データ サイエンス エクスペリエンスをスケーラブルな Python データ処理で強化
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
Python は、分析や機械学習に関連したユースケースに向けてデータを準備、処理、分析しているデータ サイエンティストにとって、代表的な言語の一つとして急速に定着しました。Dask は、Pandas、NumPy、scikit-learn といった特に人気のある Python データ サイエンティスト ライブラリと同様の API を備えた並列コンピューティング用の Python ライブラリです。Dask の並列処理により、機械学習とデータ処理タスクの効率が向上し、レイテンシを低く抑えることができます。このたび、新しい Dask 初期化アクションを通じて、Google Cloud のフルマネージド Apache Hadoop と Apache Spark サービスである Dataprocが Dask でサポートされるようになりました。この Dataproc 初期化アクションにより、データ サイエンティストはさらに簡単に Dataproc クラスタで Dask を起動し実行できるようになります。
Dask は現在、PyData や SciPy コミュニティ内で最もよく使用されている並列処理フレームワークです。ノートパソコンの CPU 上の並列化されたワークロードから、クラウド クラスタ内の数千のノードまでスケールできるように設計されています。NVIDIA が開発した RAPIDS フレームワークと組み合わせることで、CPU と NVIDIA GPU の両方の並列処理能力を活用できます。
Python データ サイエンス コミュニティ向けに構築された Dask
Dask は NumPy、Pandas、scikit-learn に加え、その他の人気のある Python データ サイエンス ライブラリに基づいて構築されています。そのため、API はこれらのコアライブラリから、スケーラブルな Dask のそれぞれのバージョンにシームレスに移行できるよう意図的な設計がなされています。これらのライブラリの一部が Dask に変換される方法についての優れた例が、こちらの Dask のドキュメントに記載されておりますのでご覧ください。
Dask のユースケース
Dask は、ハイ パフォーマンス コンピューティング、気候科学、バンキング、画像の問題など、さまざまな問題に取り組んでいるデータ サイエンス チームによって使用されています。加えて、ビジネス インテリジェンスに関する問題にも適しています。チームが Dask を使用して取り組んだ問題の一覧については、こちらをご覧ください。
