自動データ品質によって信頼性の高いインサイトを提供
Google Cloud Japan Team
※この投稿は米国時間 2023 年 2 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、Dataplex の新機能である自動データ品質(AutoDQ)および自動データ プロファイリングの公開プレビュー版の提供が始まりました。Dataplex は、分散データの大規模な管理、モニタリング、統制を可能にするインテリジェントなデータ ファブリックです。AutoDQ は、推奨ルールの自動作成、組み込みのレポート、サーバーレス実行などの機能を備えており、高品質データの作成に役立ちます。データ プロファイリングは、データの一般的な統計特性を識別することで、データに関するより詳細なインサイトを提供します。
信頼性および整合性の高いデータは、企業のイノベーションや、ビジネス上の重要な意思決定、カスタマー エクスペリエンスの差別化を促進し、貴重な機会をもたらします。反対に、低品質なデータは、非効率なプロセスや経済的損失につながりかねません。データの量が比較的少なく、データ利用者も限られていた時代は、データ品質の管理はもっと簡単でした。データ利用者たちは難なく協力してルールを定義し、各々の分析でそのルールを用いていたものです。しかし現在では、データの量や種類が増えるとともに、データ利用者や使用方法も多種にわたって増加し、以前のような手動の方法で対処するのは困難になっています。さらに、組織内に複数のデータ品質ソリューションが混在し、データ品質の指標を統一するのが難しいという問題もあります。多くの場合、その結果として組織内に不整合や混乱がもたらされています。
Dataplex の AutoDQ およびデータ プロファイリングは、次世代に対応したデータ プロファイリングおよびデータ品質ソリューションであり、ルールの自動作成や高品質データの大規模導入を特長としています。プロファイリング機能は、データの検索性や監査可能性の向上にも役立ちます。
自動データ品質およびデータ プロファイリング機能には、以下のような利点があります。
インテリジェントな機能、統合されたエクスペリエンス。ルールの推奨事項の提供、直感的なルール作成エクスペリエンス、設定なしで実行可能といった特長があり、すぐに使い方を習得できます。また、レポート機能が組み込まれているので、レポートを社内で標準化できます。
データのさまざまなペルソナに対して、サイロを回避しながら拡張性を提供。データのさまざまなペルソナのニーズに合わせて拡張可能です。データ プロデューサーが品質の所有者となって公開を担当する一方で、データ利用者がビジネスニーズに応じてレポートを拡張できます。
