BigQuery データ キャンバスのプロンプト記述に関するベスト プラクティス
Christine De Sario
Customer Engineer - Data & Analytics, Google
Layolin Jesudhass
Global Generative AI Solutions Architect, Google
※この投稿は米国時間 2024 年 7 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
これまで、SQL に精通していることは、データ専門家にとって重要な職務要件でした。しかし最近では、生成 AI を活用することで、データ専門家がスキルレベルを問わず自然言語プロンプトを使用して多様なデータタスクを実行できるようになったため、データや分析情報へのアクセスが民主化され、コラボレーションが促進されています。
BigQuery のエコシステムでは、基盤モデルの Gemini で、ユーザーがデータの検索、SQL の作成、グラフの生成、データ概要の作成を行うことができます。これらは、一般に NL2SQL や NL2Chart と呼ばれています。このようなタスクには、BigQuery データ キャンバスが使用されます。この汎用性に優れたツールは、開発者、データ サイエンティスト、アナリストによるクエリ作成プロセスと分析情報の共有を支援します。データ キャンバスでは、ユーザーが自然言語を使用して、テーブル アセットの検索、結合、クエリ、結果の可視化、プロセスを通じた他のユーザーとのコラボレーションを実行できます。これにより、最終的には分析が迅速化され、チーム全体の時間と労力が節約されます。
