Built with BigQuery: 大規模に不正行為検出ワークフローのバックテストを行う Sift
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
Sift はデジタル分野での信頼性と安全性に関する最先端の取り組みを進める企業です。同社は、ML を使用した不正行為検出サービスを提供することにより、デジタル テクノロジーを活用して変革を推進する Fortune 500 企業がリスクを負うことなく新たな収益を開拓できるようサポートしています。Sift は、業界をリードする ML ベースのテクノロジー、高い専門性、そして毎月 700 億件を超えるイベントが発生する圧倒的なグローバル データ ネットワークを通して、さまざまなカテゴリの不正行為の動的な防止を実現しています。
お客様は Sift のプラットフォームを使用して、直感的な UI でワークフローを構成し、不正行為検出を自動化することができます。これにより、不審な注文のブロック、取引への追加の手順の適用(MFA の要求など)、正常に行われた取引の処理といった非常に重要度の高いビジネス アクションを組み込むことができます。お客様は、Sift UI 内でワークフローを使用してビジネス ロジックを構築および管理し、意思決定を自動化して、手作業によるレビューを継続的に効率化できます。Sift のお客様は、このようなワークフローを通して 1 日あたり数千万件ものイベントを処理しています。
以下に Sift UI の例を示します。ここでは、ワークフローを使用することにより、お客様が新規受注の作成などのユーザー イベントに対してリスクに応じた意思決定を行う方法を示しています。以下の例では、ワークフローのロジックによって受信リクエストの不正決済スコアが評価され、重大度レベルに応じてリダイレクトが行われます。たとえばルート 3(画像下部)では、スコアが 50 よりも大きい場合に、メールによる 2 要素認証がトリガーされ、受信リクエストが検証されます。スコアが 90 よりも大きければ、不正リクエストのラベルが付けられて、ブロックされます。