大規模な自動化。データに応じて透過的にスケールします。さらに、Dataplex の属性ストア メカニズムを活用した、大規模な定義やモニタリングが可能になります。
これらのプレビュー機能は、データ品質が日常的なデータ検索および分析の一部となる将来に向けた基盤となります。
「お客様の信頼を維持できるような意思決定を行うために、信頼性の高いデータは非常に重要です。Dataplex の次世代のデータ品質とプロファイリングの機能によって、自動化やインテリジェンスを大規模に利用できるようになり、既存プロセスの簡易化、手作業の軽減につながりました。また、組み込みのレポートとアラート機能は、データ品質の標準化に役立っています。」 — Deutsche Bank、CTO / アーキテクチャ担当責任者 / CDO Jyoti Chawla 氏
「当社では、エネルギーのデータを使用して革新的なモデルを構築し、電力の予測や資源の計画、取引に関する推奨事項の作成に役立てています。データのトレーニングおよび予測を検証するために、Dataplex の自動データ品質機能の評価に日々取り組んでいますが、わかりやすく直感的に操作できることや、インテリジェントな推奨事項に満足しています。」 — Casa dos Ventos、分析およびイノベーション担当責任者 João Caldas 氏
柔軟なデータモデル
Dataplex の新機能は、さまざまなペルソナや導入形態に対応可能なデータモデルを提供しています。これらの新機能を利用するには、テーブルに対して 1 つまたは複数の「データスキャン」を作成する必要があります。