しかし、多くのデータ専門家は、既成の大規模言語モデル(LLM)は SQL の生成に適していないと認識しています。一方、これまでの経験上、適切なプロンプト手法を採用すれば、Gemini in BigQuery ではデータ キャンバスにより、データコーパスのコンテキストを元に複雑な SQL クエリを生成できます。データ キャンバスでは、並べ替え、グループ化、順位付け、レコード数の制限、SQL 構造の決定に自然言語クエリが使用されます。
このブログ投稿では、自然言語(NL)プロンプトを改善し、NL2SQL と NL2Chart のクエリの精度を高めるためのヒントを 5 つ紹介します。すぐに、BigQuery データ キャンバスを使用して、直感的な自然言語により、正確で洞察に富んだ SQL やグラフを生成できるようになります。
1. 明確さが重要
プロンプトはできるだけ明確に記述し、混乱を防ぐために、不完全または不正確な SQL は避けましょう。
-
あいまいではなく正確に: リクエストは明確に記述し、あいまいな表現は避けましょう。
非推奨: 「私の販売データについて教えてください。」
推奨: 「前四半期の総売上の商品カテゴリ別内訳を教えてください。」
正確さを重視することで、目標を迅速かつ効果的に達成できます。
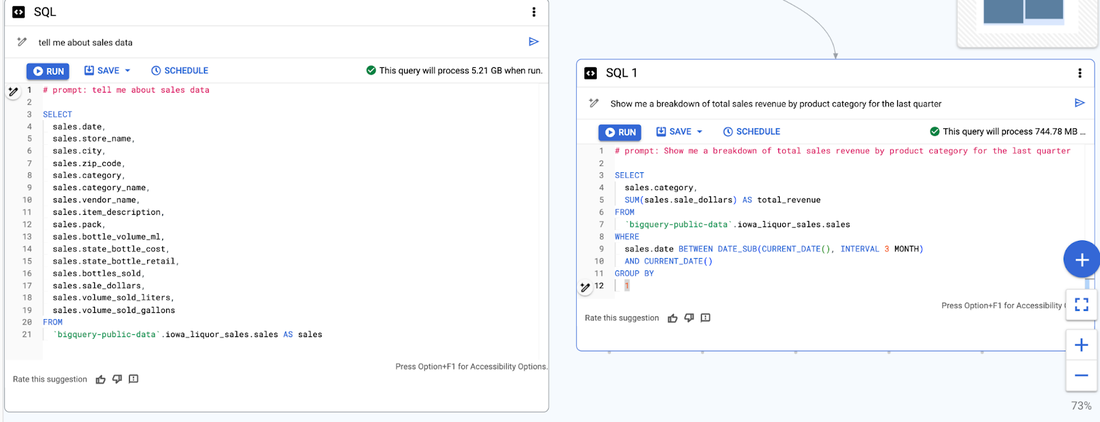
プロンプトと SQL 出力を並べた例(右側の画像はデータ キャンバスにおけるプロンプトの適切な構造を示しています)
-
-
コンテキストが重要: Gemini がリクエストを理解できるよう、関連する背景情報を提供しましょう。
非推奨: 「どのような傾向がありますか?」
推奨: 「過去 1 年間におけるモバイルアプリの 1 か月のアクティブ ユーザー数の傾向はどうなっていますか?」
-
完全な文章: 誤った解釈を避けるために、できるだけ詳細で完全な文章を使用しましょう。
非推奨: 「名前に『cloud-vision』が含まれるリポジトリのコミッターの日付に対して月名を略さず表示してください」 <<- ステップが不明確で不完全
推奨:
# プロンプト: コミッターの日付で、整数の月を完全な月名に変換してください。名前に「cloud-vision」が含まれるリポジトリの commit、リポジトリ名、作成者名、コミッター名、作成者の日付と年、コミッターの日付と年を列挙してください。LIKE では「%」を使用してください以下は、上のプロンプトによって生成された SQL です。妥当な出力が返されました。
-
2. 直接的な質問をする
LLM でプロンプトを記述する際には、率直で、一義的な表現を使用することが重要です。次の点にご留意ください。
-
質問は 1 つずつ: できるだけ正確な回答を得るには、詳細な指示を含む 1 つの質問を行うことを重視しましょう。指示を増やすことで、モデルがコンテキストを理解しやすくなります。一度の変換で、可能な限り詳しく記述しましょう。
-
過負荷を避ける: 情報量が多すぎて Gemini in BigQuery に過剰な負荷をかけないよう、プロンプトは簡潔にしましょう。必要に応じて、次の変換で新しいノードを追加することを検討してください。
非推奨: 「親、トレーラー、差異を除くすべての列を列挙してください。繰り返し列における最初のエントリのリポジトリ名のみを取得し、作成者とコミッターの日付(秒)をタイムスタンプの秒から日付に変換してください。commit、リポジトリ、作成者名、コミッター名も含めてください。」
推奨: リクエストを連続する 2 つの個別ノードに分割します。
# プロンプト: 親、トレーラー、差異を除くすべての列を列挙してください。繰り返し列における最初のエントリのリポジトリ名のみを取得してください
# プロンプト: 作成者とコミッターの日付(秒)をタイムスタンプの秒から日付に変換してください。commit、リポジトリ、作成者名、コミッター名も含めてください
3. 焦点を絞った明示的な指示を提供する
LLM では具体性が重要です。BigQuery データ キャンバスにコードの生成を要求する際には、次の点にご留意ください。
