BigQuery による構築: Tamr が大規模なマスターデータ管理を提供する方法およびデータ プロダクト戦略に与える効果
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
マスターデータは、主要なビジネス エンティティの全体像を示すもので、識別子と属性の一貫したセットを提供することで、組織にとって最も重要なビジネスデータにコンテキストを付与します。これは、クリーンで正確かつ厳選されたデータに全社的にアクセスできるよう保証することを意味します。つまり、利用可能な最高品質のデータにアクセスして、業務管理や重要なビジネス上の意思決定を行えるようにするのです。明確に定義されたマスターデータは、事業運営において不可欠です。
マスターデータは、組織全体で取得される他のタイプのデータに比べ、はるかに濃密で精巧なプロセスを経て用意されます。アプリケーションによって生成されるトランザクション データなどとは異なり、顧客、プロダクト、患者、サプライヤーなど、トランザクションが生じる基本的なビジネス オブジェクトを提供することで、トランザクション自体にコンテキストを付与します。
マスターデータのない場合、エンタープライズ アプリケーションが、異なるシステムに一貫性のないデータが存在し、複数のレコードの関連が不明確である可能性を抱えたまま据え置かれることになります。また、マスターデータなしでは、「どの顧客が最も収益をあげているか」、「どのサプライヤーと最も取り引きを行っているか」などといったビジネスに不可欠な分析情報を得ることが、不可能ではないにしろ、困難となる可能性があります。
マスターデータは、データを企業の資産として、またプロダクトとして扱うための重要な要素です。データ プロダクト戦略では、データがクリーンで統合された状態を維持し、適切な頻度で新しく更新されることが求められます。このような追加の準備と拡充を行わなければ、データは古く不完全なものとなり、ビジネス上のタイムリーな意思決定に必要な分析情報を提供できなくなります。ビジネス上の意思決定に、より完全で正確な分析情報を提供できるようにするには、外部データソースの完全なセットを統合することが必要です。つまり、データ プロダクト戦略に、データの準備、統合、拡充を含めなければなりません。このデータの準備、統合、拡充のためには、適切なインフラストラクチャ、ツール、プロセスが求められます。これらを用意しなければ、すでに負荷の大きいデータ管理チームにさらなる負担を強いることになります。