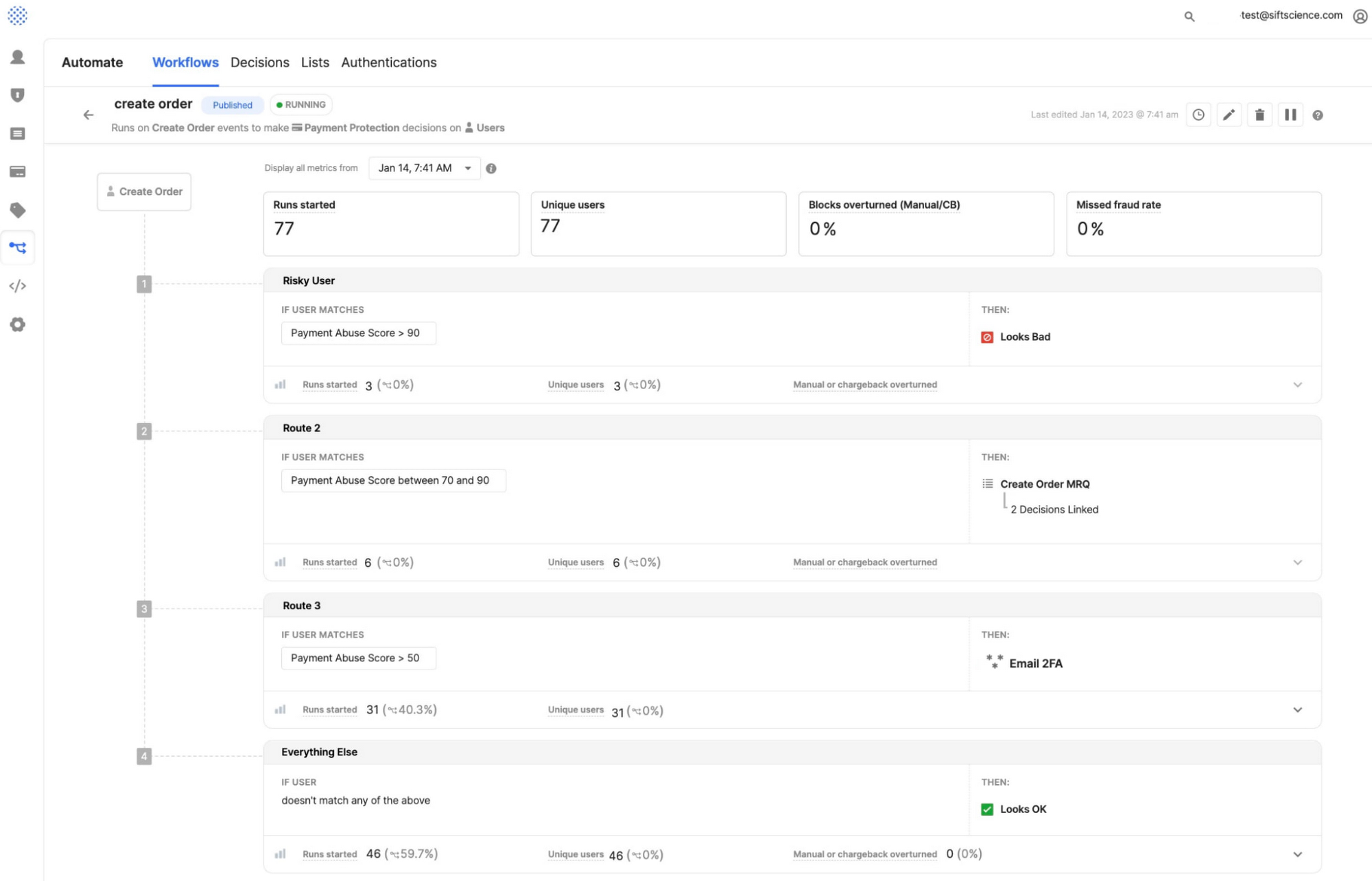
既存のワークフローを変更する場合、その変更がコアとなる KPI(ユーザーの侮辱率、不正行為の費用、1 か月のアクティブ ユーザー、顧客のライフタイム バリューなど)にプラスの効果をもたらすようにする必要があります。マイナスの効果をもたらすワークフロー ルートを本番稼働させてしまうと、投資収益率が低下し、正当なリクエストや不正行為ではない顧客を退けてしまうことになりかねません。そのような事態は何としても避ける必要があります。
BigQuery によるワークフローのバックテスト
BigQuery を活用したワークフローのバックテスト アーキテクチャにより、以下を行うことができるため、強固でスケーラブルな方法でこの機能をお客様に提供します。
(上図に示すような)実行中のワークフロー内のルートの変更をテストできます。
Sift UI を通して、コードを記述することなく「What-If」分析をセルフサービスで実行できます。
不正行為分析により、ルートを本番環境に公開する前に、ルートについてワークフローのパフォーマンスを測定できます。
以下に、ワークフローのリクエストを発行した場合に、Google Cloud のフルマネージドでサーバーレスの各種構成要素が利用される様子を表した概要フロー図を示します。
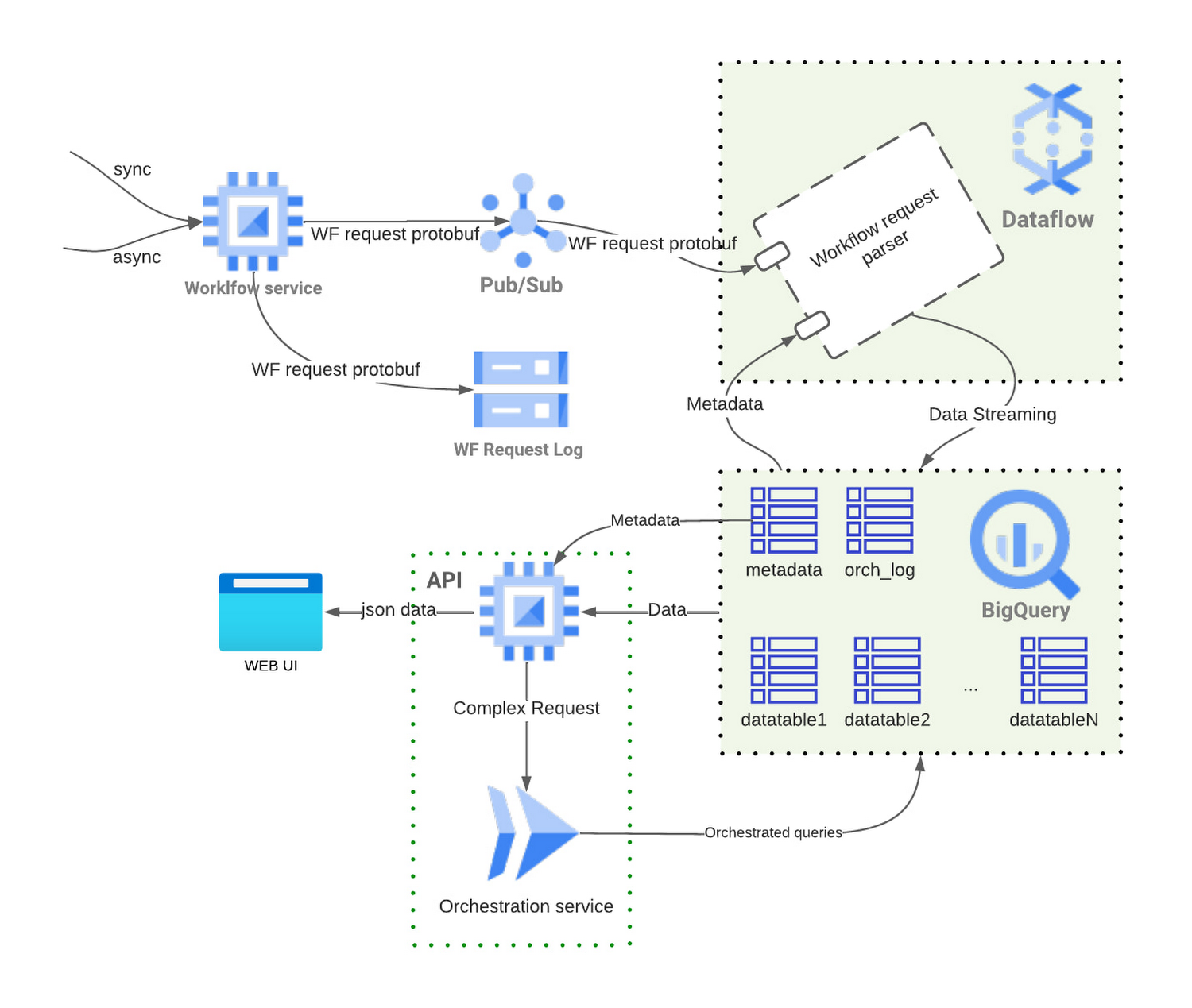
ワークフロー サービスがリクエストを受信すると、ワークフロー リクエスト全体を含むメッセージが Cloud Pub/Sub トピックに push されます。Dataflow ジョブがメッセージを受信して、パーサー(ワークフロー リクエスト パーサー)を通してメッセージを処理し、メッセージからすべての利用可能なフィールドを抽出します。この処理により、複雑なワークフロー リクエストを、後で使いやすいフラット化されたスプレッドシートのような構造へと変換できます。その後、Dataflow ジョブは(Storage Write API を介して)スキーマに依存しない設計に沿って BigQuery にレコードを作成します。