データスキャンには以下のような特徴があります。
「データ プロファイリング」または「データ品質」のいずれかのタイプである
完全にサーバーレスである
組み込みのサーバーレス スケジューラによってトリガーするか、外部のトリガーによってオンデマンドでトリガーする
データの増分(新しいデータ)か、データ全体に対して実行する
データ プロデューサーが、結果をデータカタログに公開するように構成することができる(近日提供予定)
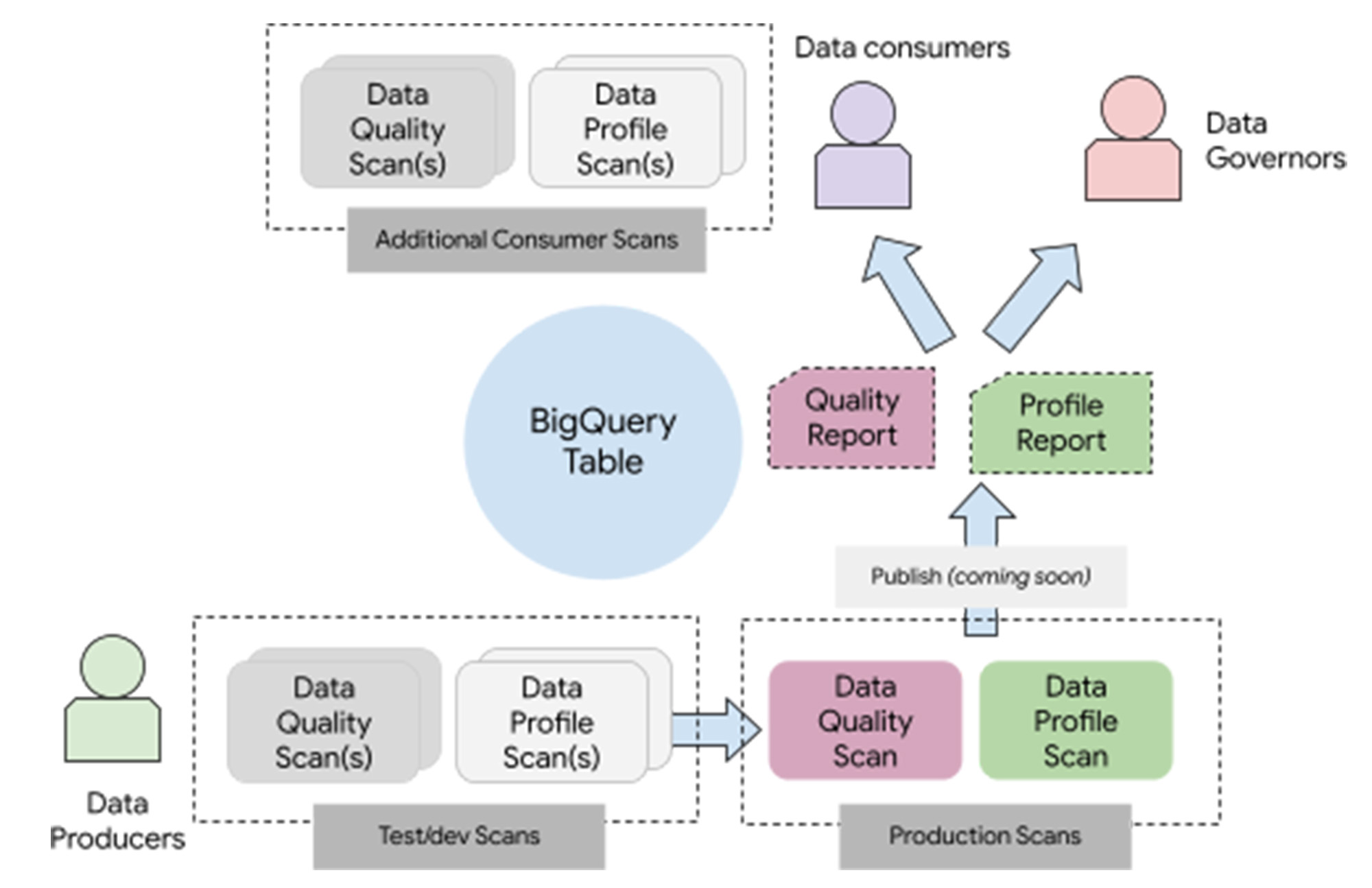
このモデルでは、データ プロデューサーがデータスキャンを作成、テストした後、結果を本番環境に公開しています。データ利用者は、公開された結果を使用できるほか、必要に応じてデータスキャンを追加することもできます。
この基本モデルにインテリジェンスが加えられ、直感的で機能豊富な UI が提供されているので、簡単に使用を開始できます。
これ以降は、BigQuery 一般公開データセットのサンプル テーブル - chicago- taxi-trips(データ提供元)を使って詳しく説明します。具体的には、新機能のうち、定義、実行、モニタリング、トラブルシューティングの各機能について見ていきます。
数回クリックするだけでデータ プロファイルを作成