データ プロダクト戦略の運用を可能にする次世代のマスターデータ管理プラットフォームの採用と実装が不可欠であるのは、このような理由からです。このようなプラットフォームを導入すれば、信頼できるデータを取得し、ビジネス上の成果を向上させることが可能となります。
課題: 信頼できる唯一の情報源 - 統合された「ゴールデン」レコード
多くの企業が、データ統合の課題に対処するために、データレイク、レイクハウス、データマート、データ ウェアハウスの構築や導入に取り組んでいます。しかし、異なるソースからの複数のデータセットを組み合わせると、問題が発生する可能性が高くなります。そこで、Tamr と Google Cloud は提携し、この問題の解決に取り組んでいます。
データの重複: セマンティック エンティティや物理エンティティが同じ(顧客が複数のキーを持っている場合など)
不整合: 同じエンティティのプロパティが部分的に一致しない(同じ顧客でも電話番号や住所が異なる場合など)
分析情報の精度の低下: 重複により、主要な分析数値に偏りが生じる(顧客の総数は、重複のない場合より重複時の方が多くなる)
適時性への影響: アプリケーションの入力や分析に際し、手動作業によりデータ エンティティの一貫性と合理性を確保しようとする場合、処理に大幅な遅延が生じ、結果として意思決定にも影響が及ぶ
ソリューション
Tamr は、データ マスタリングと次世代のマスターデータ管理のリーダーであり、急速に変化する世界で企業が一歩先を行くために、クリーンで統合され、かつ精選されたデータを提供するデータ プロダクトをお届けしています。機械学習と人間参加型、ローコード / ノーコード環境、統合されたデータ拡充を組み合わせた Tamr の統合ターンキー ソリューションにより、組織は業務効率化を実現できます。その結果、手動での作業を軽減しながら、より質の高いデータを迅速に取得することが可能になります。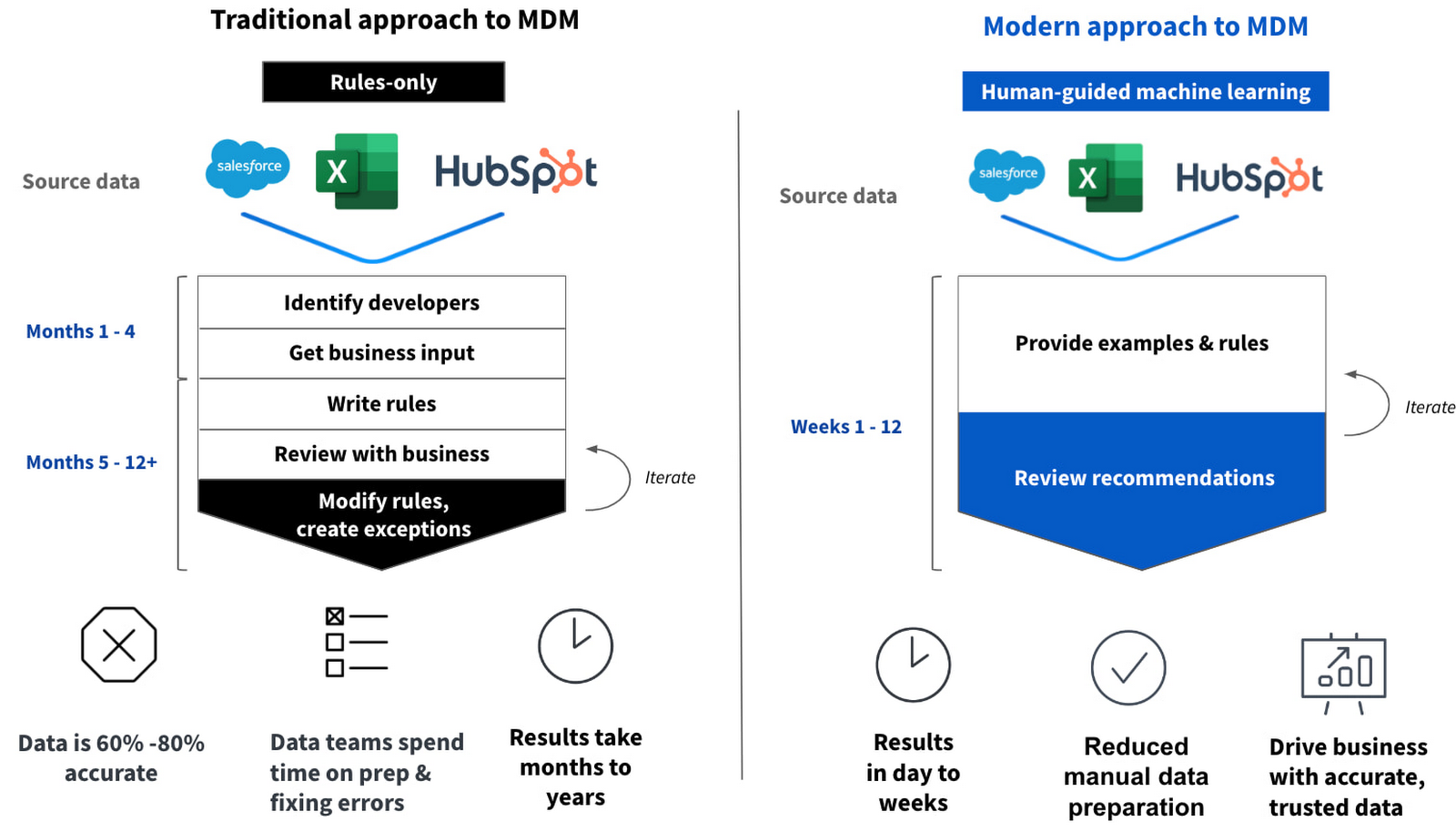
