オンプレミスの Hadoop データを使用してデータレイク処理を Dataproc にバーストする
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
多数の会社が、自社のオンプレミス環境にある Hadoop Distributed File System(HDFS)クラスタにデータを保存しています。データの保存量が増加し、Apache Spark、Presto、Apache Hive といった分析フレームワークから流入するワークロードの数が増加すると、この種の確定したオンプレミス インフラはコストがかさむようになり、データ処理ジョブの遅延を引き起こします。この問題への対処方法の一つに、分析や AI アプリケーション向けのオープンソースのデータ オーケストレーション プラットフォームである Alluxio を使用して、Hadoop、Spark などのクラスタに対応した Google Cloud のマネージド サービスである Dataproc にワークロードを「バースト」するというやり方があります。データをコピーしなくても、オンプレミスのデータソースを Alluxio にマウントすることで、ハイブリッド環境をまたいだデータ分析を高パフォーマンスで行えるようになり、プライベート データセンターのコスト削減にもなります。
Dataproc へのゼロコピーのハイブリッド バースト
Alluxio は、企業のプライベート オンプレミス コンピューティング環境とも Google Cloud とも統合します。ワークロードをオンデマンドで Google Cloud にバーストでき、コンピューティング環境間のデータ移動を前もって行う必要はありません。そのため、I/O オーバーヘッドを抑えながら高パフォーマンスでデータを分析できます。
たとえば、HDFS に保存されたオンプレミスのデータに対して Spark や Presto といったコンピューティング フレームワークを使用できます。Alluxio を使用してこのデータを Google Cloud にバーストすると、関連する分析をクラウドでオンデマンド実行できます。このため、大量のデータをクラウドに移行する際に必要だった時間やリソースが大幅に削減されます。それでも、オンプレミスのデータ パイプラインやソースシステムは変化および進化しているため、データを Cloud Storage に転送した後では、ほぼリアルタイムのデータにアクセスするのが困難です。データ オーケストレーション プラットフォームを使用すれば、必要なデータのみオンデマンドで移行して、更新があったデータをシームレスにクラウドでアクセスできるようにします。すべてのデータを Cloud Storage に保持する必要はありません。
このソリューションは、金融サービス、医療、小売業の企業にとりわけ役立っているという声をお客様からいただいています。というのも、こうした企業は、機密データをオンプレミスに保存し、マスク処理を施したうえでマスク処理済みデータと機械学習ジョブや ETL ジョブを Google Cloud にバーストする必要があるからです。
代表的なアーキテクチャは次のようになります。