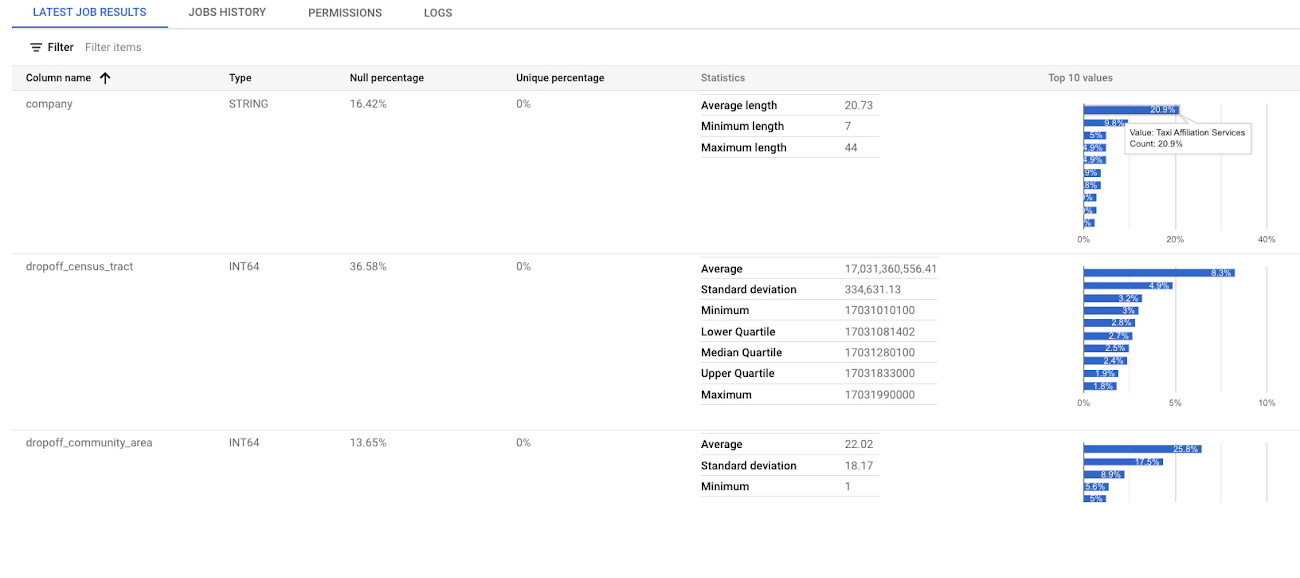
Dataplex でこのテーブルのデータ プロファイル スキャンを作成する作業は、数回クリックするだけで完了します。結果には、データの各列の統計情報およびグラフが表示されます。以下の図には、タクシーデータの各列の Null の割合、一意の値の割合、統計情報のほか、上位 10 件の値が示されています。
データ品質ルールの推奨事項を取得
データ品質スキャンの作成では、推奨ルールとともに、ルールの作成に便利な UI が提供されます。また、事前定義されているルールタイプを使用したり、独自の SQL コードを使用して、新しいルールを作成することもできます。
推奨事項の取得元とするプロファイル スキャンを選択できます。
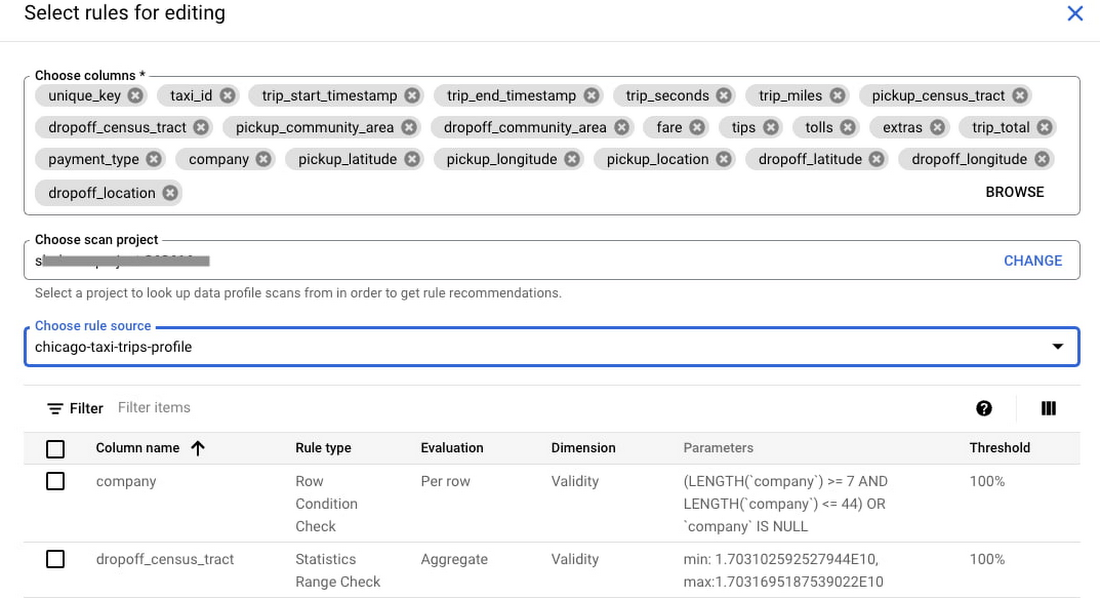
なお、各ルールはデータ品質のディメンションと関連付けられており、合格ライン(しきい値)が設けられています。
以下に、payment_type が列で検出されたいくつかの値の 1 つであると認識している推奨ルールを示します。

データコピーなしで実行
データ品質のチェックは、BigQuery 内部リソースを使って、パフォーマンスに優れた方法で実行されます。クエリの実行時にデータのコピーは行われません。
Dataplex でレポートを表示
