BigLake を使って Apache Iceberg レイクハウスを変革する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
データが複数のレイクやウェアハウスにまたがってサイロ化されている環境においては、データによる変革を行って成果をあげるのは困難です。Apache Iceberg はオープンソースのテーブル形式であり、オブジェクト ストア上でホストされているデータの管理機能を備えています。これを使えば、データの単一コピーを分析や AI のユースケースに使用することが可能になります。Iceberg を利用するコミュニティは、データ エンジニアから、顧客、業界パートナーまで広がり続けています。これらのコミュニティによる貢献や、統合、デプロイが進むに従って、Iceberg はオープン形式のレイクハウス構築の標準として認識されるようになりました。
このような流れのなかでお客様を支援するため、Google Cloud は 2022 年 10 月、BigLake による Iceberg のサポートを発表いたしました。プレビュー版の公開以来、多くのお客様が Apache Iceberg をデータ マネジメント レイヤとして使用し、レイクハウス ワークロードの構築を始めています。そしてこのたび、BigLake による Iceberg のサポート機能の一般提供(GA)が開始されました。
分析、ストリーミング、AI のユースケースをデータの単一コピーで実行
データの処理と Iceberg テーブルへの取り込みにはオープンソースのエンジンを使用でき、そのテーブルに対して BigQuery のクエリを実行できます。プレビュー版の公開以来、お客様は Spark、Trino、Flink も使って Iceberg テーブルを処理し、BigQuery ユーザーがこれらのテーブルを利用できるようにしています。そうすると、Iceberg テーブルの共有メタデータが BigLake Metastore から BigQuery やオープンソース エンジンに提供されるため、複数のテーブル定義を維持する必要はありません。さらに、Spark で Iceberg の新規テーブルを作成するときに BigQuery のデータセットおよびテーブルのプロパティを提供すれば、BigQuery ユーザーがこれらのテーブルに自動的にアクセス可能になり、クエリを実行できるようになります。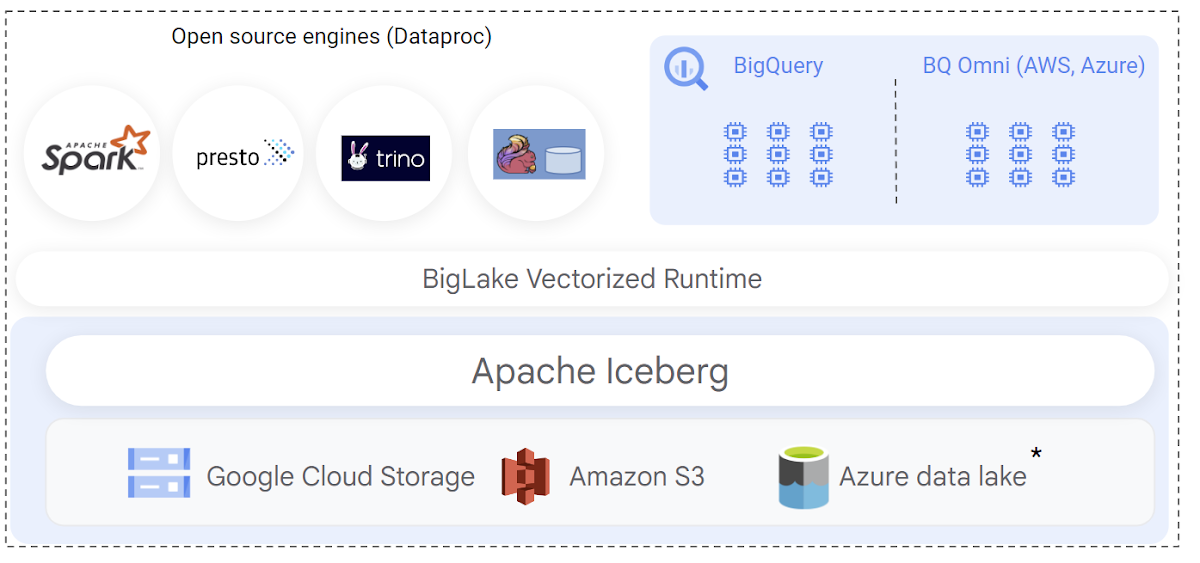
Iceberg のレイクハウス ワークロードを実装する際、データ ウェアハウスのユーザーにとって最も重要なのはクエリのパフォーマンスです。BigQuery は Iceberg のトランザクション ログとネイティブに連携し、豊富なメタデータを活用して効率の良いクエリ プランニングを行います。クエリプランとは、BigQuery のコンピューティングの使用量を減らすための計画です。具体的には、スキャンデータ量を減らしたり、結合を最適化したり、データプレーンの並立処理を改善したりします。その結果、BigLake Iceberg テーブルのクエリ パフォーマンスが向上し、スロットの使用量が減少します。
また、この GA リリースではサポート内容が拡充されており、オープンソースのエンジンによってテーブルが編集されたときに BigQuery のテーブル スキーマが自動的に同期されます。
エンジンに依存しない、業界トップクラスのセキュリティとガバナンスを実装