Tamr は複数のソースレコードの取得、重複の識別、データ拡充、一意の ID の割り当てを行い、分析とレビューのためにすべてのソース情報を維持しながら、統合されマスタリングされた「ゴールデン レコード」を提供します。クレンジングされたデータは、ダウンストリームの分析とアプリケーションで利用でき、より多くの情報に基づいた意思決定を可能にします。
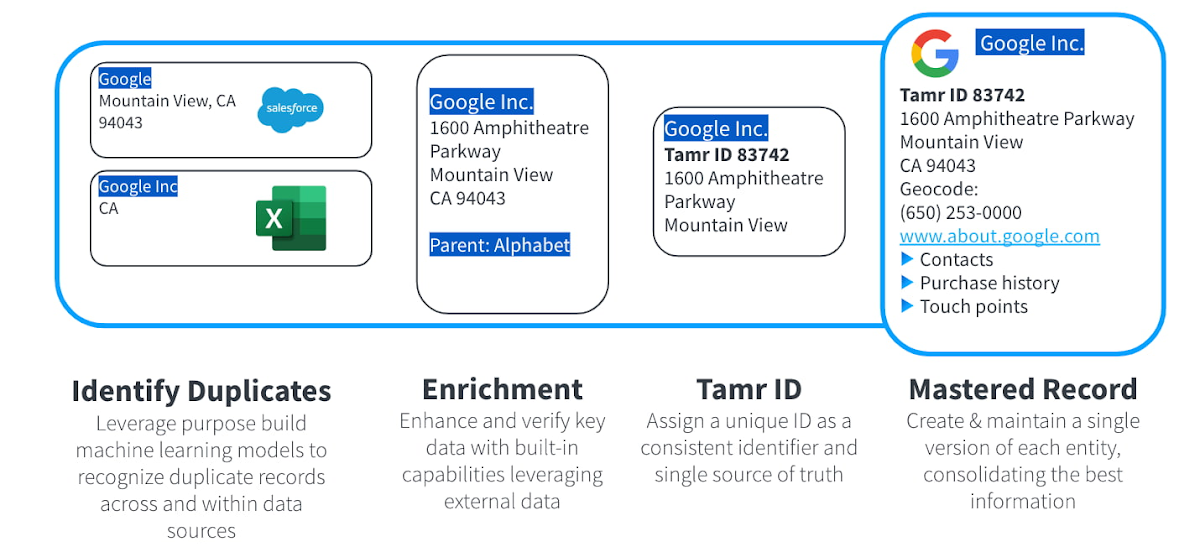
データ プロダクト戦略を成功させるには、一貫したデータのクリーニングと統合を行う必要があり、これはデータ マスタリングに最適なタスクです。データ マスタリング プラットフォームの機械学習をベースとした機能により、データの量と種類の増加に対応するだけでなく、データの拡充も行われます。また、データが常に新しく正確であることが保証されるため、ビジネスでのデータの利活用に際しても、信頼を得ることができます。
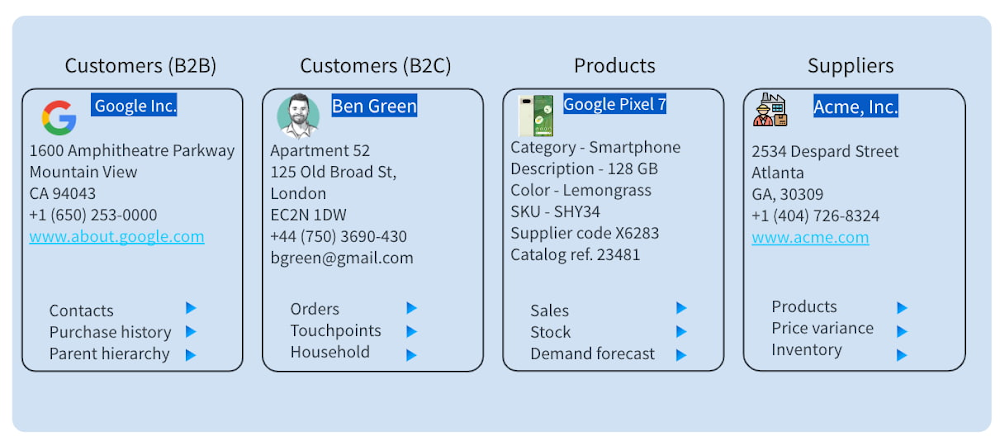
正確なキー エンティティ データを使用することで、企業はデータ分析情報の全体像を把握できます。「キー」という用語は、組織にとって最も重要なエンティティを意味します。たとえば、医療機関であれば患者や医療従事者、メーカーであればサプライヤー、金融機関であれば顧客などがこれにあたります。
以下は、Tamr でクレンジング、拡充、キュレーションを行った後のキー ビジネス エンティティの例です。
連携のメリット: Tamr が Google Cloud を活用して次世代 MDM を差別化する仕組み
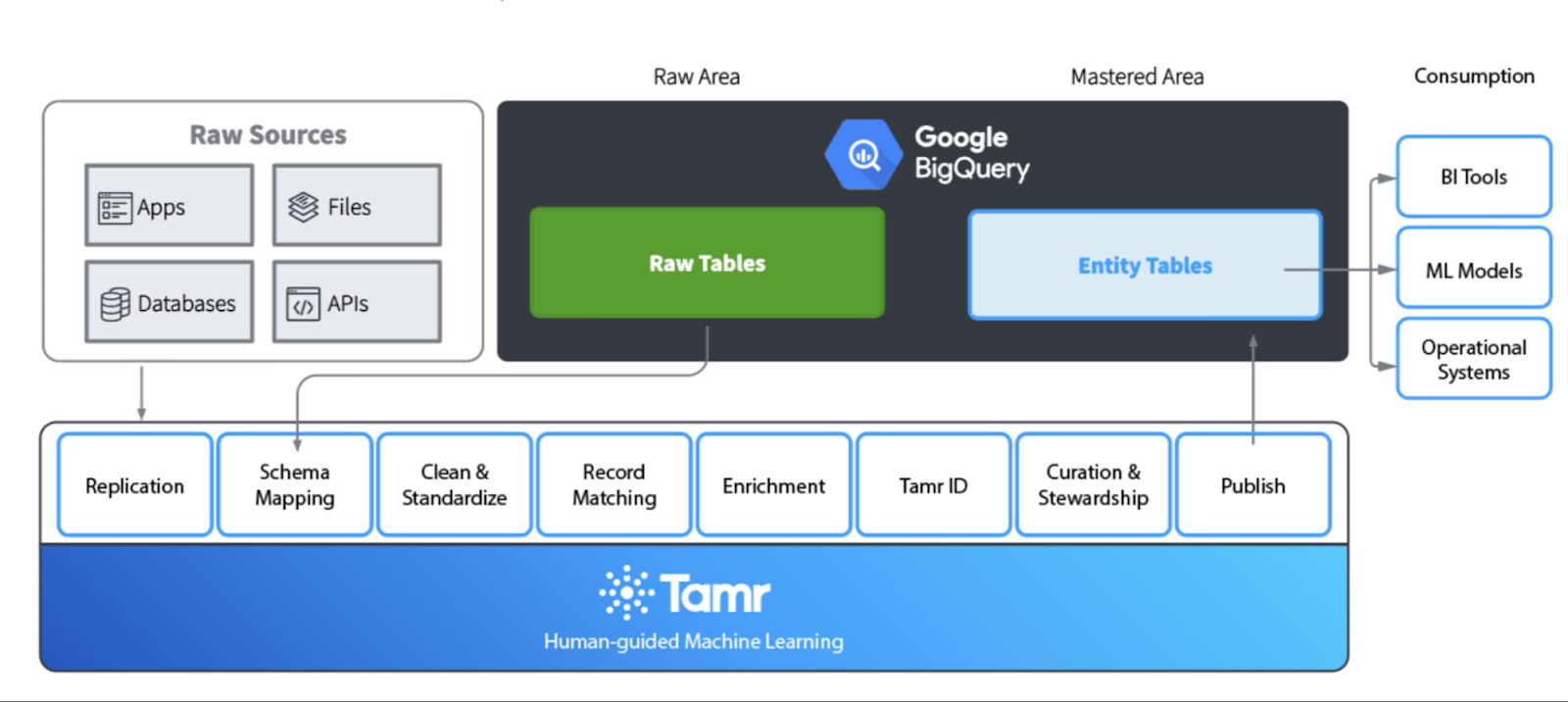
テンプレートベースの SaaS 型 MDM ソリューションである Tamr Mastering は、Cloud Dataproc、Cloud Bigtable、BigQuery などの Google Cloud Platform テクノロジー上に構築されており、お客様はコストを抑えながら優れたパフォーマンスで最新のデータ パイプラインをスケーリングできます。