-
重要な用語を強調する: Gemini が理解しやすいよう、重要な用語をハイライト表示できます。次の例では、Gemini がクエリ内のハイライト表示されたキーワードを認識することで、この複雑なロジックを迅速に構築できました。
# プロンプト: すべての列に接頭辞としてレコード名を付けることで、作成者とコミッターのネストを解除し、すべての列を列挙してください。繰り返し列における最初のエントリのみの名前に GoogleCloudPlatform を含むリポジトリ名をマッチングしてください。LIKE には「%」を使用してください
以下の SQL が生成されます。
4. オペレーションの順序を指定する
Gemini in BigQuery での処理と回答が効果的に行われるようにするには、指示を明確に順序立てて提供することが重要です。これにより、混乱が防がれ、モデルが現在のタスクを正確に理解できるようになります。
以下は、Gemini in BigQuery に対して指示を明確に順序立てて提供するためのヒントです。
-
最初に目標を記述する: 具体的なステップの前に、望ましい結果を明確に示します。
-
簡潔な言葉を使う: 多義的な表現や、不必要な専門用語は使わないようにします。
-
分割する: 複雑なタスクは、小さくわかりやすいステップに分割します。
-
指示を再確認する: 指示が明確で、順序が論理的かどうかを送信前に確認します。
-
出力によっては、必要に応じてフレーズを並べ替えるか、言い換えます。
以下の例で、プロンプト構造が結果の SQL クエリ出力にどのように影響するかをご覧ください。 作成者とコミッターのフィールドのネストを解除するために使用される元のプロンプトが、フレーズを並べ替えるか、より明示的なフレーズを直感的でない順序で追加することによって変更が加えられています。
元のプロンプト:
# プロンプト: すべての列に接頭辞としてレコード名を付けることで、作成者とコミッターのネストを解除し、すべての列を列挙してください。繰り返し列における最初のエントリのみの名前に GoogleCloudPlatform を含むリポジトリ名をマッチングしてください。
プロンプトのフレーズの順序を逆にすると、結果の SQL 出力に OFFSET 構文が追加されています。これは有効なクエリですが、データは表示されません。
変更後のプロンプト:
# プロンプト: 繰り返し列における最初のエントリのみの GoogleCloudPlatform を含むリポジトリ名をマッチングしてください。すべての列に接頭辞としてレコード名を付けることで、作成者とコミッターのネストを解除し、すべての列を列挙してください。
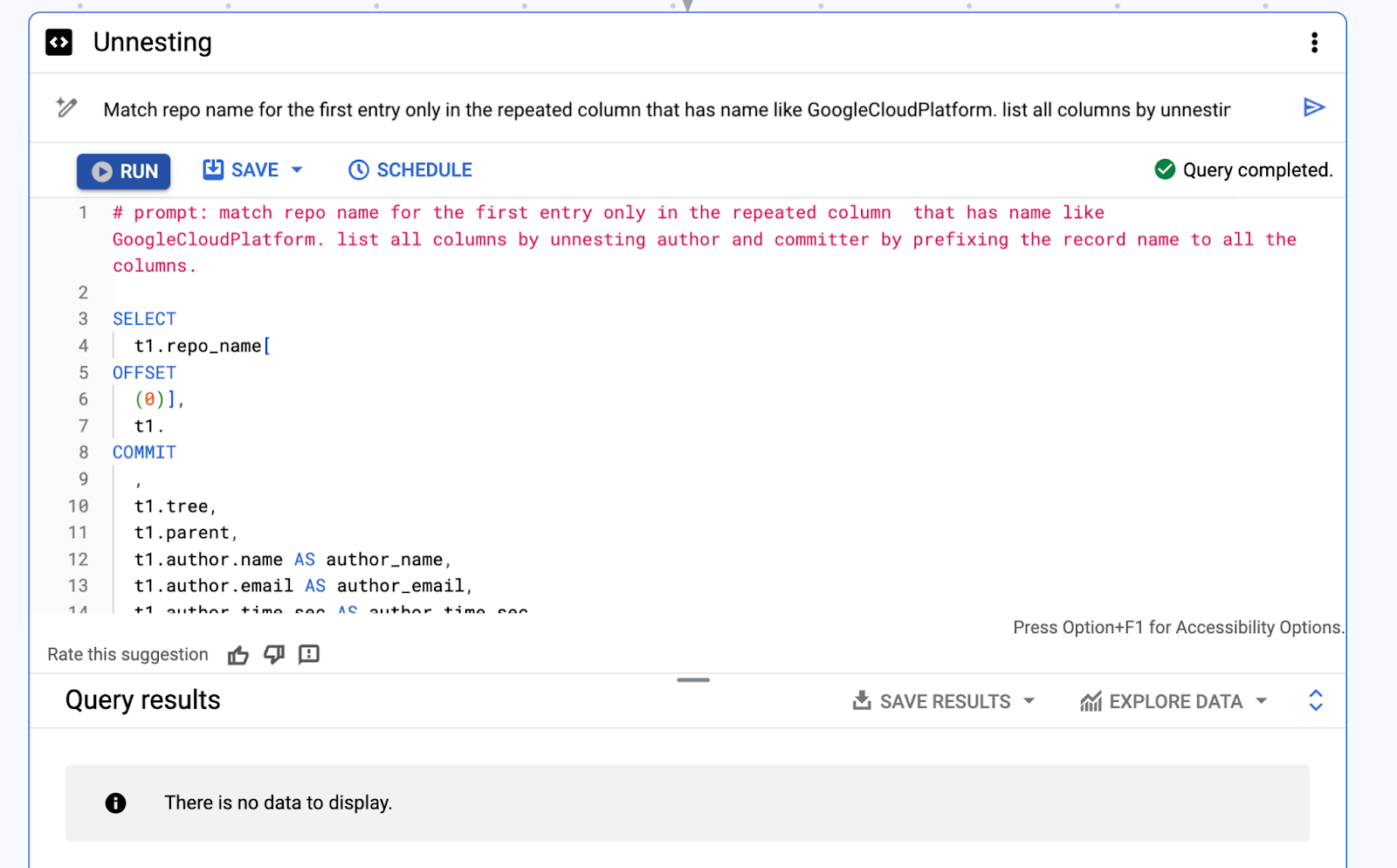
この最後の例では、前の SQL 出力にはなかった「LIKE で % を使用」が追加されています。この変更により、結果の SQL 出力で次のエラーが発生します。
2 つ目の変更後のプロンプト:
# プロンプト: LIKE で「%」を使用し、繰り返し列における最初のエントリのみの GoogleCloudPlatform を含むリポジトリ名をマッチングしてください。すべての列に接頭辞としてレコード名を付けることで、作成者とコミッターのネストを解除し、すべての列を列挙してください。
Error: No matching signature for operator LIKE for argument types: ARRAY<STRING>, STRING. Supported signatures: STRING LIKE STRING; BYTES LIKE BYTES at [31:3]
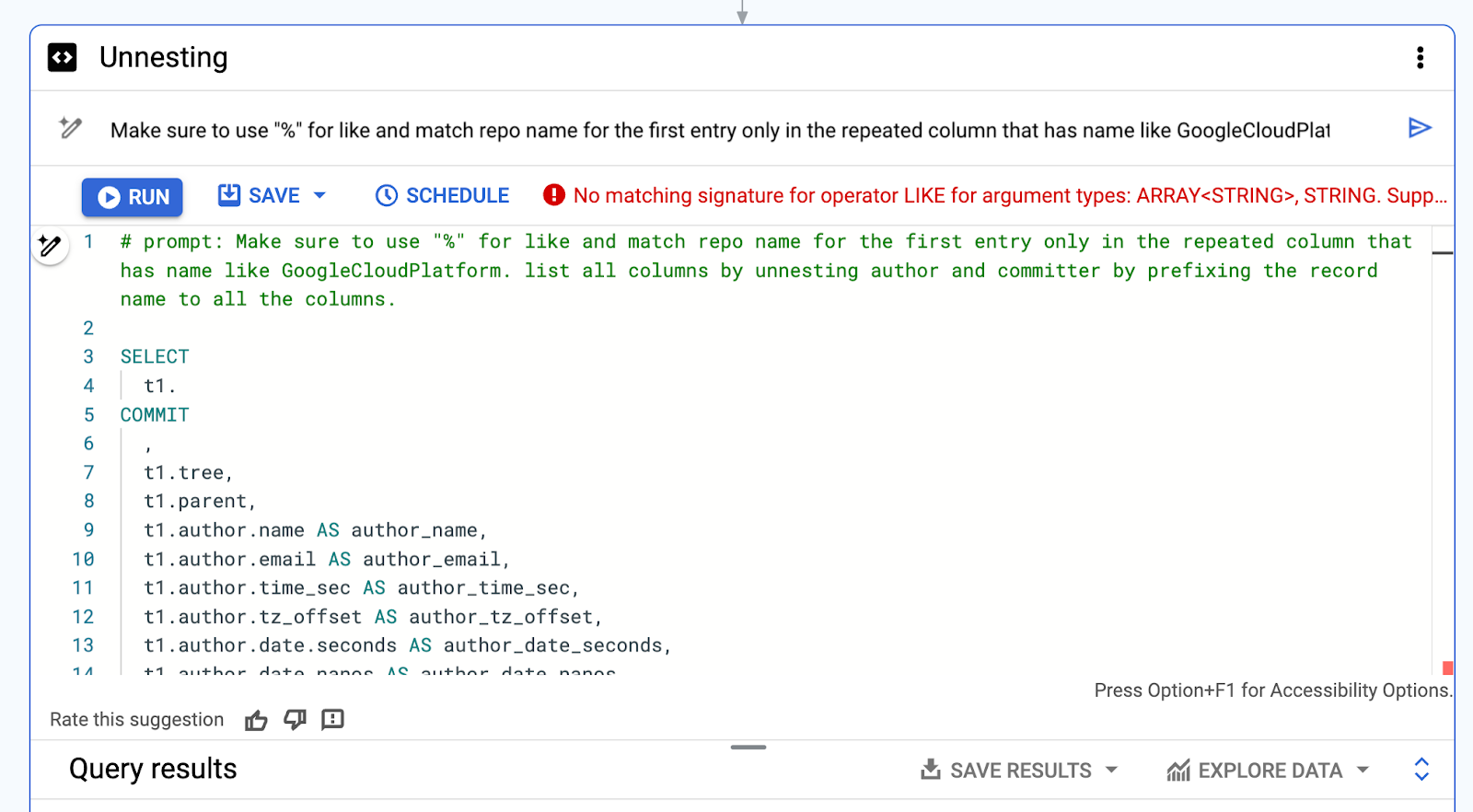
5. 改善して繰り返す
