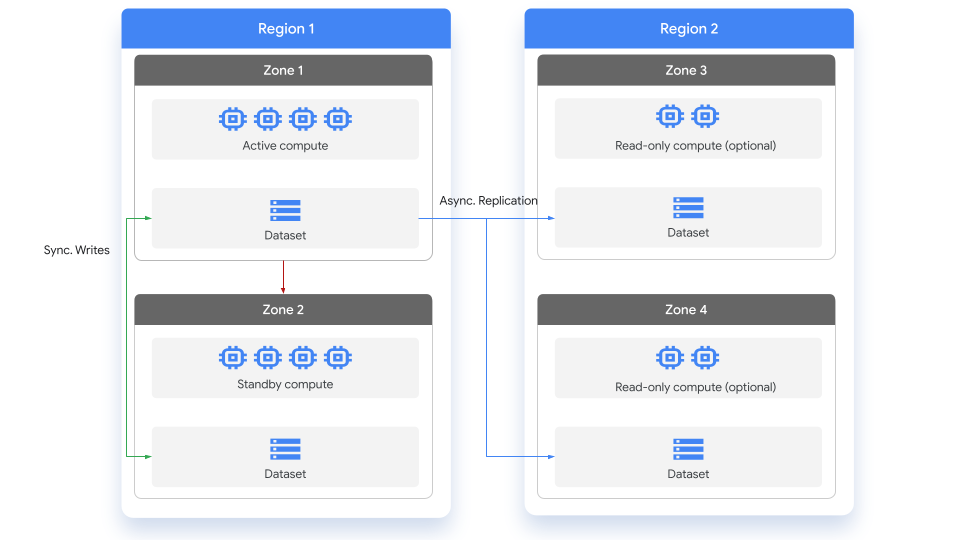
レプリケーションの実例
次のワークフローは、BigQuery データセットにレプリケーションを設定する方法を示しています。
特定のデータセットのレプリカを作成する
データセットを複製するには、ALTER SCHEMA ADD REPLICA DDL ステートメントを使用します。
各リージョンまたはマルチリージョン内の任意のデータセットに単一のレプリカを追加できます。レプリカを追加した後、最初のコピー オペレーションが完了するまで時間がかかります。データの複製中も、プライマリ レプリカを参照するクエリを実行できます。クエリの処理能力が低下することはありません。
セカンダリ レプリカが正常に作成されたことをステータスで確認するには、INFORMATION_SCHEMA.SCHEMATA_REPLICAS ビューで creation_complete 列に対してクエリを実行します。
セカンダリ レプリカに対してクエリを実行する
最初の作成が完了すると、セカンダリ レプリカに対して読み取り専用のクエリを実行できます。これを行うには、[クエリの設定] または BigQuery API でジョブのロケーションをセカンダリ リージョンに設定します。ロケーションを指定しない場合、BigQuery は、プライマリ レプリカのロケーションにクエリを自動的にルーティングします。
BigQuery の容量の予約を使用している場合は、セカンダリ レプリカのロケーションに予約が存在する必要があります。予約がない場合、クエリは BigQuery のオンデマンド処理モデルを使用します。
セカンダリ レプリカをプライマリ レプリカに昇格させる
レプリカをプライマリ レプリカに昇格させるには、ALTER SCHEMA SET OPTIONS DDL ステートメントを使用して primary_replica オプションを設定します。[クエリの設定] で、ジョブのロケーションを明示的にセカンダリ リージョンに設定する必要があります。
数秒後、セカンダリ レプリカがプライマリになり、新しいロケーションで読み取りと書き込みの両方のオペレーションを実行できるようになります。同様に、プライマリだったレプリカはセカンダリになり、読み取りオペレーションのみが行えるようになります。
データセットのレプリカを削除する
レプリカを削除してデータセットの複製を停止するには、ALTER SCHEMA DROP REPLICA DDL ステートメントを使用します。リージョン間の移行にレプリケーションを使用している場合は、セカンダリをプライマリに昇格させた後にレプリカを削除してください。この手順は必須ではありませんが、データセット レプリカを移行以外の目的では必要としない場合に便利です。
ご利用にあたって
BigQuery でクロスリージョン レプリケーションのプレビュー版が利用可能になったことで、地理的な冗長性が高まり、リージョンの移行のユースケースにも対応できるようになります。将来的には、レプリカの構成や管理を行うコンソールベースのユーザー インターフェースが組み込まれる予定です。また、クロスリージョン レプリケーションを拡張し、リージョン全体のサービスが停止するという稀なケースでもワークロードを保護できる、クロスリージョンの障害復旧(DR)機能も提供する予定です。BigQuery とクロスリージョン レプリケーションの詳細については、BigQuery クロスリージョン データセット レプリケーションのクイックスタートをご覧ください。
ー エンジニアリング ディレクター Ahmed Ayad
ー シニア プロダクト マネージャー Vinod Ramachandran