コントロール プレーン(アプリケーション レイヤ)は、Google Compute Engine(GCE)上に構築されており、そのスケーラビリティを活用しています。データプレーンでの分散処理には、Google Dataproc などの相互接続された Google Cloud Platform のサービス群全体が使用されており、分散型 TensorFlow の分析能力と Hadoop のスケーリング機能の両立が可能な柔軟かつ持続可能な方法を、マネージド サービスで実現しています。また、データの移動 / ステージングには、Google Cloud Storage が使用されます。
Tamr では、データ拡充プロセスに Google Cloud Run が使用されています。その結果、Google のスケーラブルなインフラストラクチャ上にコンテナを直接デプロイできます。このアプローチにより、ステートフル クラスタの作成やインフラストラクチャ管理を必要としないサーバーレス デプロイが可能となり、コンテナのデプロイの生産性が向上します。データ拡張ストレージには Google Bigtable が利用され、Key-Value データの高スループットとスケーラビリティを実現します。Key-Value ルックアップ スキーマに分類されないデータは、バッチで取得されるか、分析目的で使用されます。Google BigQuery は、このタイプのデータに最適なストレージであり、このブログ投稿で以前に説明したデータのゴールデン コピーのストレージです。また、Tamr では BigQuery をセントラル データ ストレージ ソリューションとして選択しています。BigQuery には、ネストされたフィールドと繰り返しフィールドをネイティブにサポートし、スキーマの非正規化を促進する機能があるためです。これにより、データ ストレージを非正規化してクエリのパフォーマンスを向上させることができます。
さらに、Tamr Mastering では、アクセス制御、認証 / 認可、構成、オブザーバビリティのために Cloud IAM を利用しています。Google のフレームワーク全体にデプロイすることで、高い帯域幅によるパフォーマンスの向上、管理オーバーヘッドの低減、自動スケーリングとリソース調整などの重要なメリットが得られ、それらすべてが TCO の削減につながります。
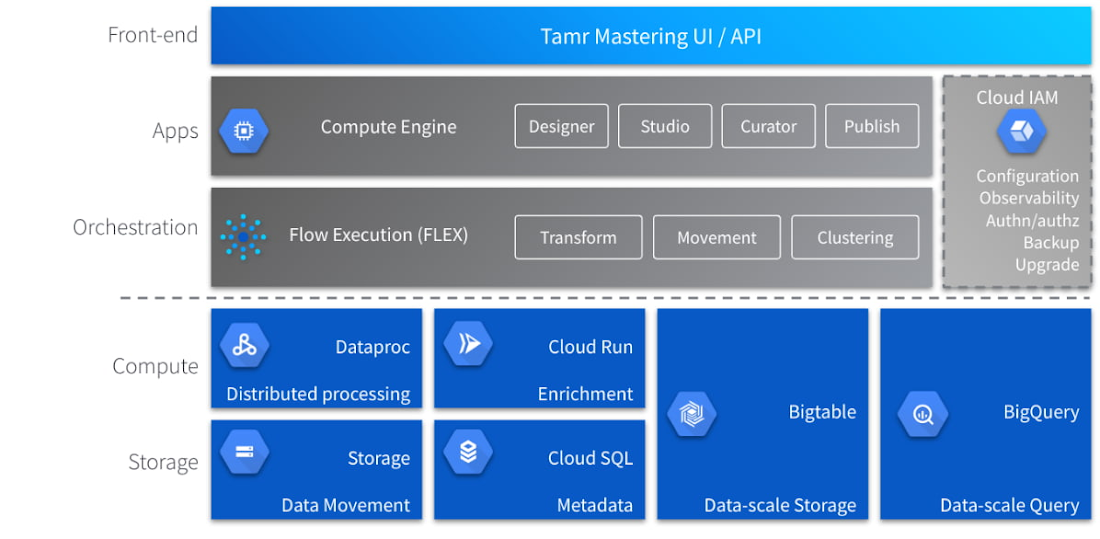