バックテスト フローのオーケストレーション
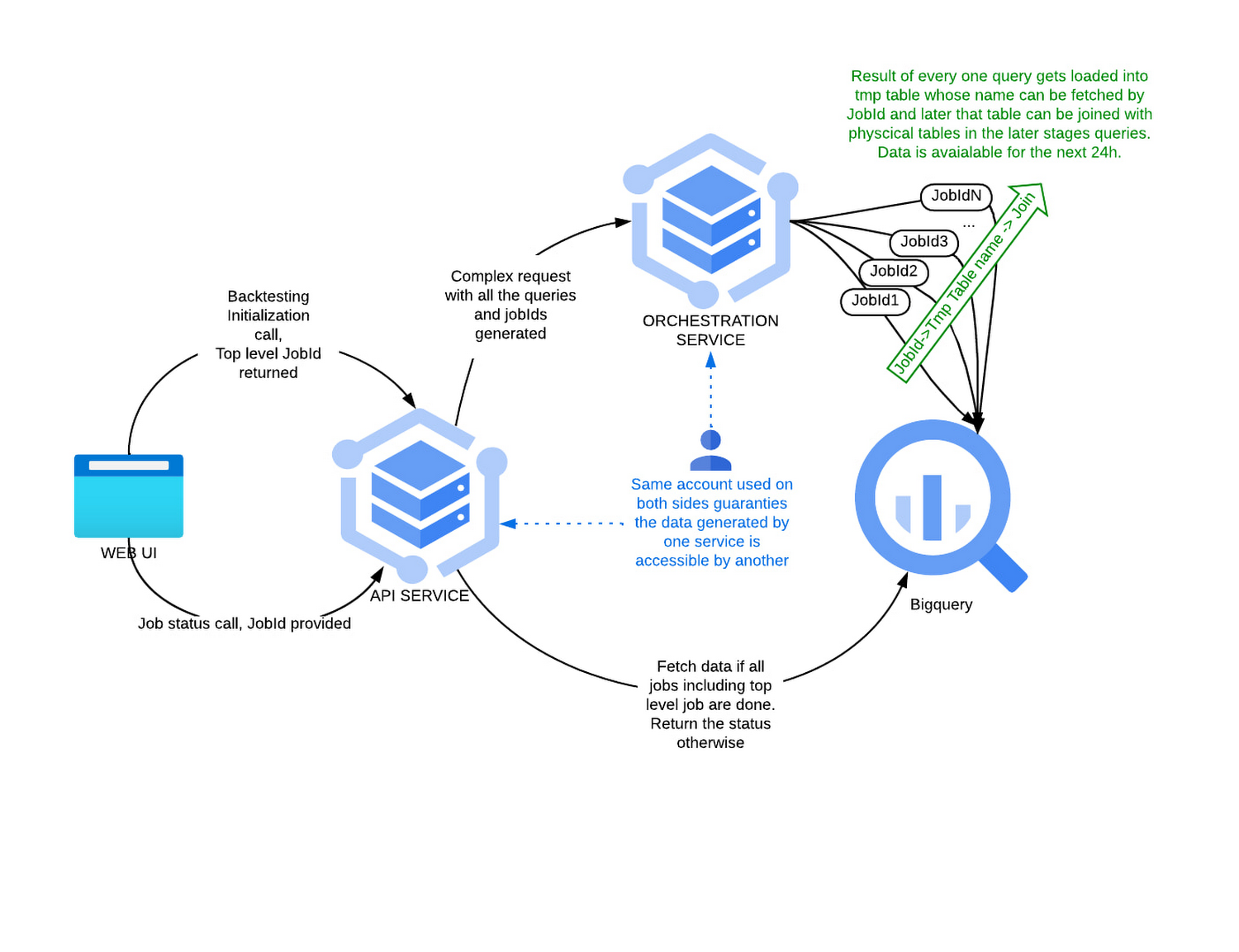
概念的には、バックテストは動的に生成された SQL クエリとして実装されます。1 回のバックテスト呼び出しを処理するためには、3 つ以上のクエリを実行する必要があります。これらのクエリは相互に依存関係を持ち、論理的な作業単位として厳密に定義された順序で処理される必要があります。バックテストの非同期 API 呼び出しは、Sift コンソールを利用して実行されます。オーケストレーション サービスは、Spring Cloud を基盤とし、JSON 形式のリクエストを受け付けるエンドポイントを公開する、シンプルなウェブ アプリケーションです。各リクエストには、すべてのバックテストのクエリ、関連するすべてのクエリ パラメータ、生成済みのジョブ ID が含まれています。このサービスによりリクエストが解析され、BigQuery に対してすべてのクエリが正しい順序で実行されます。ステップが実行されるたびに、ステータス レコードがログテーブルに作成されます。API はこのステータス レコードに対してクエリを実行し、データの準備が整っているか状況を確認します。以下の図に、このプロセスを示します。
BigQuery のスケーラビリティと、スキーマに依存しない設計への道筋
すべてのワークフロー リクエストには、お客様がバックテスト リクエストで使用すると決めた数万にもおよぶ列やフィールドが含まれることがあります。テーブルサイズはテラバイト単位となり、各テーブルに数十億件ものレコードが含まれることもあります。さらに、新たなワークフローをテストする前に、属性が追加または削除されることもしばしばです。そのため、以下のような特長を持つ、スキーマに依存しない設計が必要となります。