何事も、最初は成功しなくても繰り返し挑戦してください。BigQuery データ キャンバスで Gemini を使用する場合は、以下が重要です。
-
試行: 複数の言い回しやアプローチを試して、どれが最善の結果をもたらすのかを確認しましょう。
-
フィードバックから学習する: Gemini のレスポンスに基づいてプロンプトを調整し、将来のインタラクションを改善しましょう。
NL2Chart を使用してグラフを作成する
可視化に関しては、NL2Chart は自然言語の説明を洞察に富んだグラフに変換できる高度なツールであり、前述のアドバイスがすべて当てはまります。その効果を最大限に高めるには、プロンプトの作成時に次のガイドラインに沿って操作してください。
-
具体的かつ簡潔に: 必要なグラフの種類(棒、折れ線、円など)と、可視化する必要がある具体的なデータを明確に記述します。多義的な記述や、不必要な情報は避けます。
-
データを定義する: グラフに含めるデータポイント、変数、カテゴリを正確に指定します。
-
期間を設定する: 時間依存のデータについては、分析期間を明確に定義します(例: 「2023 年第 1 四半期」、「過去 5 年間」)。
-
単位とラベル: データの測定単位(例: ドル、パーセント、販売数)と、軸、タイトル、データポイントに対する任意のラベルを指定します。
-
カスタマイズ: 好みの色やスタイル、または特定の書式設定オプションがある場合は、それらをプロンプトに含めることができます。ただし、NL2Chart では適切に動作するデフォルト設定が数多く用意されています。
プロンプトの例
-
基本: 「前四半期の各商品カテゴリの売上高を示す棒グラフを作成してください。」
-
中級: 「2020 年 1 月 1 日から 2023 年 12 月 31 日までの Apple と Microsoft の株価を比較する折れ線グラフを生成してください。」
-