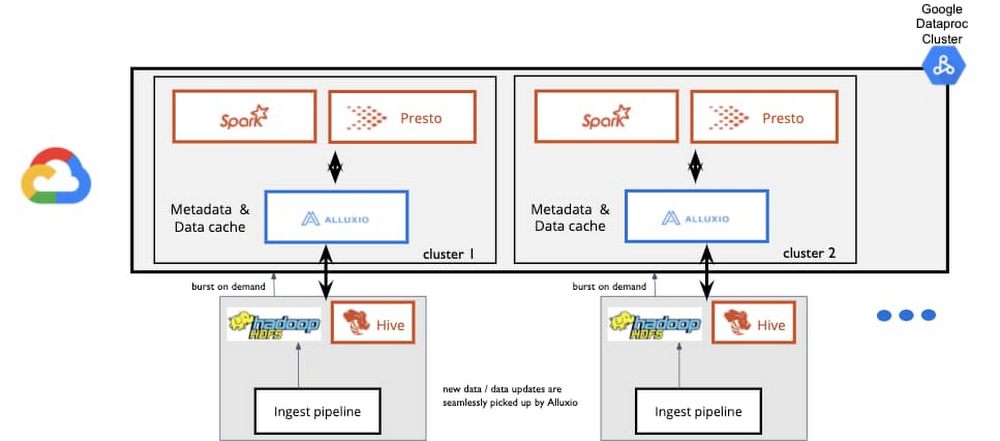
米国の大手小売業者が取り入れたバースト処理の手法
実店舗とデジタル店舗を両立させている、ある大手小売業者は、データの流入量の増加に伴いオンプレミスのデータセンターへの負荷が過剰になってきたため、Alluxio と Google Cloud を組み合わせて構築したゼロコピーのハイブリッド ソリューションに移行しました。同社は Google Cloud のスケーラビリティを活用したいと考えていましたが、セキュリティ上の懸念からクラウドにデータを保持することができませんでした。
そこで、Alluxio を導入して Presto のワークロードを Google Cloud にバーストし、以前はクラウドに移行できなかった大規模なデータセットに対してクエリを行うことにしました。Alluxio を導入するまでは大量のデータを手動でコピーしていましたが、これにはジョブの実行に必要な時間より 3~4 倍も多くの時間がかかっていました。ジョブが完了したらデータを削除しなければならず、Google Cloud のコンピューティングの利用において大きな無駄が発生していました。Alluxio への移行により、クエリのパフォーマンス全体が大幅に改善され、Google Cloud のスケーラビリティと柔軟性を活用できるようになりました。同社のアーキテクチャは次のようになっています。
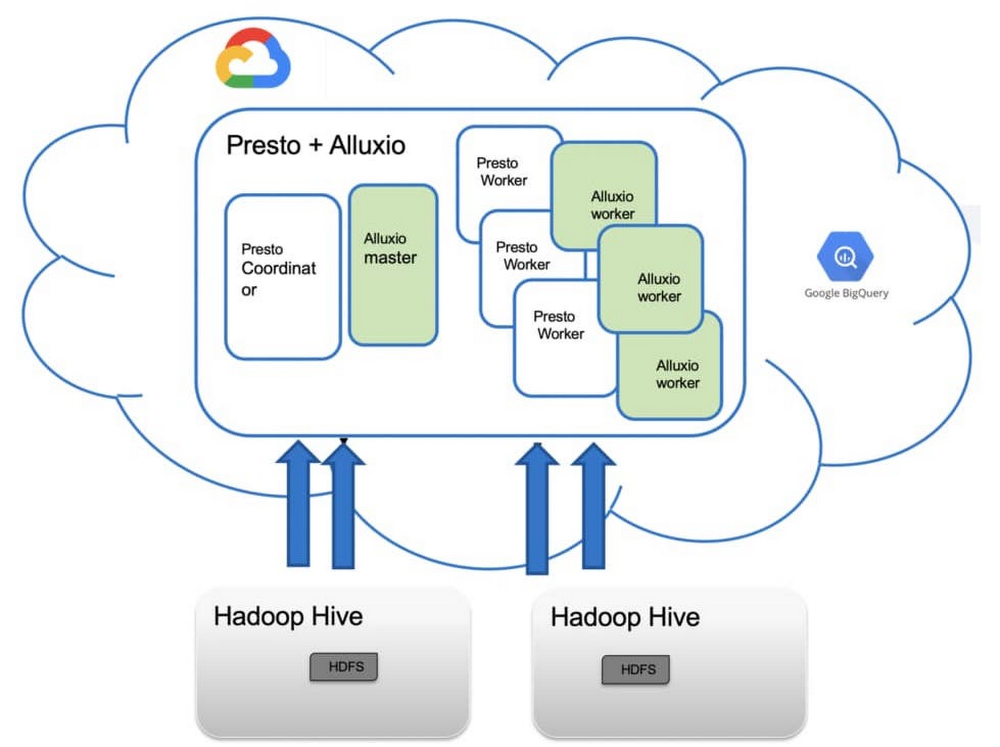
ゼロコピーのハイブリッド バースト方式を使用してコストとパフォーマンスを改善
ここでは、Hadoop や他のビッグデータ ワークロードをオンプレミスで扱っているユーザーがよく直面する課題をいくつかご紹介します。
Hadoop クラスタを実行すると CPU 容量が 100% を超える
マスター NameNode への負荷が高いため Hadoop クラスタを拡張できない
コンピューティング容量が不足しているため、一時的なビジネス ユーザーには期待どおりのサービスレベル契約(SLA)を提供できない、また SLA ワークロードとそれ以外の区別がなされていない
低頻度で突発的な分析(コンピューティング リソースを大量に消費する月次コンプライアンス レポート生成ジョブなど)に、貴重なリソースが奪われる
コスト抑制が広範囲で問題になっている
自己管理型インフラストラクチャの運用コストで総所有コストが増加し、IT スタッフの給与に関連する間接費も増加する
こうした課題に対処する手段としてクラウドを利用すれば、コンピューティングもストレージも別々のスケーリングやオンデマンドでのプロビジョニングが可能であり、複数のコンピューティング エンジン(ジョブに適したツール)を臨機応変に利用でき、エフェメラルなワークロードを移動することにより、過剰になっている既存インフラストラクチャへの負荷を低減できます。
ゼロコピーのハイブリッド バースト ソリューションについて詳しくお知りになりたい方は、Alluxio と Google Cloud Dataproc チームが 5 月 28 日(木)に共同主催する技術解説イベントにお申し込みください。
- By Alluxio リード エンジニア、Adit Madan