上述のアーキテクチャは、機能のさまざまなレイヤを示しています。図の上側のフロントエンドでのデプロイメントから始まり、下側のコアレイヤまでがあります。上の図に描かれている MDM アーキテクチャ全体を効率的にスケーリングするために、Tamr は Google Cloud と提携し、3 つのコア機能に注力しています。
機能 1: スケーリングと精度のために最適化された機械学習
従来、ほとんどの組織のレガシー インフラストラクチャにおいては、データの整理とマスタリングについてルールベースのアプローチが使用されてきました(if <condition> then <action>)。従来のルールベースのシステムは、人間が構築したロジックに基づいて実装されたルールに基づいてマスターレコードを生成するため、小規模な場合には効果的です。ただし、このようなルールは、変動性の高い大量のデータを接続して調整するタスクにおいては、スケーリングに失敗します。
一方、機械学習は、データが増えれば増えるほど、データセット間でレコードを照合する際の効率が向上します。実際、膨大な量のデータ(数十のシステムにまたがる 100 万件以上のレコード)ではより多くのシグナルが生成されるため、機械学習モデルでパターン、一致項目、関係を特定することができ、人間では何年もかかる作業を数日に短縮することが可能です。Google が提供する Compute Engine のコアあたりの高いパフォーマンス、高いネットワーク スループット、ストレージとコンピューティングの両方におけるプロビジョニング時間の短縮など、これらのすべてが Tamr の Google Cloud 上で最適化された機械学習アーキテクチャにおける差別化要因となっています。
機能 2: 人間によるインプットの確保
機械学習は重要ですが、人間を参加させ、フィードバックを提供できるようにすることも重要です。データの信頼性を高めるには、ビジネス ユーザーや対象分野のエキスパートを関与させることも大事です。機械がリードし、人間が機械とその結果をより良くするガイダンスとフィードバックを提供するという両方を考慮した方法が、最良の結果をもたらすデータ マスタリング アプローチなのです。人間によるインプットは、機械学習モデルを改善するだけでなく、精選されたデータを必要とするデータとビジネス成果とのつながりをより密接にしていくうえでも役立ちます。
機能 3: ワークフローに組み込まれた拡充