お客様が最も重視していたのは、Iceberg レイクハウスの構築時にセキュリティとガバナンスを徹底することです。こうした課題への対処を容易にするため、BigLake では Iceberg テーブルの行および列レベルのセキュリティやデータ マスキングへの対応など、きめ細かなアクセス制御が可能となっています。これらの機能は、クエリエンジンとは独立して動作するように設計されています。また、プレビュー版の公開中に BigQuery が拡充され、Iceberg を含む全テーブルで差分プライバシーがサポートされるようになりました。
BigQuery を使って、BigLake Iceberg テーブルにセキュリティ ポリシーを定義することも可能です。このセキュリティ ポリシーは、使用しているクエリエンジンの種類にかかわらず適用されます。BigQuery は実行時にこれらのポリシーをネイティブに適用し、オープンソース エンジンが BigQuery Storage API を使ってデータに安全にアクセスできるようにします。BigQuery Storage API は、データプレーン レイヤでセキュリティ ポリシーを適用し、Spark、Trino、Presto、TensorFlow 用の事前構築済みのコネクタ経由で提供されます。また、クライアント ライブラリを使って、カスタム アプリケーション用のコネクタを構築することもできます。
マルチクラウドの Iceberg レイクハウスにより新たなユースケースを実現
Apache Iceberg はオープンソースであるため、マルチクラウドのレイクハウスを構築し、データ マネジメントを統一することができます。今回のリリースにより、Amazon S3 上で BigLake Iceberg テーブルを作成し、BigQuery Omni を使ってクエリを実行することが可能になりました。BigLake のパフォーマンスやきめ細かなアクセス制御機能は、マルチクラウドの Iceberg テーブルにもシームレスに拡張されるため、BigQuery でクロスクラウド分析を安全に実行できます。今後数週間以内に、Azure Data Lake Storage Gen2 も同様にサポートされるようになる予定です。
Apache Iceberg ではクラウド間で形式が統一されているため、異なるクラウドを使用している顧客やパートナー、サプライヤーとデータを共有するなど、新たなユースケースの可能性が広がります。Cloud Storage または Amazon S3 に配置された BigLake Iceberg テーブルは、Analytics Hub で共有したり、BigQuery から、あるいは BigQuery Storage Read API 経由で OSS エンジンから使用することができ、共有方法のオープン スタンダードとして、複数のクエリエンジンの使用を可能にしています。これを示す注目すべき事例としては、最近発表された Salesforce Data Cloud のデータ共有のユースケースがあります。このユースケースは、Salesforce と BigQuery との間で双方向かつクロスクラウドのデータ共有を可能にするもので、Iceberg が活用されています。
使ってみる
Iceberg テーブルを作成してクエリを実行するには、こちらのドキュメントをご覧ください。または、Iceberg のジャンプ スタート ソリューションを使って、Google Cloud の分析レイクハウスで簡単な概念実証を実施することもできます。
- Google Cloud、プリンシパル エンジニア Yuri Volobuev