上級: 「過去 1 年間の広告費とウェブサイト トラフィックの関係を、トレンドラインと R 2 乗値を使用して示す散布図を作成してください。」
その他のヒント
-
試行: プロンプトで、複数の言い回しや詳細レベルを積極的に試してください。NL2Chart は汎用性が非常に高いツールです。
-
反復処理: 最初のグラフが想定どおりではない場合は、NL2Chart の出力を理想に近づけるため、プロンプトを改善するか、追加の情報を提供してください。
-
制限: NL2Chart は、複雑なリクエストや非常に具体性の高いリクエストは理解できない可能性があるのでご注意ください。最初はシンプルなプロンプトを記述し、必要に応じて徐々に複雑さを調整しましょう。
-
代替ツール: NL2Chart ではニーズが満たされない場合は、NL からグラフを生成できるその他のオンライン ツールを検討してください。
上述のガイドラインに沿って操作することで、NL2Chart を効果的に活用して、データ分析とコミュニケーションを強化する有益かつ視覚的に魅力があるグラフを作成できます。
これに加えて、可視化自体のカスタマイズに関する詳細も含めることができます。トレンドライン、棒グラフの棒、円グラフの領域、データ系列のうちいずれかのカラーパターンなど、グラフの要素をカスタマイズできます。また、グラフの軸、軸ラベル、タイトル、凡例も指定できます。最後に、下の 2 つ目の例に示すように、データを昇順、降順、アルファベット順に並べ替えることができます。
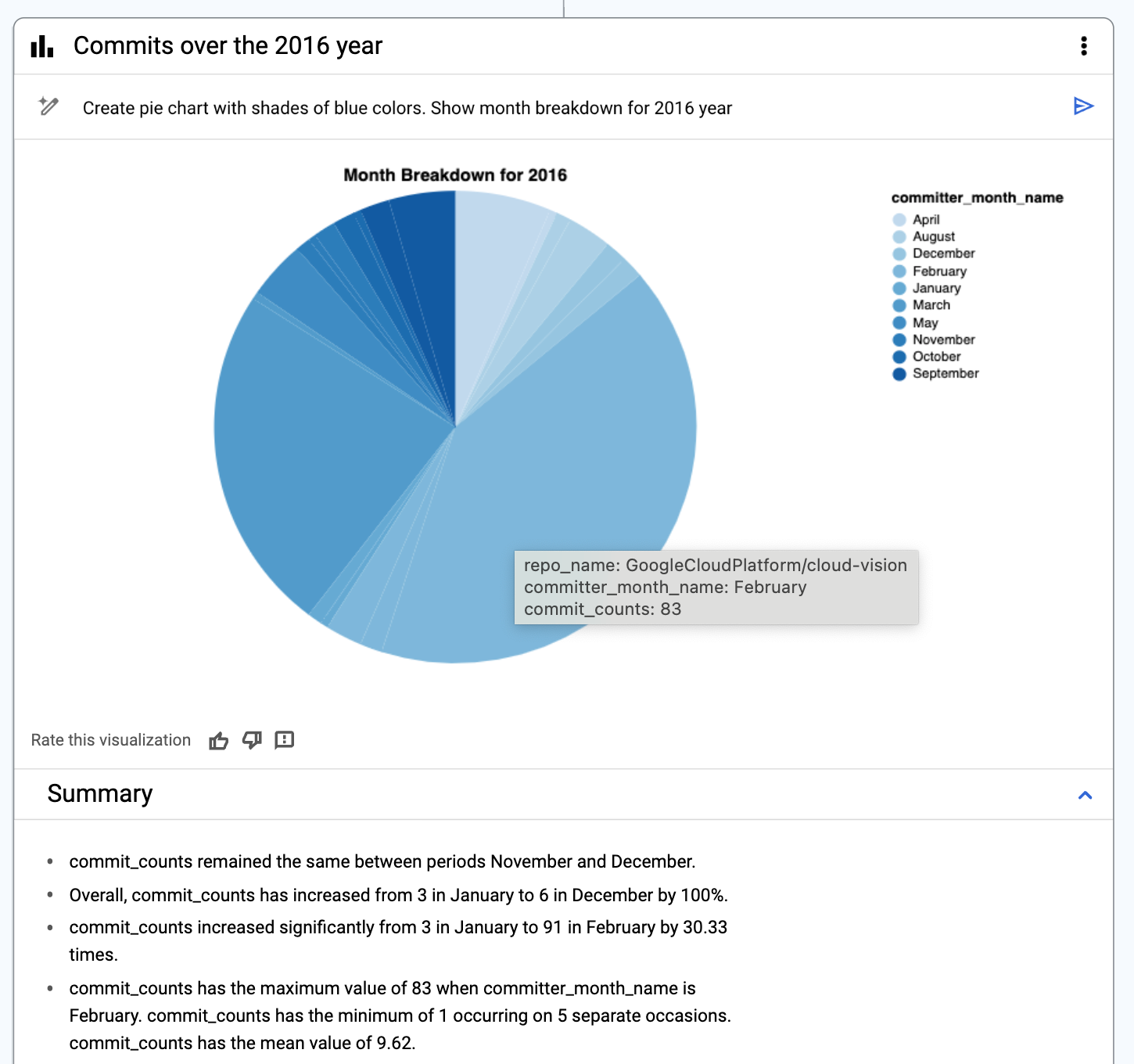
Looker Studio へのエクスポートや PNG でのダウンロードが可能なカスタムの可視化の作成
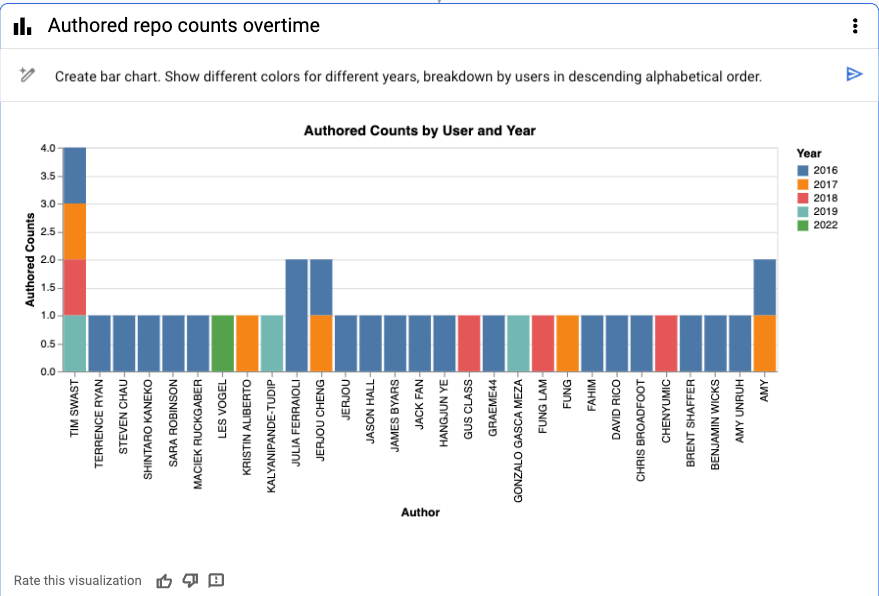
プロンプトによる逆アルファベット順での並べ替え