Dataproc で Dask を使用する理由
Dask は、ビッグデータに対してデータ変換ジョブを迅速かつ簡単に実行する方法を提供します。Yarn で Dask アプリケーションを実行するための Skein ベースのツールである Dask-Yarn を使用すると、タスクのスケジューリングが YARN スケジューラに委ねられるため、クラスタ上の別の一連のソフトウェアを管理する必要がありません。また、Yarn がジョブの処理を完了させるために必要なリソース管理の割り振りを行います。さらに、自動スケーリング、Jupyter コンポーネント、Jupyter Notebook 経由でジョブを送信するためのコンポーネント ゲートウェイなど、Dataproc サービスが提供するすべての機能を使用できます。
Dask は GCS や HDFS などの多様なソース、そして CSV、Parquet、Avro などの各種データ型からのデータ読み込みをサポートしています。これらは、PyArrow、GCSFS、fastparquet、fastavro などのさまざまなプロジェクトでサポートされており、すべて Dataproc に含まれています。
また、Yarn ではなく、ネイティブ スケジューラで Dask を活用するように Dataproc で Dask を構成することもできます。
Dask による Dataproc クラスタの作成
次のコマンドで、Dask 初期化アクション、Jupyter のオプション コンポーネント、コンポーネント ゲートウェイを有効にし、リージョンを選択して、Dataproc クラスタを作成します。
「dask-runtime」メタデータ パラメータを「standalone」に変更することで、クラスタを作成することもできます。
クラスタの操作
ご利用の環境で Dask を構成したら、Jupyter などのノートブック環境を使用するか、クラスタのマスターノードに SSH 接続して、Dask スクリプトを実行することで、Dask ジョブを実行できます。
次のコマンドで、クラスタのマスターノードに SSH 接続できます。
次に、Python ベースの環境を使用してジョブを送信します。以下のコマンドを、クラスタの Python ファイル(dask_job.py)にコピーします。これにより、Dask クラスタを操作できる「YarnCluster」オブジェクトが作成され、Dask が必要に応じてリソースをスケールし、配列を合計する機能が追加されます。
ジョブを送信します。
出力は浮動小数点数になります。
ノートブックを使用して Dask ジョブを実行することもできます。ノートブックを使用することには、データ構造をグラフィカルに表示できるなど、いくつかの追加のメリットがあります。