プロセスの最終段階として、内部データアセットと外部データを統合し、その価値を高めるのがデータ拡充です。関連する情報や不足している情報を追加し、データをより完全なものにすることで、より使いやすいものにします。データを拡充することでその品質が向上し、組織にとってより価値のある資産になります。データ拡充とデータ マスタリングを組み合わせることで、データソースが自動的にクリーニングされるだけでなく、貴重なビジネス情報が拡充され、内部データと外部データの統合や結合のための非常に時間のかかる手動作業を回避できます。
以下は、これら 3 つのコア機能がどのように Tamr MDM アーキテクチャに組み込まれているかの例です。
P360 でコネクテッド カスタマー エクスペリエンスのデータ基盤を構築
ある大手製薬会社が、顧客である医療関係者により良いサービスを提供するためのデジタル トランスフォーメーション プロジェクトの支援を P360 に依頼した際、P360 は最新のマスターデータ管理(MDM)ソリューションで強固なデータ基盤を構築することが最初のステップであると認識しました。
「お客様の課題の一つは、データ インフラストラクチャの再構築の核となるマスターデータ管理でした。すべてはデータを中心に回っているため、しっかりとしたデータ インフラストラクチャを持たないことには始まりません。それがなくては競争を勝ち抜くことはできず、顧客がプロダクトをどのように使用しているかを把握することもできません」と、製薬業界向けテクノロジー ソリューション プロバイダである P360 の CEO、Anupam Nandwana 氏は述べています。
その信頼できるデータの基盤を構築するために、P360 は Tamr Mastering に目を向けました。この製薬会社は、Tamr Mastering を使用することで、何百万もの医療従事者に関する内部データと外部データを迅速に統合し、新しい CRM システムを含むダウンストリーム アプリケーションを強化するゴールデン レコードを作成しています。他の BtoB 企業と同様に、P360 の顧客もさまざまなソースからの多様で広範なデータを保有しています。医師の名前や住所などの社内データから、処方履歴や請求情報などの社外データまで、このトップ製薬会社が顧客の全体像を把握するためにマスタリングすべきデータソースは 150 にも及びます。これには、100 万件の医療従事者の記録(および 200 万件の医療従事者の住所)と 10 万件以上の医療機関の記録が含まれます。