Dataplex でのデータ品質チェックは、スケジュールを設定するか、外部のトリガーによって実行できます。どちらの場合も、結果は Dataplex 内でデータ品質レポートとして表示されます。
直近の 7 回の実行結果を示すスコアカードが表示されます。
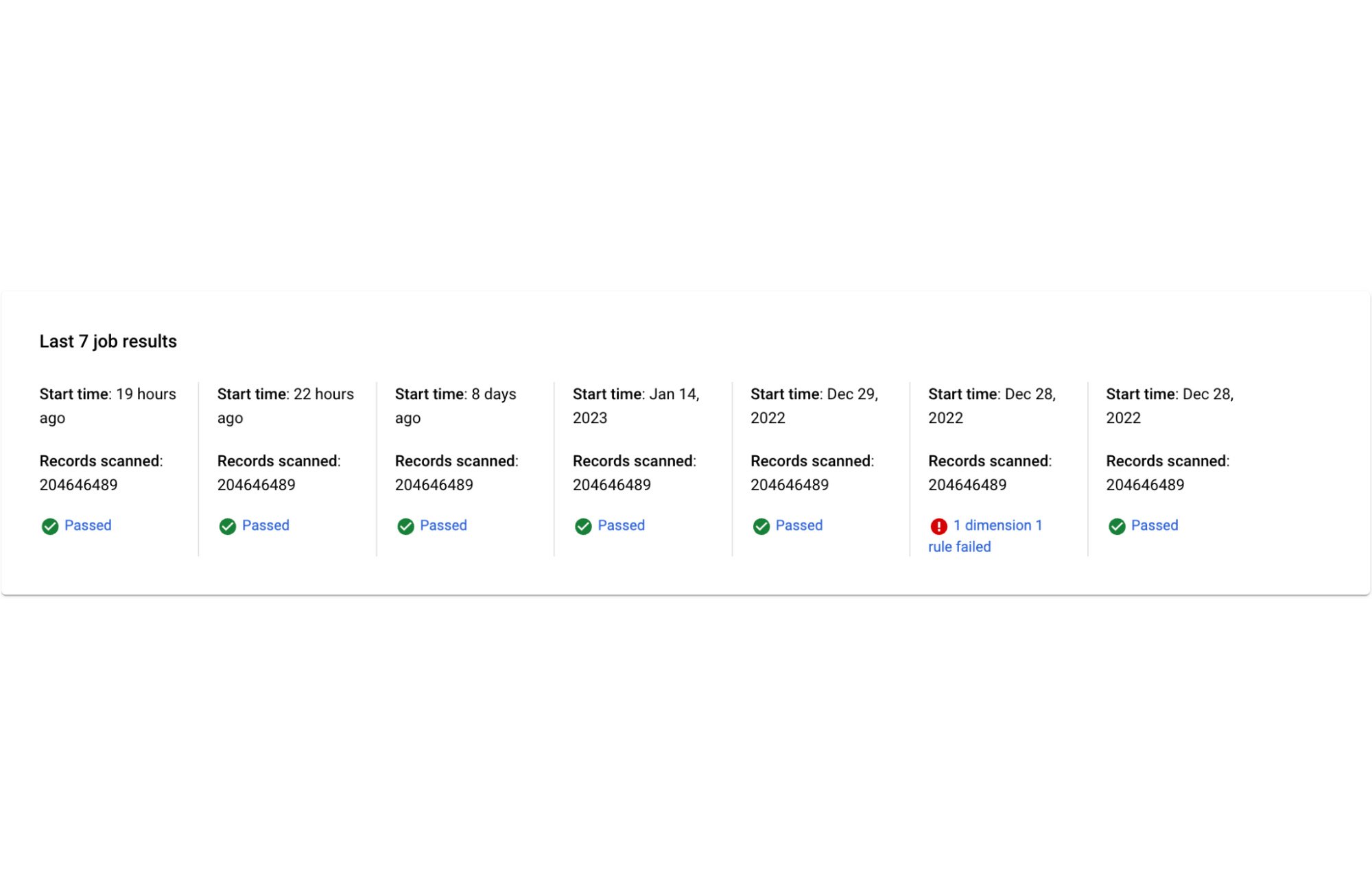
過去の実行結果の詳細を表示することもできます。なお、スキャンを実行するたびに、その実行で使用されたルールが保持されます。
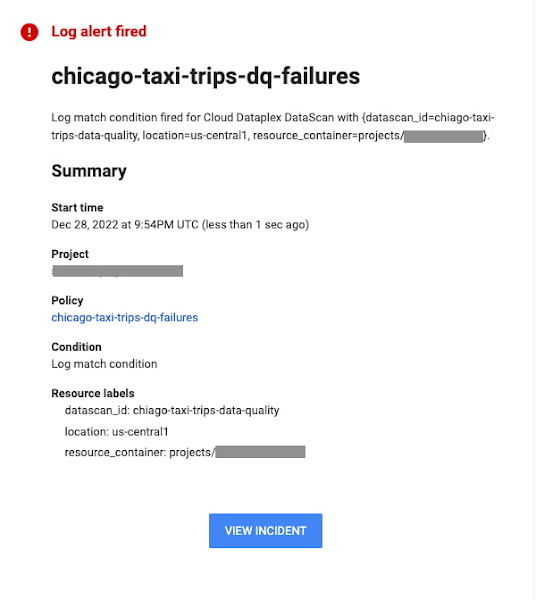
Google Cloud Logging でアラートを設定
データ品質スキャンを実行すると、Google Cloud Logging にログエントリが作成されます。このエントリに基づき、特定のスキャンやディメンションでエラーが発生したときにアラートを送信するよう設定することができます。メール通知アラートの例を以下に示します。
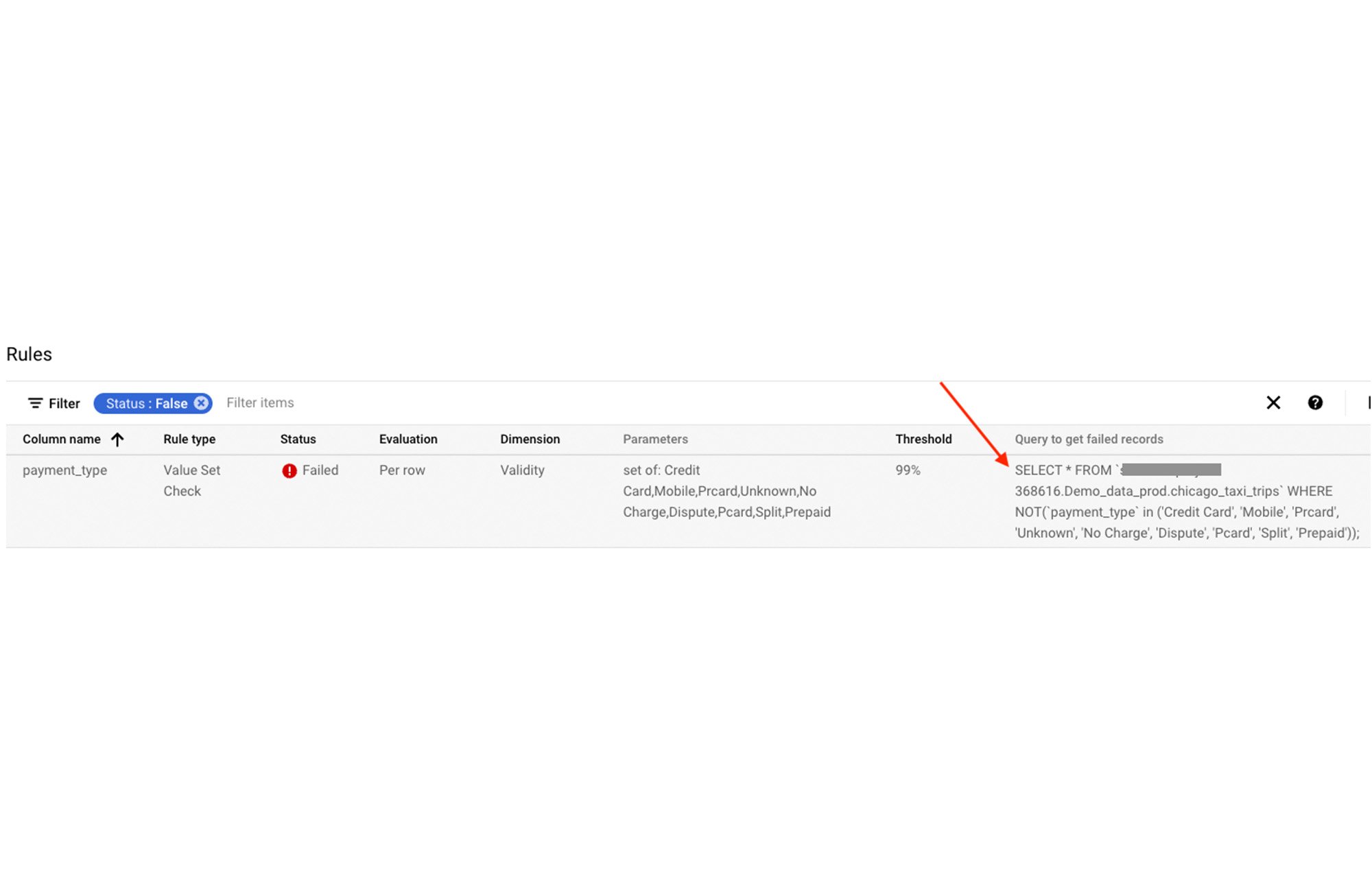
データ品質に関する問題のトラブルシューティング
データ品質ルールの違反が発生したときは、違反の原因となったレコードを生成できるクエリにより、トラブルシューティングを行えます。
詳しくは、以下のリンク先をご覧ください。
- Google Cloud、プロダクト マネージャー Sandeep Karmarkar