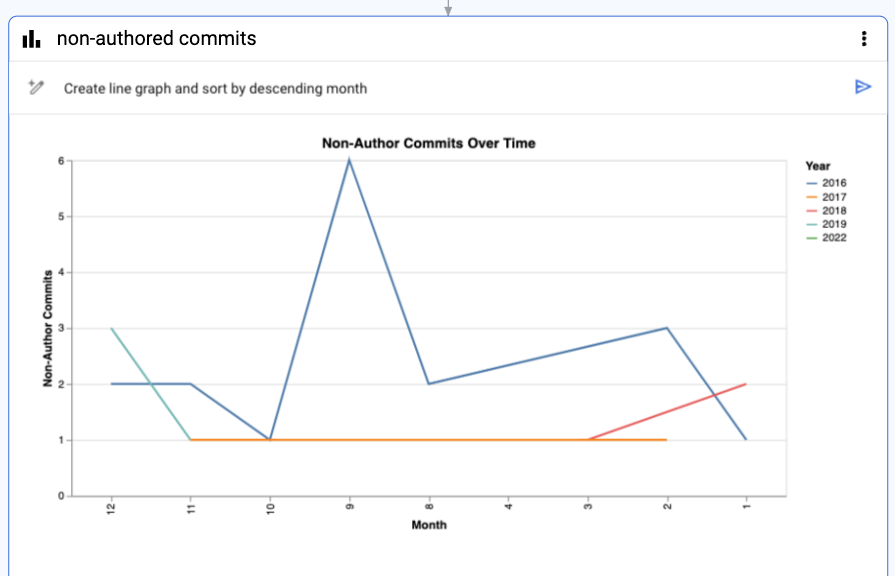
プロンプトによって月の降順で並べ替えられた可視化
最後に、データ キャンバスを使用して、グラフの結果から一見しただけではわからない解釈を導き出して要約する、可視化の洞察に富んだ概要を生成することもできます。
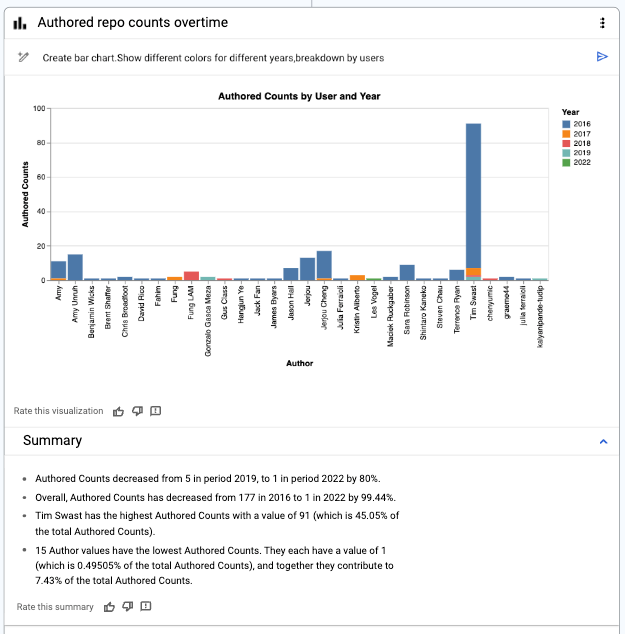
基本言語を使用し、さまざまな言い回しを試すことで簡単に生成できた詳細な可視化
完璧なプロンプトを目指すには練習が必要
データ キャンバスにおけるプロンプトの記述を習得するには練習が必要ですが、NL2SQL モデルに慣れるにつれてより直感的に作業できるようになります。データ キャンバスからできるだけ正確で有用なレスポンスを得るには、プロンプトを明確かつ具体的に記述しましょう。プロンプトを絞り込むには、完全な文章を使用し、関連するコンテキストを提供して、直接的な質問をしましょう。複数の言い回しを使用して試し、Gemini のフィードバックから学習しましょう。以上のガイドラインに沿って操作することで、Gemini in BigQuery の可能性を最大限に引き出し、BigQuery データ キャンバスにおける SQL 出力の精度と有用性を最大限に高めることができます。
BigQuery データ キャンバスにアクセスして、これらのヒントとコツを実践してください。GitHub には、データ キャンバスのプロンプトのサンプルが用意されています。また、BigQuery データ キャンバスを使用して GitHub リポジトリの公開データセットを探索する実際の例については、データ キャンバス - AI によってデータを分析情報に変換するをご覧ください。
-Google、データ分析担当カスタマー エンジニア、Christine De Sario
-Google、生成 AI ソリューション アーキテクト、Layolin Jesudhass