テーブルの構造を変更することなく、新たな特徴量を導入できる。
スキーマではなく、メタデータを変更して宣言的に変更を導入できる。
詳細なカスタマイズ機能とスケーラビリティによって、多くのカスタム フィールドを使用するお客様が 1 万個以上におよぶ同じデータ型の特徴量を試すことができる。

上図のスキーマのように、データはワークフロー固有のレイアウトではなく、データ型ごとに用意されたテーブルへとグループ化されます。このデータは、連想メタデータ テーブルを利用して結合されます。連想メタデータ テーブルは、従来のデータ ウェアハウジング設計で考えると、複数のデータ型のテーブル(ディメンション テーブル)にリンクするファクト テーブルとみなすことができます。
データ量が多く、スキーマが頻繁に変更されるため、インデックス作成は手間がかかりすぎ、実用的ではありません。Sift は、初期ワークフロー アーキテクチャを評価する際に、大規模な集計処理が発生する、ネストの深いクエリを使用して包括的なテストを行い、パフォーマンスと柔軟性に優れた最適なスキーマ設計を見極めました。その結果、メモリへのデータの読み込みに必要な IO 操作や、複雑な動的クエリを通したさらなる操作を最小限に抑えることができるため、データに列指向ストレージ形式を使用するのが最適であることがわかりました。最終的に設計を決める前に、Sift では大掛かりなベンチマークを実施しました。具体的には、論理的に類似のクエリを複数のデータ ウェアハウス ソリューションが管理する同等量のデータに対して実行し、BQ を基盤としたソリューションのベンチマークを実施しました。その結果、BQ の Dremel エンジンとクラスタレベルのファイル システム(Colossus)を使用すると、Sift のユースケースで最も高いパフォーマンスとスケーラビリティを備えたアーキテクチャを構築できることがわかりました。
BigQuery でのベンチマーク