「最新のデータ プラットフォームでは、クラウドが唯一の答えです。必要なスケール、柔軟性、スピードを実現するためには、他のインフラストラクチャの活用は現実的ではありません。クラウドは、より迅速に物事を行うチャンスを与えてくれるのです。このプロジェクトを短期間で完了することが成功の重要な基準であり、それはクラウドでしか実現できませんでした。利用を決めるのは簡単でした」と Nandwana 氏は述べています。
P360 は Tamr Mastering を使用して製薬会社を支援し、数週間で数百万の医療従事者の記録をマスタリングして、一貫した識別子と信頼できる唯一の情報源として一意の顧客 ID を含むゴールデン レコードを作成しました。
まとめ
Google のデータクラウドは、Tamr の MDM ソリューションのようなデータドリブン アプリケーションを Google Cloud 上で構築するための完全なプラットフォームを提供します。簡素化されたデータの取り込み、処理、保存、高度な分析、AI、ML、データ共有機能にいたるまで、オープンで安全かつ持続可能な Google Cloud Platform と統合されています。多様なパートナー エコシステム、オープンソース ツール、API により、Google Cloud はテクノロジー企業がプロダクトを構築し、次世代の顧客にサービスを提供するために必要なポータビリティと差別化要因を実現するプラットフォームを提供できます。
Google Cloud 上の Tamr の詳細について、こちらをご確認ください。
Google Cloud の Built with BigQuery イニシアチブの詳細については、こちらをご覧ください。
このブログ投稿を共同で執筆してくれた Google Cloud のチームメンバーである Christian Williams (Cloud パートナー エンジニアリング担当プリンシパル アーキテクト)に感謝します
- Tamr、最高プロダクト責任者 Anthony Deighton 氏- Cloud パートナー エンジニアリング担当ディレクター Ali Arsanjani 博士