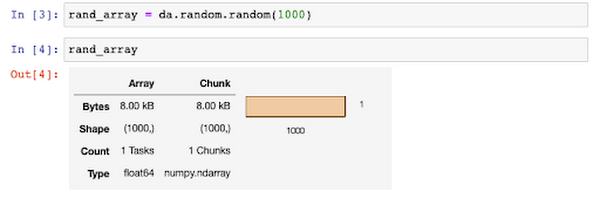
また、Jupyter Notebook で Dask を使用すると、API だけでなく、グラフィカル インターフェースでも、Dask クラスタのリソースを管理できます。
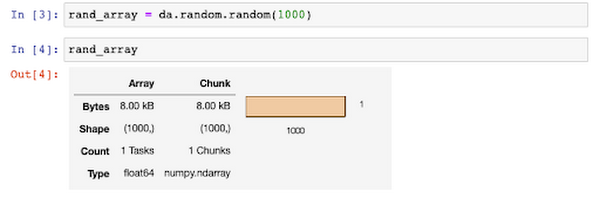
Dask ワークロードのモニタリング
Dask アプリケーションのモニタリングに、複数のウェブ UI を使用することができます。Dask-Yarn では、Dataproc コンソールのクラスタ モニターを使用して、YARN メモリや YARN 保留中メモリなどの指標を表示できます。
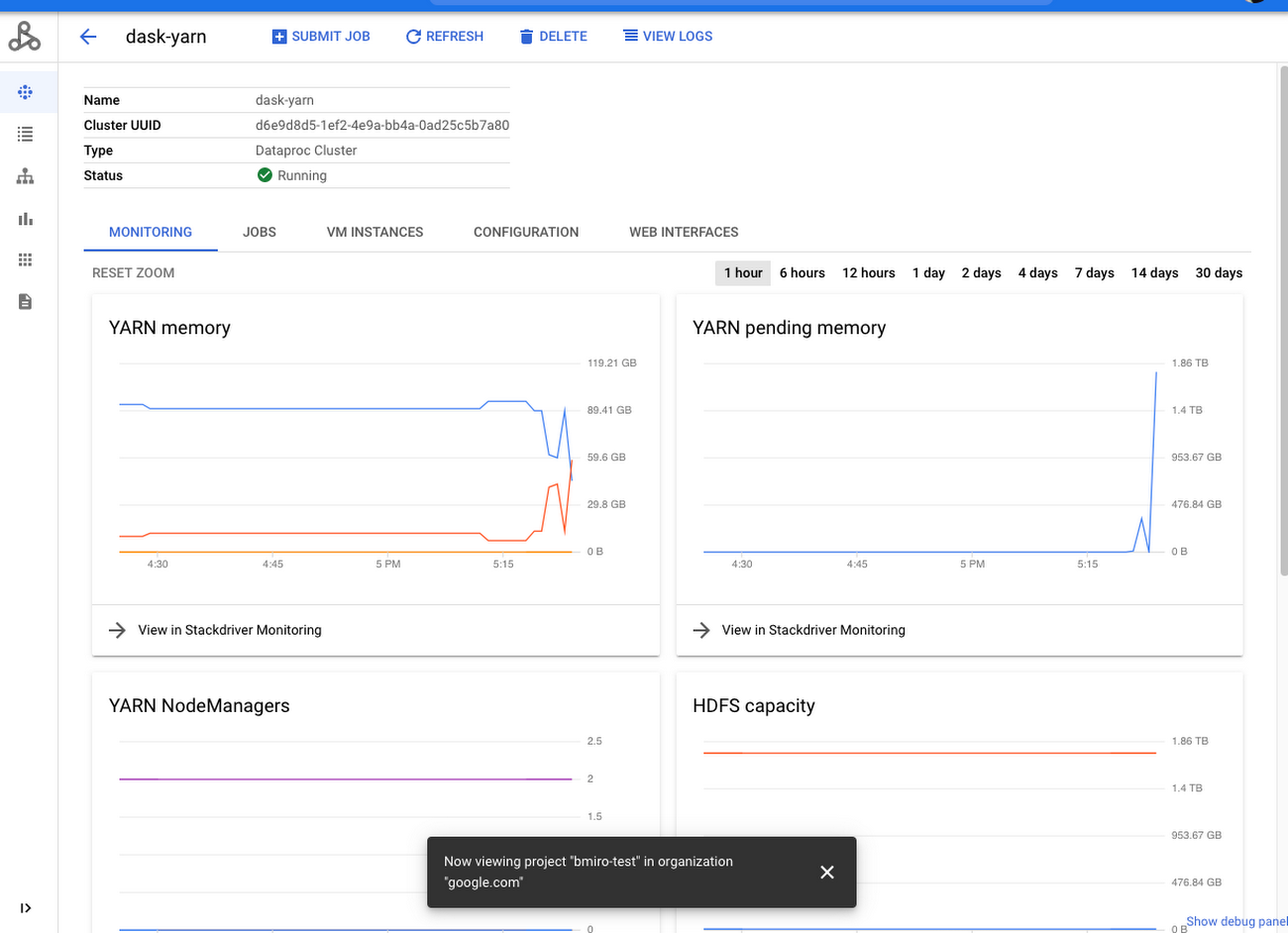
Dask-Yarn を使用している場合、Skein のウェブ UI にもアクセスすることができます。これは、YARN ResourceManager 内でアプリケーションのアプリケーション マスターとして表示されます。YARN ResourceManager にはコンポーネント ゲートウェイによりアクセスできます。
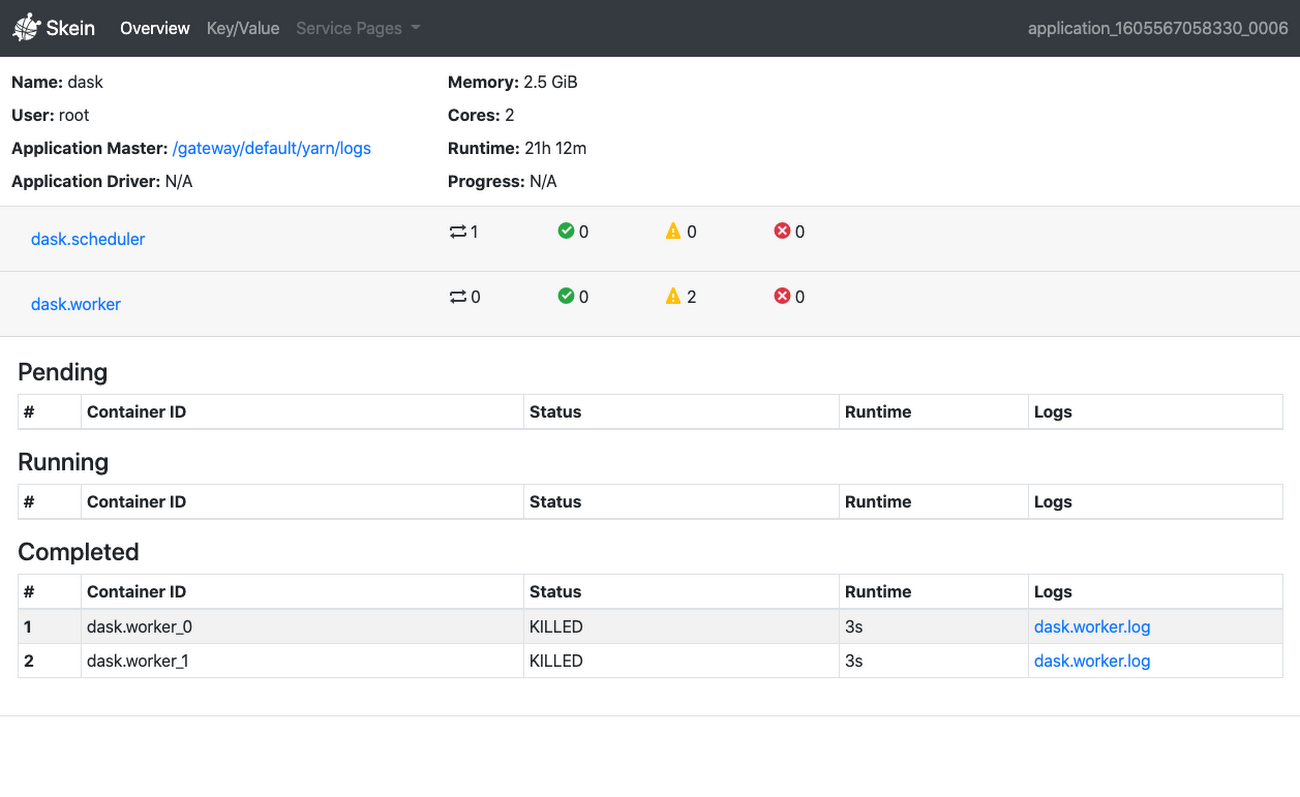
Dask のスタンドアロン スケジューラを使用している場合、SSH トンネル経由で Dask のウェブ UI にアクセスできます。
Dask の CPU 並列処理と NVIDIA RAPIDS の GPU 並列処理の組み合わせ
Dask の CPU 並列処理機能を、Dataproc もサポートしている RAPIDS オープンソース データ サイエンス フレームワークの NVIDIA GPU 並列処理機能と組み合わせることができます。次のコマンドで、Dask、RAPIDS、NVIDIA GPU、必要なドライバを使用して、Dataproc クラスタを作成できます。
「dask_cudf」などの複数のライブラリを含む、RAPIDS や Dask エコシステムの詳細については、こちらの RAPIDS ドキュメントをご覧ください。
まとめ
Dask は、ここ数年で著しい成長を遂げた画期的なフレームワークです。皆様が Dataproc で Dask を使って目的を達成されることを楽しみにしております。Dataproc で Dask を使い始める方法の詳細については、Dask 公式ドキュメントのクイックスタートをご覧ください。初めてのお客様は、Google Cloud Platform の $300 相当のクレジットを利用して、Dataproc で Dask を使い始めることもできます。
-デベロッパー プログラム エンジニア Brad Miro