負荷テストと、本番環境レベルのデータ量とスループットを持つ一連の「本番環境に即した」ユースケースを使用した動作テストを何回か繰り返したところ、単一のバックテスト リクエストの平均応答時間は約 60 秒となり、満足する結果を得ることができました。複雑なリクエストでの最大応答時間は 2 分弱となりました。負荷テストは、十分なコンピューティング リソースを確保しつつ、予期されるワークロードに対応するために必要な BQ スロット数の予測にも役立ちました。以下に、初期の JMeter テストレポートの例を示します(構成: ランダムに選択されたクライアント ID / ワークフロー構成 ID / ルート ID)。
バックテスト期間: 45 日
BQ コンピューティング リソース: 3,000 BQ スロット
目標計画ワークロード: 1 分あたり 30 リクエスト
テスト時間: 30 分

さらに、「BigQuery スロット見積もりツール」機能も試しました。このツールを使うと、以下を行うことができます。
ワークフロー固有のプロジェクトでスロットのキャパシティと使用率のデータを可視化する
大半のスロットが使用されている場合に使用率がピークになった期間を特定する
ジョブ レイテンシのパーセンタイル(P90、P95)の調査により、ワークフロー バックテスト シーケンスに関連するクエリ パフォーマンスを把握する
スロットの増減がパフォーマンスに与える影響を時系列で確認する What-if モデリングを利用する
過去の使用パターンに基づいて、自動生成された費用のレコメンデーションを評価する
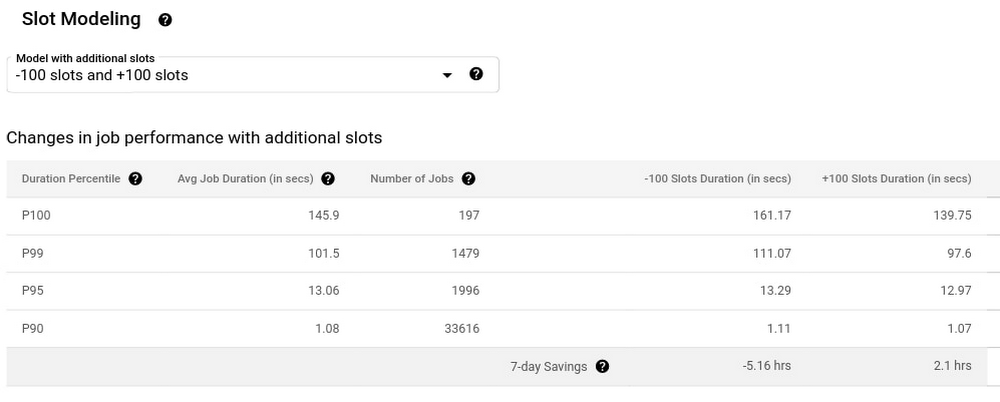
以下に、BQ のスロット見積もりツールを利用した例を示します。ここでは、現在のキャパシティからスロット数を 100 減らした場合と 100 増やした場合を比較し、異なるキャパシティ レベルでパフォーマンスがどのように変化するかのモデルを作成しました。
お客様の成功事例
暗号通貨やフィンテック分野の企業から、オンデマンドでアプリやマーケットプレイスを提供する企業まで、さまざまな企業が Sift を利用して不正行為を減らし、成長を実現しています。Sift を利用することで、スムーズな支払いを実現し、ユーザー獲得に注力できるようになったお客様の事例を以下に一部ご紹介します。
まとめ
Google のデータクラウドは、Sift が開発したワークフロー バックテスト ソリューションのような、データドリブン アプリケーションを構築するために必要なあらゆる機能を備えたプラットフォームを提供します。簡素化されたデータの取り込み、処理、保存、高度な分析、AI、ML、データ共有機能にいたるまで、オープンで安全かつ持続可能な Google Cloud Platform と統合されています。テクノロジー企業は、多様なパートナー エコシステムと、オープンソース ツール、API を備えた Google Cloud により、これまでには見られない先進的なニーズを抱えるお客様にサービスを提供するために必要なポータビリティを手にし、他社との差別化を図ることができます。
Google Cloud を基盤とした Sift の詳細をご覧ください。
Google Cloud の Built with BigQuery イニシアチブについての詳細をご覧ください。
このブログ投稿を共同で執筆してくれた Sift と Google Cloud のチームメンバーに感謝します(Sift のシニア スタッフ ソフトウェア エンジニア Pramod Jain 氏、Sift のスタッフ ソフトウェア エンジニア Eduard Chumak 氏、Cloud パートナー エンジニアリング担当プリンシパル アーキテクト Christian Williams、Google Cloud の Cloud カスタマー エンジニア Raj Goodrich)。
- Sift、CTO Neeraj Gupta 氏
- Google、クラウド パートナー エンジニアリング担当ディレクター Ali Arsanjani 博士



